
基于多维度关联的机构知识库数据模型的构建与分析
2018-07-25 09:10:30上海交通大学图书馆上海200240上海旅游高等专科学校图书馆上海2048
现代情报 2018年7期
孙 翌 胡 爱(.上海交通大学图书馆,上海 200240;2.上海旅游高等专科学校图书馆,上海 2048)
我国于2004年签署了旨在支持开放存取的《柏林宣言》。2014年全球研究理事会(Global Research Council,GRC)在北京召集各国科技界领袖共同推进开放获取,国务院总理李克强在大会上的致辞中指出:“各国应采取多种方式,促进知识科学的广泛传播与共享……。中国奉行互利共赢的开放战略……,支持建立公共财政资助的科学知识开放获取机制,促进中国和世界科学事业共同发展”[1]。这从国家层面提出了国家支持的科技成果最大限度全民共享的要求[2]。机构知识库是开放获取中的重要知识服务基础设施,称为开放获取运动中的绿色OA模式,对各种数字化产品(尤其是学术机构中专家、教授、学生的知识成果)进行收集、保护和传播[3],是科研人员跨机构传播知识、交流知识,科研机构管理知识的重要平台,它消除了利用学术资源的价格壁垒和许可壁垒,在促进学术信息免费获取、自由使用中发挥了重要作用。
机构知识库经过多年的建设,在高校等科研机构开放获取资源的数量日益增多,并呈海量增长的态势。然而,随着资源数量激增,相关问题也逐渐涌现,主要表现在如下几个方面:
1)数据的大量涌现给人们利用机构知识库查找和利用知识增加了难度,“信息超载”和“信息孤岛”问题越来越严峻。学科馆员和学者向机构知识库存缴的学术资源逐日增加,从数据海洋中获取有用资源如大海捞针。
2)机构知识库内部存储的科研成果数据在建设时缺乏标准,组织方式不完善。纵观近些年的机构知识库研究,关注重点是开放获取、长期保存、机构知识库政策等[4],对于知识组织架构的研究较少,以科研与教学角度出发的系统架构相关研究则更少,从而,无法为用户提供深层次的知识服务。
3)机构科研环境的变化也对机构知识库提出了新的要求。机构知识库已由最初的教育、科研机构存储本机构成果的工具,转变为重要的知识管理和传播平台。机构知识库的建设逐渐以资源收集为中心到以利用为中心的转变,这要求机构知识库建设人员转变理念,深度整合资源,重视知识产出之间语义关联关系管理[5]。
机构知识库建设环境的变化指明了机构库发展的新模式。为满足科研人员日益增长的知识需求,机构知识库建设者需要提出系统的资源组合方式,积极探索知识对象间的多维关联组织。
1 研究现状调研
科研领域的开放关联环境促使机构知识库向促进学术成果广泛传播、利用转变。机构知识库越来越强调科研成果内容单元的深度揭示与关联组织。然而,学者对机构知识库的知识组织方面关注尚缺,研究多集中在开放获取、长期保存、机构知识库政策和建设实践的探讨上。目前,从科研成果的深层次关联角度进行研究的,有开放获取知识库联盟的Eloy Rodrigues[6],在2012年的中国开放获取推介周国际研讨会上他强调,要发挥机构知识库的最大价值需要实现机构库间的互操作性。郎庆华[7]于2011年提出机构知识库多注重数字对象本身的联系,对知识之间关联揭示不足,无法实现对知识关联形成的知识网络进行浏览,极大地阻碍了机构知识库知识的再创造。李春秋[8]指出机构知识库的建设过程中,知识组织十分必要,唯有健全的知识组织方法,才能让更多的用户使用IR。梁娜[9]等提出机构知识库应不断加强对内容的结构化语义化组织,拓展与其他服务内容的动态关联。解金兰[10]等认为有效的数据管理和分析,有利于机构库进一步实现知识发现、数据融合与语义检索。王思丽等[11]在建设CASIR过程中,探索利用关联数据实现了机构知识库的语义扩展。侯瑞芳等[12]设计了一个数据转换模型,以实现文献实体与高校实体间的精准关联。李晨英等[13]组织内容时以人为中心,将教师与学术成果信息关联起来,使IR内容形成网状组织结构。周宇等[14]提出一种面向关联数据的机构知识库构建方法,用于支持机构知识的资源整合。知识组织的精髓在于揭示知识及知识间的关联[15]。面对全新的科研环境,需要提出一个多维知识聚合模型的组织架构,进一步揭示知识间细粒度的关联关系,为科研成果的广泛传播服务。而国内学者对机构知识库数据组织的研究多停留在对组织知识的必要性的探讨,由此可见,机构知识库建设对资源整合尚缺乏完善的标准。
