
基于降采样的堆模型预测大型规模网络课程的学习结果
2018-07-25 11:31:28林菲张展
计算机应用与软件 2018年7期
林 菲 张 展
(杭州电子科技大学计算机学院 浙江 杭州 310018)
0 引 言
学生表现预测问题PSP(predicting student performance)是教育数据挖掘EDM(education data mining)中一个很重要的课题[1]。随着互联网的发展学习的形式发生了巨大变化,慕课又称大型开放式网络课程MOOC是一种新型的学习方式,近年来受到了很多关注。在MOOC的背景下PSP问题显得更加复杂,因为MOOC打破了传统教育模式中空间、时间和学习年龄的限制,大量的互联网用户以不同的目的去学习。传统的PSP研究并没有考虑到MOOC场景下学习者表现分布的不平衡问题以及多门课程混合建模时带来的数据分布干扰问题,例如大多数学习者没能拿到证书所以预测模型倾向于预测拿不到证书的概率大,不同课程学习者的表现也有很大差别很难用一个模型进行刻画。
针对上述问题,本文提出了一种基于混合数据的降采样堆模型来预测MOOC平台中学习者能否获得证书。通过对比实验选出最优的基础模型,在此基础上使用随机降采样算法克服数据不平衡问题,但是由于传统随机降采样算法有可能丢失重要的训练样本而使得模型不稳定,因此采用堆模型的框架来提高数据的利用率并且进一步提升预测的效果。再者,借鉴推荐系统中物品相似度的概念,为MOOC课程建立一个课程相似度指标来分享混合数据集中课程之间的信息,提升了模型预测效果。本文所建立的模型具有高效性、强鲁棒性,适合实际应用。
1 相关工作
PSP问题的研究主要分为两类算法:基于教育心理学的方法(知识轨迹跟踪)和基于机器学习的方法(决策树、贝叶斯网络、支持向量机、神经网络等)。文献[2]利用了线性支持向量机结合特征工程以及模型的融合来预测学生成绩。但是这种方法需要花费巨大的存储空间,以及计算资源。文献[3]提出了知识跟踪模型。这个模型假设每一种技能的掌握程度由4个部分组成:初始知识、学习率、猜对概率、直接放弃的概率。使用这个模型去预测成绩,需要最大期望法EM(Expectation Maximization method)估计这些参数,而且需要很详细的学生学习日志的记录。近几年,矩阵分解法MF(matrix factorization)在该问题中受到很大的关注。文献[4]将学生的学习表现分为3个维度:学生信息、任务信息和时间属性,通过MF方法来预测成绩。但是MF模型需要大量的日志记录,并且数据的预处理过程十分复杂。
