
云计算下大数据分布式存储中冗余数据分配算法
2018-09-13 05:04张华丽杨华勇
中国电子科学研究院学报 2018年4期
张华丽,杨 帆,杨华勇
(武汉科技大学城市学院,湖北 武汉 430083)
0 引 言
随着云计算下大数据的广泛应用,大数据的容积逐渐增大[1],分布式存储在处理大数据时具有扩展性、可维护性、可靠性,在成本估算中都有突出的表现[2],在分布式的数据库系统中,通常情况中它的最大特征是存在数据冗余,云计算下分布式存储中冗余数据的分配问题,对于确保大数据安全性具有重要意义,其成为当下相关技术人员研究的热点问题。
以往针对大数据冗余数据集分配问题,主要以支持向量机算法为主,该种算法分配大数据中冗余数据时,仅能进行小样本数据中冗余数据的分配,且不能解决大数据中的冗余数据间关联性低的问题,具有分配效率和准确率较低等弊端。如文献[3]提出了一种动态非冗余数据分配方法,该方法确定了碎片更新参数和动态成本参数,根据数据迁移节点的最低代价的选择,使用参数迭代估计片段的重新分配到节点的成本,然而,该方法冗余数据间的关联性较低。文献[4]提出基于图覆盖的大数据全比较数据分配算法,采用理论分析把大数据全比较的数据分配问题总结成图覆盖问题后,获取图覆盖的最优解,依据特解分配数据,由于过程较为复杂,导致数据分配的效率低;文献[5]提出针对多聚类中心大数据集的加速K-means聚类算法,主要采用动态类中心调整方法对大数据进行聚类,但是由于在K-means算法中,首先需要根据初始聚类中心来确定一个初始划分,然后对初始划分进行优化。这个初始聚类中心的选择对聚类结果有较大的影响,聚类的准确率降低,后续的冗余数据的分配准确度也会降低。本文提出云计算大数据分布式存储中冗余数据分配算法,首先对云计算大数据分布式存储中冗余数据进行分类,再对于分类后的冗余数据片段进行分配,提高冗余数据的分配准确率与分配效率。
1 云计算下大数据分布式存储中冗余数据分配算法
1.1 冗余数据最优分类函数
使用局部特征分析算法,可以获取云计算下大数据分布式存储中冗余数据的重要特征,把获取的重要特征设成对云计算下大数据分布式存储中冗余数据分类时的基本数据。由于在搜集数据时云计算的网络会出现一定程度的迟延,而该算法不受其网络迟延的影响,根据冗余数据的重要特征和相邻领域的数据特征值实行对比,可以体现冗余数据的特征。
