
无监督与监督学习下的含油气储层预测
2018-08-01 11:32林年添魏乾乾
石油物探 2018年4期
林年添,付 超,张 栋,金 兴,张 凯,文 博,魏乾乾,张 冲
(1.山东省沉积成矿作用与沉积矿产重点实验室,山东科技大学地球科学与工程学院,山东青岛266590;2.山东大学岩土与结构工程研究中心,山东济南250061;3.海底科学与探测技术教育部重点实验室,中国海洋大学地球科学学院,山东青岛266100;4.山东正元建设工程有限责任公司,山东济南250101;5.山东科瑞机械制造有限公司,山东东营257000;6.山东省煤田地质局,山东济南250104)
利用地震属性对含油气储层特征进行描述是石油地球物理勘探的主要手段之一[1-2]。目前,用于描述含油气储层特征的方法较多,包括聚类分析方法[3-4]、多属性融合技术[5-7]和神经网络[8-9]等。这些方法多以规模较大的训练样本为支撑,当训练样本不足时,模型的泛化能力就会受到限制,极易陷入过学习或欠学习的状态。支持向量机是以结构化风险最小化为基础的模式分类器[10],小样本的情况下也有更高的泛化能力,所构建模型的鲁棒性更为理想。支持向量机的难点在于参数寻优,本文综合期望风险评估折衷算法、聚合(复合)地震属性算法等对支持向量机的参数进行寻优,最大程度地消除了支持向量机参数寻优问题对预测结果带来的不利影响。支持向量机算法的分类与回归不但拓展到通讯、化学[11-12]、生物[13]等领域,而且推广到了油气地球物理勘探领域。对于储层预测而言,主要应用支持向量机的回归算法(support vector regression,SVR)。
当前人们使用的地震属性有上百种[14-15],如何高效地获取对含油气储层特征敏感的地震属性,构建各种属性与含油气储层特征的关系,是储层预测必须面对的问题。在机器学习领域,对于储层的预测可以分为两大类:一类为监督学习下的储层预测[16-18],另一类为无监督学习下的储层预测[19]。在监督学习领域:王振洲[20]利用决策树方法和6种测井参数构建岩性信息与岩石特征的关系,对苏里格气田的岩性进行预测;袁照威等[21]分析了地震属性与沉积相之间的关系,并利用4种地震属性,通过马尔科夫-贝叶斯模拟算法构建了多种属性之间的关系,建立了沉积相模型,获得了较好的模拟结果;宋建国等[22]利用随机森林回归法对地震储层进行了预测。在无监督学习领域:杨兆栓[23]利用主成分分析法分析了5种测井曲线,最终识别了塔中地区的碳酸盐岩岩性,利用PCA方法整合了众多的测井参数特征,提高了岩性识别精度。监督学习和无监督学习都是为发现数据集之间的关系,基于统计学理论建立起来的算法[24-25],寻找并利用最具有特征的量对某种期望的量进行预测。
本文对原始多波地震数据进行卷积升维计算获得包含更全面信息的纵、横波(本研究实际应用的是转换横波)地震属性,运用聚类分析等无监督学习法对获得的地震属性优选优化,在此基础上,将小样本情况下具有更强泛化能力的监督学习法(支持向量机)应用于油气储层预测,在FG工区实际储层预测的应用结果验证了本方法的有效性。
1 理论基础
1.1 莱特准则下剔除异常值