2 主要技术调研
数据模型搭建的标准化资源描述框架,集成组织异构资源,对文本与非文本的科研成果进行信息揭示、描述、组织,提高了资源的可见性和检索性。本文对目前应用较广的Dspace系统和Fedora系统的数据模型进行了分析。
2.1 Dspace[16]数据模型
2002年,美国麻省理工学院和惠普公司开发了DSpace@MIT,CALIS成员馆的机构知识库大部分基于DSpace来构建[17]。Dspace构建的机构知识库以促进知识资产的长期保存为主要目标,数据模型组织数据的方式是映射机构的组织结构。Dspace6.x系统的数据模型主要由Community(社区)、Collection(合集)、Item(条目)、Bundle(数据包)、Bitstream(数据流)、Bitstream Format(数据流格式)这几个实体组成。单个的机构知识库组成一个社区,每个社区能根据机构的组织架构进一步划分为小社区。社区由合集组成,合集可以在多个社区呈现。合集由若干条目构成。每条条目由一个合集唯一拥有但可以在若干合集中呈现。一条条目由多个数据包组成,数据包内包含多个数据流。每个数据流都与独一无二的数据流格式相联系。其中,社区包含Handle属性,唯一标识一条社区记录。条目是归档的基本存档单元,包含Handle属性以唯一标识一条记录;Dublin Core属性使每个资源有一条Qualified Dublin Core元数据记录,用于实现互操作和自由获取;Withdrawn属性用于移除一条条目记录,移除后的条目虽然还存储在库中但不能被用户查看。大多数条目包含了原件、缩略图、许可等信息。数据流格式包含Support Level属性,表明机构未来保护知识内容的能力。
2.2 Fedora数据模型
Fedora是康奈尔大学在美国国家科学基金会和美国国防部高级研究项目机构共同资助下进行的关于复合数字对象模型的研究项目[18]。为了长期保存和传递各种类型的数字内容的本质特征,Fedora定义了一个通用数字对象模型。数字对象的基本组成包括数字对象唯一标识符、对象属性和数据流。一个数字对象可以包含一条或者多条数据流,数据流的内容可以是数据、元数据、关系描述等信息。通过使用数据流,数据和元数据统一封装。为了有效管理数字对象,模型定义了4种数字对象类型,包括Data Object(数据对象)、Service Definition Object(服务定义对象)、Service Deployment Object(服务配置对象)和Content Model Object(内容模型对象)。在Fedora3.0以后,引入了内容模型框架(Content Model Architecture,CMA)的管理方式,CMA为数字内容的管理对象化、服务化,提供了一个更加高效、灵活的管理模式[19],但主要的管理还是关注在数字资源上。
Dspace和Fedora构建的资源存储结构以知识资源为中心,能较好地实现保存资源的任务,并且具有一定的扩展性。随着机构知识库的建设逐渐成熟,机构知识库的目标向促进资源机构内外传播、助力知识发现创新的应用方向发展,关注点应跳出资源本身,对资源存在的环境和关联关系及时捕获。Dspace和Fedora模型对科研情境的关注不够,因此,无法完全适应机构知识库进一步发展的需要。故在对这两种模型进行深入分析后,本文针对它们科研环境揭示不足、关联关系维度单一等问题,设计了一个多维关联科研成果及其科研环境的灵活可拓展的数据模型,以完善资源组织方式,促进机构资源的全面利用。
3 概念与观点
3.1 多维度关联
维度是具有某一相同特征数据的集合,多维度则是从不同层次、不同角度呈现数据,数据之间可以有交叉。多维数据模型中的数据是以多维逻辑方式组织,数据在各个维之间相互交叉,形成立体的数据视图[20]。本文所述的多维度关联研究就是研究高校机构知识库资源之间的相互关系,从客观角度挖掘潜在的知识信息。
