
基于知识图谱技术的电力设备缺陷记录检索方法
2018-07-26 05:56刘梓权王慧芳
电力系统自动化 2018年14期
刘梓权, 王慧芳
(浙江大学电气工程学院, 浙江省杭州市 310027)
0 引言
在电力设备的日常巡检和试验中,积累了大量关于设备缺陷情况的缺陷记录文本[1-2],而在缺陷的分级、消缺等处理工作完成后,相应的缺陷记录和处理记录往往闲置于系统中。另一方面,由于缺陷情况复杂多变,目前很多缺陷处理工作依赖于处理人员的知识与经验[3-4]。如果可以通过一条缺陷记录检索具有相同缺陷情况的历史缺陷记录,就可以借鉴前人的经验,参考以往的处理方法对该条缺陷记录的缺陷情况进行相应处理,这在实际缺陷管理中,尤其是对于知识和经验相对不足的处理人员有着重要的指导意义。然而,电力设备缺陷记录的复杂性给缺陷记录的准确检索造成了很大困难。虽然有相关的电力规范以表格形式对可能发生缺陷的部件和对应现象等进行了总结[5],但缺陷情况复杂多样,规范中的表格难以进行全面归纳。即使规范中存在相应的缺陷情况,也常常由于巡检人员的经验局限,而出现没有严格按照规范中的方式进行记录的现象,因此造成了缺陷记录的复杂性。另外,缺陷记录是以自然语言的形式进行描述,这进一步增加了计算机对缺陷记录的理解难度。
文本的检索效果依赖于文本的语义分析和表示方法的有效性。对于电力设备缺陷文本,类似于文献[5],文献[6-7]通过人工经验确定语义框架,通过框架的填充对文本进行表示,但语义框架的二维表形式缺乏灵活性,难以适应复杂的电力设备缺陷情况[8],且框架的定义依赖于人工经验,难以全面考虑缺陷记录多样化的表达方式。为避免人工经验的局限,文献[9-12]采用机器学习算法,借助计算机自动挖掘缺陷记录中词级别的规律,从而基于词的统计特征对文本进行表示。然而,机器学习方法所选取的特征基本上局限于关键词的出现与否[9-10],或者词的出现频率[11-12],这些统计特征虽有一定的规律性,但对句中关键词的内在逻辑缺乏充分考虑,可解释性不足,容易局限于缺陷记录的字面特征。
缺陷文本基于设备缺陷实际情况进行记录,文本信息之间有明确的逻辑关系。因此,本文利用知识图谱的图结构对文本信息及其之间的关系进行表示,突破语义框架二维表结构的局限,在充分考虑缺陷文本信息内在逻辑的基础上,再利用自然语言处理、机器学习等技术,从缺陷语料中自动提取构建知识图谱所需的信息,从而实现知识图谱的自动构建,并在此基础上提出了缺陷记录的自动检索方法。
1 知识图谱技术
1.1 知识图谱的定义与分类
知识图谱本质上是一个知识库,是一个将实体和属性通过关系进行联结和组织的知识网络[13]。构成知识图谱的基本单元是“实体—关系—实体”或“实体—关系—属性”三元组。将知识图谱表示为图的形式时,实体和属性以节点形式存在,关系以连接两节点的有向边形式存在。这些三元组通过共有的实体或属性进行结合,形成了具有网状结构的知识图谱。
知识图谱分为开放域和封闭域两类[13]。开放域知识图谱不限定知识领域,要求知识覆盖较广,主要用于搜索引擎。开放域知识图谱会存在实体歧义、关系难以穷举、专业性不强、噪声大等问题,因此应用深度受到局限。封闭域知识图谱一般是行业知识图谱,只能应用于特定行业,其知识专业性较强,噪声较小,实体、属性和关系也可根据需求进行限定和穷举,因此应用可以比较深入,更具有针对性。
1.2 知识图谱的构建
知识图谱构建的一般过程主要分为3步,即知识抽取、知识融合、知识加工[14]。
