
基于大样本的随机森林恶意代码检测与分类算法
2018-08-06 08:07李雪虎王发明
网络安全与数据管理 2018年7期
李雪虎,王发明,战 凯
(北京江民新科技术有限公司,北京 100097)
0 引言
随着互联网的快速发展,计算机安全问题已经提高到国家安全的战略角度,但是在互联网上传播的恶意代码的数量、种类等都在增加。根据江民病毒疫情监测预警中心提供的数据显示[1]:2018年5月,新增病毒1 140种,感染计算机13 569台。北京、上海、广州是主要的被感染和受攻击地区。虽然恶意代码一直在持续的增长,但是大部分恶意代码在编写过程中都是关键模块重利用,其特征行为具有高度的相似性[2]。
首先,恶意代码为了伪装自身,会对自身代码结构进行修改,而修改自身代码结构的方法则具有规律性;其次,恶意代码为了实现获取计算机相关权限、修改计算机重要文件等敏感操作,就需要调用系统相关的API函数来达到目的。所以本文根据以上恶意代码的特点通过机器学习的方法实现对恶意代码的辨别与分类。
1 恶意代码分类算法相关研究
1.1 基于API调用的特征提取
应用程序编程接口(Application Programming Interface, API)是可以作为恶意代码分类特征使用的,恶意程序通过调用一些API(主要是系统底层API),达到窃取用户敏感信息或者获取本计相操作权限等,而这些API在大部分的恶意代码中均被大量使用,本文将这些API称为敏感API。在文献[3]中已经证实在同一种分类算法中,使用敏感API得到的分类结果准确度要优于不使用敏感API得到的分类结果准确度,故本文将敏感API作为恶意代码分类的特征向量。
一般提取恶意代码特征主要有两种方法:静态分析方法和动态分析方法。静态分析主要使用IDA[4]、JEB等反汇编工具,主要特征有PE文件结构信息和敏感API调用等。动态分析方法主要是使用沙箱[5](例如布谷鸟)等程序模拟操作系统环境,监测其中未知程序的行为并与已知的恶意代码行为进行匹配,如果匹配成功,则可判定未知程序为恶意程序。但是在具体的应用过程中发现,由于系统API层次较低,沙箱进行行为监控时,难以获得行为的准确含义,并且沙箱分析出结果的速度缓慢,耗时较长。由于这些缺点的存在,故本文采用静态特征分析的方法。
得到特征数据以后,就可以使用机器学习的相关模型进行恶意代码的分类识别。分类算法有很多,常见的算法有K近邻(K-Nearest Neighbor, KNN)[6]、支持向量机(Support Vector Machine, SVM)[7]、逻辑回归(Logistic Regression)[8]、卷积神经网络(Convolutional Neural Network, CNN)[9]等。本文主要是使用随机森林进行恶意代码分类。
1.2 随机森林
随机森林可以解释为若干自变量(X1,X2,…,Xi,…,Xn) 对因变量Y的作用。如果因变量Y有m个观测值,有n个自变量与之相关(并且大多数情况下,m是远远小于n的);在构建决策分类树的时候,随机森林会随机地在原数据中重新选择m个观测值,其中有的观测值可能被多次选择,有的可能一次都没有被选到。根据选择的样本进行决策树建模,然后组合多棵决策树的预测,通过投票得出最终的预测结果。