3.2 研究观点
从支持科研与教学的角度出发,寻找机构成果资源间、成果与人员、成果与机构、成果与团队的关联关系,并进行合理组织来满足科研工作者日益增长的知识发现的需求。针对高校机构知识库构建过程中普遍存在的知识组织、知识整合难题,通过设计数据模型,将科研机构的各类研究成果保存到机构知识库中,从而在机构知识库平台的建设实践中实现研究成果对象间深层次、多维度的数据关联。
4 数据模型概述
机构知识库面向机构内所有的用户,包括科研人员、学生、管理人员,收集、存储他们的研究成果。由于高校的科学研究存在学科类型多样,资源类型丰富等特点,机构知识库在对多学科成果构建模型时,无法使用通用的概念去描述全部多学科异构资源,因此,本研究设计一个通用的机构知识库数据描述框架,建立一个可供多种元数据标准共存的模型[21],为科学成果的集中、规范化组织管理与服务。
4.1 总体架构
为了总体了解机构知识库数据模型的逻辑框架,本文首先给出概念结构图,以期能简要呈现数据模型的面貌。这个概念模型模拟机构知识库的全部业务,罗列出机构内的科研对象以及对象间的关系。这一概念结构作为便于理解模型的工具,并不存在于数据模型中,它只是用于组织本文的虚拟结构,如图1所示。其中圆角矩形代表科研对象(圆角矩形内的词组即科研对象名称),直线代表科研对象间存在着联系。圆弧表示科研对象间的递归关系,即同一个科研对象间的关系。
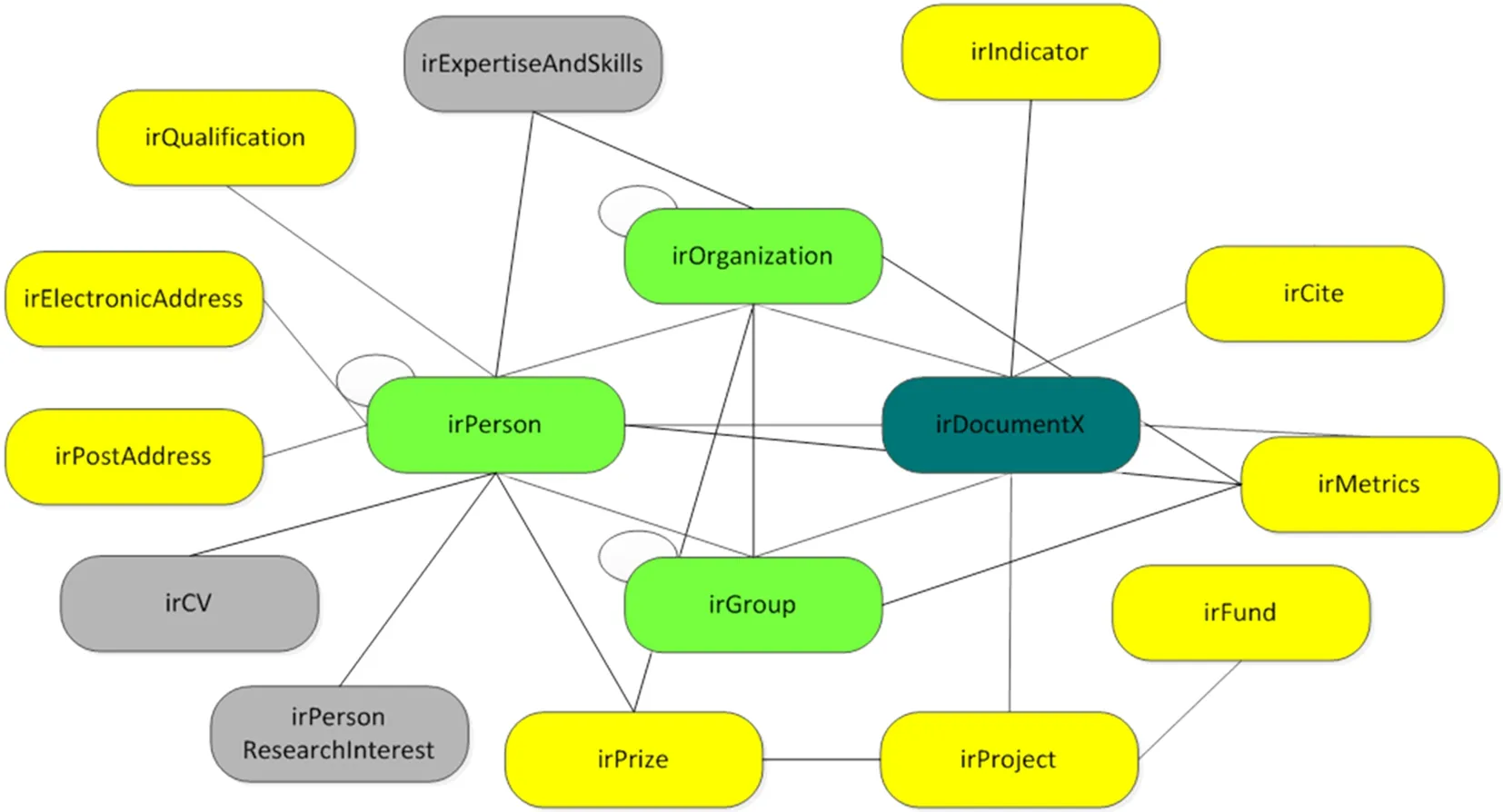
图1 数据模型实体间关系图
在构建的模型中,客观世界中的科研对象被抽象成由一系列描述特征的属性构成的科研实体。为了便于理解,本文采用了一套配色方案以表现数据模型中涉及的不同实体类型以及特征,并用一套表示方法让计算机可识别,具体如表1所示。
在概念上,数据模型由一系列实体类型和特征组织而成。实体类型分为核心实体、二级实体、链接实体和虚拟实体。在特征上具有多语言、语义和附加特征。这一概念模型的部分将会在下文持续以抽象图的形式呈现。物理层的技术细节则会以ERM(实体—关系—模型)子模型的形式呈现。抽象图中,实体名是以完整名来描述概念(Person),在物理图中则是以ir做前缀的简称(irPers)。

表1 数据模型类型及表示方法
为了更好地理解模型,表2具体列出了机构知识库数据模型实体分类的详情表,实体名后是实体在数据模型中的名称表示。表中列举了所有的核心实体和二级实体,由于链接实体含义相似数量庞大,为避免赘余故此处只列举出部分。
核心实体是机构知识库的主要组成部分。二级实体以核心实体为基础拓展,对研究的语境进行呈现。链接实体确立了实体以及实体之间的关系,实现语义关联。为了降低模型的复杂性,本文建立了多种成果类型的虚拟集合,即成果实体(irDocumentX),方便对多种类型的资源进行统一管理。它是数据模型中的唯一一个虚拟实体,也属于核心实体。成果实体的成果类型根据需求调研中研究人员的期望选出,包括学术论文、学位论文、专著、报告、标准文献、专利、数据集、音视频、课件、图片这11种资源。与成果实体关联的各类资源继承它的属性并且拥有各自的属性。把机构内的数据实体划分为核心实体、二级实体、链接实体这3种类型,使模型结构更加清晰,这3类实体对具有相同特征的实体归类,并不描述机构的任何科研对象。

表2 机构知识库数据模型实体分类表
此外,每个实体对应具有特定属性,用于描述该实体。下面以人员实体、机构实体以及人员与机构的链接实体为例呈现实体对应的属性描述。
1)irPers实体属性
为了唯一识别一条人员记录,提供了irPersId属性。任何人员都可以在数据库中建立一条记录。

表3 irPers实体属性
2)irOrg实体属性
主要描述的是人员所属的机构信息,此处所述机构表现的是高校内部的层级架构,机构的信息相对固定。

表4 irOrg实体属性
3)irPers_Org实体属性
人员与机构之间存在归属关系,一个人可以归属于某个机构,也可以归属于多个机构,这个关系表表示的是人员与机构内部组织的从属关系。开始时间和结束时间表示人员与机构的关系在某个时期内存在。

