
一种用于中文数据清洗的近邻排序算法
2018-08-15 08:02张培根黄树成
计算机应用与软件 2018年8期
张培根 黄树成
(江苏科技大学计算机学院 江苏 镇江 212003)
0 引 言
数据挖掘中,数据往往都不可避免地存在着缺失数据、冗余数据、不确定数据和不一致数据等多种问题[1]。在各个领域中,重复数据这一问题都是不容忽视的。尤其是目前的数据收集工作,已渐渐从人工搜集转变为机器搜集。并且,由于数据量的急速膨胀,导致各种数据质量问题屡见不鲜,在这中间数据重复尤为常见。导致数据中存在大量重复的因素有许多,例如数据收集条件的制约、度量方法错误、人工录入时出现错误和违反数据约束等[2]。在某些领域中的数据库中重复值比例高达50%~60%[3]。这些不完整的数据不仅意味着信息空白,更重要的是它会影响后续数据挖掘抽取模式的正确性和导出规则的准确性[4]。因此,如何处理重复数据已成为数据清洗及数据预处理领域研究的主要问题之一。
追溯到1959年,数据清洗首先出现在美国,被应用于全美社会保险号的纠正。随着美国商业和经济发展,数据清洗被大范围地应用,刺激了该方向的研究。虽然国外对中文数据清洗的研究并不突出,但是英文的数据清洗技术和相关理论已经相当完善[5]。由于中英文本身表达、语法和语义等存在的差异和国情差距,而且中文数据清洗技术的研究起步晚,现阶段全世界对中文数据清洗的成果不是很充足[6]。国内对数据清洗的研究主要在数据仓库、决策支持、数据挖掘等方面,商业性的数据清洗主要存在于各个领域,没有完整的理论性结论[7]。随着国内经济发展,中文数据清洗将取得众多成果。
本文研究了近邻排序算法(SNM)在中文重复值清洗中的应用。近邻排序算法在英文重复值清洗中的高效性取决于英文的语义和时态是基于单词的。然而中文是以中文词语为单位,并存在众多近义词成分,这是中英文重复值清洗研究存在巨大差异的根本原因[8]。因此,本文在传统近邻排序算法基础上,设计了一种改进的算法:基于编辑距离的近邻排序算法。新算法首先对编辑距离求相似度的算法进行引入,相比于现阶段大多数相似度算法,编辑距离(从A字符串变为B字符串需要最小的修改次数)的概念更适合中文求相似度;其次,引入IKAnalyzer对中文语句进行分词,将分词结果与中文近义词库进行对比。如果原本字面不相同的词语被判定为同义词,则算法同样认为这两个词语是无需修改的,所以编辑代价为0。
1 改进的基于编辑距离的近邻排序算法
1.1 基于编辑距离的近邻排序算法
相似重复记录清洗算法主要有以下两个评价标准:
标准1记忆率是识别出的相似重复记录数占所有相似重复记录数的百分比。
标准2准确率是指在算法识别出的相似重复记录里,那些真正的相似重复记录所占的百分比[9]。