对地震数据体采用不同的数学算法获得不同量纲的地震属性,其数值范围较大,为0~106。为了对不同量纲的属性进行计算,首先要对不同的属性值进行标准化处理,获得归一化后的数据集。在数据归一化之前,要对离群点进行剔除[26]。本研究引入莱特准则法进行剔除。莱特准则为:假设地震属性数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确定一个区间,认为凡超出这个区间的误差,就不属于随机误差而是粗大误差,含有该误差的数据应予以剔除。属性集为D={x11,x12,…,x1N,x21,x22,…xij,…,xMN},M为最大横测线号,N为最大纵测线号。当离均差δ的平方和越大,表明属性集D的变异程度越大,即属性集D中存在异常值,我们采用离均差的平方和量化表征属性集的离散趋势。
横向测线号为i,纵向测线号为j处的归一化地震属性值有:
(1)
式中:xij为横向测线号为i,纵向测线号为j处的地震属性;minxij为xij的最小值;maxxij为xij的最大值。
属性xij的均值μ为:
(2)
属性xij的离均差δij为:
(3)
离均差的平方和为:
(4)
属性集D的标准差κ为:
(5)
所有满足|δij|<3κ的xij均不是粗差和坏值,而|δij|≥3κ时的xij是粗差,应予以剔除。
1.2 K-means聚类分析
聚类分析优选属性首先提取地震属性,然后计算两两属性之间的相关系数,最后判断相互之间的密切程度,计算相关系数的公式如下:
(6)

上述所讨论的为单个样点(或某口井)不同属性间的相关性,即密切程度,并依此进行聚类分析,分析结果可用聚类轮廓图表征。聚类轮廓图用分类指数表示每个类中属性与相邻类中属性的接近程度,其值介于-1和1之间,-1代表该属性分类可能错误,0代表该属性的类属关系不明确,1代表该属性与相邻类中属性距离远,此时分类结果最佳,如图1所示。根据聚类轮廓图可以知道分类的合理性。如图1a所示,聚类为3时,第一、二、三类的分类效果较好;如图1b所示,聚类为4时,第一、二、三类效果较好,第四类轮廓出现负值,说明该类并不理想。
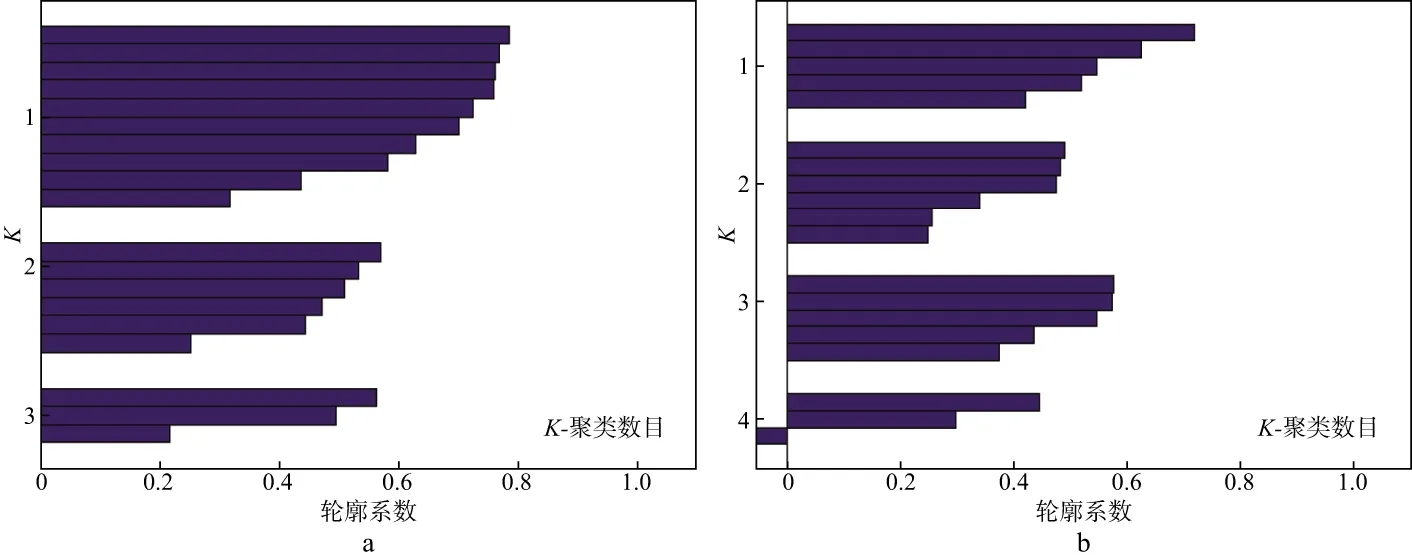
图1 聚类为3(a)和聚类为4(b)时K-means聚类分析结果
1.3 SVR 算法的基本原理
支持向量机学习策略是最大化分类间隔[27],将问题转化为一个凸二次规划问题并进行求解。对于凸二次规划问题,要找到一个回归的超平面,使得用于学习的地震属性集里面的所有数据到该超平面的距离最小。区分样本x的超平面方程为:
(7)
式中:y(x)为获得的油气特征值;ω为权值;b为偏置。
假设图2中某个样本到回归超平面的距离为S:
(8)
式中:d(xs)为监督学习标签,即在测井记录上获得的油气特征值;xs为第s个样本;y(xs)是xs的油气特征值。
为了防止数据过拟合,令ε为容忍值。当数据回归到超平面的距离S小于ε时,代价函数cost(x)表示为:
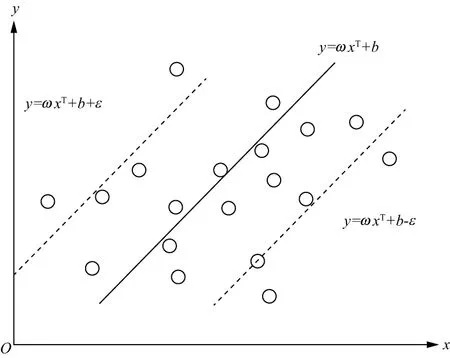
图2 SVR超平面
(9)
式中:d(xs)为监督学习标签。约束条件为:
(10)

(11)
式中:C为惩罚因子;n为样本总个数;s.t.(subject to)为约束条件。