采用最优分类平面对云计算下大数据分布式存储中的冗余数据实行分类操作[6]。把冗余数据分类问题转变成最优平面求解的问题[6]:
其中,R(β)为二次判别函数,yj·yk为两个向量的点积;Ζ为分类阈值,Ζj以及Ζk分别表示yj和yk两个向量的分类阈值,β为权重向量,βj以及βk分别表示yj和yk两个向量的权重,p为最大向量,最优分类平面求解问题必须符合以下要求:
(2)
假定云计算下大数据分布式存储中的冗余数据内的特征产生非线性转换[7],那么要使用內积L(yj,yk)替换最优分类函数内的点积。那么最优分类平面求解问题可得出转换后的结果见式(3):
设式(4)是式(3)的最优分类函数:
其中g(y)为最优分类函数;c′为类别属性。通过该函数可获取冗余数据片段。最优分类平面算法可以对两种具有差异性的类别实行分类,但是云计算大数据分布式存储中的冗余数据分类属于多类别分类[8],所以必须先把云计算大数据分布式存储中冗余数据分类变换成多种二分类。同时一一求解[9],最终提取云计算下大数据分布式存储中冗余数据的分类结果。目前对两种分类进行变换通常使用一对多与一对一的分类方式。因为云计算下大数据的冗余数据的分配有一定程度的难度,冗余数据的特征数值又过多,则必须使用一对一的分类方式实行云计算下大数据分布式存储中冗余数据分类的变换操作。
1.2 基于遗传算法的冗余数据最优分配算法
基于上小节获取的云计算下大数据分布式存储中冗余数据片段[10-11],本文采用基于遗传算法的冗余数据分配算法对冗余数据进行准确分类。云计算下大数据分布存储冗余数据分配流程图用图1描述,
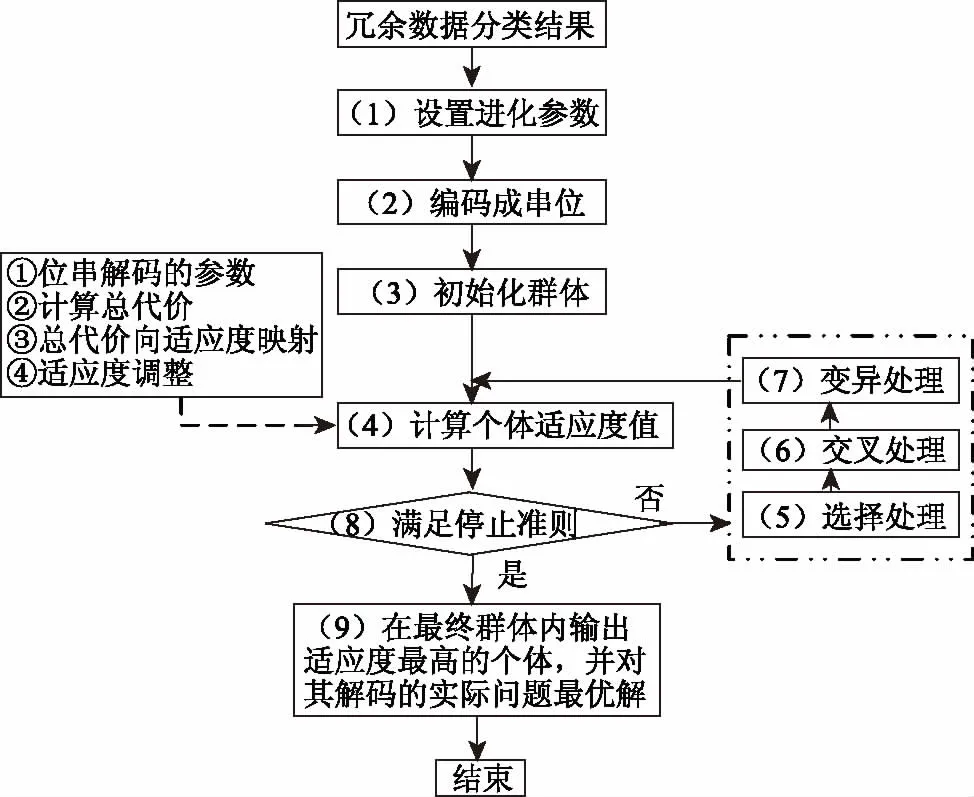
图1 云计算下大数据分布存储冗余数据分配流程图
本文针对上小节获取的云计算大数据分布式存储中某一冗余数据片段Fj的分配过程进行求解,构建分配策略和评估准则[12],获取最佳冗余数据分配策略。
代价公式是综合每项的整体信息,其可评估冗余数据的通信代价。本文使用的代价公式为:
其中,sumcost是整个数据分配策略相应的通信代价;g(y)是上小节获取的云计算下大数据分布式存储中冗余数据的分类结果,cost(Fj)是数据片段(Fj)的分配策略相应的通信代价,它的计算公式见式(7):