2 数 据
2.1 数据集的介绍
本文使用的数据来自edX公开数据集。数据集包含了60多万用户在2012年到2013年参与的16门课程的相关信息,因为考虑到原始数据集过大,所以官方只提供了每个学生在每门课程上所有的行为的聚合信息。数据集共有20个字段,一条记录代表一个用户的一门课程的所有相关信息,分别是用户名、课程id、是否注册课程、是否浏览课程、是否探索过课程、是否获得证书、来自地区、学历、年龄、性别、成绩、开始注册日期、最后一次交互日期、活跃的天数、视频播放次数、学习的章节数、论坛使用次数、数据是否完整。在该数据集中,一个有趣的现象是大量的学习者是无法拿到证书的,如图1所示。
图1从每一门课程的角度反应出大量学习者是没有拿到证书的,综合统计所有课程中有证书的学习者只占到了4.6%。这使得建模任务变得更加困难,因为模型会倾向于预测学习者拿不到证书。
2.2 数据的处理
异常值和缺失值的处理在建模过程中十分重要,会直接影响到后面的预测结果。例如,很多用户不愿意提供正确的性别和年龄信息和学历信息,甚至有时他们会胡乱填写,在模型中这将会是一个很大的干扰。本文考虑使用以下的方法对这些异常和缺失进行处理:
1) 删除官方标记为不完整的记录。
2) 将关键字段缺失的记录删除,比如最后一次交互的日期。在实验中需要用到这个字段划分训练集和测试集。
3) 利用可信的人口统计学信息,以及课程信息恢复性别、年龄和学历的异常值。以年龄字段来说,具体的方法如下所示:
(1)
式(1)表示在知道学历和性别的前提下,利用同一堂课course(i)中与i相同学历LoE(i)与性别gender(i)的人的平均年龄插补空值。如果不知道学历,那么可以只用性别信息:
(2)
如果学历和性别都不知道,可以使用参加课程的所用人的平均年龄来代替:
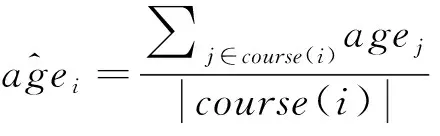
(3)
通过上述方法,最大程度的保留的可用的字段,修正了数据的分布,为模型提供了可靠的数据。
3 模型的建立
3.1 问题的描述
本文的预测任务是一个二分类任务,要求将学生最后分成两类(能拿到证书的和不能拿到证书的)。模型由两部分组成:输入(自变量,X)和输出(因变量,Y)。X=(x1,x2,…,xn),其中每一个元素都是一个列向量代表一个影响结果的因素(特征)。分类模型就好比是一个映射函数Y=F(X),对于一个模型的输出结果Yi,只由和它对应的自变量Xi来决定,其中输出1为有证书,0为没有证书。如图2所示是整个模型建立过程。
