
基于生成对抗网络的人脸热红外图像生成
2018-08-27 12:40王雅欣史潇潇
网络安全与数据管理 2018年8期
王雅欣,史潇潇
(1.中国科学技术大学 软件学院,安徽 合肥 230015;2.中国科学技术大学 计算机科学与技术学院,安徽 合肥 230027)
0 引言
热红外图像是红外传感器根据热辐射采集的图像,具有良好的目标探测能力。与可见光图像相比,热红外图像因不受光照影响具有更好的鲁棒性,近年来在表情识别研究中开始受到关注[1-3]。然而,热红外数据的采集需要昂贵的设备,与可见光图像相比获取成本高昂。因而,本文提出基于生成对抗网络从可见光人脸图像生成热红外人脸图像的方法。
传统的生成模型对机器学习来说具有不同的限制。比如,对真实样本进行最大似然估计的生成模型,严重依赖于所选取样本的分布情况;采用近似法学习的生成模型难以求得最优解,只能逼近目标函数的下界;马尔科夫链方法虽然既可以用于生成模型的训练又可用于新样本的生成,但是计算复杂度较高。随着深度学习的发展,神经网络模型在各个领域取得突破性进展[4-6]。GOODFELLOW I等人根据博弈论提出了生成对抗网络(Generative Adversarial Networks,GAN)[7],创造性地结合了生成模型和判别模型进行数据生成。但GAN的生成方式太过自由,在图片像素较多的情况下容易失控。针对这一问题,MIRZA M[8]在GAN的基础上提出条件生成对抗网络(Conditional Generative Adversarial Networks,cGAN)。而ISOLA P[9]受cGAN和文献[10]启发,将GAN的目标函数与传统损失函数相结合提出Pix2Pix方法,该方法在多种任务中有着出色的表现。
本文提出基于生成对抗网络生成热红外人脸图像的方法,与Pix2Pix[9]一样在cGAN目标函数的基础上加上传统损失函数作为惩罚项,即任务目标,惩罚项为可见图片与生成样本间的相似程度。实验在USTC-NVIE[11]库上进行,在以可见光图像为条件进行热红外图像生成的基础上,利用SVM模型进行表情识别,验证生成的热红外图片能否被模型识别以及作为扩充样本是否可以提升模型的训练效果。
1 方法介绍
1.1 网络结构
本文的网络框架如图1所示,由生成器(Generator,G)和判别器(Discriminator,D)组成。生成器使用随机噪声z在可见光图片y的约束下生成样本图片G(z,y)传递给判别器。生成的样本图片与可见光图片的L1距离被作为惩罚项反馈给生成模型,以此保证最终的生成图片与可见光图片的相似程度。判别器接收到的输入既有生成的样本图片G(z,y)也有真实的热红外图片,它的任务就是判断接收到的图片在该可见光图片y约束的情况下有多大概率是真实的。本文生成器模型采用U-Net神经网络结构,如图1中生成器G中框图所示。判别器模型则采用神经网络,其结构如图1中判别器D框图所示。