利用拉普拉斯变换可将目标函数与约束条件构建到一个方程中,由于此问题满足KKT条件(Karush-Kuhn-Tucker,卡鲁什库恩塔克条件,即对于给定的某一函数,求解其在指定作用域上的全局最小值),故可以将此问题转换为它的对偶问题求解。因为一方面对偶问题和原问题有近似解,另一方面转换后的对偶问题便于求解。即有:
(12)
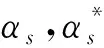
(13)
b=y(xs)-(ωTxs+b)-ε,αs∈(0,C)
(14)
(15)
将(13)式,(14)式及(15)式代入(7)式可求得训练模型,对于任意给定的数据x,可得到该数据的预测值y。
2 无监督与监督学习的储层分布预测模型
无监督学习与监督学习的有机融合及其在地震油气储层分布预测的应用是本研究的核心。
无监督学习:事先没有任何训练数据样本,需要直接对数据进行建模。故数据没有类别信息,也不会给定目标值。在无监督学习中,将数据集合分成由类似的对象组成的多个类,该过程即为聚类分析。
监督学习:利用已有的训练样本(即已知数据及其对应的输出)来训练,从而得到一个最优模型,再利用这个模型将所有新的数据样本映射为相应的输出结果,对输出结果进行简单的判断从而实现分类,那么这个最优模型也就具有了对未知数据进行分类的能力。
无监督学习可以减少数据的维度,利用聚类分析法进行降维处理,再输入监督模型,比未经降维处理的数据直接输入监督模型效果更好。
本研究针对多波地震属性对油气储层敏感度上存在的差异,设计了无监督学习与监督学习的串联模型,从而实现多波地震油气储层的有效预测。模型主体算法为聚类分析法及支持向量机,前者执行的是无监督学习,后者执行的是监督学习。图3所示即为用于多波地震油气识别的深度学习模型。在该模型中,无监督学习模块主要实现地震属性优选优化的目的,即尽可能去除对油气储层不敏感或弱敏感的属性,优选出对储层敏感的属性,然后作为监督学习的输入,以提高油气储层预测的效率和效果。
2.1 卷积升维获取多波地震属性
应用不同卷积核分别对纵波与转换横波原始地震数据进行卷积计算,获取各类地震属性,这些地震属性包含了丰富的几何学、运动学、动力学和统计学特征。基于不同的应用目的,大类地震属性主要包括振幅统计类、频率类、频谱统计类及时间序列统计类。

图3 机器学习模型
通过深入研究分析,特别是进一步分析纵、横波地震属性差异性对寻找油气储层的影响,明确了纵、横波在振幅、波形、频率、衰减、相位、能量、相干、比率等有关属性上的差异对于含油气性储层预测以及流体判别等方面的作用。因这些属性能够将单属性难以呈现的地下储层信息更加全面地呈现出来,故可以对目的层段有利含油气储层区域进行更有效预测。
2.2 剔除异常值
地震属性的提取难免会受到信噪比低的影响或噪声的干扰,势必会造成局部异常值的存在。采用公式(4)离均差δ的平方和来量化表征异常值对属性集的离散趋势,离均差δ的平方和越大,表明属性集D的变异程度越大,即属性集D中存在异常值。为消除异常值可能给后期数据处理带来的不利影响,在数据归一化之前,要对离群点进行剔除[28]。输入用于训练的样本数据D={x11,x12,…,x1N,x21,…,xMN}后需剔除异常值,以确保数据的有效性。