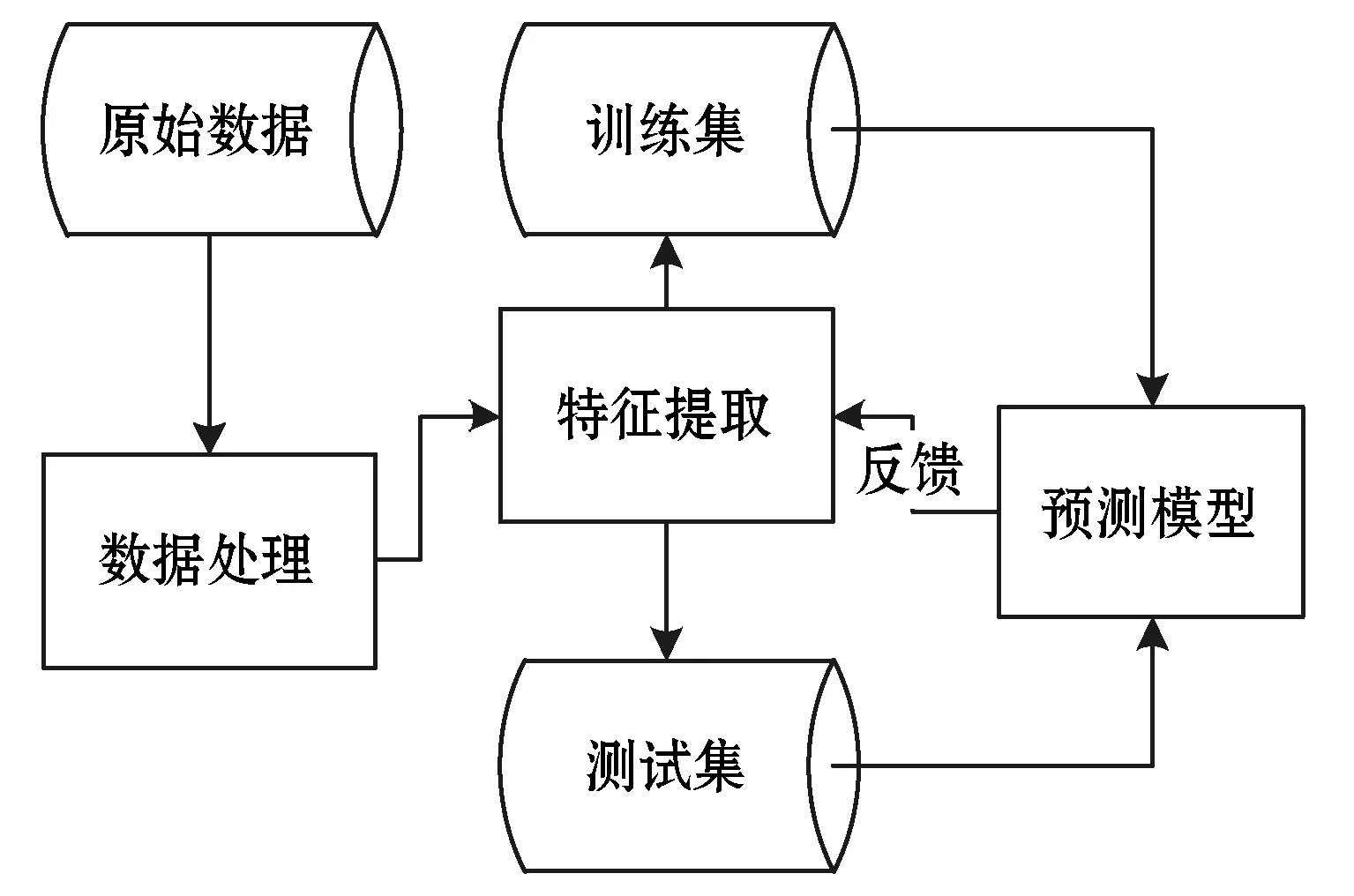
图2 训练的整体流程
3.2 基础模型
最终的预测模型是一个融合模型,要建立在基础模型之上,所以基础模型的好坏直接影响到最终预测模型的好坏。本文通过对比实验得到最好的基础模型,所考虑的基础模型有:逻辑回归(LR)、支持向量机(SVM)、随机森林(RF)、K近邻(KNN)、朴素贝叶斯(NB)、梯度提升树(GBDT),还有一个比较新的模型eXtreme Gradient Boosting(XGBoost),最后本文选择了XGBoost作为基础模型。具体的实验结果见4.2节。下面将简单介绍这个模型以及它的原理,并且说明它比一般树模型好的原因。
在2016年,陈天奇提出了XGBoost模型[5],并在KDD大赛上利用该模型获得了冠军。现在很多数据比赛都流行使用XGBoost模型。 XGBoost是对传统梯度提升树的改进,在特征粒度上实现了并行的算法,又加入了正则化和高效的特征搜索算法,使得模型的速度和性能都非常令人满意。而且对于一些缺失的特征,XGBoost模型可以自动将缺失值归类到损失函数最小的分支中,而且对于一些不平衡数据集,树模型本身就比较占优势。
对于一个给定n个样本,包含m个特征的训练集D={(xi,yi)}(|D|=n,xi∈Rm,yi∈R),模型的输出定义为:
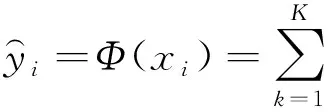
(4)
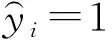
可以看到上面的树模型是对回归问题提出的,这时候的输出值是一个连续的变量。根据Logit的思想,通过simgoid函数映射到0-1的范围。如公式所示:
(5)
其中,一个属于一个类的概率可以这样表示:
(6)
式(6)中的概率服从逻辑分布,当输出概率p>0.5时,则认为发生这件事,那么在这里就表示拿到了证书,最后的输出值就是1,反之则输出0。为了学习上面的模型,要求下面目标函数达到最小值。
(7)
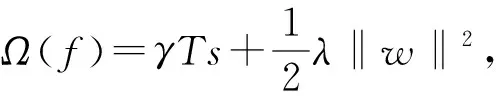
(8)
如果将一个结构q代入式(8)中,目标函数可以表示为以下形式:
(9)