图1 本文使用的生成对抗网络框架
1.1.1生成器
本文采用U-Net结构作为生成器的网络结构。在ISOLA P提出U-Net结构前,图像到图像的转化任务中编码解码结构的使用最为广泛,其结构如图2所示。编码解码结构在编码时,使用卷积层和激活函数减少信息量。解码时则执行与编码过程相反的操作。但在数据流传递的过程中,会出现输出与输入之间信息遗失的情况。因此ISOLA P提出了U-Net生成器结构[9],其结构如图1中生成器结构所示。U-Net的结构和编码解码类似,但该结构在编解码过程的镜像层间加了跳步连接(通过复制编码层的特征图谱传递给对应的解码层实现),以此解决生成器输出输入之间信息传递的问题。
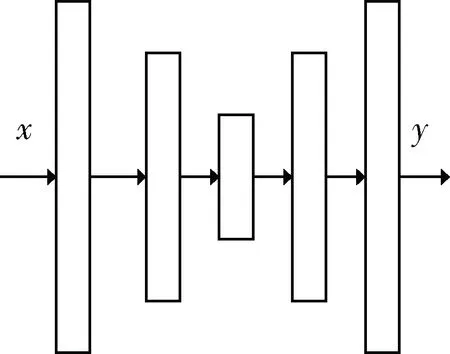
图2 编码解码器结构
1.1.2判别器
ISOLA P[9]为了追求细节的生成效果,采用马尔科夫链模型作为判别器。然而热红外人脸图像并不追求分毫毕现的效果,因此本文采用神经网络作为判别器结构,其结构如图1中的判别器所示。输入经过这个卷积神经网络输出判定该输入是真实图像的概率。
1.2 目标函数
本文的目的是通过生成对抗网络以可见光人脸图像为素材生成热红外人脸图像。考虑到同一张图的可见光图像与热红外图像的五官分布一致,而且文献[10]表明,将cGAN的目标函数和传统的目标结合可以提高生成图像的质量,因此本文在生成时还考虑生成图像与可见光图像之间的相似程度,即有条件约束的生成对抗网络,其目标函数为:
minGmaxDV(D,G)=V′(D,G)+λLL1
(1)
式(1)中V′(D,G)就是cGAN的目标函数,即不考虑生成图像与可见光图像相似程度的目标函数:
minGmaxDV′(D,G)=Ey x~pdata(x,y)[logD(x,y)]+
Ey z~ pz(z)[log(1-D(G(z,y)))]
(2)
本文将可见光图片y和生成器输出G(z,y)之间的L1距离作为两张图片相似程度的惩罚项:
式(2)和式(3)中z是随机噪声,x是目标图像,y是可见光图像,G(z,y)指生成器的输出,D(·)指判别器输出的概率。判别器的目标是最大化式(1),即maxDV(D,G),而生成器的目标是最小化式(2)的第二项与λLL1之和,其中,λ是超参数。
1.3 训练和优化
为了训练生成对抗网络,需要反复迭代多次,每次迭代需要交换固定判别器和生成器中的一个模型参数,更新另一个模型的参数。
判别器的训练过程如下:
(1)从随机噪声z中采样;
(2)对训练样本进行采样,采样的可见光图片作为条件y,对应的热红外图片作为真实数据样本x;
(3)更新判别器模型的参数;
(4)所有样本都采样过一遍后,固定判别器模型参数,开始新一轮的生成器参数更新。
生成器的训练过程如下:
(1)从随机噪声z中采样;
(2)对训练样本的可见光图片进行采样作为条件变量y;
(3)计算y与输出G(z,y)之间的L1距离;
(4)更新生成器模型的参数;
(5)所有样本都采样过一遍后,固定生成器模型参数,开始新一轮的判别器参数更新。
本文使用随机梯度下降法进行参数优化,进行足够多次交替训练的迭代之后,停止训练。
2 实验条件及结果分析
2.1 实验条件
本文在USTC-NVIE[8]数据库上进行实验,该数据库在左、中、右三种光源下,共收集了126名志愿者6种基本面部表情(高兴、悲伤、惊喜、恐惧、愤怒和厌恶)的可见光和热红外图像。
在进行实验之前,需要对图片进行预处理。使用haar级联特征对可见光图像进行人脸定位和截取;对热红外图像则使用大津法(OSTU)和垂直投影曲线进行人脸定位和截取。最终,截取了1 051对有表情的可见光人脸图像和热红外人脸图像对以及980对无表情的可见光和热红外图像对,并调整所有图像的大小为256×256。本文将成对的可见光人脸图像和热红外图像称为一个样本。
2.1.1对照实验设置
本文设置了3组对照模型进行效果对比,加上本文提出的模型,共4组模型,都采用神经网络作为判别器,但生成器结构和目标函数各不相同。为了方便表述,后文称公式(2)为目标函数Ⅰ,称公式(1)为目标函数Ⅱ;以编码解码为生成器结构的生成框架为网络结构I,以U-Net为生成器结构的生成框架为网络结构II。则本文的4组实验模型分别是网络结构I目标函数I、网络结构I目标函数II、网络结构II目标函数I以及本文提出的方法网络结构 II目标函数II。
本文使用的判别器神经网络如图1中的判别器框架所示,所有卷积核大小都为4×4,除最后一层的步长为1,使用Sigmoid激活函数输出概率,其他卷积层的步长都为2,都使用LeakyReLU作为激活函数并且都需要进行批量正则化(Batch Normalization, BN)。
对于两种生成器网络结构,除了跳步连接的差别外,所有卷积层的卷积核大小都为4×4,步长都为2,都使用ReLU函数作为激活函数,并且都需要进行批量正则化。从输入开始各编码层的输出通道数为32→64→128→256→512→512→512→512,编码之后一直到输出的各解码层的输出通道数为512→512→512→ 512→ 256→128→64→32→3。
设置的4组模型除进行生成实验外还进行表情识别实验。
2.1.2生成实验条件
生成实验中,数据集被分为训练集、验证集和测试集。其中,训练集有1 222个样本,包含了全部的980对无表情图片和242对有表情图片。验证集和测试集样本则都是有表情的图片,分别有384个样本和425个样本。
为了评估测试集的目标图片和生成图片的差异,本文使用高斯Parzen窗[12]作为衡量标准。
2.1.3识别实验条件
为了验证生成图像能否被模型识别,本文使用SVM作为识别模型,以生成实验的训练集和验证集中的热红外图像为训练集,总共有1 606幅热红外图像。训练SVM模型分别识别测试集的生成图像和原本热红外图像(目标图像)的表情标签。
最后,为了验证生成图片作为扩充样本的效果,仍使用SVM模型,除了生成实验的训练集和验证集外,再加入213幅生成的图像,总共1 819幅热红外图像作为训练集。剩下的212幅生成图像的目标图像作为测试集。
2.2 实验结果和分析
2.2.1生成实验结果
图3为一个样本的可见图像、生成的红外图像及其目标图像的示例。对比4种模型的生成图片与目标图片可以发现,本文提出的模型(网络结构II目标函数II)的生成图片与目标图片更相似。表1是生成图片与目标图片基于Parzen窗的对数似然估计,结果表明本文提出的方法的生成图片(图3(e))与目标图片更相似。结合表1的结果以及图3的成像效果考虑,生成效果还是比较令人满意的。

