
代码变更中抽取类重构模式的识别①
2018-09-17 08:49孙美荣杨春花
计算机系统应用 2018年9期
孙美荣,杨春花
(齐鲁工业大学(山东省科学院)信息学院,济南 250353)
重构[1,2]是一种有纪律、经过训练、有条不紊的程序整理方法,是现代软件开发和维护中用于提高软件可维护性和软件质量的常用手段,在代码整理过程中可以将不小心引入的错误降低.
现代的软件开发一般基于版本管理系统进行,软件工程师为了维护系统或提高系统的性能,每天会提交大量的代码.文献[3]指出代码变更伴随着软件系统的整个生命周期,不断的代码变更,会使软件的复杂度大幅度的提高[4].代码变更是指日常的bug修复、代码重构、功能增加,这使得代码评审者[5]和软件工程师在理解代码时不得不人工对代码进行探查,以区分哪些变更的代码是重构,哪些不是.
而且日志描述往往反映不了代码变更的真正行为,廖湘科等人在《大规模软件系统日志研究综述》[6]中,通过对软件(Apache,Squid,PostgreSQL,SVN以及Coreutils等)系统的失效报告进行随即检测,发现77%的系统失效都是常见的错误诊断,而57%的错误是没有进行日志记录.
文献[7] 对微软54位资深开发人员进行的调研,发现96%的人认为日志在软件开发和维护中有重要作用,认为日志是了解变更代码的主要信息来源,然而业界人员对日志的重视度不高,且代码变更书写不规范,导致评审员和维护人员花费大量的时间去定位及分析这些代码变更.因此,为了使得变更的代码易于理解,及提高代码质量,将重构模式从代码变更中隔离出来是非常必要的.
重构模式的识别是在变更后的代码中寻找符合特定重构模式的代码修改,是重构的反过程.刘阳等人[8]提出了一种重构检测算法,是基于版本元素匹配原理,对函数抽取重构进行了识别,但是并没有涉及其它类型的重构模式.
本文通过对四个开源项目的变更代码进行探查,抽取类是最为常见的重构模式.因此,本文对抽取类重构模式进行了研究,提出了识别的算法.
1 识别方法
1.1 抽取类模式示例
抽取类(Extract Class)[9]重构模式,一般用于处理过长的类.一个类如果包含过多的功能及属性,会导致这个类过于臃肿.为了提高类的高内聚,低耦合,就会将一些不必要的或不经常用的方法提炼到另一个类中,来为这个类服务.如图1是一个用类图形式表示的抽取类模式示例.类Person中过多的属性oficeAreaCode和officeNumber以及功能代码getTelephoneNumber()被抽取到了一个新类TelephoneNumber中,且在移动代码的地方对新增加类方法的引用.
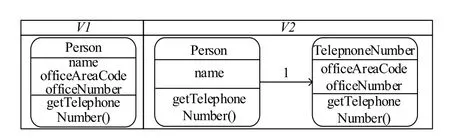
图1 抽取类模式示例
1.2 识别方法
根据上述抽取类模式的例子,不难发现,抽取类模式变更具备如下3个特性:
① 变更文件中的某些属性及方法被删除;
② 文件中删除的属性和方法移动到其它类文件中;
③ 在原文件删除代码的位置有对被移动方法的引用.
其中,①和③的判定需要基于变更代码块的语法信息进行识别,因此我们借用了ChangeDistiller1https://bitbucket.org/sealuzh/tools-changedistiller/src/工具获得一个变更文件中所有的代码变更,如声明对象:ADDITIONAL_OBJECT_STATE、插入语句:STATEMENT_INSERT、删除语句:STATEMENT_DELETE、移除属性:REMOVED_OBJECT_STATE.它是BeatFluri等人[10,11]编写的一个 Tree differ 算法,将对变更前后抽象语法树进行对比,获取分类变更.它可以区别多种方法类型的变化或类等级上的变化.
