
基于堆栈降噪自编码器改进的混合推荐算法
2018-08-27 10:54:10杨帅,王鹃
计算机应用 2018年7期
杨 帅,王 鹃
(1.国家多媒体软件工程技术研究中心(武汉大学 计算机学院),武汉 430072;2.空天信息安全与可信计算教育部重点实验室(武汉大学 计算机学院),武汉 430072)(*通信作者电子邮箱shuaiyy2358@whu.edu.cn)
0 引言
随着互联网电子商务和多媒体社交网络的发展,信息呈爆炸式增长,信息过载问题愈发严重,用户需要高效的获取信息方式,商业公司也希望能够定位目标用户并向其推荐产品或服务,因此推荐系统被广泛应用,为用户提供个性化推荐。现有的推荐算法模型可以分为三类:基于内容的推荐、协同过滤推荐和混合过滤推荐。基于内容的推荐算法使用用户信息或项目内容作为推荐依据;基于协同过滤的推荐算法利用了用户的历史行为偏好,如用户对项目的评分,仅考虑了用户、项目间的联系,没有利用用户或项目内容;混合推荐算法则是将上述二者结合[1]。
基于内容的推荐算法由于没有考虑用户的历史偏好,推荐精度不高,且利用用户个人信息将会涉及隐私问题,随着隐私保护意识的提高,收集用户个人信息的难度也不断加大。基于协同过滤的推荐算法在用户评分数据稀疏时性能很低,且也没有利用关于项目内容的有价值信息,因此将二者结合的混合推荐算法逐渐成为主流[2-3]。
混合推荐算法分为两个步骤,从项目内容中提取特征,然后利用特征和用户历史偏好进行协同过滤推荐[4]。如果项目内容仅通过处理一次,就作为特征提供给协同过滤模型(Collaborative Filtering Model, CFM),推荐性能往往较低,因为信息流是单向的,没有评分信息作为特征有效性的反馈,在这种情况下提高推荐性能只有依靠人工编辑或复杂的特征工程[5]。依据有监督的机器学习思想,在提取项目内容特征时,利用评分信息进行反馈,可以提高特征的质量,而高质量的项目特征,能够大幅提高CMF的预测能力[6]。
如何从项目内容中提取有效特征,成为提高混合推荐算法性能的关键因素。目前深度学习在自然语言处理领域应用广泛,如机器翻译、社区问答、情感分析、信息提取等都已实现商用。当前将深度学习应用到推荐系统中的研究才刚刚起步,算法尚无法准确理解书籍、电影内容,并从中提取有效特征,但是从用户原创内容(User-Generated Content, UGC)如评论、标签等中提取有关项目内容的特征却是可行的[7]。在已有的研究中,国内的张敏等[8]提出的语义增强的隐因子模型(Semantics Enhanced Latent Factor Model, SELFM),利用堆栈降噪自编码器(Stacked Denoising AutoEncoder, SDAE)提取商品评论文本特征,实现评论与评分结合,提高评分预测的准确性;国际上的深度协同推荐模型(Collaborative Deep Learning for recommender system, CDL)[9],将SDAE算法贝叶斯化,实现概率化的矩阵分解模型,预测用户对商品评分的数学期望,同时利用商品描述信息提高模型性能;基于自然语言模型正则化的隐因子推荐模型(Language Model regularized Latent Factor model,LMLF)[10],利用循环神经网络模型长短期记忆(Long Short-Term Memory, LSTM)网络与CMF结合,根据评论文本的词概率分布,计算不同评论文本的似然度,并将其作为CMF的补充推荐依据。上述3种算法模型中,CDL利用的是固定的项目内容描述或分类信息,无法反映不同个体间的兴趣偏好。SELFM和LMLF虽然利用了用户评论信息,但是评论信息的质量和内容相关度会严重影响推荐算法的精确度,在没有人工编辑干预的情况下性能并不理想。在实际应用中,在线商品评论系统中往往有大量的无效评论,包括内容无关的用户情感表达和恶意的刷评信息等,而在线标签系统中,用户出于追溯、管理、分享、检索信息等目的,为感兴趣的项目打上的自由文本标签,内容相关性较高,是提取项目内容特征的有效信息源[11-12]。
