
基于粒子群优化的模糊C均值聚类算法*
2018-08-27 12:59:40王宇钢
网络安全与数据管理 2018年8期
王宇钢
(辽宁工业大学 机械工程与自动化学院,辽宁 锦州 121000)
0 引言
随着大数据、云计算等技术的迅猛发展,聚类分析已成为数据挖掘的主要研究手段之一。为符合人类的认知,研究员将模糊集理论引入聚类分析中,提出了模糊C均值聚类算法(Fuzzy C-means Clustering Algorithm,FCM)。经典FCM 算法由于是一种局部最优搜索算法,存在对初始聚类中心敏感、易于陷入局部最优解的缺陷,限制了算法的应用[1-2]。因此,学者尝试通过各种智能算法对经典FCM 算法进行改进。粒子群优化算法(Particle Swarm Optimization, PSO)作为群体智能算法的代表,依靠个体之间的简单交互作用在群体内自组织搜索,具有很强的学习能力和适应性[3]。一些学者利用PSO算法克服传统FCM算法的缺陷,将PSO算法与FCM算法融合已成为近年来的研究热点[4]。
文献[5]针对FCM算法用于高维数据样本聚类时效果较差的不足,提出一种基于粒子群的FCM聚类算法。该算法在满足FCM算法对隶属度限制条件的前提下,根据样本与聚类中心间距离重新分布了隶属度,并通过比较样本与各聚类中心距离加速最优粒子收敛。文献[6]对初始聚类中心和模糊加权指数进行粒子编码,通过粒子群优化算法搜索最优的适应度值及模糊加权指数,经人工数据集与UCI数据集实验,证明该方法比传统的FCM算法和粒子群聚类算法的聚类准确性和稳定性都有提高。文献[7]将基于直觉模糊的粒子群算法(IFPSO)和FCM算法混合,利用犹豫度属性参数寻找目标函数与聚类中心的相似性,对高维数据集进行聚类分析取得较好效果。文献[8]提出一种基于惯性指数权重的粒子群聚类算法(ACL-PSO)。将改进的PSO算法与FCM算法相结合,改善FCM算法易于陷入局部最优解的缺陷,对UCI数据库中标准数据集进行测试,结果显示了该算法的有效性。
为克服FCM算法缺陷,提高聚类质量,本文对基本粒子群聚类算法进行改进,并与FCM算法结合,提出了一种改进的粒子群优化模糊C均值聚类算法(Improved Fuzzy C-mean Clustering Algorithm Based on Particle Swarm Optimization,IFCM-PSO)。首先通过选择合理的粒子初始化空间,降低对初始聚类中心的敏感度,提高收敛速度;其次通过优化参数粒子运动最大速度以及引入环形拓扑结构的邻域,解决粒子群聚类算法易早熟收敛的缺陷。选取UCI 数据库中3 个真实数据集IRIS、WINE和Breast Cancer Wisconsin (BCW)进行仿真实验,以验证该算法的有效性。
1 模糊C均值聚类算法(FCM)
分为L个类簇的数据样本集合X={x1,x2,…,xn}∈Rp,n为样本个数,p为样本空间维数,L介于2~n之间。FCM算法采用误差平方和函数作为目标函数,其定义式为:
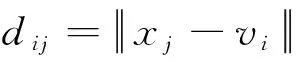
隶属度uij应满足约束条件:
FCM算法是以误差平方和为准则函数的一种逐点迭代聚类算法。通过式(2)和式(3)迭代计算隶属度矩阵U和聚类中心V,使目标函数J(U,V)的取值不断减小。当准则函数会聚时,获得数据样本的最终聚类结果,即模糊划分后的隶属度矩阵U和聚类中心V。
2 基本粒子群聚类算法
2.1 粒子群优化算法
在粒子群优化算法中,每个粒子si抽象为一个个体,种群就是由这些粒子构成的,所求问题的解就是粒子在空间中的最优位置。在每次迭代计算过程中,根据所有粒子的适应值评价每个粒子的极值当前最优位置pi和群体全局最优位置g。依靠两个位置极值,粒子更新其移动速度和位置,直至收敛到空间位置的最优解。
目前普遍采用的粒子速度和位移更新形式为:
vi=ωvi+c1r1(pi-si)+c2r2(g-si)
(5)
si=si+vi
(6)
其中,c1、c2为学习因子,一般取c1=c2;r1、r2是[0,1]之间的随机数;w为惯性权重,取值限定在[wmin,wmax]之间。在迭代过程中,惯性权重通常采用线性递减方式由最大值变为最小值,即:
