
铁路旅客价值指数计算模型的设计研究
2018-09-14 07:39郝晓培单杏花张军锋
铁道运输与经济 2018年9期
郝晓培,单杏花,张军锋
(1.中国铁道科学研究院 研究生部,北京 100081;2.中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
1 概述
随着信息时代的高速发展及“互联网+”商业模式的快速推广,如何识别并发展高价值客户成为各个服务型行业提高市场竞争力的关键。客户价值是指与企业具有长期稳定关系并愿意为企业提供产品和服务,从承担合适价格的客户中获得的利润,也就是客户对企业的利润贡献。有效地识别高价值客户群体,有利于针对不同价值客户群体合理地配置资源,提高企业竞争力。
在21世纪前,对客户价值评估模型衡量因素的研究主要集中在客户的货币因素。在Harvard Business Review关于客户关系管理的研究中,将客户目前产生的净利润作为衡量客户价值的主要因素;1994年Hughes[1]构建了RFM (最近购买日期、重复购买频率、购买金额)客户价值模型,主要以客户消费行为特征为衡量因素;1996年Reichheld将基础利润、增加购买、成本节约、推荐效应、价格溢价等作为主要衡量因素;直到2000年之后,客户价值的非货币因素才开始受到重视,Walter等[2]提出非货币价值因素是企业衡量客户价值的重要组成部分。近些年,旅客价值研究已经成为交通运输领域研究的热点[3]。与其他行业相比,铁路对旅客价值的测算及评价方法难以操作,理论研究落后于现实需要,导致铁路企业旅客管理效率低下。一方面,铁路企业无法依赖传统的运输服务来区分旅客价值,更不熟悉旅客评价和管理机制,因而铁路客运服务只能采取相互借鉴的方式来管理旅客;另一方面,随着铁路竞争对手(航空、公路等)对旅客价值测算与评价越来越重视,铁路高价值旅客出现大量流失。
因此,为解决铁路企业现阶段旅客价值评价体系角度单一、缺乏普适性和科学性等问题,在以往研究成果基础上,采集铁路12306互联网售票、站车WIFI、铁路互联网订餐等信息系统的旅客交易行为数据[4],构建铁路旅客价值指数计算模型。该模型主要有以下步骤:①根据旅客固定时间段内的购票次数、交易金额、退票比例、动车组购票比例、出行里程等历史出行和交易特征对旅客历史价值指数进行计算;②根据旅客之间的同行行为数据及历史价值指数构建旅客同行关系网络,并对旅客潜在价值指数进行计算;③基于旅客历史价值和潜在价值2个维度对旅客群体进行类别划分,区分出不同价值的旅客群体。
2 铁路旅客价值指数计算模型
铁路旅客价值总体评估包括历史价值(HV)和潜在价值(PV) 2个价值维度,其中历史价值反映旅客在过去出行过程中对铁路盈利的贡献情况;潜在价值反映旅客在今后一段时间内可能给铁路带来的收益情况[5]。历史价值指数计算主要根据旅客的历史出行及交易数据进行计算;潜在价值指数计算主要根据旅客的历史价值指数评估结果及旅客之间共同出行的社交网络进行计算。为更好地对旅客价值进行评估,需要将旅客的价值进行数字化,因而采用旅客价值指数来表示旅客价值,指数范围是[0,1],再根据旅客历史价值指数和潜在价值指数对旅客价值进行分类。
