
基于用户可信度的Web服务推荐方法
2018-07-25 12:09曹继承朱小柯荆晓远
计算机技术与发展 2018年7期
曹继承,朱小柯,荆晓远,,吴 飞
(1.南京邮电大学 计算机学院,江苏 南京 210003;2.武汉大学 计算机学院 软件工程国家重点实验室,湖北 武汉 430072;3.南京邮电大学 自动化学院,江苏 南京 210003)
0 引 言
随着提供类似功能的Web服务越来越多,服务质量(QoS)成为选择最佳可用服务的重要标准[1]。QoS是一些非功能属性,例如响应时间、吞吐量、可靠性、可用性等,能够在提供相同功能的服务中作为第二轮筛选标准[2]。
协同过滤是目前广泛使用的一种推荐技术[3]。基于协同过滤的Web服务推荐系统通过搜集用户的Web服务访问记录,利用用户的反馈数据为用户提供个性化的服务推荐[4]。但是大多数推荐系统都是默认用户的数据是可信的。而现实生活中,用户的数据会因为各种原因而变得不可信,包括设备异常或恶意评价等。如果不考虑用户的可信度,会对最终预测结果产生严重的干扰。
为了解决上述问题,提出了一种基于用户可信度的Web服务推荐方法(CRCF)。首先利用所有用户的反馈数据计算出用户的可信度,然后通过聚类的方式排除可信度低的用户,从而排除含有较多干扰数据的用户,避免其对最终预测结果的影响。最后使用协同过滤进行预测并使用平均绝对误差和均方根误差评判预测结果。
1 相关工作
1.1 协同过滤
协同过滤是一种广泛使用的推荐技术,主要分为基于历史数据的方法和基于模型的方法。基于历史数据的方法首先搜集用户历史数据,然后计算用户或者项目的相似度,最终通过相似用户或项目产生推荐结果。基于模型的方法在训练数据上通过数据挖掘和机器学习算法找到相应的模型,然后完成推荐。相比前者,基于历史数据的方法因其易于理解和使用在实际中应用广泛。文中算法属于基于历史数据的方法。
经典的基于历史数据的协同过滤算法包括基于用户的方法(UPCC)[5]和基于项目的方法(IPCC)[6]以及基于用户和项目的方法(UIPCC)[7]。
UPCC利用式1计算用户u和用户v的相似度,然后找到相似度最高的k个用户,最后通过式2进行QoS值的预测。
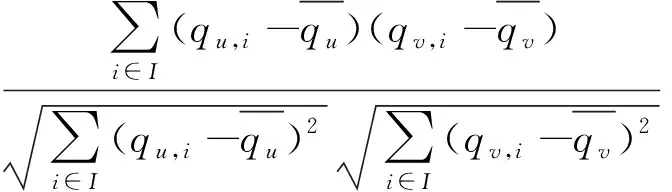
(1)


(2)
其中,N(u)表示用户u和用户v相似度最高的k个近邻用户。
IPCC与UPCC类似,利用式3计算服务i和服务j的相似度,然后找到相似度最高的k个服务,之后通过式4进行QoS值的预测。
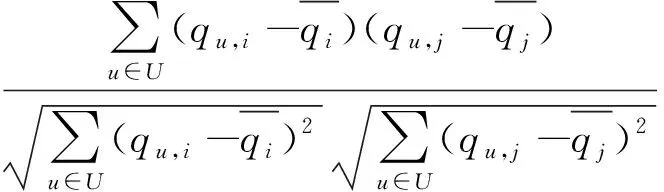
(3)