XGBoost使用特征不存度(基尼系数)作为特征的评价标准,如果一个特征的某个切分点的不存度是当前所有特征的切分点中最低的,那么就考虑在这个位置对该特征进行子树分裂。可见寻找最佳切分位置是一个NP-hard问题,如果特征空间很大将消耗非常多的时间。XGBoost使用一种带有排序的贪婪算法去找近似最优的划分点,而且该算法可以并行运算,所以XGBoost比一般的梯度提升树运算更快同时还具备了梯度提升树良好的泛化能力。
3.3 降采样的堆模型
在MOOC场景中,学习者的行为不同于传统的电商和购物场景,因为学习者的行为更加复杂。也正是因为这种复杂而又丰富的行为造成了数据集中的不平衡问题。传统的随机降采样算法也可以对不平衡问题进行修正,但是随机降采样在训练模型的时候因为使用了自助(bootstrap)采样可能在训练模型的时候会丢失一部分重要的训练样本,导致模型的效果波动很大。为了解决这个问题,本文提出堆模型的框架结合随机降采样法去弥补降采样的缺点。堆模型的思想和神经网络类似,堆模型将数据的预测结果作为另一个模型输入再进行预测,所以类似于隐藏层。堆模型是一个网络结构,层数可以自己定义但一般不会太深,不然很难调参数。在文献[6]中也提到堆模型在大多数的场景中比贝叶斯均值融合(随机采样就是一种均值融合的方法)具有更好的鲁棒性能。伪代码1描述了本文所使用的随机降采样SUS(stochastic under-sampling)的方法。
伪代码1 随机降采样(SUS)
1. Begin:
2. 输入:训练集包D={N,M}含了两类样本多数类N和少数类M,以及自助法采样的次数T。
3. Fori=1,…,Tdo
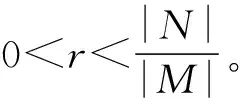
5. End for
7. End
堆模型先从初始数据集中训练初级学习器(基础模型),然后生成一个新的数据集用于次级学习器。在这个新的数据集中,初级学习器的输出被当作样例输入特征。而初始的样本标记仍然被作为样例标记。在这里初级学习器和次级学习器可以相同也可以不同,本文选用的所有学习器在3.2节中有介绍。堆模型算法见伪代码2所示。
伪代码2 模型算法
1. Begin:
2. 模型的输入:训练集包D含样本个数为M,初级学习算法f1,f2,…,ft。次级学习算法F,初始化次级训练集D′=φ。
3. Fort=1,…,Tdo
4. 训练每一个次级学习器,得到模型ht=ft(D)。
5. End for
6. Fori=1,…,Mdo
7. Fort=1,…,Tdo