1.3 随机森林算法实现
本文的随机森林算法是在Spark下实现的,采用的是Python第三方库Pyspark。实验分为两个,第一个实验的输入为样本文件的文件特征,包括文件类型、文件大小、文件导入表、文件基地址、文件版本等50个特征作为输入;第二个实验的输入为敏感API特征,其中调节的参数为:numTrees=150,maxDepth=30,labelCol=“indexed”,featuresCol='features',seed=42,其余参数保持不变。本文将总数据集的80 %用于训练,20%用于测试。
2 实验分析
2.1 实验数据集
恶意代码数据集是进行恶意代码分析的基础,机器学习算法只有结合相关的数据集对样本进行训练,才能更好地实现检测功能。
本文采用的数据集是江民新科技术有限公司病毒库中的数据集。本次采用的数据集总量为90万,其中45万白样本,45万病毒样本。并且在45万病毒样本中,Downloader、Trojan、Backdoor三类样本样本量分别是15万、15万、15万。
2.2 实验环境
实验环境:CPU:Intel(R) Xeon(R) CPU E5645 @ 2.40 GHz,操作系统CentOS Linux release 7.3.1611,内存32 GB。
Hadoop和Spark的版本为:Hadoop版本2.7.1,Spark版本2.2.1。
2.3 实验评判标准
用查准率(Precision)、查全率(Recall)和F1度量评估本文算法,通常以关注的类为正类,其他类为负类,指标的取值为0~1。这些度量的计算公式如下:
(1)
(2)
(3)
其中,TP(True Positive)是指将正类预测为正类数,FP(False Positive)是指将负类预测为正类数,FN(False Negative)是指正类预测为负类数。
2.4 结果分析
在所选择的数据集(江民新科技术有限公司病毒库中的数据集)上将本文的随机森林算法与支持向量机算法、逻辑回归算法做比较。
首先进行黑白样本分类的实验,查看实验的查准率、查全率和F1值,从实验结果可以看出当样本总量在10万左右的时候,随机森林在辨识黑白样本的效果上与支持向量机算法、逻辑回归算法相比较,结果并不理想。但是随着样本数量增大到90万,随机森林模型在辨识黑白样本的查准率、查全率、F1值从原来的0.732、0.711、0.721提升到0.973、0.973、0.973,都达到了三种分类中的最好,其中在500 000到700 000样本的时候,查准率、查全率和F1值出现了下降,是因为随着病毒样本的增加,其中部分白样本经过编译器编译得到的PE结构信息与部分病毒样本的结构信息相似,使得随机森林算法出现了一定的误差。但是随着样本量的继续增大,这一小部分的样本对于整体的分类影响逐渐变小。实验结果如图1、图2、图3所示。