cost(Fj)=TQ(Fj)+TU(Fj)
(6)
其中Q以及U表示不同的事物,数据片段Fj的分配策略相应的分类、通信代价用TQ(Fj)与TU(Fj)来描述,它的计算公式为
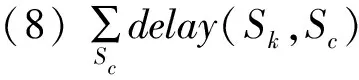
依据上述式(1)至(8)分析的云计算大数据分布式存储中冗余数据的分类结果以及分类过程,得到本文方法实现冗余数据分配策略为:
(1)设置进化参数。依据实质问题,合理设置提前给予的冗余数据进化参数,例如np与ng分别代表冗余数据群体大小与终止进化代数。
(2)编码成串位。把问题的答案,也就是某冗余数据片段Fj的分配策略根据二进制的串结构数据来描述,假如Fj被分配至站点Sk中,那么此串结构数据第k个数位中的数字是1,反之是0。因此,片段Fj总计(2m-1)种分配策略,且具有相应的不一样的通信代价cost(Fj)。若冗余数据片段数目是q,那么整体系统冗余数据分配策略体现是一个q行m列的0~1矩阵,总计(2m-1)q种,且具有相应的不一样的通信总代价sumcost。
(3)初始化群体。计算结果与效率受冗余数据初始群体的特征所干扰。基于遗传算法的冗余数据分配算法采用选育方式实行初始化[13],也称:第一步随机组成np0个个体,第二步在其中提取相应通信代价最小的np个个体构成初始种群。此处理可以保障冗余数据初始群内个体的优异水准。
(4)计算个体适应度值。使用式(7)、(8)、(9)逐次获取冗余数据群体内每个个体相应的通信代价,该代价的倒数就是此个体的适应度的数值。
(5)选择处理。基于遗传算法的冗余数据分配算法把最优储存与数据抉择综合起来实行个体选取处理。
最优保存:在子代最有个体的适应度没有父代的优秀时,根据父代最优个体代替子代最劣个体,可保障算法的收敛性。
顺序选择:为了构建相应稳定的选取流程,防止某个超级个体在种群中过大,根据个体适应度的顺序对选择概率固定化,从而让个体选择在个体间适应度差距不大的状况下可以顺利操作[14]。详细流程是:第一步计算群体内全部个体的适应度数值同时进行降序布列,个体的数目是np;第二步设置参数p0为1/np,使用公式(10)逐次计算有顺序后每个个体的选取概率。其中每个个体的序号是j。
(6)交叉处理。GA2法使用简单常数概率pc下的单点交叉可以增强算法实行效率。