8. 对于每个样本xi都用ht来预测得到中间输出结果zit=ht(xi)。
9. End for
10. 扩大次级训练集D′=D′∪((zi1,zi2,…,ziT),yi)。
11. End for
12. 次级学习器训练新的训练集得到h′=F(D′)最后得到结果:
H(X)=h′(h1(x),h2(x),…,hT(x))
13. End
在训练阶段,次级训练集是利用初级学习器产生的,若直接使用初集学习器的训练集来产生次级学习器的训练集过拟合风险比较大。因此,本文方法就在堆模型的交叉验证训练次级模型的过程中加入随机降采样,保证了所用训练集样本都被用到,又防止过拟合。本文将这种方法称为SSUS,该方法如图3所示。
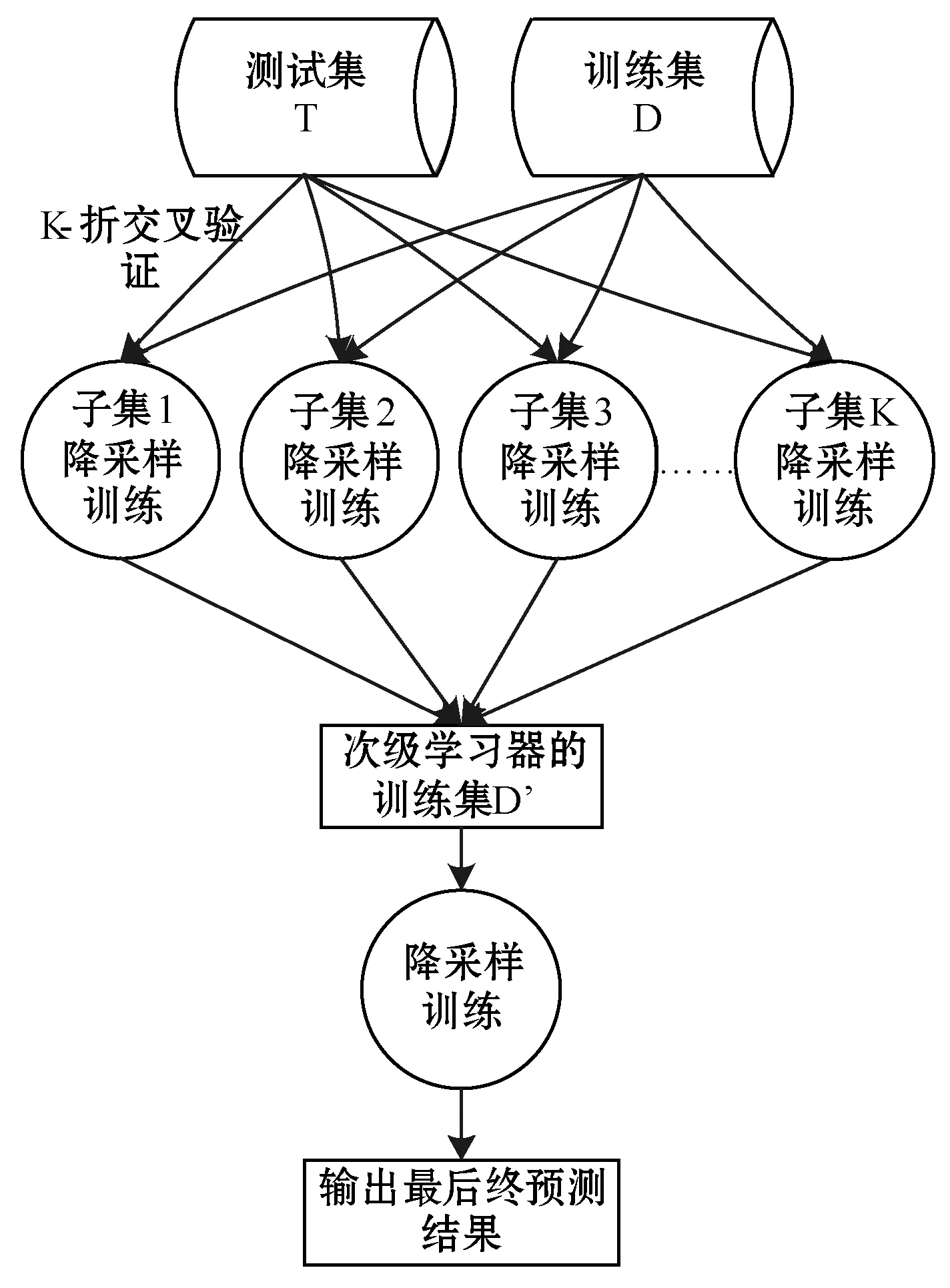
图3 随机降采样的堆融合模型SUSS
3.4 特征的选择
特征的选择影响到最后模型预测的效果,在建模的过程中属于比较关键的一步,本文的特征变量就是前面介绍的模型的输入X,其中每一列代表一个特征。特征选择需要一定的技巧,根据经验和常识可以先提取出一部分有用的特征,然后通过模型的预测结果不断地调整,直到找到比较好的特征集合。基础的特征划分为3部分,学习者属性特征Xl,课程属性特征Xc,和学习者-课程的活动特征Xlc。表1列出了本文所使用的学习者属性特征。表2列出了本文所使用的课程属性特征。表3列出了本文所使用的学习者-课程活动特征。
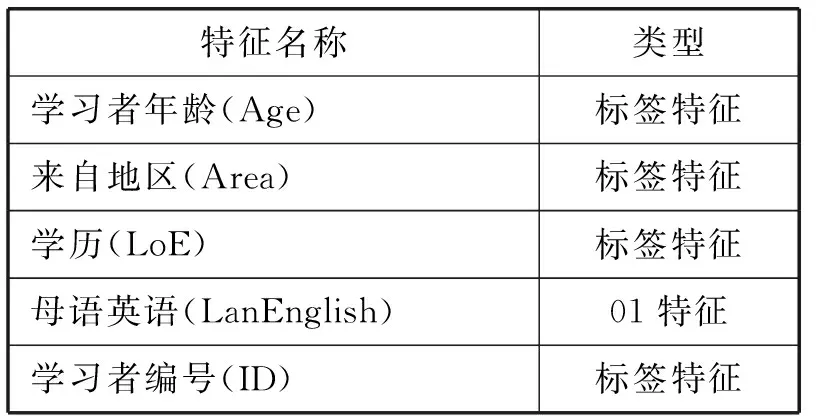
表1 学习者属性特征
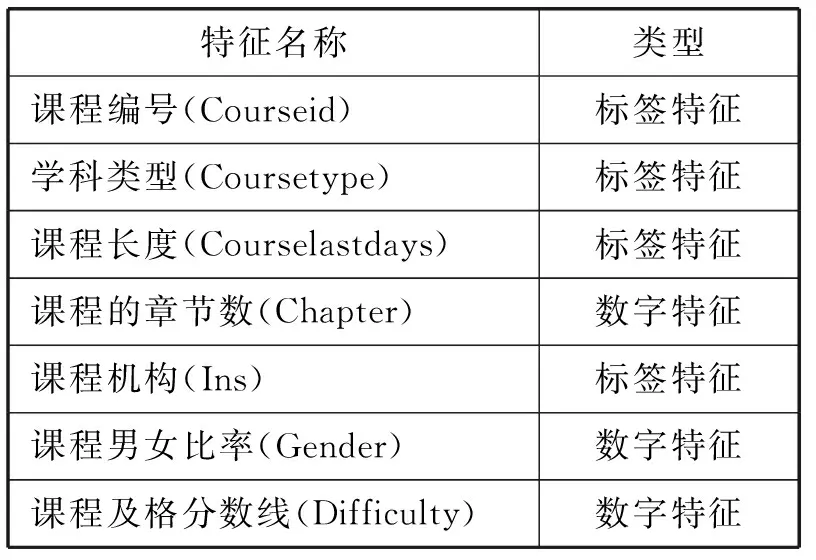
表2 课程属性特征
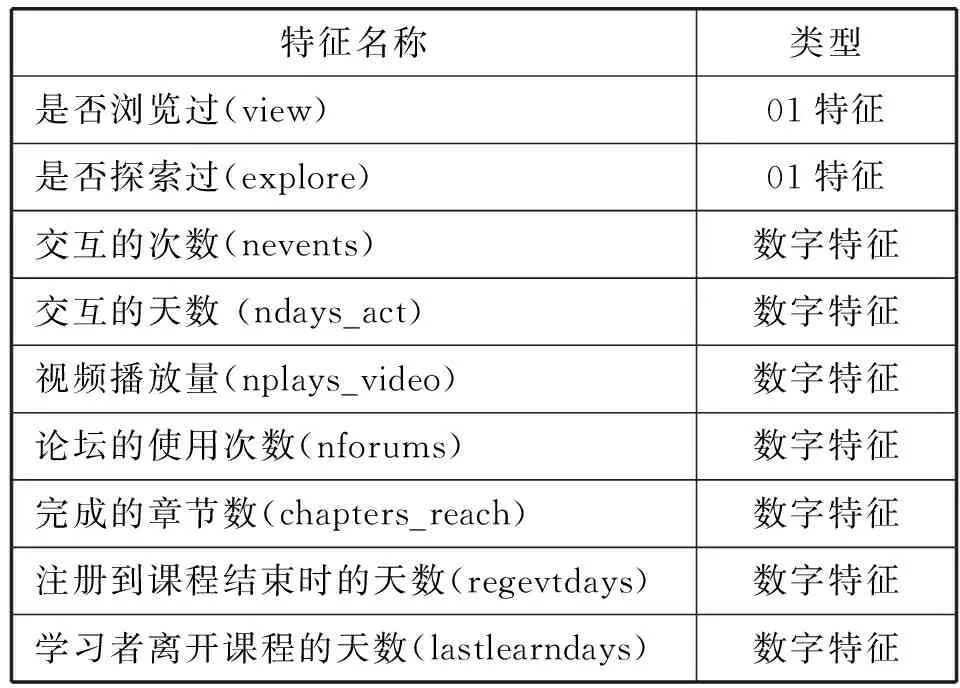
表3 学习者-课程活动特征
表1中学习者的年龄跨度很大,而且年龄层次差不多的人可能有相似的特征,所以本文将年龄分段为0到10岁、11到20岁、21到30岁、31到40岁、41到50岁以及50岁以上,做成了标签特征,更具鲁棒性。
表2和表3中有些特征虽然是同一个含义,但是来自不同的课程,特征的范围就会不同。比如用户完成的课程的章节数,每一门课程章节数量是不同的,所以需要归一化处理,还有一些特征比如标签特征在逻辑回归中需要独特编码。