图3 可见光图像、生成的红外图像及其目标图像样例

模型似然估计网络结构Ⅰ 目标函数Ⅰ66 020±87网络结构Ⅰ 目标函数Ⅱ65 074±82网络结构Ⅱ 目标函数Ⅰ65 997±93网络结构Ⅱ 目标函数Ⅱ64 654±84
2.2.2识别实验结果
表2是使用SVM模型识别生成图片的实验结果,实验结果表明生成的图片可以被识别模型识别,并且与目标图片被识别的效果相似。本文提出的方法(网络结构II目标函数II)的准确率是所有生成图片中最高的。

表2 识别生成图像与目标图像结果
表3分别是没有进行样本扩充与使用生成图片作为扩充样本训练的模型对真实热红外图像的识别结果。实验结果表明生成的图片作为扩充样本对模型识别效果的提升起了积极的作用。与没有扩充样本的模型相比,四组扩充训练集样本的模型,识别准确率分别提升了1.28%、2.7%、1.97%以及3.24%。训练集只进行了12.36%的扩充,提升效果令人满意。由此可见使用生成对抗网络生成图片可以作为扩增样本提升模型训练效果。四组扩充识别实验中,本文提出的方法(网络结构II目标函数II)生成的图片作为扩增样本训练效果最好。

表3 样本扩充后的表情识别结果
综合生成实验以及识别实验可以发现本文提出的方法比其他模型的结果更好。如果分别观察各组实验的网络结构和目标函数,可以发现不论是生成实验还是识别实验,目标函数相同的情况下,使用U-Net的(网络结构II)模型,实验结果都比使用编码解码器(网络结构I)的结果要好。而网络结构相同的情况下,使用目标函数II的结果都比使用目标函数I的结果要好。综上所述,本文所提方法表现出的优越性是来自模型结构以及目标函数的双重作用。
3 结论
为了解决近年来备受研究关注的热红外图像采集困难的问题,本文提出采用条件生成对抗网络结合L1损失从可见光图像中生成热红外图像的方法。USTC-NVIE库上的实验结果表明,生成对抗网络框架可用来从可见光图像生成热红外图像,并且生成的图片作为扩充样本可提升模型训练的效果。
猜你喜欢
环球时报(2022-05-23)2022-05-23
金桥(2021年4期)2021-05-21
中学生数理化·高一版(2021年2期)2021-03-19
电子制作(2019年7期)2019-04-25
电子制作(2019年7期)2019-04-25
知识经济·中国直销(2018年8期)2018-08-23
数学学习与研究(2017年3期)2017-03-09
系统工程与电子技术(2016年7期)2016-08-21
系统工程与电子技术(2016年7期)2016-08-21
中国老区建设(2016年1期)2016-02-28