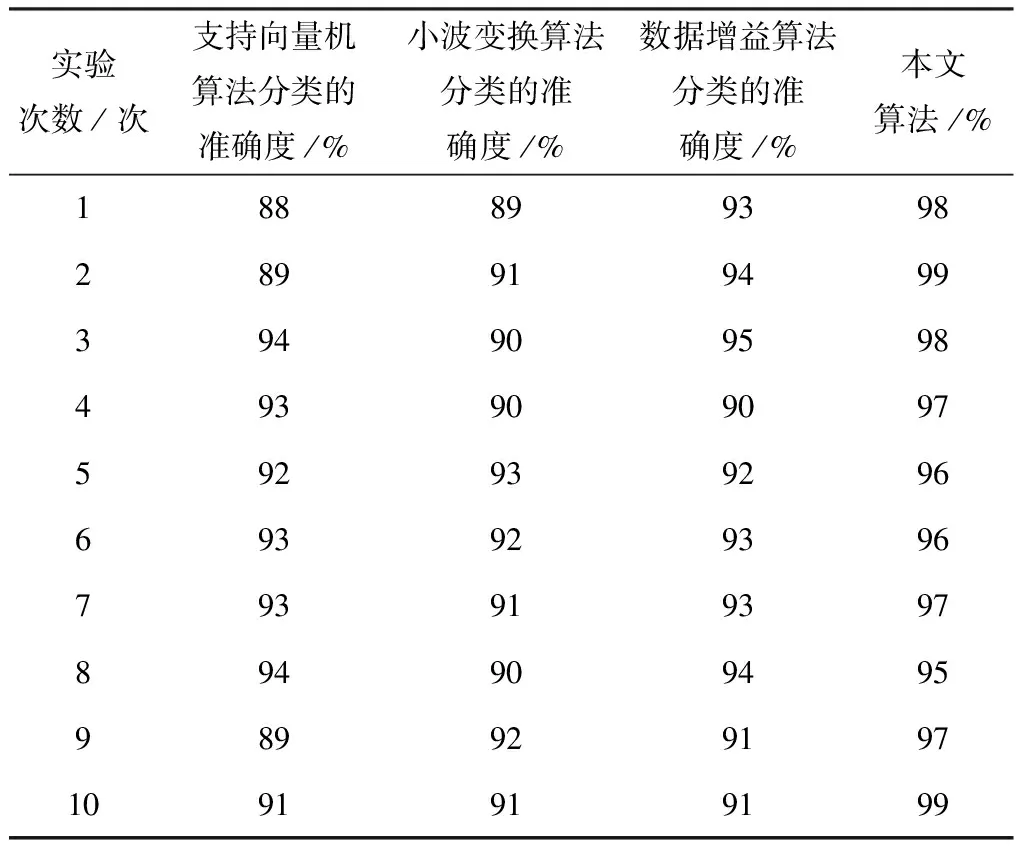
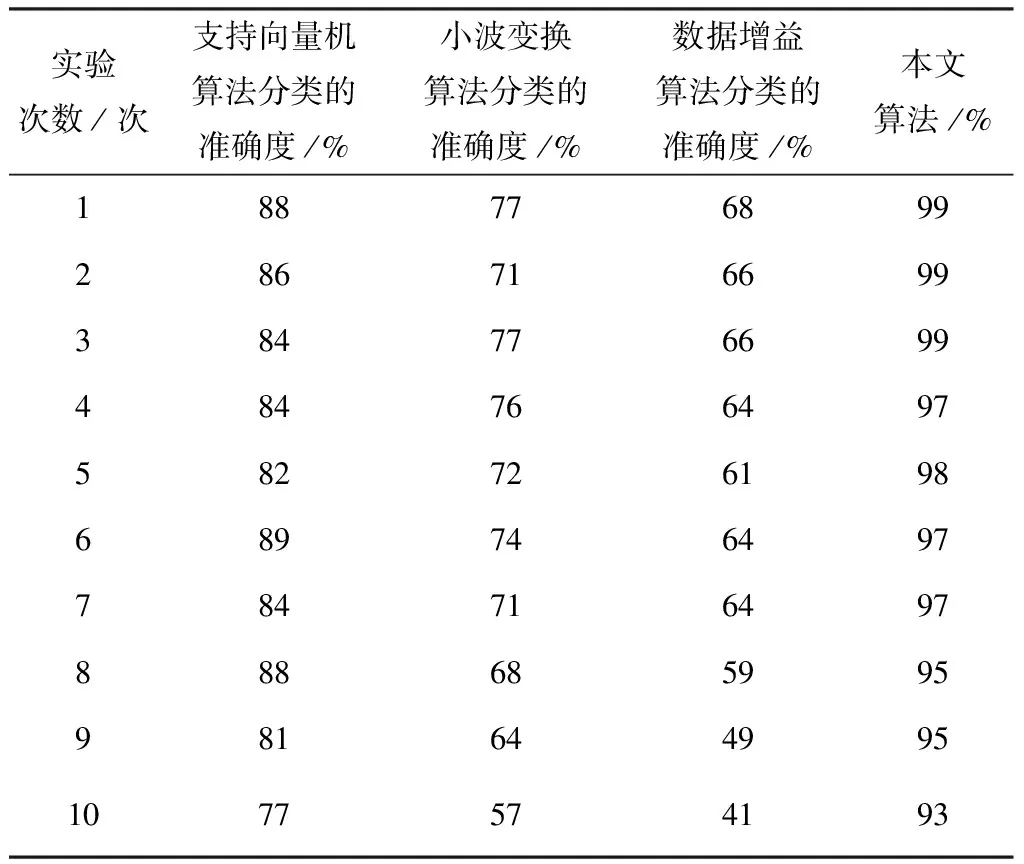
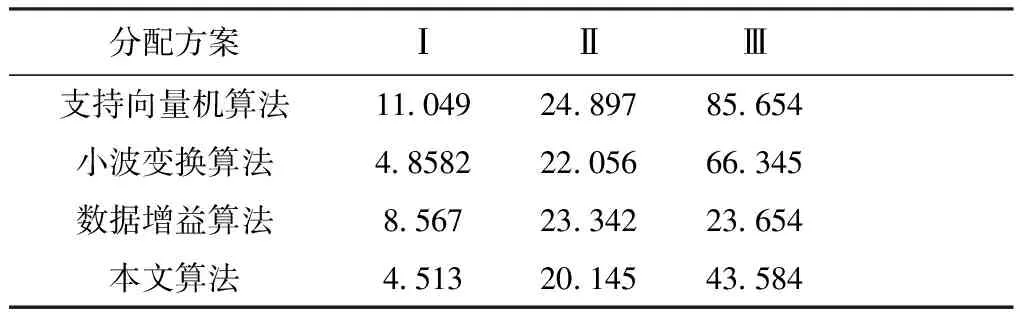
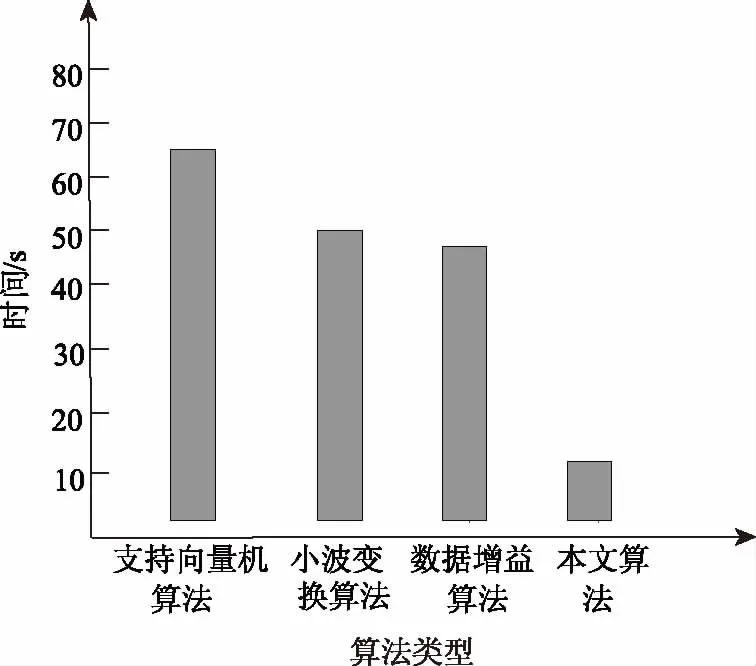
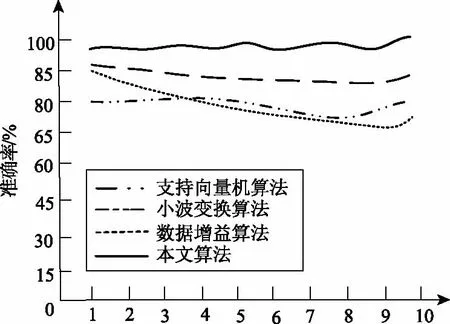
(7)变异处理。没有成熟收敛(Premature Convergence)为遗传算法内经常出现的专有的情景。由于以往的遗传算法内,想要保障算法的不出现异常,变异概率的取值一般较小,若是产生早熟收敛,会难以获取局部最优解。所以,基于遗传算法的冗余数据分配算法为了可以实时、自主的形成多个新个体,迅速提高冗余数据种群的多样性,协助种群摆脱早熟,从而获取预想的结果,使用大变异处理方法[15],受限判别某一代群体内个体的最大适应度fmax和平均适应度favg满不满足条件t*fmax 冗余数据的第gen代群体通过选择、交叉、变异等处理之后,获取(gen+1)代群体。 (8)判别满不满足停止准则。如果目前此冗余数据种群进化代数gen小于停止进化代数ng,那么回到第(5)步重新进化。否则,如果gen不小于ng,那么则会获取冗余数据的最终群体,跳入第(9)步。 (9)解码冗余数据的最终群体适应度最高的个体,获取冗余数据片段Fj的最优分配策略。 为了验证本文算法的有效性,本文使用配置了酷睿Intel i5双核@2.48 GHz,RAM为8 GB的个人电脑,使用仿真软件matlab7.1建立实验环境,进行仿真实验,设定云计算大数据分布式存储数据库内全部数据的数量为1000000个,冗余数据的种类数量是200种。 若冗余数据种类很少的状况内,使用不一样的算法实行10次冗余数据分类,把实验过程内的数据实行归纳研究,获取到的结果用表1来描述: 通过表1可以看出,当云计算下大数据分布式存储中冗余数据的种类少时,支持向量机算法、小波变换算法以及数据增益算法对冗余数据的分类准确度都没有超过95%,甚至于出现低于90%的情况出现,而本文算法的分类准确度一致保持在95%之上,本文算法在冗余数据种类少的时候分类准确度高。 