综上所述,利用深度学习对项目内容进行特征提取并用于推荐的混合推荐算法,已经是相关研究领域的趋势所在。在真实应用场景下,用户评论数据质量较低,难以从中提取有效项目特征。针对这些问题,本文提出基于SDAE算法改进的混合推荐(SDAE-based improved Hybrid Recommendation, SDHR)算法,通过SDAE深度模型从标签中抽取项目内容特征,并将项目特征作为隐因子模型(Latent Factor Model, LFM)的显式特征,将深度学习算法与传统的协同过滤算法相结合,提高推荐算法的性能。
1 相关理论
1.1 自编码器理论基础
自编码器(AutoEncoder, AE)是最简单的人工神经网络模型,仅包含一个隐含层,广泛用于样本特征提取。AE的网络结构如图1所示,样本数据x经过编码器函数f编码得到编码特征y,x和y满足式(1):
y=fθ(x)=s(Wx+b)
(1)
其中:s为神经网络激励函数,一般使用非线性函数如sigmoid函数;θ={W,b}为参数集合。然后通过式(2):
(2)
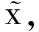
(3)
通过不断修正参数θ和θ′,使得平均重构误差L最小,此时得到的y就可以认为保留了原始样本的大部分信息,即样本x的等价特征。
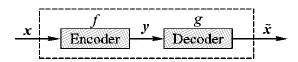
图1 AutoEncoder网络结构
1.2 降噪自编码器
当仅保留原始输入数据的信息时,AE无法保证学到有效的特征表示,比如在极端情况下,AE只需使用恒等函数就能实现输入数据的完美重构,因此需要给予AE一定的约束以使其学到比输入数据更好的特征表示。降噪自编码器(Denoising AutoEncoder, DAE)算法是在AE的基础上,随机丢弃输入向量x中的某些元素,得到腐蚀的输入数据x′,然后利用x′恢复输入向量x,得到重构输入z。DAE的主要思想是“一个好的特征能够从一个腐蚀输入鲁棒地得到,并且能够恢复出未腐蚀的输入”,DAE能够减输入样本中无效特征的干扰[13],DAE的优化目标如下:
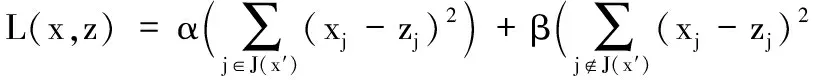
(4)
其中:α为腐蚀维度重构代价权重,β为未腐蚀维度重构代价。
1.3 SDAE深度模型
由于一层DAE网络的编码能力有限,SDAE将多个DAE堆叠在一起组成深度学习架构,用于处理超大规模的数据集,挖掘输入样本的深层特征[14]。SDAE网络模型如图2,第i层DAE的输出作为第i+1层的输入,最后一层DAE的输出作为原始输入的重构数据。
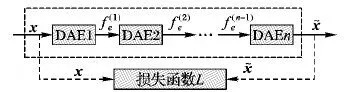
图2 SDAE网络结构
1.4 隐因子矩阵分解
隐因子矩阵分解(Latent Factor Model, LFM)在基于协同过滤推荐算法中应用广泛,其目标是将用户-项目评分矩阵Rm×n降维分解,得到用户-特征关注矩阵Un×k和项目-特征质量矩阵Vk×m(k为隐因子特征空间维度,ui表示用户i对k种特征的喜爱程度,vj表示项目j包含k种特征的程度),如果LFM能够在已有的用户评分数据上使得:
Rn×m≈Un×k·Vk×m
(5)
那么通过ui*vj计算得到的评分rij,就可以作为用户i对项目j预测评分,因此LFM的优化目标函数为:
(6)
基于LFM的协同过滤算法在评分数据稀疏时容易过拟合,且隐因子空间维度k无实际语义,可解释性差,无法反映项目的真实特征[16]。
2 SDHR算法描述
2.1 SDHR框架