知识抽取主要是抽取出非(半)结构化数据包含的实体、属性和关系,作为构成知识图谱的基本元素。知识融合先对抽取出的实体进行实体消歧和共指消解:实体消歧是对可能存在多种含义的实体名称(如“苹果”可能指水果,也可能指公司名称)进行区分;共指消解是将具有相同含义和指代的名词和代词在知识图谱中进行合并。然后对实体、属性和关系进行整合并加入现有结构化数据,初步形成知识图谱。知识加工是一个动态过程,在知识图谱不断应用的过程中,评估其数据质量和应用效果,并结合知识的发展与丰富,对知识图谱进行更新与修正。
2 电力设备缺陷知识图谱的自动构建
2.1 电力设备缺陷知识图谱的构建过程
电力设备缺陷记录通常以单个句子的形式存在,一般都以自然语言记录缺陷的设备部件、现象、程度等内容。由于电力设备缺陷记录有其自身特点,本文在构建电力设备缺陷知识图谱时,在知识图谱构建一般过程的基础上进行以下修改。
1)在电力设备缺陷中,缺陷现象作为缺陷部件的属性,本身还具有缺陷程度等属性,故除抽取实体间及实体与属性的关系外,还要抽取属性间关系。
2)电力设备缺陷知识图谱属于封闭域知识图谱,实体词义仅限于电力领域,且电力行业有明确的术语规范,实体歧义问题基本不存在,省去实体消歧步骤。
3)在共指消解时,属性也会出现同义词现象,也要进行共指消解。另外,封闭域数据量相对较小,应先对实体/属性进行共指消解,再抽取关系,使同一个实体/属性对能获得更多的关系训练样本。
4)文献[5]以表格形式归纳了部分三元组,可作为训练样本用于关系抽取,以充分利用结构化数据。
5)关系抽取完成后,需要对关系进行筛选处理,避免关系出现冗余,影响知识图谱的后续应用。
6)数据整合步骤将实体、属性及关系形成的三元组,连同文献[5]包含的三元组进行整理与合并,形成图结构的电力设备缺陷知识图谱。
上述修改后的知识图谱构建过程如图1所示。除了数据整合方法与一般知识图谱基本一致,其余步骤都需进行针对性设计,以下将进行重点阐述。

图1 电力设备缺陷知识图谱的构建过程Fig.1 Construction process of defect knowledge graph for power equipment
2.2 实体/属性抽取
实体/属性抽取的主要任务是抽取电力设备缺陷记录语料中表示实体/属性的词,并进行词性标注。由于实体和属性可以穷举,可直接采用电力专业词典对其进行匹配和抽取[7],具体步骤如下。
1)分词。首先对电力设备缺陷记录语料进行分词。分词基于常用词词典和隐马尔可夫模型(HMM),并导入电力专业词典辅助进行分词,以提高准确率。
2)词抽取。将分词后的语料中的词逐一在电力专业词典中进行检索,若能检索到匹配项,则抽取该词表示的实体/属性作为知识图谱的实体/属性。
3)词性标注。利用常用词词典与电力专业词典中词的词性对语料中所有词进行词性标注[15],并将所有词分为5类:①描述电力设备及部件的名词,表示实体,词性为“En”(前缀E表示Entity);②描述缺陷现象的动词,表示属性,词性为“Pv”(前缀P表示Property);③描述缺陷程度的副词,表示属性,词性为“Pad”;④描述缺陷程度的量词,表示属性,词性为“Pq”;⑤未在词抽取步骤被抽取出来的词,不表示实体或属性,词性按原词典标注。
2.3 共指消解
电力设备缺陷记录文本中基本不包含代词,因此共指消解不需要考虑代词,其主要任务是查找出所有表示实体/属性的词当中的同义词,步骤如下。
1)按词性分类。两个同义词的词性一定相同,因此可以将所有表示实体/属性的词按照4种词性划分为4个集合,分别对每个集合进行同义词识别。