表1 冗余数据种类较少时分类对比数据表 当冗余数据种类较多的状况中,使用不同算法实行10次冗余数据分类,对在实验过程内的数据实行归纳研究,获取的对比结果用表2来描述: 表2 冗余数据种类较多时分类对比数据表 由表2可知,当云计算下大数据分布式存储中冗余数据种类多时,支持向量机算法、小波变换算法以及数据增益算法对冗余数据的分类准确度都没有超过90%,且随着实验次数的增多,准确度逐渐降低,数据增益算法分类的准确度最低下跌至41%,而本文算法的准确率没有下降至93%,本文算法的分类准确度高。 本文算法可以避免由于数据库内的冗余数据间关联性差的情况出现。增强了分布式存储中冗余数据分类的效率,为接下来的冗余数据分配打下了良好的基础。 为了可以提高对冗余数据分配的效率,分配的工作站点S的数量设定为小于5,届时冗余数据分配的解空间缩小,可以直接求取最优解。综合云计算下大数据分布存储冗余数据分配流程图,假定数据片段F为6个、检索事务Q为7项、革新事务U和工作站点S10个,并且当中设定六个城市分别为S1~3(一城)、S4(二城)、S5(三城)、S6(四城)、S7~8(五城)、S9~10(六城)。设此六城处于不一样的城市的网络单元格中。单位数据在相同网络单元局域网内传递的延迟和干扰较小,同时假定本地访问的通信代价系数是0.1。根据以上设置模拟实验环境Ⅰ。 在实验时,本文算法的每项参数的值设成:群体大小np为11;停止进化代数ng是50;群体初始化时待选个体数值np0是50;交叉概率pc为0.9;大变异处理时,一般变异概率pm是0.05,大变异概率pmax为0.4,设定密集因子为t∈[0.8,0.9],同时伴随进化代数gen的增多其会减少,它的取值方法见公式(10): 本文实验环境不仅设置实验环境Ⅰ,同时还设定了站点数量是15与20的两种实验环境Ⅱ与Ⅲ进行对比实验。实验对三种不同实验环境下支持向量机算法、小波变换算法、数据增益算法与本文算法,进行云计算大数据分布式存储冗余数据分配时的总代价运算,计算结果也就是最终使用的分配策略相应的通信总代价的数目级是105,数值最小的为最佳分配方案,实验结果用表3来描述: 表3 三种实验环境下不同分配算法的总代价计算结果(105) 通过表3可知,三种分配方案的对比下,本文算法的通信总代价最小,可以得出本文算法进行云计算大数据分布式存储中冗余数据分配的成本最低。 