2.1 旅客历史价值指数计算模型
旅客的历史价值反映旅客对目前铁路盈利的贡献情况,历史价值高的旅客在今后有较大的概率继续为铁路带来盈利。旅客历史价值指数计算模型是以价值贡献特征为聚类变量,采用K-means聚类算法(聚类类别K通过肘部法则估计)将特征具有相似性的旅客进行聚类,再分析分类后的结果[6],获得价值最高和价值最低的旅客群体,并将价值最高的类别和价值最低的类别进行价值指数数字化处理(其中价值最高样本的价值指数赋值为1,价值最低样本的价值指数赋值为0),将无监督样本数据转换为有监督样本数据作为BP神经网络的训练样本,再进行旅客历史价值指数计算。旅客历史价值指数计算模型如图1所示。
由图1可知,旅客历史价值指数计算模型包括以下过程。①基于K-means算法对旅客样本进行分群并标识。旅客价值指数是计算型的旅客属性,无法根据统计信息获得旅客价值指数。在实际的旅客价值指数计算中,将聚类算法作为前导算法进行预处理,其目的是将无监督的样本数据转换成有监督的样本数据,因而旅客的价值指数计算是在有监督样本数据基础上完成的。因此,需要借助K-means聚类算法对旅客样本进行分群标识,避免在BP神经网络训练中因样本大而引发网络结构复杂、收敛性差、泛化能力低等问题。②基于BP神经网络算法进行旅客价值指数计算。基于机器学习的分类和预测算法有很多[7],如BP神经网络、决策树[8]、遗传算法[9]等,其中BP神经网络算法已经在实际分类计算问题中得到了有效的利用和验证,具有较强的自学习和自适应能力,以及高度非线性的表达能力。BP神经网络是将输出层的数据与期望值的误差平方和作为神经网络的误差,并将误差值反向传播,从输出层到输入层采用不同的算法进行权值和偏移量的调优。BP神经网络模型主要采用附加动量的梯度下降法,对调整之后的权值和偏移量进行正向传播并计算输出预测值,如果误差不在一定的范围内,则再次通过反向传播进行参数调整,使得预测输出逐渐逼近期望输出,直至模型的计算误差小于期望误差值。BP神经网络结构如图2所示。

图1 旅客历史价值指数计算模型Fig.1 Model of historical value index

图2 BP神经网络结构Fig.2 BP neural network structure
针对铁路旅客的历史价值指数计算,以K-means聚类算法分类结果中价值最高及价值最低的分类样本作为BP神经网络的训练样本,计算出铁路旅客历史价值指数。BP神经网络正向传播过程公式及激活函数计算公式为
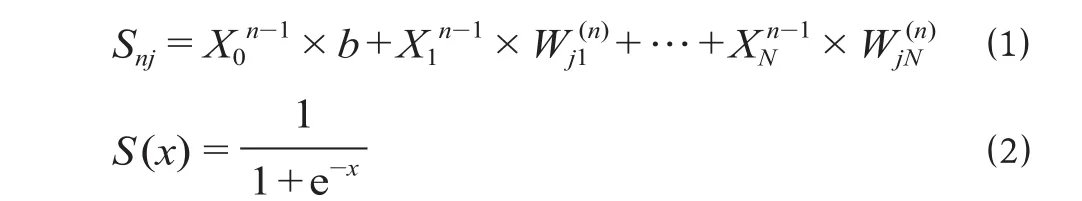