SDHR算法框架如图3所示,框架由2部分组成:基于SDAE的项目特征提取模型和基于LFM的协同过滤推荐模型。在特征提取部分,通过SDAE算法从自由标签文本中提取项目特征。对原始的SDAE算法加以改进,加入一个softmax分类器用于项目预测评分,并引入项目评分作为特征有效性反馈,参与SDAE网络微调。在协同过滤部分,改进LFM算法,使用SDAE网络的输出编码特征矩阵替换LFM中的项目隐因子特征矩阵,将项目-特征质量矩阵由隐因子空间转换为显因子空间。
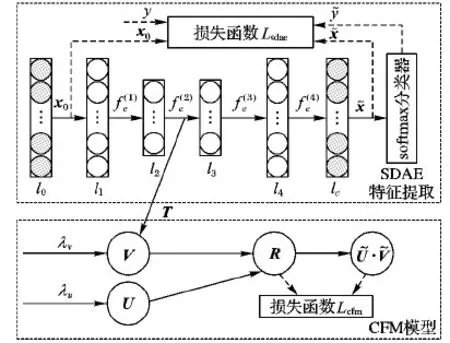
图3 SDHR框架结构示意图
2.2 改进的SDAE特征提取
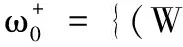
由于SDAE网络本身无法实现评分预测,故SDAE提取的特征无法反映用户对项目的喜爱偏好。为了充分利用评分信息提高特征质量,在最后一层DAE网络后添加一个softmax分类器,将标签特征分为5个类别,对应项目的5分制评分,预测评分和真实评分数据将参与网络参数的整体微调,此时的优化目标需在式(3)的基础上作出相应的调整:
(7)
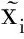
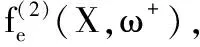
(8)
2.3 改进的CFM
为了提高项目特征的质量和可解释性,项目-特征质量矩阵V不直接使用LFM从评分矩阵中分解,而是由SDAE模型提取的项目特征矩阵T计算得到。由于特征矩阵T是SDAE模型从项目的语义标签中提取而来,因而能够反映项目的真实特征。为了解决稀疏数据上的过拟合问题,在式(6)的基础上引入L2范数作为过拟合惩罚项,由此得到改进后CFM的优化目标函数:
(9)
其中λ1、λ2为过拟合惩罚因子,V为:
V=w·T+b
(10)
1)参数初始化,取wjk=0.1,bjk=0.001,如果用户i没对项目j评分,则令Rij=0,bjk=0;假设用户对项目的真实评分与算法预测评分的差值服从高斯分布,在此基础上使用服从N(0,1)的高斯分布随机数初始化用户-特征关注矩阵Um×k;超参数λ1=λ2=0.1,α=0.1,ξ=e-9,其中λ1、λ2为正则项系数,α为梯度下降的学习步长,ξ为停止参数更新的阈值,超参数的取值应在不同的数据集下由调参决定(调参过程在实验部分给出)。
2)确定损失函数梯度,即Lcfm对U、V的偏导数:
(11)
(12)
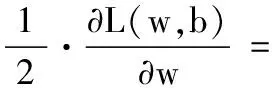
(13)
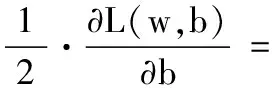
(14)
式(11)、(13)、(14)里有三组参数需要优化:U、w和b。
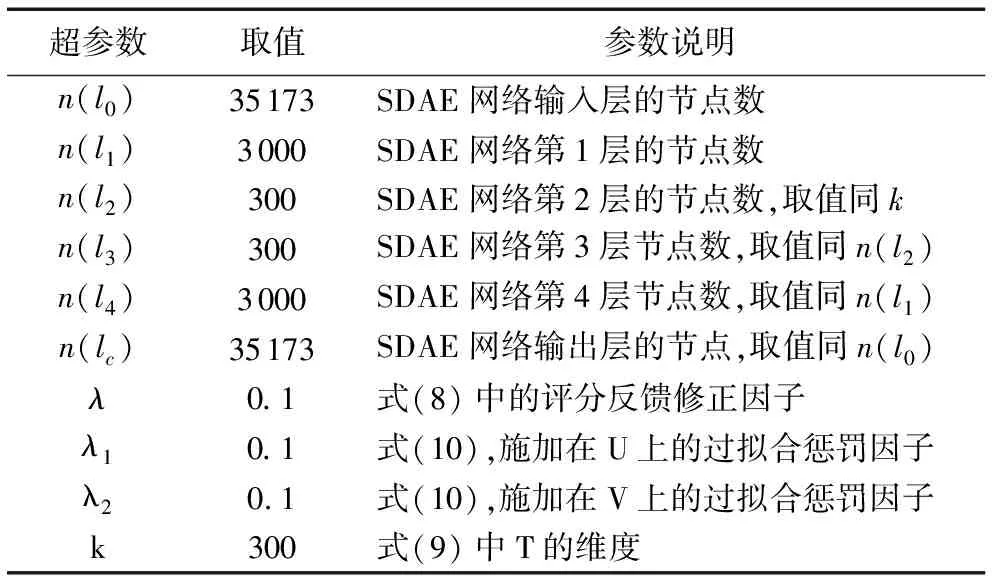
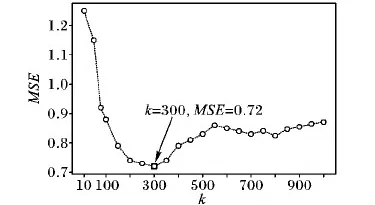
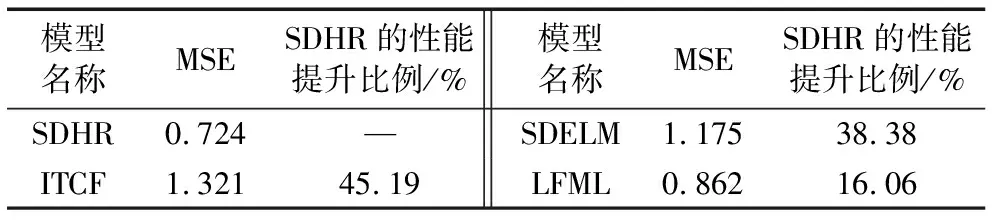
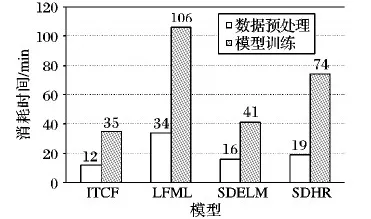
3)对于每一个用户i和项目j(0 当所有的Uik、wjk、bjk都更新一次后,重复执行步骤3),进行新一轮的参数更新,直到算法收敛退出。 对于给定的观测数据集,利用ui、vj、xij计算预测评分rij,结合式(8)、式(10),可得: (15) 3.1.1 实验环境和数据集 实验编程环境为Python 3.5,深度学习计算框架为TensorFlow 1.4,系统OS为Windows 10,8 GB RAM,GPU GTX1080。 实验采用的数据集为开源数据集MovieLens,该数据集收集了Movielens(类似豆瓣电影的电影推荐网站)上138 493个用户对27 278个电影的20 000 263条评分、465 564个标签,评分为5星制,取值1~5,标签为自由文本词汇。