表5 irPers_Org实体属性
4.2 实体类型
4.2.1 核心实体
核心实体是机构知识库的主要组成部分,传统的机构知识库以典藏的角度演变而来,主要以成果资源为核心实体,而本研究以成果实体(irDocumentX,其中X代表多种文献类型)、团体实体(irGroup)、人员实体(irPerson)和机构实体(irOrganization)4个核心实体组成,以满足从团队、人员、机构3个角度进行研究成果的深度分析。如图2所示,表现了实体之间的连接关系,每个核心实体不仅自身内部数据需要进行关联,同时也需要与其他核心实体相关联。图中的圆圈表示实体之间的递归关系,即同一个实体间的关系。机构、团体、人员实体都存在递归关系。由于irDocumentX是作为虚拟实体存在的,它的递归关系在多种资源实体中得以体现,并且每一种类型的资源实体都能与机构、人员、团体相连。此处使用虚拟实体是用irDocumentX实体来指代各种类型的资源实体,便于管理的同时使模型关联关系更加简洁,同时让成果类型可以根据机构需要任意添加,具备扩展性。
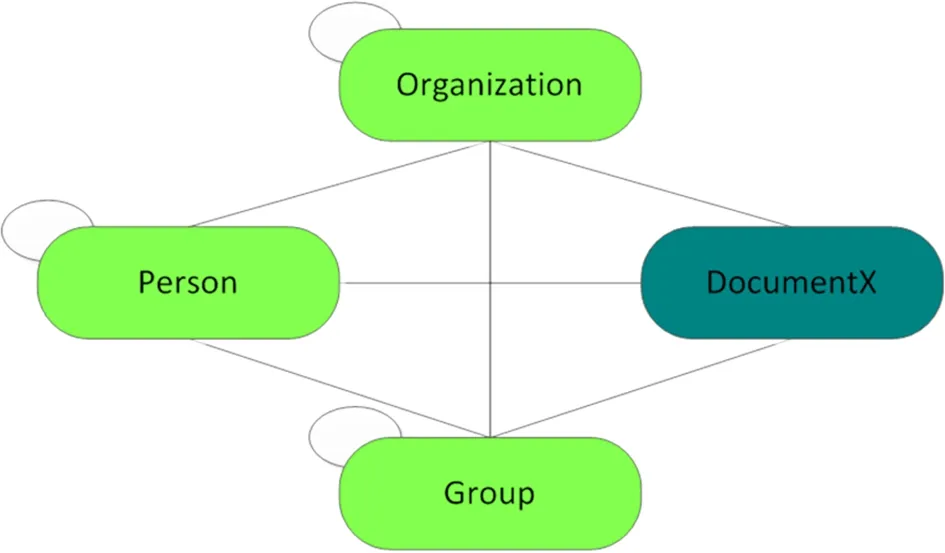
图2 数据模型中的核心实体(抽象图)
图3以ERM视角展示了成果、团体、机构、人员4个核心实体以及一些与它们相关的实体。在图3中的递归关系是指单个实体间的联系,即Person间、Group间、Organization间和DocumentX间。在图中,这些实体的递归关系以链接实体(irPers_Pers、irOrg_Org、irGro_Gro)的方式体现。由于成果实体是虚拟实体,其多种类型的资源间的递归关系在此不详细呈现,其与其他实体之间的链接关系在图中呈现。图中名称为irPers_DocX、irPers_Gro、irPers_Org、irGro_DocX、irGro_Org、irOrg_DocX的实体也叫做链接实体,主要阐述两个实体之间的关联意义,其作用将会在链接实体部分做具体介绍。
4.2.2 二级实体
除了核心实体外,数据模型中还添加了很多的二级实体,名称分别是irMetrics、irCite、irIndicator、irFund、irProject、irPrize、irQualification、irPAddress、irEAddress、irEdition。如图4所示,二级实体围绕着4个核心实体展开,通过与核心实体连接以实现对研究语境的呈现。
二级实体与核心实体相关联。每一个二级实体都有一些共同的属性特征,例如至少都有ID和URI属性。二级实体之间的联系以及它们的多语言特征在图中并没有完全呈现出,这部分内容将在模块分析时逐一介绍。二级实体与其他实体关联生成的链接实体具有的语义通过ClassId和ClassSchemaId属性在语义层中定义。
4.2.3 链接实体
链接实体的是本模型表现多维度关联的重要环节,数据模型中用于表示实体与实体之间的联系或者关系的实体为链接实体,通常将两个实体连接起来。图5为核心实体之间的联系抽象图,图中展现出核心实体之间关联产生的链接实体(Person_Organization、Person_Group、Person_DocumentX、Group_Organization、Group_DocumentX、Organization_DocumentX)。其中,表示人员发表各类成果、人员隶属于高校的某个机构、几个归属于某个团队、团队产生成果、团队可能属于某个部门之下、机构是成果的拥有者等。
数据模型中所有的链接实体的结构和功能在物理层面上是一致的,表6从元数据的角度展现了链接实体的结构和功能。

图3 核心实体、核心实体间的递归以及其他链接关系(物理视图)

表6 数据模型元数据视角的链接实体图