nj(Snj为第n层第j个节点的线性输出)表示第n-1层第i个节点的实时输出;各层所有节点与其相邻下一层的所有节点相连,除外,节点之间的连接都表示为两点之间的权重即第n-1层的第i个节点与第n层第j个节点的权重,当n = 2时,表示在公式 ⑴ 的基础加上偏移量b;为实现输入数据的非线性变换,在隐藏层设置1个Sigmoid函数如公式 ⑵所示,对Snj进行非线性化处理并得到输出数据。
2.2 旅客潜在价值指数计算模型
旅客潜在价值指数计算模型主要是依据Lawrence提出的PageRank算法[10]而构建的。铁路客运信息系统积累了大量旅客同行关系数据,如旅客12306账号购票信息,利用这些共同出行数据可以构建铁路旅客同行关系网络,网络中的节点代表网络系统中的旅客个体,节点之间的连线代表旅客之间共同出行关系,边的权重代表衡量旅客之间社会属性的相似程度。铁路旅客同行关系网络结构如图3所示。
由图3可知,每个节点表示旅客的3个信息:①旅客的惟一标识PID;②旅客的历史价值指数PVH;③旅客的潜在价值指数PVP。每条边是双向连接,a>b的值TRab表示旅客a与旅客b公共出行的概率(表现为旅客a与旅客b共同出行总次数与旅客1结伴出行总次数的比值)。
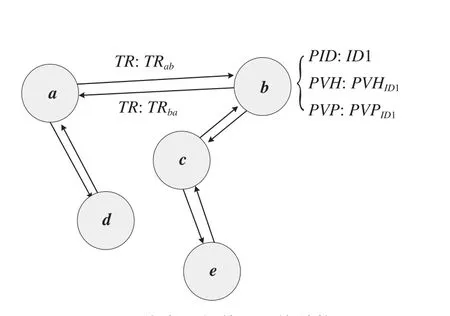
图3 旅客同行关系网络结构Fig.3 Travelers peer relations network structure
旅客潜在价值指数计算模型的主要思想是如果1个旅客比较频繁地与历史价值指数高的旅客共同出行,则该旅客的潜在价值指数就会相对比较高,同时也能体现出与其同行旅客的历史价值指数。同理,如果1个旅客的历史价值指数比较高,则与该旅客共同出行的旅客潜在价值指数就会相应地提高。旅客潜在价值指数计算模型的主要流程步骤如下。
(1)假设构建如图3所示的关系网络G,共包括N个旅客。对于G中的每个节点n,PVHn为第n个节点的历史价值指数;PVPn为第n个节点的潜在价值指数;TRmn为旅客m与旅客n共同出行的比例;向量的每个元素表示与旅客n同行的旅客的历史价值指数;向量的每个元素表示与旅客n同行的旅客的潜在价值指数;向量向量的每个元素表示与旅客n同行的旅客共同出行比例,这2个向量的元素个数表示与旅客n有过共同出行的旅客人数。
(3)对于k= 1,2,…,n的每个节点,如果Indegree (k)<0,则计算公式为
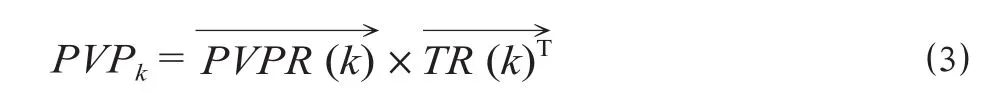
如果Indegree (k) = 0,则计算公式为

由以上公式计算出每个节点的潜在价值指数,并更新每个节点的潜在价值指数。
(4)以公式 ⑶ 作为代价函数,PVPik为第i个旅客第k次迭代生成的潜在价值指数。当代价函数的值大于某一个即定值时,返回步骤(3)继续执行循环,反之,当代价函数的值小于即定值时,上述步骤结束,得到关系网络G中所有旅客节点的潜在价值指数J。
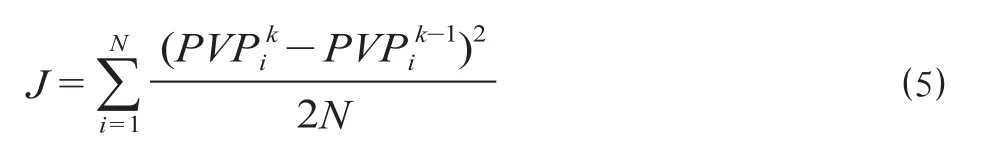