2)向量化。为刻画表示实体/属性的词间的语义相似度,采用word2vec方法对缺陷记录语料进行训练[16],将词向量维度选为100维[17],得到语料中所有词对应的词向量,再通过计算词向量之间的余弦相似度,判断表示实体/属性的词间的相似程度。
3)筛选词对。对词进行向量化时,在句中位置邻近的词(邻近词对),如“主变本体储油柜锈蚀”中的“储油柜”与“锈蚀”,或者上下文相似的词(同位词对),如“主变本体储油柜锈蚀”中的“储油柜”与“主变本体油枕锈蚀”中的“油枕”,都有较高的余弦相似度[18]。显然,同位词对才是所要寻找的同义词,而同位词对的两个词基本不可能出现在同一条缺陷记录中。因此,可删除在同一条缺陷记录中出现过的词对,从而剔除邻近词对,筛选出同位词对。
4)形成同义词表。将含有相同词的同位词对合并为一个同义词集,从而形成若干个同义词集,并在每个集合中选择一个词,作为集合内所有词的标准化名称,最后以同义词表的形式来表示同义词集。
2.4 关系抽取
关系抽取主要任务是识别各实体/属性间是否存在关系及相应关系类型。电力设备缺陷知识图谱可以结合实体/属性的词性对关系进行限定,如表1所示。

表1 实体/属性间的关系类型Table 1 Relation types of entities/properties
由此,关系抽取任务转化为分类问题,训练集由文献[5]提供。由于训练样本较少,监督训练方法分类效果不佳,故采用半监督协同训练方法进行分类。
关系分类前,先形成待分类的词对,即在所有表示实体/属性的词的两两组合中,筛选出属于表1中4种词性组合的词对,然后对每个词对进行关系分类。具体的关系分类流程及相关说明见附录A。
2.5 关系筛选处理
关系筛选处理主要对冗余的包含关系进行删除。由于巡检人员往往不会严格按照规范逐级记录缺陷部位,如“主变冷却器系统风扇故障”可能被记为“主变风扇故障”,因此,“主变”与“风扇”虽然不是直接包含关系,但在关系抽取时,也很有可能被识别为具有包含关系,从而出现如图2所示的结构。
可见,“主变”与“风扇”间的包含关系可通过知识推理进行识别。如果表示出所有间接包含关系,将大大提高知识图谱的复杂性。因此统一删除间接包含关系,具体方法是:检测每个具有包含关系的实体对中两个实体间是否存在另一条路径连通两者,若存在则删去两者间的包含关系。如“主变”和“风扇”间还存在另一条路径“主变—冷却器系统—风扇”,故删去“主变”和“风扇”间表示包含关系的边。

图2 包含关系的实例Fig.2 An example of inclusion relations
3 电力设备缺陷记录检索
3.1 缺陷记录检索的实现方法和问题
电力设备缺陷记录检索的任务就是在缺陷记录集中,找出与给定的一条缺陷记录所描述的缺陷情况(包括发生缺陷的设备类型和部位、缺陷的现象、缺陷程度和量化单位)都一致的所有记录。具体实现时,可以将给定的缺陷记录与缺陷记录集的记录逐条匹配,并输出所有匹配成功的缺陷记录。
从知识图谱的角度看,两条缺陷记录描述的缺陷情况一致,等价于这两条缺陷记录在知识图谱中对应的实体路径和属性节点所连成的完整树完全一致。因此检查两条缺陷记录是否匹配,只需要找出每条缺陷记录对应的完整树,再对两完整树进行比对即可。
2.5节已提及,巡检人员往往不会严格按照规范逐级记录缺陷部位,因此寻找缺陷记录对应的完整树时,需通过缺陷记录已有信息推理出缺少的实体,以构成完整的实体路径。若缺少关键缺陷部位信息,则可能无法明确定位到缺陷主体,如缺陷记录“主变呼吸器硅胶变色”,“呼吸器”可能是主变本体的呼吸器或有载开关的呼吸器,此时该记录没有唯一对应的完整树,应给出错误提示1,表示关键信息缺失;如果多记了缺陷信息,如“主变本体有载呼吸器硅胶变色”,同样难以确定“呼吸器”位于本体还是有载开关,应给出错误提示2,表示关键信息矛盾。