2.3 属性值的标准化处理

2.4 地震属性的聚类降维
降维分为两个层面:一是通过降维,将纵、横波地震属性维数降低,起到优选作用;二是利用纵、横波对油气的敏感度不同,进行有机聚合,使纵、横波属性融合在一起,起到优化降维作用。
2.4.1 纵、横波地震属性聚类降维
利用聚类分析优选属性,首先将提取的地震属性归为一类,然后计算两两属性之间的相关系数,判断它们之间的密切程度,两种地震属性的相关系数Rij介于-1和1之间,靠近0时,属性之间相关性差,靠近-1或1时,两属性之间相关程度高,将相关程度高的属性归为一类,根据经验从同一类属性中选择具有代表性的地震属性(具有油气特征或对油气敏感的属性)与其它不同类属性,最后组成优化后的属性集,既达到优选目的,又完成了降维的过程。
2.4.2 纵、横波地震属性聚合降维
经过相关计算,将纵波和转换横波所包含的信息融入到新构建的属性中,生成新的属性,这一过程称为聚合属性(亦称复合属性)。聚合后的地震属性降低了原始属性集的维度,同时新获得的聚合属性具有一定的地质意义。首先,根据经验并结合数学理论选择与油气特征相关的属性,获得的多波聚合地震属性包括叠合类、差值类、比值类和乘积类的属性。类比分析认为,比值类及差值类属性反映纵、横波在油气地震响应敏感性方面更突出,故本研究选出这两类属性作为监督学习的输入,比值类地震属性可以突出油气敏感属性的特征,又称为为第一类属性,用符号F1表示,F11表示第一类比值属性,F12表示第二类比值属性,分别如(16)式和(17)式所示。差值类属性是当属性A对油气敏感,属性B对油气不敏感时,利用属性A与属性B之间的差压制背景干扰,突出地质异常体,又称为为第二类属性,用符号F2表示,F21表示第一类差值属性,如(18)式所示。
纵波均方根振幅对油气敏感,当纵波遇到油气层,特别是气层时,气层的强烈吸收作用使得均方振幅值衰减较大,而转换横波遇到气层则不会发生明显衰减。通过(16)~(18)式获得纵、横波聚合地震属性如下:
式中:rPP为纵波均方根振幅;rPS为转换横波均方根振幅;fPP为纵波瞬时频率;fPS为转换横波瞬时频率;aPP为纵波瞬时振幅;aPS为转换横波瞬时振幅。
2.5 储层分布的监督学习与预测
需要对由无监督学习获得的数据进行评估,从而为监督学习提供更可靠的学习样本输入,特别需要对学习样本的井点处数据进行评估并校正。
2.5.1 期望风险评估
由于工区内已知测井、钻井记录非常少,所以支持向量机需要输入的学习样本点在某一层位的值非常少。如果井点处的学习样本存在异常值,该样点值会造成SVR在学习时产生偏差。在全工区推广这个存在偏差的模型则可能会导致应用支持向量机的分类/回归产生较大误差或错误,学习效果会受到严重影响。期望风险评估就是对原始数据集校正,使数据集趋于正态分布。与常规方法相比,期望风险评估算法能够充分利用属性集数据的分布规律,最大程度还原数据的真实性。对井点处属性值进行经验风险评估,可得到更加贴合数据真实度的SVR学习样本输入[28]。
2.5.2 SVR预测多波地震油气储层预测