链接实体的物理名称由两个相连的实体的物理名称共同组成,并且包括机构知识库的前缀ir,表示方法如下所示:irEntity1Name_Entity2Name。链接实体名称的顺序意味着它们的两个唯一标识符属性的顺序,第一个(irInheritedEntity1Identifier)继承于irEntity1Name;第二个(irInheritedEntity2Identifier)继承于irEntity2Name。在链接实体中所有的标识符在元数据层面都会标记为继承,因为它们并不来自于链接实体,而是从其他实体中继承的,例如从irEntity1、irEntity2、irClass、irClassScheme继承。所有的链接实体在两个实体间建立联系都是通过继承两个实体的唯一标示符irInheritedEntity1Identifier和irInheritedEntity2Identifier(即ID)建立起来的。除此之外,通过irInheritedClassIdentifier和irInheritedClassSchemeIdentifier映射到语义层以及通过irFraction属性给分类(角色或类型)引用指派部分值,链接实体携带了语义。Classification和ClassificationScheme引用是强制要求的,但是Fraction属性不是必须的。同时,每个连接记录要求有起始时间和结束时间,以清楚说明链接作用的时间范围。继承的标识符属性和日期属性一起构成链接实体的主键。
4.3 数据模型特征
4.3.1 多语言特征
在学术环境下,许多学术信息在记录时需要不止一种语言去表达。多语言特征对于用多种语言保存学术信息的机构具有重要意义。图7展示了部分具有多语言特征的实体。它们的标识符(irProjId、irOrgId、irGroId)指向了它们原来的实体。存储在irLangCode属性之下的编码语言有两种值,中文(irLangCode=ch)和英文(irLangCode=en)。名字、标题、描述、关键词、研究兴趣等以特定的语言存储文本。

图4 数据模型的二级实体(物理视图)
4.3.2 语义特征
数据模型的语义特征是对应链接实体中关联关系的表现,也是通常所指的语义层。它利用Classification Schema来存储实体与实体、实体与属性之间的关联内容,在此语义特征部分提供了语义类型、扮演的角色、专业分类或映射等多个语义方式。语义特征层存储链接实体描述的语义值,通过ClassSchemaId属性,把每个语义值指派到特定的Classification Schema中。数据模型的语义层由Class和ClassSchema两种class类型的实体组成。另外,它允许对多语种的术语(irClassTerm)和术语描述(irClassDescr)的说明。这两种class类型的实体(irClass和irClassSchema)用两种递归实体(irClass_Class、irClassScheme_ClassScheme)内连接以说明结构和Classification和Classification Schema间的映射。数据模型语义层的递归实体始终支持Classification参考的小数部分的值[22]。
4.3.3 附加特征
根据机构知识库的建设环境,可建立不同的附加特征。例如将机构知识库的数据字段与Dublin Core等各类元数据模型进行字段映射,方便数据共享与交换。
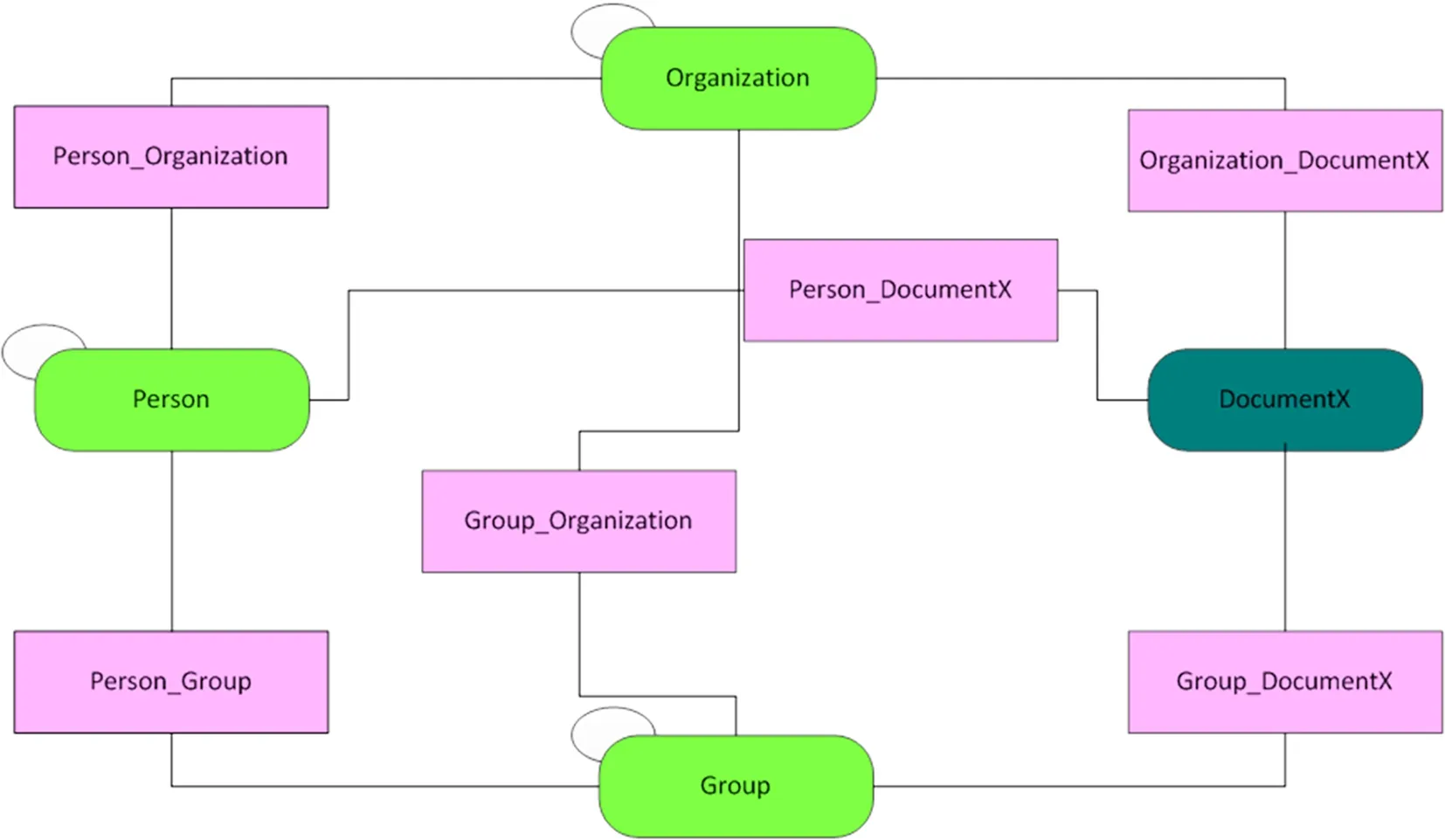
图5 数据模型链接实体关系图(抽象图)

图6 数据模型的链接实体样例(物理视图)
5 实体分析
5.1 人员实体(irPerson)
人员实体指的是所有成果资源的人员信息,包括创建者、申请人、受益人等。如图8摘录了部分Person实体与其他实体的连接关系,Person实体与其他核心实体的关系已在前文中介绍,在此不赘述。每个Person实体创建一个irPersID,由此ID与所有的外部实体以及属性进行关联,例如一个人可能有多个姓名的表达方式并且可能会变化,因此构建irPersName与irPers实体关联,关联后生成一个新的实体(irPers_PersName),通过实体的irClassId和irClassSchemeId属性映射到语义层对人名进行说明。
图7 部分有多语言特征的数据模型实体(物理视图)