在常规的重复值清洗算法的研究中,重复值清洗最可靠的方法是嵌套循环法,具体而言就是对数据库的数据进行遍历,但是时间复杂度太大,需要N(N-1)/2次比较,其中N是数据仓库中记录的总数[10]。排序合并方法是对数据集进行排序,之后对相邻记录比较,该方法已经成为现阶段数据库级重复值清洗的主流思想,也是众多优化算法的思想基础[11]。
传统近邻排序算法思路为:依据数据集实际含义,选出最具有代表性的某一列为关键字,以该关键字为依据对整个数据集进行排序,使大致相似的字段靠近;在排序后的数据集上加上大小为w的滑动窗口,每次对滑动窗口内数据进行遍历检查[12]。如图1所示。
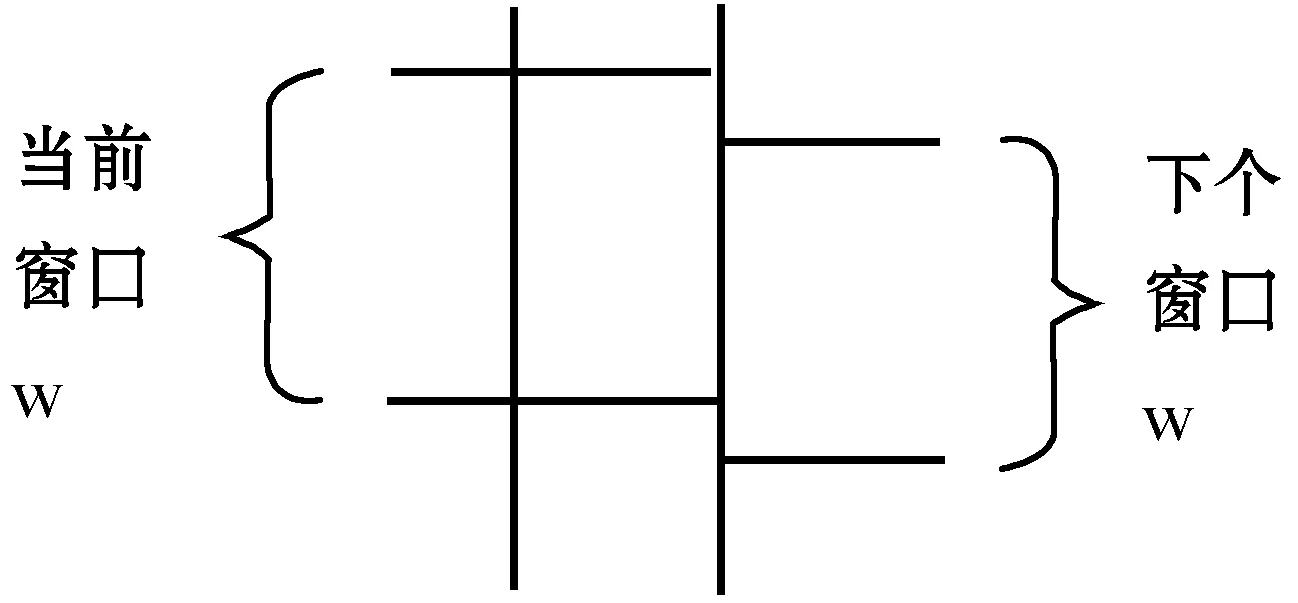
图1 近邻排序算法示意图
滑动窗口包含w条记录,每条新进入窗口的记录都要与先前进入窗口的w-1条记录依次对比是否为重复记录,窗口往下移一位,再把新的w条记录按照之前的方法迭代进行,直到数据集的最后。在数据集数据条数过多的情况下采用滑动窗口技术,准确率有所提高的基础上,很大程度上减少运行次数,提高运行效率,但该算法依然存在两点不足。(1) 太依赖于关键字的选取,关键字选择的成功与否,很大程度上影响了该关键字是否反映现实对象特征,如果失败,将无法使相似记录聚集在一起而失去重复值清洗的意义[13]。(2) 合适的窗口大小很难选取,每个数据集大致相似记录数量各异,窗口过大,则时间增加;窗口过小,容易漏掉相似记录,影响匹配效率[14]。
高职课程学习效果评价指标千差万别,设计一套具有普适性且科学、合理,能充分激发学生学习兴趣和潜能,便于实施的基于能力本位的评价体系非常必要。依据工学结合的教学模式和以就业为导向的培养目标,通过梳理企业岗位能力,可以将高职课程学习效果评价指标分解为专业核心能力、职业核心能力、职业素养三大部分[3]。专业核心能力是基础、针对性强,职业核心能力和职业素养作为职业导向,具有普适性。
该算法采用滑动窗口技术,减少了比较次数,也能有基本满意的记忆率和准确率,但是该算法有两点不足。(1) 对关键字依赖程度太大,若选取的关键词本身错误严重或不能反映现实对象的特征,则真正重复的记录不能聚集在一定范围内,失去匹配比较的机会。(2) 窗口大小w很难选取,窗口过大,则比较时间增加;窗口过小,则容易漏掉重复记录。
近邻排序算法的优点显而易见,但是针对缺点,后续产生了众多优秀的优化算法,比如Hernandez等[15]提出了多趟近邻排序算法MPN算法,利用多趟排序,来减少不恰当的关键字对整个清洗结果的影响,同时可以考虑联合关键字排序。并且承认传递闭包关系,认为记录R1与R2互为重复记录,R2与R3互为重复记录,则R1与R3互为重复记录。
1.2 改进算法的策略
本文从以下几个方面对近邻排序清洗重复值算法进行改进。
