
面向公共信息服务的藏文问题分类方法研究
2018-09-17 03:12孙丽萍戴玉刚
无线互联科技 2018年17期
孙丽萍,戴玉刚
(西北民族大学 中国民族语言文字信息技术教育部重点实验室,甘肃 兰州 730030)
在信息化时代,随着藏语言文字的信息资源日益丰富,相关的藏文数据信息不断增加,藏族人民对信息获取的需要不断增强,传统的搜索方法已不能满足用户需求,这极大影响了用户获取信息的快捷性和正确性。藏文问题分类对藏文信息抽取具有重要意义。目前,关于中文问题分类已经有很多学者对此进行了研究以及更深层次的探讨,却少有学者进行对藏文问题分类的研究。
藏文问题分类在少数民族公共信息服务领域有着重要的研究意义和应用价值。针对民族院校的公共信息服务平台,学校应该不仅仅是局限于采用中文,而是应该多增加少数民族语言,方便少数民族学生。同时,此举更能彰显民族院校的特色。文章是面向公共信息服务的藏文问题分类,采用西北民族大学“校园百事通”的问题集进行分类。
1 相关研究
对于问题分类的研究,最早是采用基于规则的方法[1],分类的准确率较低,在所定义的7个类别上的准确率只达到了57.57%。现在主要采用基于统计的机器学习方法。其中代表性的是Dell等[2]提出的采用支持向量机(Support Vector Machine,SVM)算法对英文问题进行分类[3],该方法采用tree kernel提取特征,最终达到6个大类的90.0%精度。另一个是层次分类思想,把词汇、词性、语块、命名实体、中心语块和相关词作为特征,达到6个大类91%的精度和50个小类84.2%精度。由于英文问题通常把疑问词放在句首,且不存在分词问题,而中文问题相对复杂,处理起来相对困难。对于中文问题,有代表性的是张宇等[4]提出的基于改进贝叶斯模型的问题分类,达到72.4%精度。文勖等[5]提出的基于句法结构分析的中文问题分类,将问题的主干和疑问词以及附属成分作为特征,大类和小类的精度分别达到了86.62%和71.92%。
作为一门少数民族语言,藏语方面的自然语言处理没有像中文那样被广泛关注。但是作为一个多民族国家,大力发展少数民族语言是势在必行的。关于藏文问题分类少有研究。柔特[6]提出了基于藏文疑问虚词的问句分类方法,该方法首先提取问句中的藏文虚词,然后根据所得虚词进行问句分类。
2 问题分类
2.1 数据来源
文章采用西北民族大学“校园百事通”的问题集,该数据集包含902条校园问题和答案。主要是对西北民族大学的公共信息服务平台进行问题分类,进而提高校园服务平台的执行效率,方便新老学生查询学校信息。
2.2 校园公共信息服务问题分类体系
不同的语言,提问的方式也各有不同。关于校园公共信息服务领域是相对比较窄的一个面,所提问的有关问题也只于学校和学生切身利益有关。该领域的用户问题与开放领域问答系统中的用户问题是不一样的。主要区别在以下方面。
(1)开放领域是面向所有领域的问题,因此不对处理的用户有任何限制。但是面向公共信息服务领域的问题分类首先要区分用户提交的问题是否在该领域范围之内,在系统处理范围之内。
(2)开放领域的问题分类主要分为人物、时间、地点、数字等问题类型,而校园公共信息服务领域的问题有其特殊性,主要关注的是校园概况,师资队伍、校园服务、科学研究等问题类型。
文章采用西北民族大学“校园百事通”问题集,结合领域知识对语料库进行分析,建立了满足校园公共信息服务的问题分类体系。将该问题分类体系划分为两类,大类7个和小类39个(见表1)。
2.3 贝叶斯模型简介