图8 数据模型核心实体irPerson(物理视图)
如图8所示,人员实体与其它实体也建立了关联,进行关联的实体包括irPerson、irPrize、irQualification、irPostAddress、irElectronic Address、irExpertiseAndSkills、irPersonName、irCurriculumVitae、irClassification,所建立的关系分别为irPers_Pers、irPers_Prize、irPers_Qual、irPers_PAddr、irPers_EAddr、irPers_ExpSkills、irPersName_Pers、irPers_CV、irPers_Class。每个关系或者链接实体使用time-stamped属性通过irClassId和irClassSchemeId映射到语义层。此外,人员实体的人员关键词(irPersKeyw)、人员研究兴趣(irPersResInt)具有多语言特征。个人与个人进行合作。个人有获奖经历、职称、电子邮箱和通讯地址、强项、名字等信息。
5.2 机构实体(irOrganization)
本模型所阐述的机构指的是相对较稳定的学术团体,例如学院、研究所、实验室等。与Person实体的创建方式类似,在每个irOrg提供了id属性(irOrgId),机构实体与其他实体建立联系,包括Organization、Person、Prize、Expertise and Skills、Post Address、Classification,可分别表示为irOrg_Org、irOrg_Pers、irOrg_Prize、irOrg_ExpSkills、irOrg_PAddr、irOrg_Class。每个关系或者链接实体使用time-stamped属性通过irClassId和irClassSchemeId映射到语义层。另外,机构实体的机构名(irOrgName)、机构关键词(irOrgKeyw)、机构研究活动(irOrgResAct)具有多语言的特征。
5.3 团体实体(irGroup)
跨学科和跨机构的合作交流频繁,涌现出许多跨地区跨领域的科学研究。A机构人员研究成果可能B机构人员也参与其中,这类情况在项目合作、论文合作、专利合作等诸多方面均有体现。这样的团队合作信息可以被科研人员使用,用于寻找合作伙伴、追踪竞争对手。在此背景下,本模型设计了团体实体并将其作为核心实体,以记录团队合作产生的成果以及团队情况。此类科学研究涉及多家机构,除了本机构的科研人员参与外,也有其他科研人员做出贡献。本模型所阐述的团队实体相对机构实体而言较为松散,指的是非正式的创造出科研产出的科研人员的合集。
核心实体irGro提供了id属性(irGroId)。机构实体的通用属性还包括首字母缩写词、统一资源标识符以及团体成立和解散的时间(irAcro、irURI、irStartDate、irEndDate)。团体实体与许多其他实体可建立联系,包括:Group、Organization、Person、DocumentX、Classification,可分别表示为irGro_Gro、irGro_Org、irGro_Pers、irGro_DocX、irGro_Class。每个关系或者链接实体使用time-stamped属性通过irClassId和irClassSchemeId映射到语义层。另外,团体实体的团体名(irGroName)、团体关键词(irGroKeyw)、团体描述(irGroDes)也同样具有多语言的特征。
5.4 成果实体(irDocumentX)
成果资源的收集、建设是机构知识库生存、发展的关键。在传统的学术交流体系中,期刊论文是最重要的研究成果,也是研究人员获取学术信息的重要途径。在E-science环境下,信息化的科研环境得以建立。期刊论文作为科研过程中的最终产出,伴随着科研同时产生的数据集、图片、手稿等成果类型,对于重现科研流程、供研究人员研究学习同样具有极高的价值。在此环境下,科学研究开始向数据密集型科研转变:越来越多的科学研究不再从头开始,而是建立在对已有数据的重新认识、组织、解析、分析和利用的基础上,用不同的工具或方法、不同的时间段对同一组科学数据进行分析可以产生不同的结果[23]。在机构知识库中对多种类型资源进行保存、管理,使科研成果能为今后的科研人员获得对科研创新意义重大。