本研究主要采用SVR作为监督学习工具,实现利用已知预测未知的目的。将上述由经验风险评估得到的更加贴合真实情况的数据作为SVR学习样本输入,利用(7)式获得基于学习样本的支持向量机回归模型,并依此进行推演,最终获得经过支持向量机回归的属性集。利用支持向量机建立学习样本与各个样点之间的内在联系,从而将已知井油气特征推广到全区,最终实现油气储层分布的预测。
3 应用实例
将上述无监督学习与监督学习模型应用于FG工区的多波地震油气储层分布预测,以验证该设计模型的有效性和可行性。
3.1 卷积映射升维提取地震属性
应用不同卷积核分别对试验工区纵波与转换横波原始地震数据进行卷积计算,获取各类地震属性,本案例分别生成纵波与转换横波属性各36种,图4为优选出的部分典型纵、横波地震属性。
3.2 地震属性去噪及标准化处理
应用莱特准则剔除地震属性中可能存在的异常值,进行去噪处理,然后对去噪处理后的地震属性进行标准化处理,为后面的聚类分析提供更可靠的源数据。
3.3 卷积映射降维优选地震属性
该环节是无监督学习的主要环节,包含两个层次的降维:第一层次聚类降维优选出6种地震属性(图4),再根据专家经验优选出3种纵波与转换横波属性,作为第二层次聚合降维的输入;经过第二层次的无监督学习,纵波与转换横波地震属性聚合成新的地震属性(图5),作为监督学习的输入。

图4 优选出的典型纵、横波地震属性a 纵波均方根振幅; b 转换横波均方根振幅; c 纵波瞬时振幅; d 转换横波瞬时振幅; e 纵波瞬时频率; f 转换横波瞬时频率
无监督学习环节结合专家经验、数学理论及该区储层特点优选属性,获得的聚类属性不但能够反映含油气储层的纵波特点,还能够揭示含油气储层的转换横波特征。图5为获得的聚合地震属性,其中,图5a,图5b为比值属性,图5c为差值属性。从图5可以看出,采用不同聚合算法得到的地震属性可能都存在油气地震响应,但由于所包含的信息不同,对于油气藏边界的刻画不唯一,结果存在较大的不确定性。为此,本研究引入支持向量机进行监督学习,以降低不确定性。

图5 纵、横波聚合地震属性a F11比值属性; b F12比值属性; c F21差值属性
3.4 监督学习与预测含油气储层的分布
将获得的纵、横波聚合地震属性(图5)作为支持向量机的学习集,开展地震油气储层分布的监督学习与预测,即通过支持向量机建立学习样本与各个样点之间的内在联系,将已知井储层特征推广到全工区。
选取工区内10口井的信息作为支持向量机的学习样本,每口井周围取9个采样点应用经验风险评估折衷算法,获得经验风险最小的输入样本值。根据已知测井、钻井及前人研究成果,可将井分为高含气井、低含气井和未含油气井三类。对应的区域分为有利气藏地震响应区、较有利气藏地震响应区和油气前景不佳区。需要说明的是,由于SVR的学习过程中需要划分出正样本和负样本,而本区的井点负样本较少,所以在构造低部位的已知非油气区域选取5个样本点作为未含油气井。
以纵波地震属性为样本,经聚类分析后再进行支持向量机储层预测,结果如图6所示。将纵、横波聚合属性(图5)作为学习集,将获得的井点样本作为支持向量机回归器的输入,利用回归器将运算结果推广到全工区,最终得到多波地震含气储层分布的预测结果(研究区已被证实主要为气藏区),如图7。图7a是采用SVR监督学习以图5为输入的预测结果,而图7b是利用激活函数对图7a进行激活处理得到的结果。可以看出,图7b刻画的含气储层异常分布边界更加清晰。