该数据集的评分稀疏度为1-20 000 236/(138 493×27 278)≈0.994 71,可以看出数据非常稀疏。 采用10折交叉验证法(10-fold cross-validation)[18]评估算法性能,将MovieLens数据集随机分成10组互斥的子集,每次选择其中1组作为测试数据集,其余9组作为训练数据集,重复10次测试算法,确保每个数据都参与且仅参与一次测试,最后取10次测试结果的平均值作为实验结果。 3.1.2 评价标准和对比模型 采用均方误差(Mean Square Error, MSE)和Top-K推荐精度(K-precision)作为衡量算法性能的标准。 1)MSE。对于给定的测试数据集,用户对项目的评分集合R={r1,r2,…,rn},推荐算法计算得到的预测评分集合P={p1,p2,…,pn},则有: (16) 2)K-precision。在给定的测试数据集上,算法计算用户u在项目集合J上的预测评分,并将评分最高的前k个项目推荐给该用户,记推荐集合为Pre(k|u;J),用户真实评分的Top-K集合记为Real(k|u;J),则Top-K推荐精度定义为: (17) 本次实验使用了3组对比模型,基于标签改进的协同过滤算法(Improved Collaborative Filtering algorithm based on Tags, ITCF)[19]、基于SDAE及极限学习机的协同过滤推荐模型(collaborative filtering model based on Stacked Denoising autoencodes and Extreme Learning Machine, SDELM)[20]和LMLF。其中文献[19]提出的ITCF模型是在传统的协同过滤算法基础上引入标签词频动态权重,本质上仍是一种浅层模型(Shallow Learning);SDELM和LFML属于深度模型,文献[20]提出的SDELM使用SDAE提取特征,并使用极限学习机和最近邻算法预测评分,文献[10]提出的LMLF模型使用LSTM分析文本词汇概率分布,计算不同文本的似性度,并将似然度作为推荐参考依据。 3.1.3 数据预处理和SDHR模型超参数 需要将原始训练数据表示为向量形式,才能参与SDHR模型的训练。这里借助one-hot编码的思想,使用N位状态寄存器表示N位信息,对于评分使用长度为5的数组表示,具体编码如表1。由于SDAE只能接收定长的输入,数据集中不重复的标签(忽略大小写)共有35 173条,对标签进行编号,并使用长度为35 173的数组表示一条标签集合记录,例如用户i对项目j打上一系列标签xij,标签编号集合为{2,3,4,6},则xij=[011101000000…00],其中只有第2、3、4、6位置上的元素值为1,其余值全部为0。 表1 评分值的one-hot编码 SDHR模型的超参数取值如表2所示,其中SDAE网络层数为4,由于输入向量x的长度为35 173,所以l0和lc层的网络节点数是为35 173,相邻网络层之间的节点数保持10~100倍的倍数关系。为了保持网络的对称性,l3的节点数和l2相同,l4的节点数和l1相同。使用随机梯度下降法(Stochastic Gradient Descent, SGD)训练SDAE网络和CFM,学习率α取值0.1。超参数k=300、λ1=0.1、λ2=0.1,k、λ1、λ2的取值是由实验调参确定的,不同取值会对SDHR模型的性能产生影响。 表2 SDHR模型的超参数 3.2.1 模型超参数的影响 由于超参数k的取值既是SDAE从文本标签中提取出的项目特征的有效维度,也是CFM中矩阵分解的隐因子空间维度,即式(5)中的k,因此k的取值将会直接影响算法的精确度,图4是不同k值对SDHR的模型性能的影响。