而特性②的判定需要基于文本的相似性进行识别.我们借助了Levevshtein2https://en.wikipedia.org/wiki/Levenshtein_di stance.算法,即文本相似性判断.Levevshtein是一种计算两个字符串间差异程度的字符串度量(string metric)算法,即一个单词变成另一个单词要求的最少单个字符编辑数量(如:删除、插入和替换).那么两个字符串的相似度算法:
Similarity=(Max(x,y)-Levenshtein)/Max(x,y)
其中,x和y为源串和目标串的长度,本文x指删除的代码语句,y指在新类文件中的代码行.注意:本文研究的是重构模式识别,不是字符串的相似性,所以并没有对该算法进行改进.
识别方法的具体流程如下:
1)利用ChangeDistiller获取两个相邻文件的所有变更类型的详细信息如:变更类型、变更内容、变更内容所属的双亲;
2)根据每条变更所属双亲实体进行分组,将相同双亲实体分到一个组内,并对每个组内的所有删除的语句和增加的语句按行号进行排序,其中代码行号通过读取文本行获得;
3)依据重构模式的特性从2)所得分组中,借用Levevshtein算法进行相似度匹配(删除语句和新增文件的代码行),查找相应的元素,具体过程见下节.
1.3 抽取类模式识别
图2显示了该算法的框架,具体流程如下文.
1)代码变更抽取
通过ChangeDistiller获取所有的代码变更,包括声明对象、删除的语句、原方法中新增的语句等.一个代码变更由变更类型(ChangeType)、变更实体(ChangeEntiy)和变更双亲实体(ParentEntity)构成.
2)代码变更分组
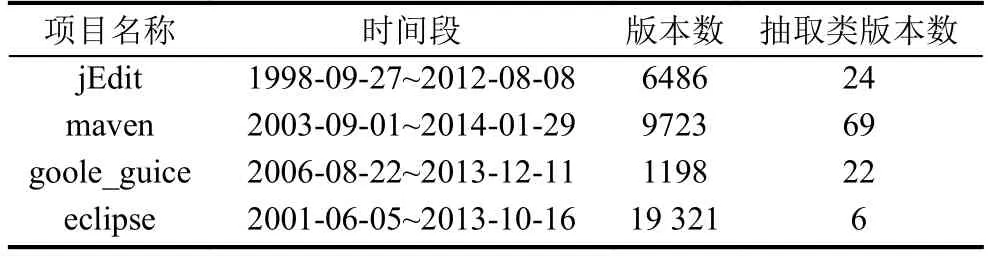
通过上述步骤1),每条变更可获得一个元组的集合C={ 3)代码块抽取判定步骤, 将每组CS分为两部分,令删除部分为ldelete和增加部分为ladd,即CS=cg.ldelete+cg.ladd. ① 若父类实体是类等级上的变更.判断cg.ladd是否为新增类文件的声明对象,若是则,再判断cg.ldelete是否为该新增类文件的属性; ② 若父类实体是方法变更.cg.ladd是否为新增类文件的方法,若是则,再判断cg.ldelete是否为该方法的方法体; ①、②的过程我们借用了文本相似性工具Levevshtein对相应元素进行判定,若以上步骤成立,则成功识别一个抽取类重构模式. 方法扩展:新文件fnew获取及相关操作,1)新增文件fnew是根据本次提交的revision_id与上次revision_id–1进行比较获得,若revision_id–1中的文件集不包含文件f,则认为文件f为新增文件fnew;2)通过Java的反射机制获取新增类文件的属性fnew.field、方法fnew.method、类名fnew.class. 图2 抽取类思想 编写抽取类重构模式识别的伪代码算法. 1 输入:一次提交的版本号revision_id 2 输出:重构模式集合P3 获取revision_id中所有的代码文件集F4 for eachf∈Fdo 5 获取f的前相邻版本fold6 依据fold和f,获取所有的变更集合C7 对集合C进行分组得到集合CG8 获取所有属性的变更组集合CGfieldCG10 for eachcg CGdo 11 for eachfnew∈Fdo 9 获取所有方法的变更组集合CGmethodCG 12 ifcg CGfield13 for eachcg CGfield14 获取CGfield.CS中所有的新增语句cg.CS.ladd15 获取CGfield.CS中所有的删除语句cg.CS.ldelete16 ifcg.CS.ladd.entity=“FIELD”17 ∩Levevshtein(cg.CS.ladd.parententity,fnew.class)18 ifcg.CS.ldelete.entity=“FIELD”19 ∩Levevshtein(cg.CS.ldelete.conten t,fnew.field)20 end if 21 end if 22 end for 23 else ifcg CGmethod24 for eachcg CGmethoddo 25 获取CGmethod.CS中所有的新增语句cg.CS.ladd26 获取CGmethod.CS中所有的删除语句cg.CS.ldelete 27 ifcg.CS.ladd.entity=“RERURN_STATEMENT”28 ∩Levevshtein(cg.CS.ladd.parententity,fnew.method)29 ifcg.CS.ldelete.entity=“RERURN_STATEMENT”30 ∩Levevshtein(cg.CS.ldelete.content,fnew)31 end if 32 end if 33 end for 34 end if 35 end if 36 成功识别一个抽取类模式p 37 end for 38 end for 39 end for 40P=P∪{p} 算法伪代码中第4行指遍历集合F中的所有文件f;第5行通过ChangeDistiller可知f是否为变更文件;第8行指获得集合CG中的属性集合;第9行指获取集合CG中的方法集合;16~19指在变更类型为“FIELD”的情况下,判断属性是否移动到fnew中;27~30 指在变更类型为“RERURN_STATEMENT”情况下,判断删除的方法及方法体是否移动到新文件fnew中,且在删除代码的位置有对该方法的引用;第36行若以上步骤为真,则成功识别一个抽取类模式;第40行返回所有识别成功的重构模式集. 我们通过minigit3https://github.com/SoftwareIntrospectionLab/MininGit工具获取了四个开源项目jEdit4https://github.com/linzhp/jEdit-Clone,eclipse JDT Core5https://github.com/eclipse/eclipse.jdt.core,Apache maven6https://github.com/apache/maven/,and googleguice7https://github.com/google/guice/,在某段时间的变更历史,该工具将该时间段内所有的变更信息(包括所有提交的版本、每个版本的日志、源文件等)抽取到了MySQL数据库中. 我们前期通过人工分析变更日志和源代码探查,判定了一些存在重构模式的版本.项目的信息及人工判定的重构版本数据见表1. 表1 开源项目详细信息表 通过人工检测4个开源项目,获得抽取类重构模式的数目分别为:jEdit中含有24个版本,maven中含有69个版本,goole_guice中含有22个版本,eclipse中含有6个版本. 图3、4是取自项目maven版本68ca923 中DefaultMetadataResolutionReques.java(left.java)和DefaultRepositoryRequest.java(right.java)的部分变更内容;其中减号表示删除代码行,加号表示增加代码行.图5是该算法对这一变更检测的信息输出.其中ChangeDistiller获取声明对象FIELD、删除代码,以及文本读取代码块行号. 该实验对表1中的数据进行验证,通过实验后检测得到的实验结果,见表2. 图3 left.java 图4 right.java 通过表2可以得出,该试验进行的抽取类模式识别,其平均准确率为82.6%,准确率在77.3%~91.6%之间略有波动.准确率没有达到100%的原因与借用的代码相似性比较算法有关.因为被测文本是重构代码变更文本,所以被提取的代码块并不是简单的复制/粘贴.程序员在进行代码重构时,为了提高代码质量的可理解性、可维护性和可扩展性,被提取的代码行中的有些元素可能被替换,如新增方法中的参数、局部变量等,但整个操作并不会改变软件功能.因此,对本文反过程重构模式识别中代码块提取过程会有些影响. 图5 实验结果 表2 实验结果 我们提出了一种基于变更类型和文本相似性比较的重构模式识别方法,并设计和实现了对抽取类(Extract Class)模式的识别.通过实验验证,该方法可以比较准确地识别Extract Class模式. 除了Extract Class模式,该方法还适用于其它存在代码移动的重构模式,如Extract Superclass,Move Interface等.后续工作包括将该方法应用于这些模式的识别.
2 算法



3 实验验证
3.1 数据源
3.2 结果及实验分析




4 结束语
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
思维与智慧·上半月(2018年10期)2018-11-30
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
思维与智慧·上半月(2018年9期)2018-09-22
小学生·多元智能大王(2014年6期)2014-07-09
外语教学理论与实践(2014年1期)2014-06-15