成果实体(irDocumentX)是四大核心实体之一,用于存放学术成果和数据资源。在此概念结构中irDocumentX是唯一的虚拟实体,它不作为实体存在而是用于指代机构知识库中不同类型的成果。机构知识库的成果资源中常用类型包括:学术论文、学位论文、专著、报告、标准文献、专利、数据集、音视频、课件、图片等。为了识别一条成果记录,成果实体irDocX提供了id属性(irDocXId)。如图9所示,本模型用irDocX指代了所有类型的资源,通过irDocXId与其他类型资源进行关联,生成例如irDocBook_DocX、irDocArticle_DocX、irDocPat_DocX等关系,既表明了资源与自身之间的关联,又表明了资源与其他类型资源之间的关联。以irDocBook_irDocX为例,当irDocX指代的是irDocBook时,表明了irDocBook与自身相关联(irDocBook_DocBook);当irDocX指代除irDocBook以外的资源时,表明了irDocBook与其他资源存在关联(如irDocBook_DocArticle、irDocBook_DocPat、irDocBook_DocImage)。资源自身的相互链接以及与其他类型资源的链接所生成的实体称为链接实体。资源实体之间链接实体的存在,指明了不同资源之间存在着或多或少的联系。期刊论文、会议论文、学位论文、专著、专利等传统文献出版物系由科研人员创作,经过同行评议出版发布,因此,这些出版物类型的文献知识产出由科研人员最初创作的研究手稿变化而来,文献出版物之间具有引用关系[24]。另外,在数据驱动的时代,科学数据集与科学文献的关系越来越密切。科学文献中为佐证结论形成过程,往往也包含文本格式的科学数据[25]。因此,为了数据模型的可扩展性,对不同资源间存在的相关关系会在irDocX与资源关联生成的链接实体中使用time-stamped属性通过irClassId和irClassSchemeId映射到语义层去定义。
5.5 其他实体
5.5.1 Metrics(irMetrics)
Metrics在机构知识库中的主要作用是机构评估,不同的机构知识库可以对其进行不同的定制,并且可以设置多个相关属性,以用来对科研人员、科研机构、科研团队和科研成果的评估,从而管理人才、选择优势学科、比较与竞争者的差距。
5.5.2 引用实体、贡献度实体(irCite & irIndicator)
Indicator和Cite都是针对成果(即DocumentX)的测量实体。Indicator在本模型中指的是对文献的贡献度,主要是对不同的人给予不同的贡献度的属性,以便对成果进行深入分析预评估;Cite在本机构库中指的是文献的引用情况。
5.5.3 项目实体、基金实体(irProject & irFund)
Project在本机构库中指的是产生成果输出的科研项目;Fund指的是科研成果所属的科研基金。
6 案例分析
根据多维度关联的机构知识库数据模型进行数据模拟,从上海交大学者王如竹的部分成果进行分析。他所属的研究领域为制冷及低温工程,在上海交大的制冷与低温研究所工作。他与吴静怡、王丽伟、郭开华、孙志高有科研协作关系。产出的大量论文中,《制冷技术发展与全球环境问题》为个人研究产出,《低品位热能驱动的高效热化学吸附式制冷研究》与王丽伟合作产出,另外6部作品分别是参与的团队A、团队B的共同产出。
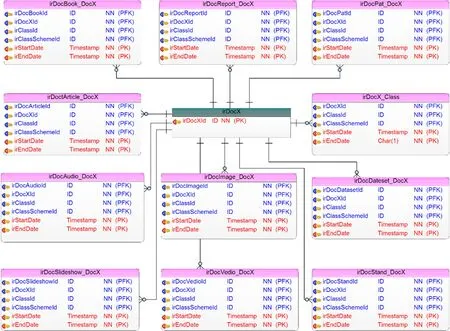
图9 成果实体内各资源类型的关系(物理视图)

图10 学者成果关联示意图
通过成果关联示意图可以看出,数据关联可实现以下功能:
1)关联发现学者个人信息:将个人履历、电子邮箱、通讯地址、奖项、职称与王如竹关联,通过王如竹可以直接获取与他相关的个人信息。王如竹的研究归属于制冷及低温工程研究所,通过机构实体将王如竹与王丽伟联系起来。