由图4可以看出,当k值较低时,无法提取到有效的项目特征;当k值较大时,又会在项目特征中引入干扰信息导致推荐精度降低;k=300时,模型性能最优。 图4 超参数k对模型性能(MSE)的影响 式(10)中的λ1和λ2是为了防止模型过拟合,加在U、V上的正则项惩罚因子,不同取值对推荐结果准确度的影响如图5所示。由于U是通过评分矩阵R分解得到的,λ1=0时模型处于过拟合状态,取其他值时λ1的变化对推荐结果的影响不大。从图5(b)可以看出,λ2=0时模型并未出严重的过拟合现象,由于V是由T计算得到,而T是SDAE模型学习到的特征,当λ2取值较大时,导致对V的惩罚过高,反而使得SDHR模型的性能降低。当λ1=0.1,λ2=0.1时,SDHR模型的学习效果达到最优。 图5 超参数λ1、λ2对模型性能(MSE)的影响 3.2.2 不同模型性能对比 在测试数据集分别运行SDHR、ITCF、SDELM和LFML模型,得到的评分预测性能如表3所示。 表3 不同模型性能(MSE)对比 从表3中可知,本文提出的SDHR模型与传统的协同过滤推荐模型ITCF相比,性能提升明显,提升了约45.19%。ITCF是一种浅层机器学习模型,学习能力较弱,在大规模稀疏数据集上的表现很差,同时其引入标签词频作为特征加强信息,对提高推荐性能效果不明显。在同样使用SDAE抽取特征的情况下,SDHR比SDELM性能提升了约38.83%,SDELM没有引入额外的特征加强信息,且其评分预测使用极限学习机和最近邻算法严重依赖特征质量,学习能力弱于SDHR使用的隐因子矩阵分解算法。与LFML相比SDHR模型推荐准确率提升约为16.06%,LFML模型使用的深度学习算法长短期记忆网络虽然在自然语言特征提取上表现优异,但在评分预测上性能不如SDHR。 图6是不同推荐模型的Top-K推荐性能表现。Top-K推荐的命中率与模型评分预测的准确性呈正相关,由表3结果可以看出,SDHR推荐准确率优于其他3个模型,因而Top-K推荐命中率最高。随着推荐项目数量K的增大,模型推荐命中率会不断降低。 图7是不同模型在同一训练数据集下的模型训练花费时间。模型训练所用时间与训练数据的特征有效维度和模型复杂度相关,特征维度越低(特征质量低),数据预处理耗时越少,模型复杂度越低(学习能力弱),网络训练消耗的时间越少。传统的ITCF模型简单,仅使用项目评分矩阵作为学习特征,在数据预处理和网络训练花费的时间最少;SDHR模型由于引入了额外的特征辅助增强信息(自由文本标签),且使用了深度学习网络SDAE,因而在数据预处理和模型训练时花费的时间较多,但是对比深度模型LFML和SDELM,SDHR模型在性能提高的同时,所花费的时间代价仍是接受的。 图7 不同模型的训练用时 针对协同过滤推荐算法推荐精度低,在大规模稀疏数据集上表现不佳的问题,本文提出使用深度学习模型SDAE改进的混合推荐模型,利用SDAE从自由标签文本中提取项目特征,并结合改进的隐因子矩阵分解算法,以此提高推荐系统性能。对比深度模型LFML和SDELM,在推荐性能提升的同时,模型训练时间并未明显增加,能够保证在合理时间内处理大规模数据。随着深度学习算法研究的进步,未来利用自然语言处理相关的深度模型对项目标签、评论、内容或分类描述文本进行语义处理,提取高质量项目特征,可以进一步提高推荐系统的推荐性能。
2.4 用户评分预测
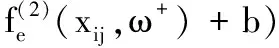
3 实验与结果分析
3.1 实验设计
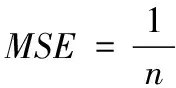

3.2 实验结果和分析

4 结语
猜你喜欢
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
公民与法治(2016年10期)2016-05-17 04:12:58
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