3.2 基于图搜索的缺陷记录检索过程
以图3所示的知识图谱结构为例说明检索过程,节点a至i对应En词性的实体,节点j和k对应Pv词性的属性,节点l对应Pad词性的属性,节点m对应Pq词性的属性。寻找某条缺陷记录的完整树时,先对其进行分词和词性标注,再对照同义词表将缺陷记录中所有词规范化为标准名称。假设规范化后缺陷记录包含节点b,c,d,i,j,m和l代表的实体/属性,则在知识图谱中标记对应节点,如黄色节点所示。然后按图4流程确定缺陷记录的完整实体路径。

图3 知识图谱结构示例Fig.3 Example of knowledge graph structure

图4 查找完整实体路径的流程Fig.4 Searching flow chart for full entity path
对应图3的结构,将按照以下步骤进行。
1)输入与被标记的Pv节点j匹配的En节点i,并设其为节点N。
2)令有序集合S为空集。
3)用深度优先搜索方法搜索N向上的一条未搜索过的路径,则从N出发将搜索边1→2→3,相应经过的节点依次为i→f→e→g,故形成的有序集合R为{i,f,e,g},但R中未包含所有被标记的实体节点。
4)继续搜索新路径,将退回上一分支点e,从节点e开始搜索边4→5,可得到新路径的R为{i,f,e,b,a},R中同样未包含所有被标记的实体节点。
5)继续搜索新路径,将退回上一分支点f,从节点f开始搜索边6→7→8→5,可得到新路径的R为{i,f,d,c,b,a},R中包含了所有被标记的实体节点,且S为空集,故令S=R。
6)继续搜索,已无新路径,此时S不为空集,故输出完整实体路径中的节点有序集合S。
如果节点c和d未被标记,表明根据缺陷记录无法判断节点f代表的实体来源于节点d还是e代表的实体,此时步骤4中S将变为非空集,从而在步骤5中输出错误提示1;如果节点e被标记,则会对节点f代表的实体来源造成混淆,相应地会在搜索完所有新路径后S仍为空集,从而输出错误提示2。
最后,将完整实体路径的S中所有节点与被标记属性节点连接即可形成完整树,如图3中缺陷记录完整树包含的节点为{a,b,c,d,f,i,j,l,m}。
4 算例分析
4.1 算例情况
为研究基于知识图谱的电力设备缺陷记录检索方法的效果,以变压器缺陷记录为例进行实验。选取某电网公司3 000条变压器缺陷记录并随机均分为3份:第1份中所有正确记录作为训练集,第2份作为待检索的语料库,第3份作为测试集。构建变压器缺陷知识图谱时,使用训练集的所有记录作为非结构化数据来源,并且在第1个知识图谱模型“KG1”中不加入结构化数据信息,而在第2个知识图谱模型“KG2”中加入文献[5]包含的结构化数据信息。完成知识图谱构建后,将测试集的记录逐条作为输入记录,检索语料库中与其匹配的所有记录。
另外,采用基于机器学习的潜在语义索引(LSI)和潜在狄利克雷分布(LDA)模型作为对照,进行缺陷记录检索。模型基于Python的gensim工具包实现。
评价缺陷记录检索效果时采用准确率、召回率、F1值三个指标[19],分别反映检索的精确程度、全面程度和两者的综合效果。
4.2 变压器缺陷知识图谱的自动构建结果与分析
用训练集中正确的缺陷记录自动构建知识图谱,并加入文献[5]包含的结构化数据信息,构成了包含490个节点和614条边的变压器缺陷知识图谱,其局部如附录B图B1所示。然后对构建过程的关键步骤,即实体/属性抽取、共指消解和关系抽取进行分析。