本文使用了推荐系统的物品相似度来刻画课程之间的联系。当使用所有课程的数据来训练模型可能发生不同分布数据规律的干扰导致模型性能下降。如果课程之间的信息可以有效地共享,那么模型的表达能力将进一步增强。文献[7]对推荐系统中物品相似度的定义,本文的课程相似度可以用下面的公式来表示,称为基础相似度(sim1):
(10)
式中:Wij表示课程i对课程的相似度j;N(i)表示学习了课程i的学习者集合;N(j)表示学习了课程j的学习者集合。式(10)表示课程i与课程jj相似是因为喜欢课程ii的学习者也喜欢课程j。物品相似度受到长尾分布的影响[8],越是热门的物品越是有人喜欢,越是冷门就越少人喜欢。MOOC课程和学习者可能也存在类似规律,比如有些学习者兴趣特别广泛,参加的课程非常多,但是这些学习者对相似度的贡献不大,因为他们体现不出课程的区别;还有一种情况是热门的课程之间拥有大量相同的学习者,导致课程相似度异常偏高。于是,本文又提出了两种带有惩罚的课程相似度,来削弱上面两种情况对课程相似度的不良影响。
针对积极学习者的惩罚(sim2),加入分母项N(j),如下式所示:
(11)
针对热门课程和积极学习者的惩罚(sim3),如下式所示:
(12)
式(11)中学习者参加的课程越多则分母越大,会降低相似度权重。式(12)中N(u)代表学习课程u的人数,N(u)越大分子也会越小,也会降低相似度权重。通过式(10)-式(12),计算得到课程相似度特征Xcc, 最后,将上述特征拼接到一起形成特征变量X,如下式所示:
X=(Xl,Xc,Xlc,Xcc)
(13)
3.5 评价指标
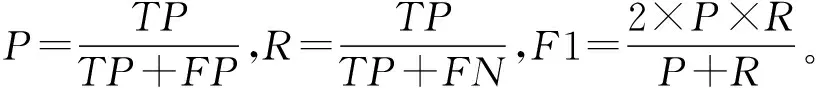
4 实验结果与分析
4.1 实验的设置
本文将训练集按照时间线进行划分,一是符合MOOC平台数据产生的场景,二是符合预测时候的客观逻辑用已存在的数据预测未知的数据。特征变量X通过学习者最后一次学习的日期划分为3个训练集和3个测试集(测试集1:2013-03-01到2013-04-01,测试集2:2013-05-01到2013-06-01,测试集3:2013-08-01到2013-09-01,训练集为切分点之前的数据)。通过对照实验寻找最优的模型,防止一些偶然因素的影响,每次实验都跑10次取平均值。
4.2 基础模型的比较