2)发现合作者:王如竹与王丽伟共同发表了《低品位热能驱动的高效热化学吸附式制冷研究》这篇论文,通过资源实体可认定他们是合作者关系。王如竹与吴静怡同样都是团队A的成员,那他们也具有合作者关系。通过是否拥有共同成果来鉴别,可以有效识别发现合作者关系。共同成果越多,合作关系越紧密。合作关系可用可视化图表来表示,某位学者与其他学者距离的远近,即代表合作关系的亲疏。
3)个人成果聚合:可以对各个学者的成果聚合,集中展示,其中包括个人作品、合作产出作品。
4)关联检索合作团队:王如竹除了存在于上海交大的制冷与低温研究院,还与其他学者组成相对松散的科研团队。将研究人员与团队也进行绑定,可以找到合作团队信息以及衍生作品。
5)个人评估:使用一套个人评价体系,分析科研人员的学术成就,从而进行个人评估。
从机构、团队、成果资源、项目等多个角度均可进行如图10相似的关联关系分析,经过分析发现,模型能较好地组织与聚合知识资源,实现关联知识,使科研人员更快、更完整地了解到相关信息。
1)关联检索:支持由一条成果记录,从作者、团队、机构、基金、主题等方式进行关联检索,发现相关知识;由一条研究人员记录,关联检索其个人信息(包括个人履历、电子邮箱、获奖经历等),从研究领域、合作者、团队、机构关联检索,发现相关知识。由一条机构记录,关联检索机构学者、团队等内容;由一条团队信息,从团队成员、所属机构等方式进行关联检索,发现相关内容。
2)聚合知识:提供从机构、院系、团队、研究人员、基金方式聚合的成果目录和聚类;根据文本间的引用与被引关系,揭示成果集合内蕴含的关系,进行成果引证关系的聚合;将内容上具有关联性和相似性的成果整合分析,聚合结构不同、表现形式不同的成果;提供语种、发布时间的知识聚合。
3)识别各类协作关系:支持通过数据挖掘和统计分析,识别研究人员间的协作关系、机构科研协作关系、成果引证关系。
4)科研产出力分析:统计个人、学院、团队每年成果产出量,通过比较个人间、学院间、团队间的投入和产出,从而进行绩效分析。
5)学科贡献度分析:统计属于某学科各类科研成果的个人、团队、院系贡献度,与其他机构比较,从而识别出机构具有学术竞争力的学者,发现优势学科,为人才评估、学科评估服务。
7 结 语
随着开放存取运动日趋深入人心,机构知识库建设也逐渐成熟,从最初长期保存知识资产为目标转变为向提供科研、教学服务的应用方向发展。不同于反映机构的等级结构的Dspace数据模型和将所有数字对象使用统一方式揭示的Fedora通用数字对象模型,本模型明确定义了人员、机构、团队、成果四类核心实体和具备一系列操作的二级实体,实体内容与行为操作分离使得数据模型具有拓展性。在以结构固定的机构架构组织的同时,学术团队的引入也是本模型的一大特色,团体相较于机构结构松散,在以往的数据模型中往往被忽视,但对于研究人员发现知识和寻找学术合作具有一定的意义。机构知识库作为机构知识基础设施,促进知识的长期保存,促进知识内外传播从而促进学术信息交流与评价的目标将会逐步实现,机构知识库也会朝着支持文本与多媒体知识、支持教育科研活动、支持机构知识管理方向发展,进而成为一个知识服务平台。
猜你喜欢
当代陕西(2019年15期)2019-09-02 01:52:00
制造技术与机床(2019年6期)2019-06-25 10:17:46
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:48
学苑创造·A版(2018年11期)2018-02-01 06:29:20
电子测试(2017年12期)2017-12-18 06:35:36
读者(2017年5期)2017-02-15 18:04:18
中国交通信息化(2016年9期)2016-06-06 07:42:23
图书馆研究(2015年5期)2015-12-07 04:05:48
测绘科学与工程(2013年1期)2013-03-11 15:07:24
中国土地科学(2011年11期)2011-03-20 16:26:50