图1 三种分类算法黑白分类查准率

图2 三种分类算法黑白分类查全率

图3 三种分类算法黑白分类F1值
其次,再进行基于Downloader、Trojan、Backdoor这三种病毒分类的实验,本次实验的恶意代码数据是总数据集中的45万病毒样本。从实验结果可以看出随机森林在对Downloader、Trojan、Backdoor三种病毒分类时,与支持向量机分类算法和逻辑回归分类算法相比较,实验效果是比较好的。随着恶意代码的样本量从9万增长到45万时,查准率、查全率、F1值从原来的0.924、0.918、0.921提升到0.935、0.932、0.934,评判标准都有提升。其实验结果如图4、图5、图6所示。

图4 三种分类算法在病毒分类的查准率
从以上结果可知,随机森林在分类的泛化能力上要优于SVM和逻辑回归。

图5 三种分类算法在病毒分类的查全率
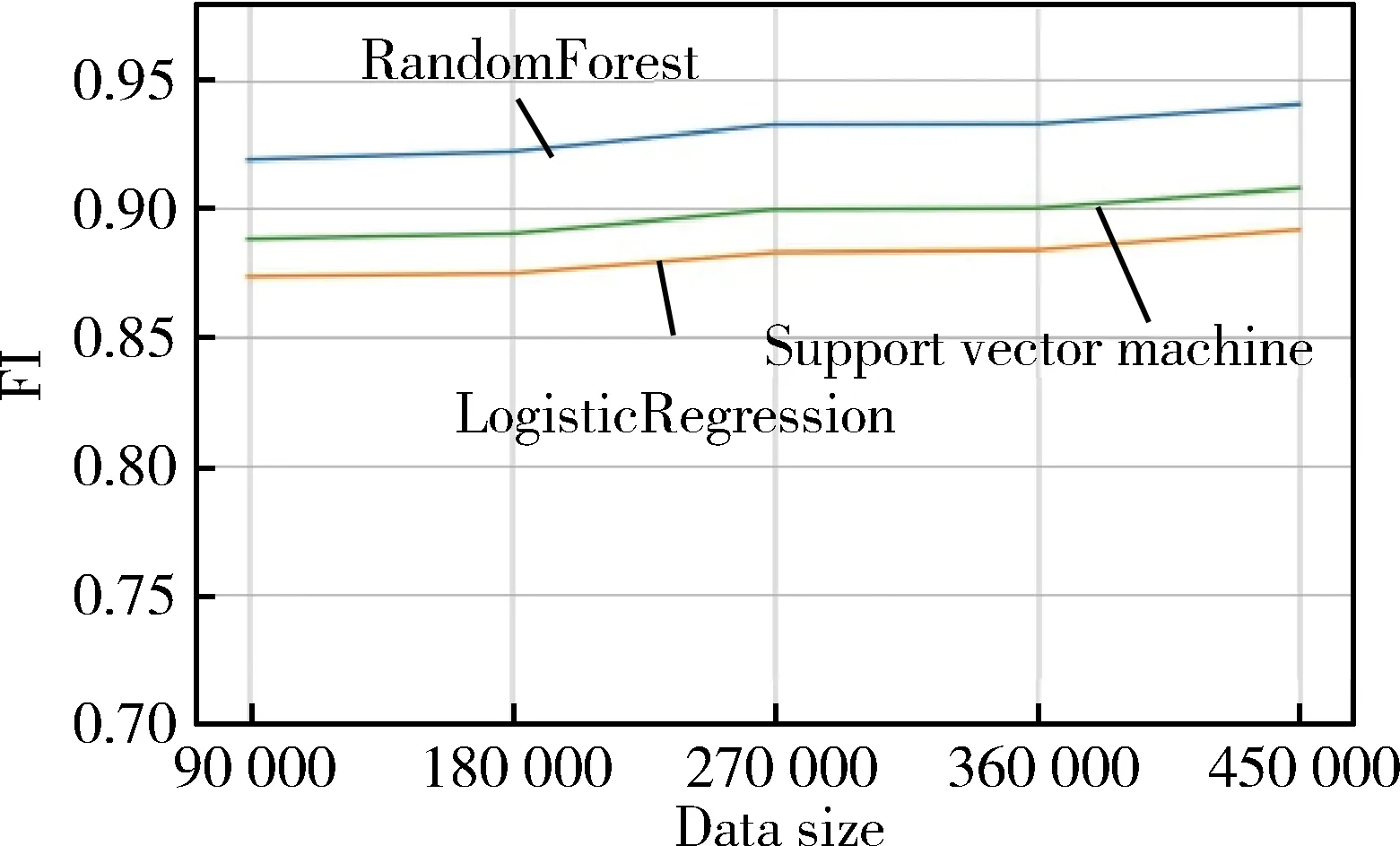
图6 所示为三种分类算法在病毒分类的F1值
3 结束语
本文聚焦在大样本下利用机器学习算法对恶意代码进行识别和分类检测,选择PE文件结构和敏感API作为输入,实验数据表明随机森林的评价效果比支持向量机、逻辑回归模型的效果优秀。在进行三种病毒分类上,虽然随机森林的效果最好,但是随机森林对于某些白样本使用和病毒样本相同的编译器时,容易将其划分为病毒样本。其次,准确率仍然不是很高,只有0.935左右,在基于大样本的前提下,模型的分类效果仍然需要提升,以上两个问题是本文今后工作的重点。
猜你喜欢
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
作文大王·笑话大王(2016年2期)2016-02-24
中国管理信息化(2009年10期)2009-06-19