(4)
UIPCC是将UPCC和IPCC的两个结果利用式5进行加权求和,从而获取更精确的预测,这里不再展开描述。
P(u,i)=λ×P1(u,i)+(1-λ)×P2(u,i)
(5)
1.2 用户可信度
搜集到的用户反馈数据中,包含很多可能干扰到最终预测结果的不可信数据,例如:(1)用户可能会提交一些随机的值作为其QoS反馈值;(2)用户可能会为了某种利益故意对某些服务给予很好的QoS值,而对另外一些服务给予很差的QoS值;(3)用户虽如实提交了其QoS数据,但是数据由于受到当时网络环境、设备等的干扰,处于不正常的范围内。如果不对上述的不可信数据进行处理,会对最终的预测结果产生很大的影响。
文献[8]提出了一种通过计算用户评价可信度来完成可信Web服务推荐的方法,但是该方法包含的参数很多,设置不当会导致很差的结果。文献[9]提出了一种可信的Web服务推荐模型,该模型的缺点是对现有的Web体系结构并不是很适用。文献[10]提出了一种排除含有异常数据较多的用户的方法,该方法只考虑到了范围异常的数据,没有考虑范围正常但与服务实际性能不符的恶意评价数据。文献[11]提出了一种利用可信第三方来解决不可信用户问题的方法,但是事实上找到可信的第三方并不容易。
通过分析所有用户的反馈数据可知,如果某个用户对某个服务的反馈数据与其他访问过该服务的用户差距很大,且很少有用户与其相近,则这个用户的数据是有问题的。若某个用户有问题的数据很多,则这个用户更有可能是有问题用户。
在上述研究的基础上,文中提出了一种基于用户可信度的Web服务推荐方法,使用一种计算用户可信度的方法,排除干扰数据的影响,并通过聚类方式排除干扰用户,减少需要设置的参数。
2 基于用户可信度的推荐方法
2.1 用户可信度的计算
该算法旨在排除那些不可信的用户,从而使预测更准确。人们更倾向于相信被大多数人认可的数据,如果某个用户对Web服务的反馈与其他用户差别很大,则此用户很可能是干扰用户。用户t的可信度由式6求得:
TRDt=
(6)
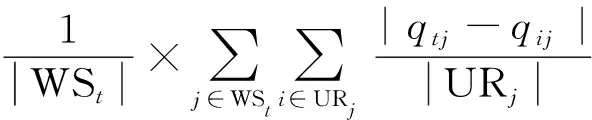
通过式6可以得到一个保存用户可信度的向量:T={t1,t2,…,tm},其中含有范围异常数据以及恶意数据的用户的可信度会明显小于可信用户。图1为香港中文大学搜集的数据集的用户可信度的分布图。由图1可见,多数用户的可信度都集中在某个区间,只有少数在此区间外。
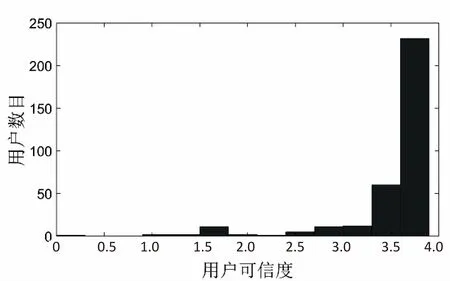
图1 用户可信度分布直方图
2.2 不可信用户的排除
通过设置阈值并将用户可信度与之比较来分辨用户是否可信是一种方法,但是阈值的设置会对结果有一定的影响,增加了需要调试的参数。
文中利用K-means聚类的方法,将上述向量中的数据聚为两类,排除可信度低的类别,利用剩下的可信用户进行QoS预测,从而避免了阈值设置不当而产生的误差,也避免了参数过多的问题。
2.3 算法步骤
输入:QoS数据的训练集TrainData,QoS数据的测试集TestData,近似邻居数top-k,调和参数λ。
输出:QoS预测值P(u,i)。
(1)对训练集TrainData中的QoS数据,用式6计算出用户的可信度,获得用户可信度向量T。
(2)利用K-means聚类方法对用户可信度向量T进行聚类,其中类别数为2。排除可信度低的类别中的用户,利用可信度高的类别中的用户进行预测。
(3)使用式1计算出用户的相似度。
(4)选取相似度最高的k个用户作为此用户的邻居用户N(u)。
(5)使用式2计算此用户基于UPCC的QoS预测值。
(6)与UPCC相似,使用式3和式4计算出基于IPCC的QoS预测值。
(7)使用式5将得到的以用户为基础的和以项目为基础的预测值通过调和参数λ进行加权求和,获得最终的预测值。
(8)调节参数获得最佳预测值。
3 实 验
3.1 数据库
文中使用的是香港中文大学搜集的数据集distributed reliability assessment mechanism for web services (WS-DREAM)[12-13]。该数据集描述了339个用户在5 825个服务上的QoS评估结果。QoS项包括响应时间和吞吐量,选用响应时间来进行算法性能的验证。
3.2 评价指标
选取平均绝对误差(MAE)和均方根误差(RMSE)作为最终预测结果准确率的评价指标。定义分别如下:

(7)
(8)