(1) 语义方面,中英文有显而易见的差异。首先英文语义基于单词,而中文语义基于词语[16];其次,根据每个英文单词语义,可以直接拼接出整个语句的语义,但是中文语句不存在明显的语义分隔符,更无法根据单个文字语义拼接出整个语句的语义。在中英文表述方面,英语是形合语言,注重句法平面,而汉语是意合语言,注重语义平面[17]。
改进算法思想:
传统编辑距离算法应用于中文相似度计算时,一般以字为单位计算字符串之间的编辑距离,但是此种方法的计算结果往往存在于字面本身并且与中文语句的实际语义出入较大,而且计算过程中,对每个字符的计算需要可考虑到语句长短对整个语句计算时间的影响。针对以上情况,本文考虑采用中文分词的方法解决。即在此采用IKAnalyzer中文分词模块,随后以词语为单位进行编辑距离的计算,从而在满足相似度计算要求的同时,更符合中文的使用环境,计算速度和准确率也会有相应的提高。
(2) 英文的语义和时态直接反应在英文语句的特定单词中,而汉语有时需要读者自己“体会”。再者,汉语中常见的同音词、同义词在英文中较少出现。最后,在中英文提取缩写的过程中,英文语句本身存在自然分隔符,可以轻易通过首字母大写提取出缩写,而汉语是双字节编码,很难得到统一的缩写方式[18]。综合以上三点,这给将英文中成熟的重复值清洗算法应用到中文分词中带来了巨大难度。
改进算法思想:
采用分词的思想来计算编辑距离,虽然以词语为单位很大程度上提高了计算效率,但是与中文的实际应用场景存在很多不符之处,尤其两词为同义词时,实际一个意思,但会被传统编辑距离算法认为是不同意思。针对这些情况,考虑在进行编辑距离的计算时采用以下方式:“计算编辑距离的过程中,如果两词条字面完全一样,则编辑代价cost为0;如果两词条字面不一样,则编辑代价cost为1;”利用同义词库变更为:“如果两词条相互同义,则编辑代价cost为0;如果两词条不互为同义词,则编辑代价cost为1;”从而使计算结果更符合字符串词语相似度计算的要求。
1.3 改进算法的步骤
改进的基于中文分词和同义词检查的近邻排序算法的具体描述如下:
输入:含有m个对象的数据集D
输出:被判定为重复值的对象以及相似对象的个数和数据集D对象的总个数
方法:
Step1选取关键列,依照该关键字对数据集D进行排序,排序后的数据集为D′。
Step2设置大小为w的滑动窗口,在该窗口内,以第w-1为基础,依次对比从w-2到0的对象。
Step3在对比过程中采用优化后的编辑距离算法,首先,通过IKAnalyzer进行中文分词;其次,引入同义词库,对分词后的对象中每个相对应词语进行同义词对比,若判定为同义词,则编辑代价为0。