从表4中可以发现,效果最好的基础模型为XGBoost。树模型(RF、GBDT、XGBoost)的表现比较让人满意对不平衡的修正比较强,而其他的模型表现并不是非常好。在实验中发现了一个有趣的现象,就是随着时间的推移R值(召回率)下降的非常快,导致整体的F1下降。这里反映出MOOC平台现有的一个问题就是,大量的学习者越晚参加课程就越不容易拿到证书。此外,文献[9]指出edX的课程中存在这样一种现象:有部分学习者是积极的学习者按照常理完全有能力拿到证书,但是这些人放弃了考试或是不以获得证书为目的去学习,反之也有这样一群人几乎没有学习就能拿到证书。他们的这些行为在数据中就以离群点的形式表现出来并且这些离群点对模型的结果有很大影响,所以一些对异常值和不平衡数据敏感的算法表现不佳。
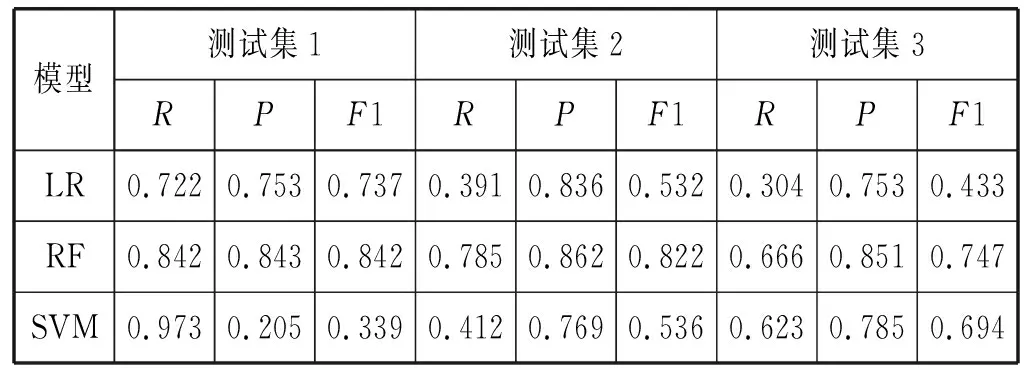
表4 基础模型的对比
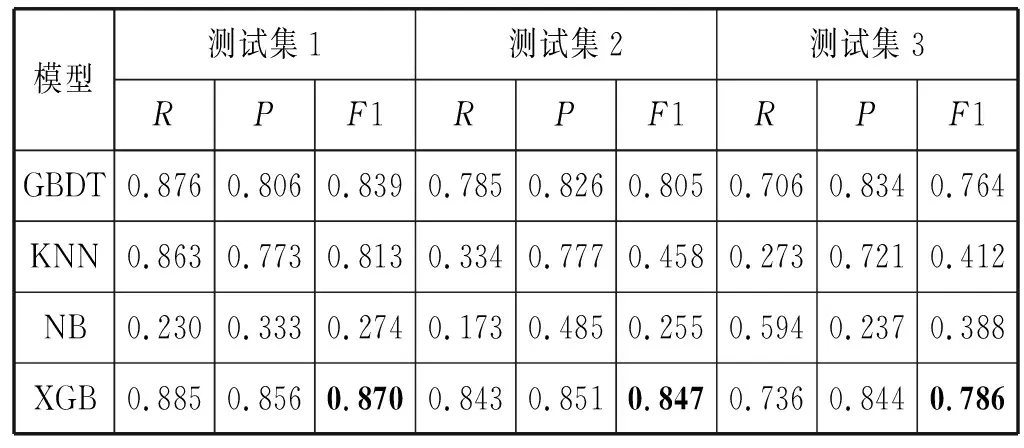
续表4
4.3 课程相似度效果的分析
为了说明课程相似度的效果,表1中的所用的特征集合并没有使用课程相似度。本节在4.2节选出的最优模型XGBoost的基础上加入了课程相似度,并且比较3种课程相似的差异。结果如表5所示。
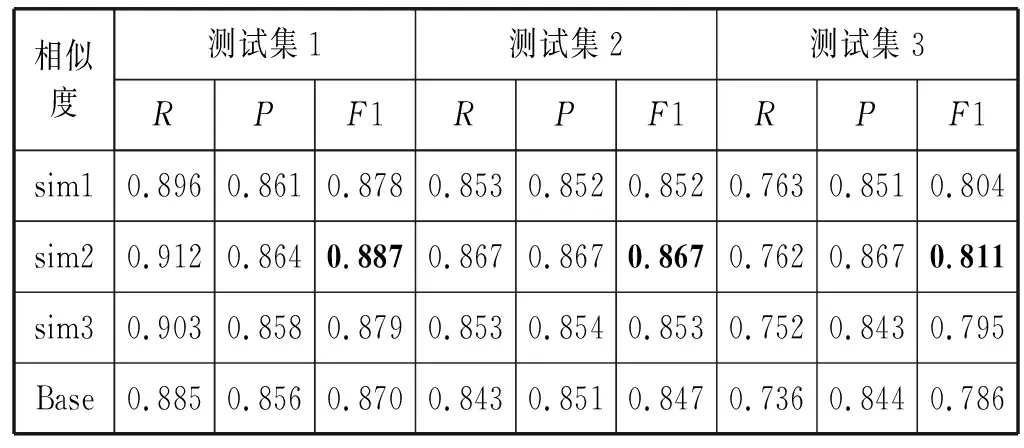
表5 课程相似度的作用
表5比较了不同相似度的效果,带有积极学习者惩罚的课程相似度(sim2)的效果最好,从整体上看3个相似度都提升了模型的P值和R值,并且对R值的提升大于对P值的提升;此外,随着时间的推移学习者数量增加,课程相似度对F1的提升效果越来越明显。但是带有热门课程惩罚的相似度表现不是很突出,一个可能的解释:虽然数据集中学习者很多,但是包含的课程太少只有16门,所以很难体现出热门课程对课程相似度的影响。
4.4 堆模型的比较
本文使用了降采样的堆融合模型作为最终模型,选用的参数为:基础模型XGBoost,降采样子集数量T=15~20,采样比r=10~20,并且利用了10-折叠训练集作为堆模型的交叉验证方法。为了证明本文的方法是有效的,对比了传统的随机降采样算法和最经典的改进降采样算法EE(EasyEnsemble)。最后的结果如表6所示。
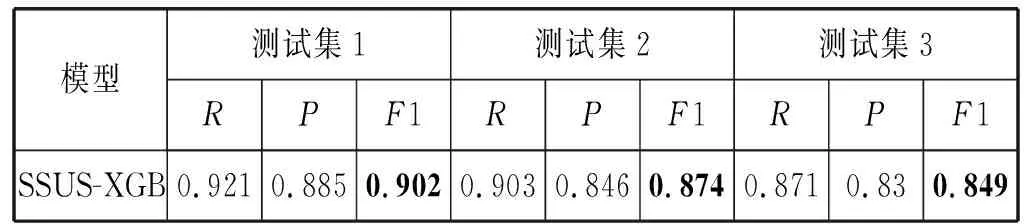
表6 融合模型的比较
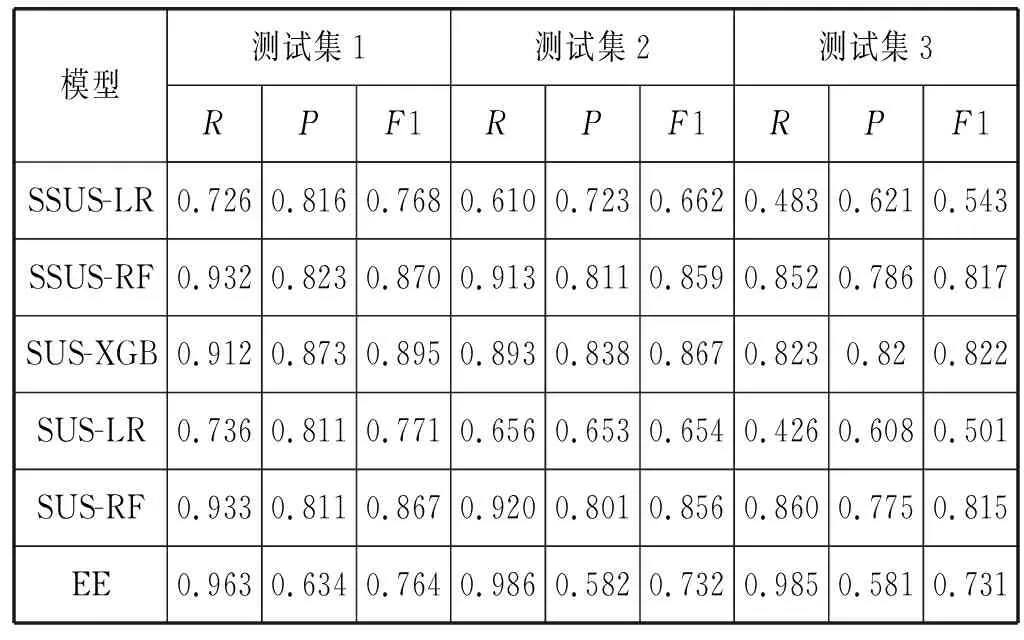
续表6