w=wmax-iter×(wmax-wmin)/itertotle
(7)
其中,iter为当前迭代次数,itertotle为最大迭代次数。
2.2 FCM-PSO算法
为了实现传统聚类方法缺陷的突破,研究人员尝试将粒子群优化算法与传统聚类算法相结合,通过PSO算法的全局寻优能力和分布式随机搜索特性解决传统聚类算法易陷入局部最优和对初值敏感的问题。将聚类作为一种优化问题实现对数据集的近似最优划分。基本粒子群聚类算法的流程如下:
(1)给定聚类的数目,初始化聚类中心矩阵,并赋值给各个粒子,随机产生粒子的初始速度。
(2)对每个粒子计算隶属度,更新所有的聚类中心,计算各个粒子的适应值,更新个体极值。
(3)根据各个粒于的个体极值,找出全局极值和全局极值位置。
(4)根据粒子群优化算法的速度公式更新粒子的速度,并把它限制在最大速度内。
(5)根据粒子群优化算法的位置公式更新粒子的位置。
(6)若不满足终止条件,返回步骤(2)继续迭代计算;若满足终止条件,则输出最优粒子的位置即最优分类中心矩阵。
目前,将FCM算法与PSO算法相融合的聚类算法(Fuzzy C-Mean Clustering Algorithm Based on Particle Swarm Optimization,FCM-PSO)已成为基本粒子群聚类算法的一种主要研究形式[9]。该方法将每个粒子表示为一种聚类中心的选取方式,应用FCM算法的目标函数计算各粒子的适应值,作为对应聚类中心聚类效果的评判依据,算法收敛后输出粒子的全局最优位置,即最优聚类中心。
3 改进的粒子群优化模糊C均值聚类算法
3.1 粒子群聚类算法的改进
(1)PSO算法通常将粒子初始值均匀分布于[0,1]之间,而非在粒子的最优解的附近空间,这将使粒子搜寻最优解的迭代时间增加,聚类的效果变差[10]。本文将样本聚类中心作为种群个体,因此粒子的最优解空间即为样本的分布空间。将粒子的初始位置随机分布于取值范围[Xmin,Xmax],Xmin、Xmax分别为样本每维最小值和最大值组成的向量。这样初始化的粒子在接近最优解的搜索空间开始进化运算,可有效缩短收敛时间,提高聚类质量。
(2)最大速度vmax决定粒子在一次迭代计算中的最大移动距离,vmax过大则易使粒子错过最优解,过小则会使粒子易陷入局部最优解。因此,通常将粒子最大速度设为一个常数。然而,在样本各维取值存在较大量纲差异时,由于各维空间取值范围不同,将粒子的vmax在样本各维空间均设定为一个常数,显然易出现错过最优解或陷入局部最优解的情况,结果影响算法的全局收敛性。本文对粒子在样本空间每一维都定义一个最大速度,最大速度vmax根据样本每维变化的取值范围设定。
vmax=λ(Xmax-Xmin)
(8)
其中,λ为常数。
(3)在实际应用中,PSO算法仍易出现早期迭代震荡及早熟收敛的情况。因此,研究人员尝试使用局部邻居的概念,将邻域也作为粒子进化的一个调节源,降低早熟收敛情况的发生概率。
在PSO算法中,粒子群的信息共享范围即为粒子的邻域拓扑结构。环形邻域拓扑结构使用局部邻居的概念,每个粒子只与最近的邻居沟通,较好地协调粒子本身和群体之间的关系。本文通过引入环形拓扑结构邻域改善PSO聚类算法性能。在初始阶段,邻域就是每个粒子自身,随迭代次数增加,每个粒子只与最近邻居沟通,邻域逐步扩展到包含所有粒子[11]。新的速度更新策略调整为:
vi=ωvi+c1r1(pi-si)+c2r2(g-si)+c3r3(pl-si)
(9)
其中,pl为粒子邻域极值。
3.2 改进的粒子群优化模糊C均值聚类
综上分析,本文提出的IFCM-PSO算法将聚类中心作为种群中粒子的位置,将FCM算法目标函数作为适应函数,终止条件为最优粒子目标函数适应值变化量小于阈值或迭代次数达到设定值itertotle,算法归纳如下:
(1)设定聚类初始参数:聚类数,种群数,最大速度系数,迭代误差。
(2)在取值范围[Xmin,Xmax]内初始化聚类中心矩阵,并赋值给各粒子。
(3)根据式(1)计算初始种群中每个个体的适应值。
(4)根据公式(9)计算粒子移动速度,根据公式(6)更新粒子的位置。