Step4初始滑动窗口的大小一般为3,但是由于数据集的不同或者大致相似数据的多少的差异,窗口大小不能一概而论。在完成以上三步的基础上,对窗口大小进行缩放后重复以上三步,得出在窗口大小不同的情况下重复值清洗的差异。
Step5得到在不同数据集下相似度随着w大小变化而产生的折线图。
2 实验结果
本实验的数据集采用供应商商品库存数据集,该数据集具有6个属性,1 044条数据。
本文采用正确率来衡量算法的清洗精度。实验最终,将经过算法清洗的数据集与原始数据集进行比较,通过计算正确率来体现清洗算法的匹配程度。正确率计算方法如下:
式中:m是正确清洗出重复值的属性个数,n为原始数据集中重复的属性值个数,P为清洗算法的正确率。当P值为0时,表示所有清洗结果都错误;相反,当P值为1时,所有清洗结果都正确。
实验结果及分析:
从图2可以看出,对于原近邻排序算法,并非w值越大重复值清洗效果就越好,而且w的取值没有规律可循,当与数据集的分类吻合时,其实验结果较好。
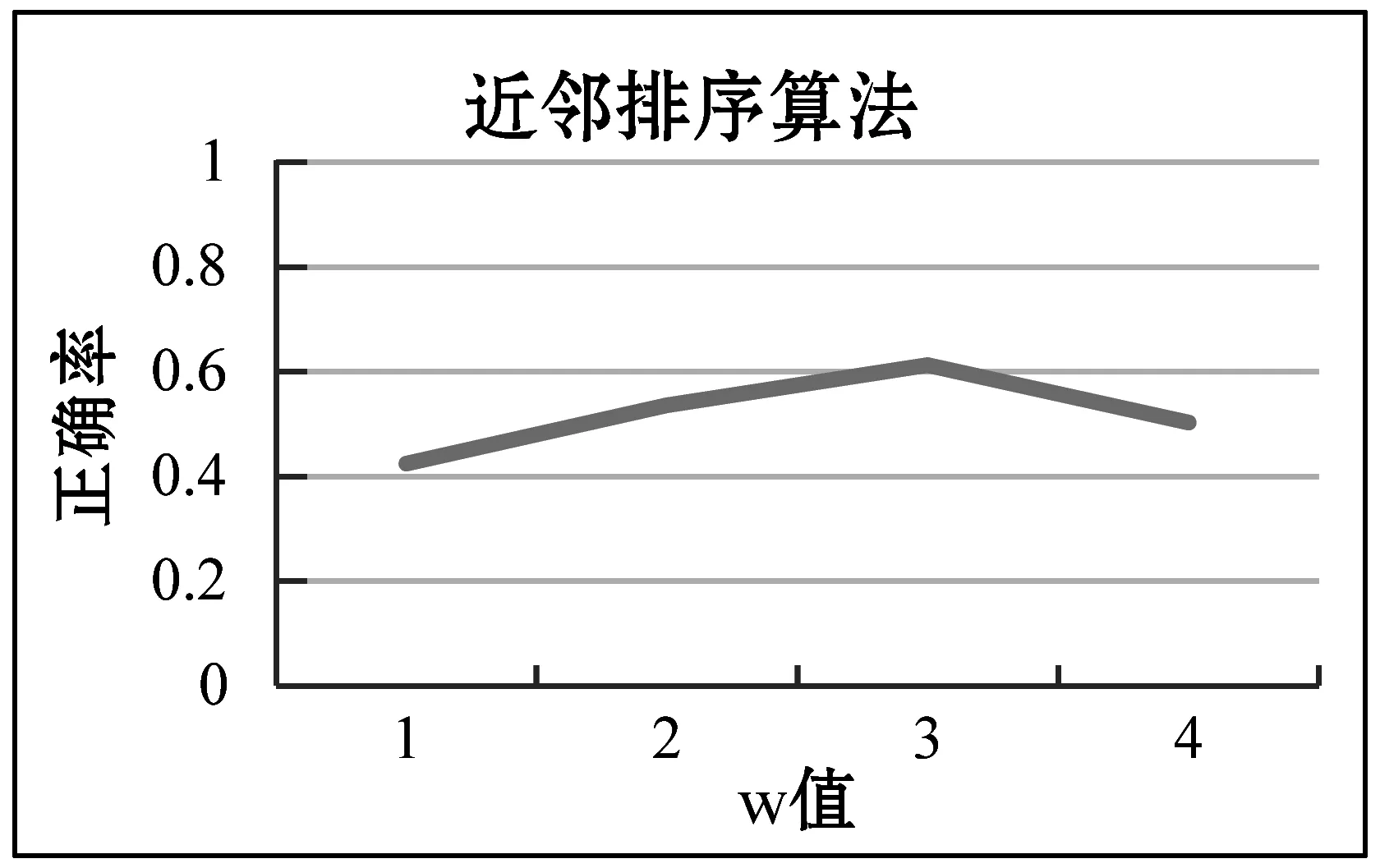
图2 基于近邻排序算法不同w值下的精确度曲线
从图3可以看出,重复较多的情况下,清洗的精确度普遍较高,当重复值比例20%左右的时候,精确度降低。

图3 不同算法不同重复比例下的精确度曲线
通过表1可以看出,虽然原近邻排序算法正确率比较可观,但是结合中文分词和同义词检查之后,改进后的近邻排序算法更适合普遍中文文本的重复值清洗,正确率有显著提高。

表1 不同清洗算法最优正确率对比表
3 结 语
本文提出了一种基于中文分词和同义词检查的近邻排序优化算法。首先,考虑到中英文的语义、时态、提取缩写等方面本身存在的差异性,本文在沿用编辑距离的情况下,采用中文分词和同义词检查的方法,对近邻排序算法加以改进。其次,在实验过程中,合适的窗口大小、关键字的选择等方面对算法的实际效果存在影响。本文通过在不同窗口大小下对同一个数据集的实验,得出结论:若想得到最合适的结果,需多次试验获得最合适的窗口大小。综上所述,在将近邻排序算法应用于中文重复值清洗的过程中,该优化算法在取得预期清洗结果的同时,在一定程度上提升了效果。
猜你喜欢
华人时刊(2022年1期)2022-04-26
名家名作(2021年4期)2021-05-12
校园英语·月末(2021年13期)2021-03-15
科普童话·学霸日记(2020年1期)2020-05-08
动漫界·幼教365(大班)(2019年10期)2019-10-28
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
小天使·一年级语数英综合(2019年2期)2019-01-10
环球时报(2009-11-25)2009-11-25
中学生英语·外语教学与研究(2008年4期)2008-03-18