为了进一步验证本文算法的优越性,在相同实验环境中分别采用不同算法,对云计算下大数据分布式存储中冗余数据进行分配,对四种算法的分配用时以及准确率进行对比,详情见图2与图3: 图2 相同实验环境中不用算法对冗余数据分配的用时对比图 图3 相同实验环境中相同实验次数不同算法的冗余数据分配准确率对比图 通过图2可以看出,在云计算下大数据分布式存储的相同实验环境中支持向量机算法对冗余数据的分配耗时最多接近于70 s,效率低,小波变换算法与数据增益算法的耗时相近,都接近于50 s,而本文算法耗时最低,即使经过10次实验,本文算法在对云计算下大数据分布式式存储中冗余数据分配时耗费的时间仍保持在10 s。说明本文算法在进行云计算下大数据分布式存储中冗余数据分配时用时短,效率高。 通过图3可以看出在云计算下大数据分布式存储的相同实验环境的前提下,支持向量机算法对冗余数据的分配准确率上下波动不大但是只保持在85%以内,分配准确率相对欠缺;小波变换算法对冗余数据的分配准确率随着实验次数的增多,准确率却有轻微的下降,只保持在85%上下;数据增益算法对冗余数据的分配准确率随着次数的增多明显看出在下降,准确率最低;本文算法对冗余数据的分配随着实验次数的增多基本保持平稳,始终接近于100%,说明本文算法在分配云计算下大数据分布式存储中的冗余数据时的准确率高。 本文提出云计算下大数据分布式存储中冗余数据分配算法,对冗余基本数据使用一对一的分类方式变换成二分类数据,采用最优分类平面对变换后冗余基本数据进行分类获取冗余数据片段,通过基于遗传算法的冗余数据分配算法,获取冗余数据片段的最优分配策略,实现对云计算大数据分布式存储中冗余数据的最优分配。2 实验分析
3 结 语
猜你喜欢
计算机仿真(2022年8期)2022-09-28
郑州大学学报(工学版)(2018年2期)2018-04-13
海峡姐妹(2017年12期)2018-01-31
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
作文与考试·初中版(2017年12期)2017-04-19
雷达与对抗(2015年3期)2015-12-09
中学生(2015年12期)2015-03-01
自动化博览(2014年12期)2014-02-28
舰船电子工程(2010年1期)2010-04-26