(5)计算种群中个体粒子的适应值,若满足终止条件, 则将粒子全局最优位置作为最优解输出;否则返回步骤(3)继续迭代计算。
4 实验与结果分析
为了验证算法的性能,选择来自机器学习数据库UCI中的3个真实数据集进行实验,分别为IRIS、WINE和Breast Cancer Wisconsin(BCW)。以上3个数据集经常被用于测试聚类算法的有效性,数据集的详细信息如表1所示。

表1 数据集信息
4.1 算法有效性测试
对选择的3个数据集分别采用FCM算法、FCM-PSO算法以及本文的IFCM-PSO算法进行聚类仿真实验。实验参数为:FCM-PSO算法的粒子种群数为20,最大迭代次数为500,最优解改变量阈值为0.001;IFCM-PSO算法的粒子种群数为20,允许的最大速度系数λ=0.15,最大迭代次数为100,最优解改变量阈值为0.001。数据集分别对3种算法进行10次仿真运算,各指标为10次计算的平均值,聚类结果如表2所示。

表2 数据集聚类结果
由表2可知,对3个数据集,FCM算法迭代次数最少,表明收敛最快,但由于自身算法的缺陷使得聚类准确率较差;FCM-PSO算法对IRIS和BCW两个数据集的聚类准确率较FCM算法高,但在3种算法中迭代次数最多,收敛速度最慢;本文的IFCM-PSO算法对3个数据集在迭代100次后均获得了最高的准确率,表明该算法在聚类速度和准确率方面的综合性能最好。
4.2 算法结果分析
对应3个数据集,FCM算法、FCM-PSO算法和IFCM-PSO算法各选取与聚类结果平均值最接近的一次聚类运算目标函数迭代曲线进行分析,目标函数值迭代曲线如图1所示。
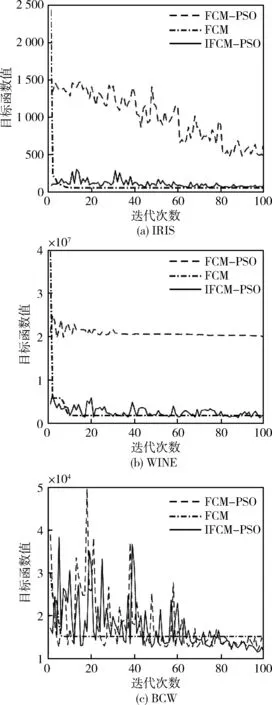
图1 目标函数值迭代曲线图
由图1(a)可以发现,对IRIS数据集聚类时,FCM算法函数值下降迅速,很快收敛;FCM-PSO算法目标函数值在迭代100次后仍震荡,未见明显收敛;而IFCM-PSO算法由于初始化取值接近最优解,收敛较快,目标函数值最小。
图1(b)显示,对WINE数据集,FCM算法很快收敛,FCM-PSO算法迭代约30次后收敛,但目标函数未见明显下降,表明出现早熟收敛;IFCM-PSO算法在迭代100次后基本收敛,目标函数值与FCM算法目标函数值接近。
图1(c)显示对Breast Cancer Wisconsin数据集虽然FCM-PSO算法和本文的IFCM-PSO算法均出现震荡,但最终本文的IFCM-PSO算法震荡幅度较小,收敛效果更好。
通过以上3种算法对应3个数据集的目标函数曲线比较可以发现:本文的IFCM-PSO聚类算法由于在聚类初始化取值、最大速度取值方面进行了改进,并引入了环形邻域辅助进化,使该算法有效克服了FCM算法对初始值敏感、易陷入局部最优解及基本粒子群聚类算法迭代初期震荡、早熟收敛的问题,因而获得了最好的聚类效果。
5 结束语
本文针对模糊C均值聚类算法存在的主要问题,利用改进的粒子群聚类算法,提出了一种基于粒子群优化的模糊C均值聚类算法。通过对粒子初始化空间和粒子运动最大速度两个参数的优化设置,并引入环形拓扑结构的邻域,提高了粒子群聚类算法的聚类效果。仿真结果表明该算法在聚类准确性和收敛速度方面均优于模糊C均值聚类(FCM)算法和基本粒子群聚类(FCM-PSO)算法。
猜你喜欢
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
测控技术(2018年10期)2018-11-25 09:35:54
自动化学报(2018年7期)2018-08-20 02:59:04
浙江工业大学学报(2017年5期)2018-01-22 02:03:46
电子测试(2017年15期)2017-12-18 07:19:27
周口师范学院学报(2016年5期)2016-10-17 06:36:47
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
华东理工大学学报(自然科学版)(2014年2期)2014-02-27 13:48:48
华东理工大学学报(自然科学版)(2014年2期)2014-02-27 13:48:48