实体/属性抽取时,只要电力专业词典中表示实体/属性的词在缺陷语料中出现,就可以被抽取出来,抽取过程本身不存在准确率的问题。为直观说明实验中基于电力专业词典的实体/属性抽取过程,将抽取过程的一个典型实例展示于附录B图B2。
共指消解步骤中,对所有表示实体/属性的词两两构成的词对,进行是否同义词的判别,可得:

(1)
统计得到共指消解准确率为94.8%,其错误情况主要是无法识别出现频率很低的词的同义词现象,如“呼吸器”和“吸潮器”(“吸潮器”词频很低);或者将上下文情况很相似的近义词误识别为同义词,如“变色”和“饱和”(都用于描述硅胶现象)。
2.4节提到,关系抽取实质是关系分类问题,故有
关系抽取准确率=
(2)
统计得到关系抽取的准确率为92.2%,其错误原因主要是某些词对在电力设备缺陷记录语料中对应的实例较少,以及半监督协同训练采用的机器学习模型本身具有一定的不确定性。
需要说明的是,上述准确率是基于1 000条训练记录训练后的统计结果。随着训练记录数量的增加,词频过低、实例过少等问题将进一步改善,从而使知识图谱构建的准确性更高。另外,知识图谱构建完成后,在检索时无需重复构建过程,只进行图搜索即可。
4.3 缺陷记录检索结果与分析
采用LSI,LDA和知识图谱模型分别检索测试集1 000条缺陷记录在语料库中的匹配记录,并将1 000条测试记录的混淆矩阵取平均(将所有混淆矩阵相加后除以1 000),得到附录B表B1所示结果,再进行统计后得到表2所示的结果。

表2 各种模型的检索结果统计Table 2 Retrieval result statistics of different models
由表2可见,知识图谱模型相对于LSI和LDA模型,在准确率、召回率和F1值上都有明显的优势,且加入结构化数据信息能进一步提升检索效果。从原理上看,知识图谱的优势是可以准确地识别关键信息、匹配同义词和进行知识推理,而不局限于字面上的相似度,并充分结合了电力领域的知识,具有很强的针对性,这也是传统语义分析方法难以实现的。为了更直观地反映知识图谱的上述优势,以表3中两组缺陷记录的匹配为例进行说明。
采用LSI,LDA和知识图谱模型分别判断每一组的两条缺陷记录是否匹配,结果如表4所示。
对于A1和A2,虽然两条记录只相差一个词,但这个差别决定了两条记录描述的是不同的两个瓦斯继电器上的缺陷,显然两条记录不匹配。由于两条记录在字面上很相似,通过LSI和LDA模型难以进行区分,但知识图谱模型可以将两条记录定位到不同的完整树,从而判断其不匹配,如附录B图B3、图B4所示。

表3 两组缺陷记录实例Table 3 Two groups of defect record examples

表4 各种模型对表3中两组记录匹配关系的判断结果Table 4 Judgment of different models to matching relation of two groups of records in Table 3
对于B1和B2,两条缺陷记录没有相同的词,但实际描述的是同一部件的相同缺陷现象。由于两条记录文本在字面上相差较大,通过LSI和LDA模型难以识别出其匹配关系。而知识图谱模型除了可以识别“在线滤油装置”与“滤油机”、“报警”与“告警”这两对同义词外,还可以通过节点的连接推理出两条缺陷记录对应同一完整树,如附录B图B5、图B6所示。