由于该藏文问题分类主要针对校园百事通,采用的藏文训练文本量小。通过分析各个分类器的优缺点,文章选择贝叶斯分类器。贝叶斯分类方法以贝叶斯定理为理论基础,采用了概率推理方法。贝叶斯分类的原理就是通过计算给定样本在各个类别上的后验概率,然后把该样本判定为最大后验概率所对应的类别。而在计算后验概率的过程中,需要知道数据集中每个类别的先验概率,以及属性的条件概率。类别的先验概率可以通过统计的手段预先知道,而属性的条件概率也可以通过统计的方法或者假定的分布模型来估计。
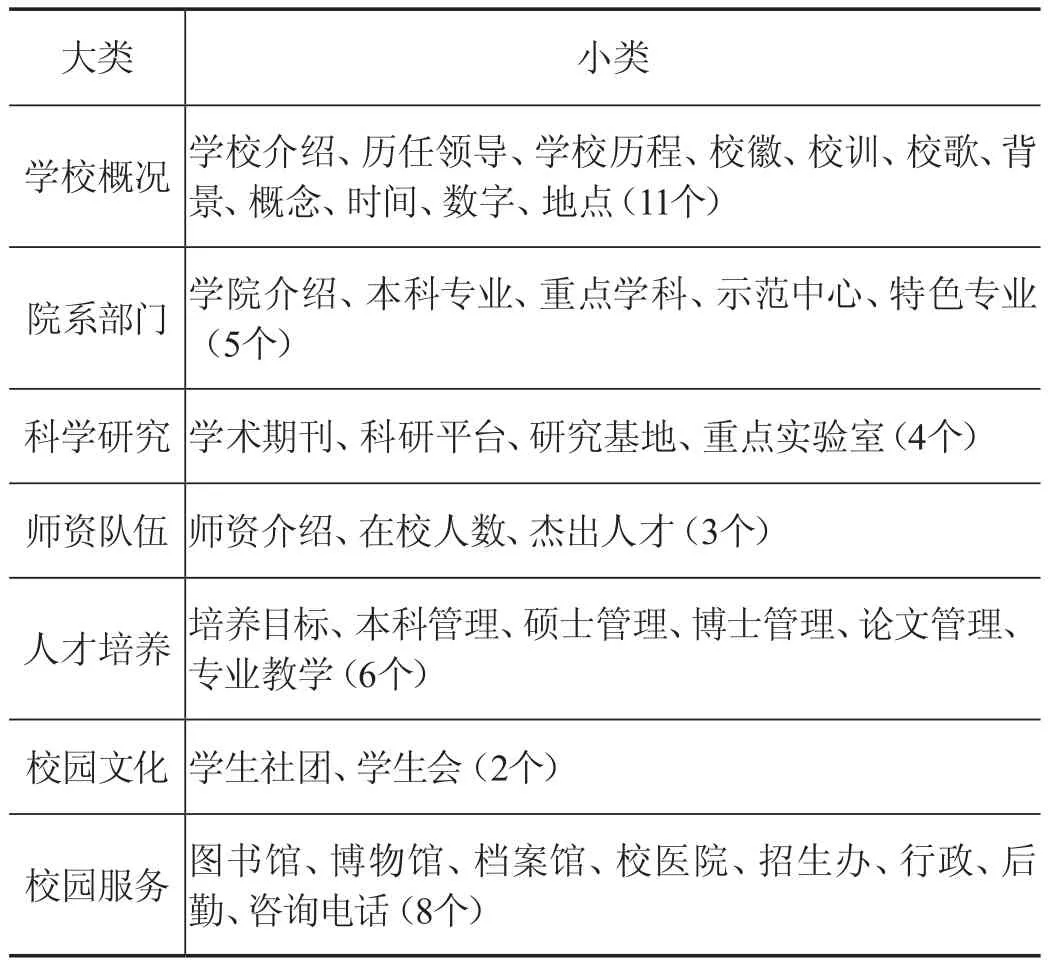
表1 面向公共信息服务的问题分类体系
朴素贝叶斯分类原理:
(1)设x={a1,a2,…,am}为一个待分类项,而每个a为x的一个特征属性。
(2)有类别集合C={y1,y2,…,yn}。
(3)计算P(y1|x),P(y2|x),…,P(yn|x)。
(4)如果,P(yk|x)=max{P(y1|x),P(y2|x),…,P(yn|x)},则x∈yk。
根据上述分析,朴素贝叶斯分类流程如图1所示。
2.4 藏文问题预处理
2.4.1 藏文分词
藏文是由30个辅音字母和4个元音字母组成的一种拼音文字,由这些字母组成音节,由音节构成词,音节之间用音节点“.”作为分隔符来进行区分。因此没有明显的分隔符进行区分。分词是藏文预处理的一个重要阶段。词在汉语和藏语中都是最小的语义单位,词与词之间不像英文那样有空格。藏文分词是将句子切分成单独的词,也就是通过一定的方法使得在计算机上能自动地将藏文文本的词与词之间加上空格。文章采用TIP-LAS开源的藏文分词词性标注系统[7]。该系统能够提供藏文分词、词性标注功能。
2.4.2 去停用词
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。在问题分类中去停用词目的是提高分类速度。文章所用到的藏文停用词都是人工输入、非自动化生成的,得到的停用词组成一个停用词表。通过停用词表把这些词在预处理阶段去除。
2.4.3 命名实体识别
命名实体识别(Named Entity Recognition,NER)其目的是识别语料中人名、地名、组织机构名等命名实体,识别文本中具有特定意义的实体。通常包括实体边界识别和确定实体类别两部分。命名实体识别是自然语言处理领域的基础问题[8]。
2.5 分类精度
对藏文问题分类体系的大类和小类的分类准确率对系统进行评价。其分类精度定义如下:

3 结语
目前,面向公共信息服务的藏文问题分类的研究尚处于初级阶段,可供参考的资料不多。文章结合中英文的分类体系以及藏文自身特点设计了藏文问题分类体系,简要介绍自然语言处理方面的藏文问题分类的研究,进而能有效提高藏文问题分类的准确率。
因为该藏文问题分类主要针对校园百事通,采用的藏文训练文本量小,该藏文问题分类系统会存在一定缺陷,但通过增加训练文本,会有效改善情况。研究可知,问答系统已经成为当前自然语言处理的一个热门方向。问题分类作为问答系统的关键组成部分,也必然是一个值得研究的方向。
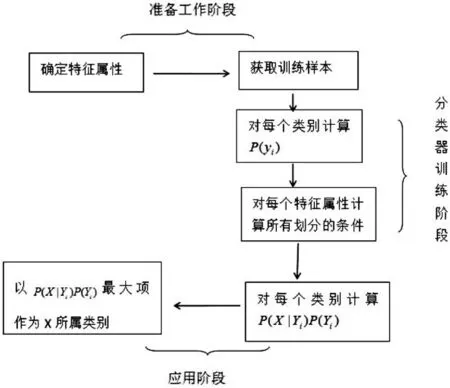
图1 朴素贝叶斯分类流程
猜你喜欢
新世纪智能(高一语文)(2021年11期)2021-03-08
中国交通信息化(2018年5期)2018-08-21
通信电源技术(2018年3期)2018-06-26
幼儿100(2018年10期)2018-04-10
小学生作文(低年级适用)(2017年3期)2017-07-06
中国水运(2017年4期)2017-04-26
中国老区建设(2016年3期)2017-01-15
文学教育(2016年33期)2016-08-22
中国交通信息化(2016年8期)2016-06-06
农村百事通(2016年2期)2016-05-30