MAE计算预测值与真实值差的绝对值的平均值,其对所有差的权重是一样的;RMSE在计算预测值与真实值差的和之前对其进行了平方操作,增大了对大误差的权重。MAE和RMSE的值越小,说明预测的结果越好[14]。
3.3 实验设置
为了更好地证明文中算法的有效性,在原有数据集的基础上进行了人为加噪声的操作。增加若干用户,其QoS的值随机生成;选取若干用户,随机交换其若干QoS值;选取若干用户,随机选定若干位置,给予该位置一个很大的QoS值。
服务的数量是巨大的,用户只可能对其中的很少一部分进行访问,因此用户与其访问过的服务的QoS矩阵是稀疏的,为了满足现实情况,需要对数据进行稀疏操作。选取的稀疏度为5%~30%,以5%为间隔(稀疏度为5%即保留5%的数据用来训练,剩余数据用来测试)。
在进行了5%的稀疏以及上述加噪后,各个用户的可信度如图2所示。
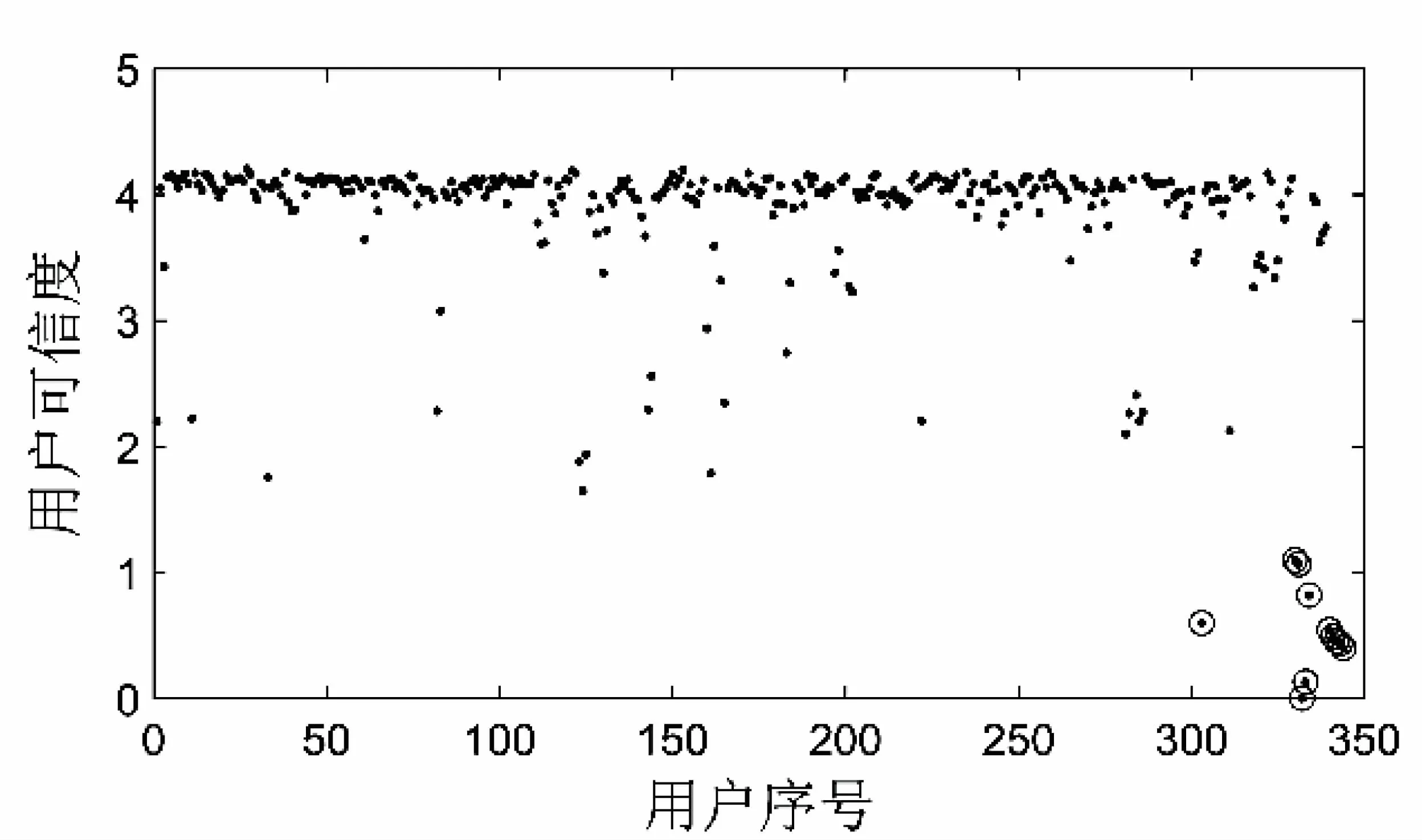
图2 稀疏及加噪后用户的可信度散点图
由图2可以看出,加噪用户的可信度都处于可信度最低的水平(图中圆圈所示),可以很容易地用聚类进行排除。
3.4 实验结果
为了降低预测结果的偶然性,进行了20次随机试验,使用MAE和RMSE评价预测结果的好坏,并同时选取了UPCC、IPCC、UIPCC作为对比算法[15]。最终结果以及对比算法的结果见表1和表2。
由表1和表2可以看出,在数据很稀疏的情况下,CRCF比UIPCC的预测准确率有很大的提升,也进一步说明了有噪声数据对最终预测结果具有一定的影响。现实中数据是很稀疏的,并且干扰数据也较多,CRCF能有效提升预测准确率。

表1 不同稀疏度下MAE的对比结果

表2 不同稀疏度下RMSE的对比结果
4 结束语
文中提出了一种基于用户可信度的Web服务推荐方法,首先计算出用户的可信度,然后根据用户可信度对用户进行聚类,从而选取可信用户使用协同过滤进行预测。该方法有效地避免了范围异常数据及用户恶意评价数据对最终预测结果的影响,提高了QoS预测精准度。但是该方法只考虑了用户的可信度,并未考虑服务的可信度。下一步工作是充分挖掘不可信用户的数据,发现可以分辨服务可信度的方法,找到一种更一般化的可信服务推荐模型。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年6期)2022-07-02
新班主任(2022年4期)2022-04-27
今日农业(2021年19期)2022-01-12
电子产品世界(2021年6期)2021-02-10
中国现代医生(2020年2期)2020-04-09
汽车观察(2019年2期)2019-03-15
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
民生周刊(2017年19期)2017-10-25