2.3 旅客价值分类
以铁路旅客价值为旅客分类的主要依据,将旅客的历史价值指数和潜在价值指数作为旅客分类的2个维度,其中每个维度分为高档和低档。整个旅客群体分为以下4个类别。①Ⅰ类旅客。低历史价值且低潜在价值旅客(表示现在及将来都为铁路带来较低的利润);②Ⅱ类旅客。低历史价值且高潜在价值旅客(表示现在为铁路带来较低的利润,但是将来有可能带来较高的利润);③Ⅲ类旅客。高历史价值且低潜在价值旅客(表示现在为铁路带来较高的利润,但是将来有可能带来较低的利润);④Ⅳ类旅客。高历史价值且高潜在价值旅客(表示现在及将来都为铁路带来较高的利润)。对应的旅客价值分类矩阵如表1所示。
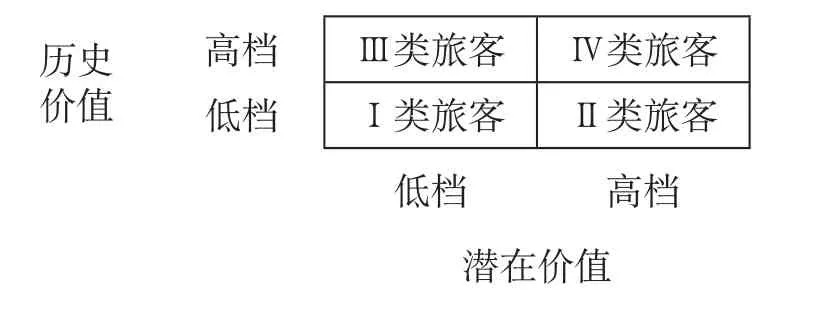
表1 旅客价值分类矩阵Tab.1 Passenger value classification matrix
构建铁路旅客分类价值矩阵,需要确定群体边缘旅客的历史价值指数和潜在价值指数的临界值,再根据临界值对旅客进行分类。在旅客分类过程中,类别之间临界值的选择会直接影响旅客的分类结果,应根据实际问题及业务专家意见来合理设置分类临界值,从理论和经验2个角度提高旅客分类的精确性。由表1可知,对于铁路,Ⅳ类旅客具有最高的价值,为铁路创造的利润最多;Ⅲ类旅客创造的价值比Ⅳ类旅客少,但也是铁路旅客运输需要维持好关系的旅客群体;Ⅱ类旅客虽然过去创造的利润较少,但是属于有潜力的旅客,将来很有可能转换为高价值旅客,即Ⅲ类或Ⅳ类旅客;Ⅰ类旅客是价值最低的旅客群体。
3 实例分析及应用
3.1 旅客价值指数计算分析
选取铁路旅客价值计算衡量因素:货币因素(购票张数、购买高铁动车组所占比例、购票金额、订餐比例、单位公里平均票额等)和非货币因素(旅客同行关系)。根据铁路旅客历史价值指数计算模型及潜在价值指数计算模型,对2017年的100万互联网订票旅客数据进行价值计算,得到旅客历史价值指数和潜在价值指数。在与铁路旅客运输业务专家沟通之后,决定选用旅客历史价值指数和潜在价值指数的均值作为旅客分类的临界值,铁路旅客历史价值和潜在价值如表2所示。根据计算结果,得出历史价值指数的高/低临界值(取均值)为0.43,潜在价值的高/低临界值(取均值)为0.34。
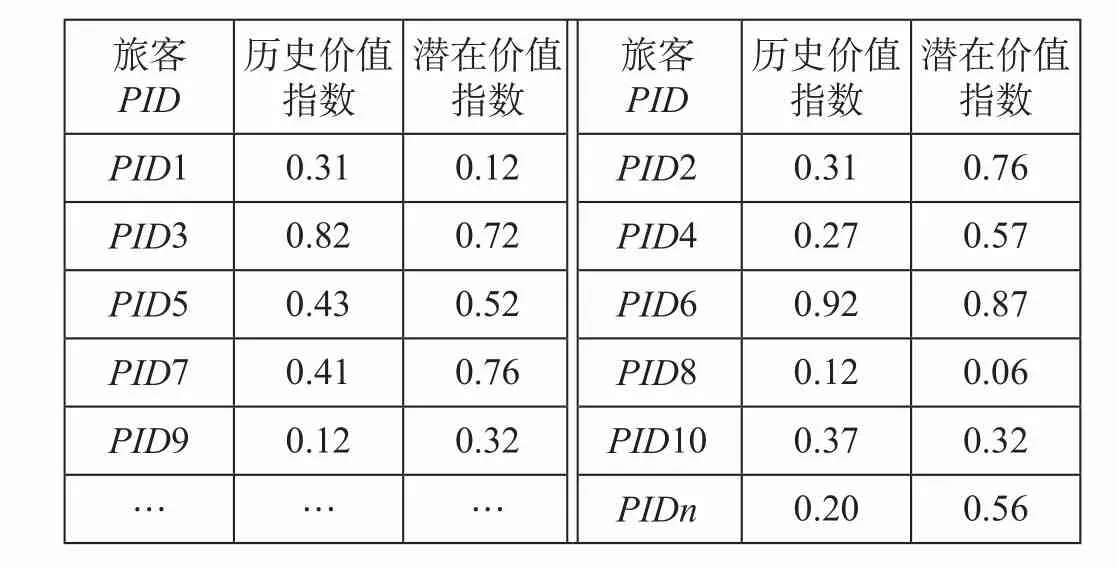
表2 铁路旅客历史价值和潜在价值Tab.2 Historical value and potential value of railway passenger
对铁路旅客价值指数结果进行统计分析,得出铁路旅客分类分布如表3所示。在4类旅客中,Ⅲ类、Ⅳ类旅客虽然占比少,但对铁路而言最具有价值,为铁路创造的历史利润也最大;Ⅲ类旅客的潜在价值存在降低的情况;Ⅰ类旅客占比为21.34%,在2017年为铁路创造的利润最低,但在将来很有可能转换为Ⅲ类、Ⅳ类旅客;Ⅱ类旅客占比最大,约占训练样本的54.34%,为铁路带来的利润最少。根据Pareto原理(即20%的旅客能够带来80%的利润)可知,Ⅲ类、Ⅳ类旅客约占铁路旅客总量的20%,但其为铁路旅客运输创造的利润占总利润的80%,是铁路旅客运输最有价值的旅客。而Ⅰ类、Ⅱ类旅客占比接近80%,但为铁路旅客运输创造的利润仅占总利润的20%。