为了从理论技术层面对上述现象进行说明,通过编辑距离(LD)刻画两条缺陷记录间的字面差别度[20],LD越大则字面差别度越大,从而研究LD对检索效果的影响。采用LSI和KG2模型检索一条测试记录在待检索语料库中的匹配记录时,首先将语料库的所有记录按照与该条测试记录的LD划分为10个子集(LD=0的记录舍去,LD≥10的记录统一为一个子集),然后分别在10个子集中进行检索,得到10个混淆矩阵。按照这一方法检索1 000条测试记录后得到10×1 000个矩阵,再将每种LD下的1 000个矩阵取平均,最终形成10个平均矩阵,并通过平均矩阵统计10种LD下的准确率和召回率,如图5、图6中的折线图所示。由于不同LD下的模型准确率(召回率)对模型总体准确率(召回率)的影响程度与该LD下模型准确率(召回率)计算的基数有关(如模型准确率计算的基数为“被模型判别为匹配记录的数目”),基数越大则影响程度越高,故将每种LD下的指标计算基数展示于图5、图6中的柱形图。
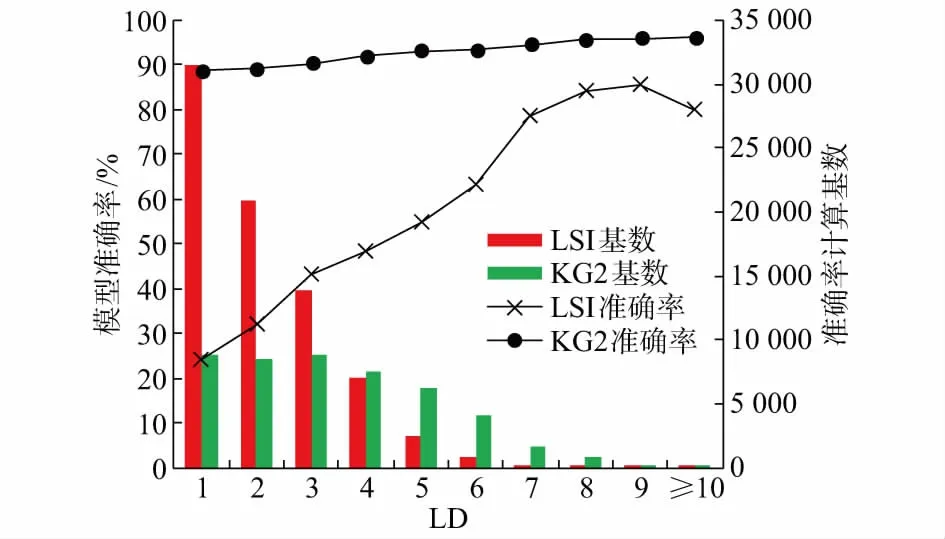
图5 不同LD下的准确率及计算基数Fig.5 Precision rates and calculation bases under different LDs

图6 不同LD下的召回率及计算基数Fig.6 Recall rates and calculation bases under different LDs
由图5可见,总体上LD越小,LSI模型准确率越低,即越倾向于将非匹配记录识别为匹配记录(类似于表4中A组情况),且其计算基数随LD减小而增大,进一步降低了模型的总体准确率;由图6可见,LD越大,LSI模型召回率越低,即越倾向于将匹配记录识别为非匹配记录(类似于表4中B组情况),但其计算基数总体上随LD增大而减小,一定程度上减弱了对模型总体召回率的影响。
相比而言,KG2检索效果受LD的影响明显要小。LD影响KG2检索效果的原因主要是KG2本身构建过程中共指消解和关系抽取步骤有可能存在错误。对于匹配记录,LD越大,意味着需要正确识别的同义词或关系越多,故受到共指消解和关系抽取中错误影响的概率也更大,从而召回率降低;对于非匹配记录,LD越小,意味着一旦有少量区分两条记录的信息点识别有误(如非同义词被识别为同义词),模型就会出现误判别,影响准确率。
5 结语
本文在电力设备缺陷记录检索中引入了知识图谱技术,提出了基于知识图谱技术的缺陷记录检索方法,详细阐述了电力设备缺陷知识图谱的构建过程和缺陷记录检索过程中基于知识图谱的图搜索方法,并通过算例证明了知识图谱模型在检索效果上的显著优越性,从而可通过现有缺陷的记录,检索相似的历史缺陷记录及对应的分级、消缺等记录,为现有缺陷的处理提供有效指导。
如果能够利用句法分析等自然语言处理技术,在共指消解和关系抽取步骤中提取更多的语义特征,将有利于提高这两个关键步骤的准确性和知识图谱构建的精确性和完整性,从而进一步提升缺陷记录检索的效果,这也是后续研究的重要方向。
猜你喜欢
少先队活动(2020年12期)2021-01-14
江苏安全生产(2020年7期)2020-09-04
意林图解作文(小学版)(2019年6期)2019-07-16
中成药(2017年3期)2017-05-17
现代工业经济和信息化(2016年22期)2016-08-23
领导科学论坛(2016年9期)2016-06-05
专利代理(2016年1期)2016-05-17
电测与仪表(2016年18期)2016-04-11
电测与仪表(2014年10期)2014-04-04
杂草学报(2012年1期)2012-11-06