3.5 实际应用效果分析评价
图7b红色高值处表示含气有利区,蓝色低值处表示为非有利区。预测结果与实际钻井结果相比较不难看出,仅以纵波数据进行支持向量机预测,虽也能预测油气分布情况,但存在模型的泛化能力差,对油气的边界刻画不清晰等缺陷,如图6b所示。而综合利用纵、横波地震数据进行无监督学习后,再由SVR进行监督学习与预测,得到的气藏分布情况更符合实际情况,如图7b。图8中粉红实心圈所指示的井为产气井,说明所预测的含气储层区域基本位于已知产气井所在的暖色调区域,井点以外预测的高含气区域可以作为进一步钻探部署的依据。不难看出,相比于原始纵波均方根振幅属性(图6a)和由单一纵波监督学习得到的预测结果(图6b),图7b和图8所刻画的含油气储层边界更清晰,所反映的储层地震响应特征更明显,预测结果更为准确。

图6 FG工区纵波单属性及无监督学习预测结果a 纵波均方根振幅; b 单一纵波无监督学习的预测结果

图7 FG工区含气地震储层的地震响应激活前、后预测结果a 基于SVR监督学习的预测结果; b 利用激活函数处理得到的结果

图8 FG工区含气储层预测结果
以多波地震数据为基础,综合利用无监督学习与监督学习方法进行地震油气储层预测,不仅有助于降低属性反演的多解性,而且能更好地突出地震油气储层特征。
4 结论
本文所提出的基于无监督与监督学习的多波地震油气储层分布预测方法,融合了聚类分析及支持向量机等技术,是一种能有效刻画含油气储层分布边界的方法。
无监督学习的聚类分析算法是将数据集合分类,降低数据特征的维度。本文首先将多达几十种的纵、横波地震属性经过聚类优选降维得到6种属性;然后对该6种属性进行聚合计算,以突显纵、横波在油气地震响应敏感度的差异,为随后的监督学习提供了学习样本;再利用无监督学习得到表征目标区地震油气响应的地震属性,通过支持向量机建立学习样本(井点)与各个样点之间的内在联系,从而将目标区已知井油气特征推广到全工区。利用支持向量机学习集不仅降低了属性反演的多解性,而且使得所刻画的含油气储层边界更清晰。相比于单一纵波地震属性,多波聚合地震属性包含更多信息,能够突出油气敏感属性特征。相对于常规纵波支持向量机属性反演,多波支持向量机属性模型泛化能力更强,预测结果精度更高,油气边界刻画更清晰。该方法的预测结果与实际钻井结果的对比验证了方法的有效性。
致谢:感谢中石化勘探开发研究院提供了资料。感谢中石化勘探开发研究院魏修成、季玉新、陈天胜、刘春园及刘韬在本文完成过程中提供的支持和帮助。论文的完成过程中,王守进、杨修超、张建彬、赵传伟、丁仁伟及李桂花等做了不少工作,在此一并表示感谢。
猜你喜欢
建材发展导向(2021年19期)2021-12-06
非常规油气(2021年2期)2021-05-24
中国海上油气(2020年6期)2020-03-15
能源(2017年5期)2017-07-06
物理通报(2015年9期)2016-01-12
陶瓷学报(2015年4期)2015-12-17
浙江大学学报(工学版)(2015年6期)2015-03-01
传奇故事(破茧成蝶)(2015年6期)2015-02-28
火花(2015年1期)2015-02-27
能源(2014年8期)2014-08-25