表3 铁路旅客分类分布 %Tab.3 Classified distribution of railway passenger
3.2 旅客价值指数实际应用
(1)延伸服务。为提高旅客出行体验,中国铁路总公司逐渐开发并上线了广告、站车WIFI、餐饮等延伸服务系统。随着延伸服务产品的不断增长,为识别出潜在的消费旅客群体,建立旅客与产品之间的连接,促进旅客消费,实现产品利润最大化,应在综合考虑旅客购票及出行阶段行为特征的基础上,构建“个性化”推荐系统,旅客价值指数则为推荐系统需要考虑的重要因素之一。只有将产品个性化地推荐给有需求的高价值旅客,才能够在网络资源最小情况下实现利润最大化。
(2)动车组编组调配。目前,动车组编组的席别车厢分配是固定的,每条线路上的动车组都相同,然而,不同运营线路的常出行旅客群体是不同的,动车组的统一分配难免会在一些线路上造成资源浪费或资源欠缺。通过对旅客价值指数计算,得出每条线路上不同价值旅客的分布情况,可以为动车组编组提供调整建议,如动态地调整动车组席别数量。针对不同价值旅客群体,合理配置铁路客运资源,可以在满足不同价值旅客需求的同时,实现铁路旅客运输的利益最大化。
4 结束语
随着信息技术在铁路旅客车票发售与旅客出行服务方面的广泛应用,铁路客运服务与数据分析已经处于深度融合、相互促进的发展阶段,铁路旅客数据的种类和规模也在快速增长。针对日益增长的旅客出行需求,铁路部门正充分应用云计算、大数据、物联网、人工智能等信息技术手段为旅客提供更加丰富的客运服务,而个性化、便捷化、定制化的服务需要建立在更多数据收集的基础之上,更深入的数据分析可以促使产生更加便利的铁路运输服务业态。因此,研究基于大数据的旅客历史价值和旅客潜在价值指数计算模型,不仅可以区分出不同价值的旅客群体,将铁路12306互联网售票、站车WIFI、铁路互联网订餐等信息系统的营销焦点从产品中心转变为用户中心,还可以优化旅客出行体验,推动铁路客运服务行业发展。
猜你喜欢
现代电力(2022年2期)2022-05-23
小哥白尼(趣味科学)(2021年3期)2021-07-16
云南画报(2021年12期)2021-03-08
云南画报(2021年12期)2021-03-08
数学大王·趣味逻辑(2020年8期)2020-08-14
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
故事大王(2018年3期)2018-05-03
中国火炬(2015年7期)2015-07-31
海军航空大学学报(2015年4期)2015-02-27