表6和图4比较了不同融合模型的效果,SSUS-XGB是最出色的融合模型,可以发现SSUS主要提升了模型的R,但是会导致P值略微下降。SUS算法对基础模型效果也有所提升,但是不稳定,这也反应出了降采样的缺点会丢失重要的训练样本,导致P值大幅下滑,并且这个结果和文献[6]的结论一致,堆模型比均值融合算法更加鲁棒。对于经典的降采样模型EE来说,在MOOC这种复杂场景下表现并不是很好,因为EE模型中Adaboost学习器对一些离群点是异常敏感的,所以模型的效果会受到很大的干扰。综合比较各种模型,本文提出的SSUS模型更有鲁棒性,能更好地符合MOOC这种复杂的场景。在时间效率上使用XGBoost模型会更快而且效果更好,本文的实验环境是4个Intel Core i5-6500 CPU和8 GB RAM,SSUS-XGB训练开销约为10 min,而其他SSUS模型需要30 min甚至更久。
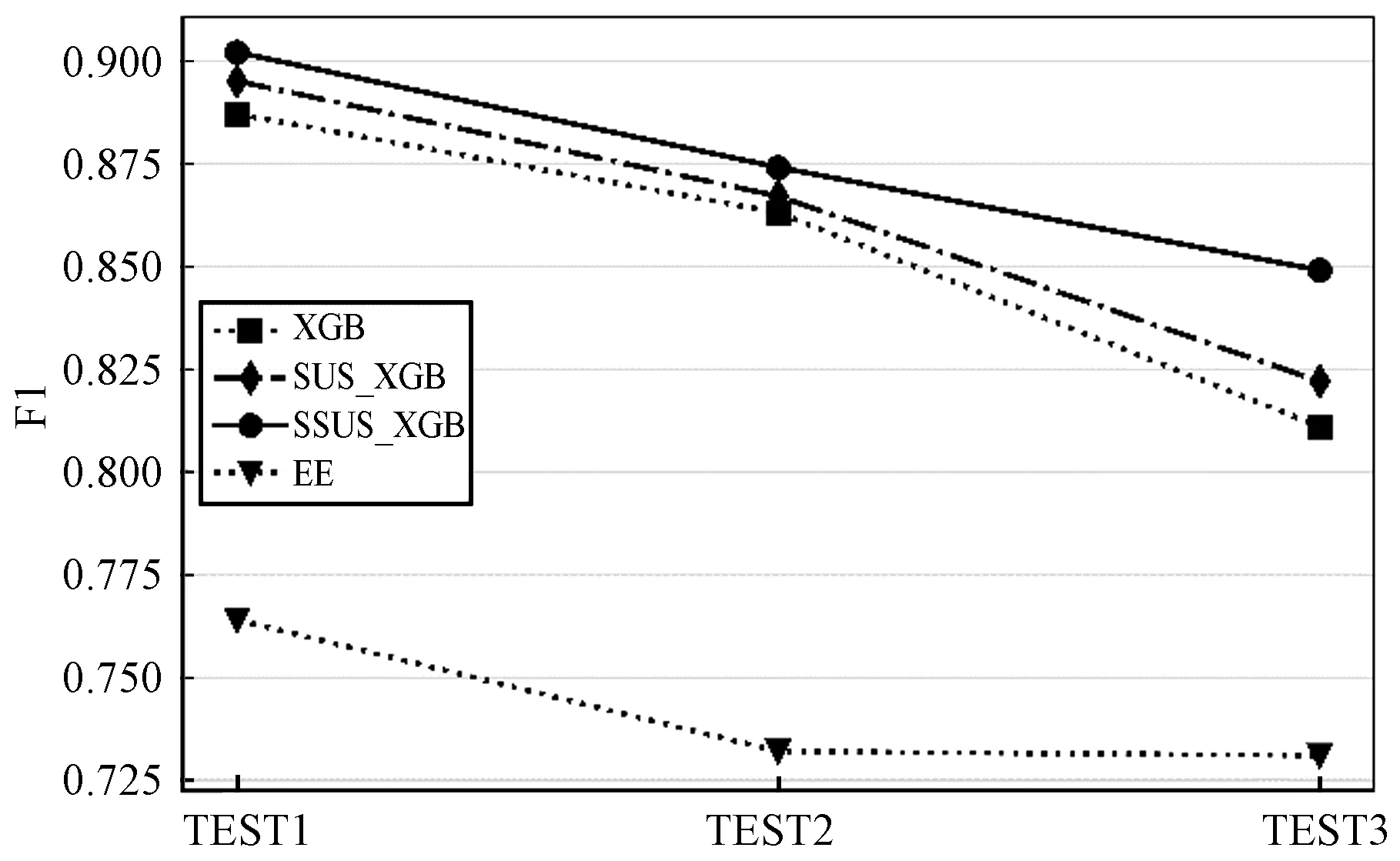
图4 基于XGBoost模型预测结果的F1值比较
5 结 语
本文提出了一种降采样堆模型去解决MOOC平台中学习者证书的预测,该模型克服了数据集中的不平衡问题,同时避免了降采样算法丢失重要训练样本的缺点,通过比对实验证明了该模型的可靠性和稳定性。为了扩充样本空间以及节省建模的成本,本文提出了课程相似度的指标,成功传递了数据间的信息并且提升了模型的精度。本文选择较新的XGBoost模型来处理二分类问题,不但节省了大量的时间还具有较好的预测效果。不过由于数据集的限制,热门课程对预测结果的影响还无法确定,需要搜集更多的数据来验证。此外,数据处理也是教育数据挖掘一个很重要的研究课题,但是目前的相关研究很少,而本文对缺失值和异常值采取了较为稳健的处理方式,这个还需要后面的研究继续探索。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
林产化学与工业(2022年3期)2022-07-07 00:33:32
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
草原与草坪(2022年1期)2022-05-11 10:44:40
中华老年多器官疾病杂志(2022年1期)2022-03-09 12:55:34
学生天地(2020年15期)2020-08-25 09:22:02
意林·少年版(2020年2期)2020-02-18 11:14:52
中华老年多器官疾病杂志(2020年1期)2020-02-06 12:10:02
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
