
基于NSGA-II的扩展置信规则库激活规则多目标优化方法
2018-07-20 07:13林燕清傅仰耿
智能系统学报 2018年3期
林燕清,傅仰耿
(福州大学 数学与计算机科学学院,福建 福州 350116)
专家系统[1]作为一种人工智能系统,已经被广泛应用于图像处理、医疗检测、地质勘探、石油化工等领域。利用专家系统进行决策时,需要先将有用的信息表示成知识,知识的表示形式有很多种,其中应用最广泛的是产生式规则,即IF-THEN规则。置信规则(belief rule)是在传统IF-THEN规则的结果部分加入置信分布转化而来的,由一组置信规则组成的集合称为置信规则库(belief rule base, BRB)。置信规则对应的是系统的输入信息,而实际工程中包含的信息既可能是定性知识也可能是定量数据,同时,信息中往往存在着含糊或模糊不确定性、不精确性以及不完整性。为了能够有效利用带有这些不确定性的信息,Yang等[2]于2006年在D-S证据理论[3-4]、决策理论[5]、模糊理论[6]和传统的IFTHEN规则库基础上提出了基于证据理论的置信规则库推理方法(belief rule-base inference methodology using the evidential reasoning approach,RIMER)。RIMER方法作为BRB系统的核心,能够对具有线性或非线性关系的输入和输出进行建模,具有处理各种不确定性的能力。目前,BRB系统已被广泛应用到输油管道泄漏[7-8]、石墨成分检测[9]、消费者偏好预测[10]、军事能力评估[11]和出租车乘车概率预测[12]等领域。
利用BRB系统对实际问题进行建模时,要先确定其内部参数的取值,各个参数的不同取值会对BRB系统的推理能力造成一定的影响,传统的参数取值确定方法是专家根据经验给定其值,但当参数个数较多或系统较复杂时,专家很难确定参数取值。鉴于此,Yang等[10]最先提出一种通用的BRB参数学习模型,该模型以满足各个参数约束条件为基础,通过最小化由置信规则库推理得出的模拟输出值和真实数据的输出值二者的差值来训练BRB参数。在Yang的基础上,Chen等[13]提出了包括前提属性参考值在内的全局参数学习方法。不过以上两种参数学习方法均是建立在MATLAB工具自带的FMINCON函数的基础上,参数学习效率不高。鉴于此,常瑞等[14]、吴伟昆等[15]提出结合梯度下降法的BRB参数学习方法,这种方法虽然优于FMINCON函数,但其涉及的公式推导过于复杂,只能训练少量的参数,不适合用来学习大量的参数,且参数学习的收敛速度过慢。为了提高BRB系统参数学习的收敛速度和精度,苏群等[16]、王韩杰等[17]相继提出基于群智能算法的参数学习方法。以上参数学习方法均能够优化BRB参数取值,从而提高BRB的推理能力,但是,这些参数学习方法都是建立在Yang等[10]提出的参数学习模型基础上的,无法避免重复的搜索过程,需要不断地进行迭代。此外,因为BRB系统构建时需要覆盖所有的前提属性的参考值,当前提属性和前提属性参考值过多时,会出现“组合爆炸”问题。为了解决该问题,专家学者们提出了各自的降维方法:Zhou等[18]提出“统计效用”的概念,根据每条规则的统计效用值来确定是否删减该规则,如果某条规则的统计效用值越小,说明该规则对整体系统的贡献越小,就可以将其删除;Chang等[19]提出利用灰靶理论、多维尺度变换、主成分分析来选择关键前提属性,从而减少前提属性的数量;王应明等[20]引入粗糙集理论,提出客观的规则约简方法,该方法不需要借助BRB以外的任何先验知识。这些BRB结构优化方法虽然可以在一定程度上避免组合爆炸问题,但是会降低BRB的推理能力。为了从根本上解决BRB参数取值以及组合爆炸问题,Liu等[21]对原有的置信规则进行扩展,在规则的前件部分也加入置信分布,提高其对含糊、不完整和不确定信息的表示能力,改进后的规则库被称为扩展置信规则库(extended belief rule base, EBRB)。同时,Liu等[21]还提出了一种简单且有效直接利用训练数据生成初始扩展置信规则的规则生成机制,数据驱动型的规则生成机制可以详细表示出数据中包含的各种信息,不需要进行反复迭代的参数学习过程也不会造成组合爆炸问题。但正因为扩展置信规则是根据训练数据集得到的,数据集的质量对EBRB系统的推理能力影响要更大,相互矛盾、不一致的数据容易降低EBRB的推理准确性。在EBRB中,数据的不一致是指两条或多条规则的前提属性取值大致相同,但评价结果却完全不同或与专家知识相冲突。
针对EBRB系统中的数据不一致性的问题,Alberto等[22]提出动态规则激活方法,该方法通过调整改进后的相似性度量公式中的参数来选择不一致性最小的激活规则集合,不过,该方法中用于衡量激活规则集合不一致性的公式只考虑了规则数量对其的影响,没有考虑规则激活权重对其的影响。要减小激活规则集合之间的不一致性,最简单的方法就是舍弃部分不一致性较高的激活规则,这部分激活规则不参与最终的合成推理过程,但这部分激活规则可能带有重要的信息,而且很难确定这部分激活规则的具体数量。为了减小激活规则集合的不一致性同时保留激活规则集合中的大部分重要信息,本文提出了基于NSGA-II的扩展置信规则库激活规则多目标优化方法,将激活规则的不一致性与激活权重和分别作为目标函数,通过求解多目标优化问题获得相对较优的激活规则集合并用于最终的合成推理。本文首先介绍扩展置信规则库和多目标优化问题的基础知识,然后介绍如何利用NSGA-II求解Pareto的最优解,最后通过非线性函数问题和输油管道检漏实例对所提方法进行实验验证,并分析说明所提方法的有效性和可行性。
1 扩展置信规则库系统与问题提出
1.1 扩展置信规则生成
扩展置信规则库由一系列扩展置信规则(extended belief rule)组成,其中第 k条扩展置信规则的表示为
式中: ( A,αk)表示扩展置信规则前件部分的置信分布,可表示成 {(,j=1,2,···,Ji}|i=1,2,···,Tk},Ai,j表 示第i个 前提属性的第 j个 参考值,且第i个前提属性的参考值总数为表示第 k 条 规则的第i个前提属性输入值相对该属性的第 j个 参考值 Ai,j的置信度, Tk表 示第 k 条 规则前提属性总数;δi表 示第i个前提属性的属性权重; θk表 示第 k条规则的规则权重;j=1,2,···,N;k=1,2,···,L)表 示第 k条规则第j个评价结果 Dj的置信度,每条置信规则的所有评价结果置信度需满足称第 k条规则是完整的,否则称第 k条规则是不完整的。
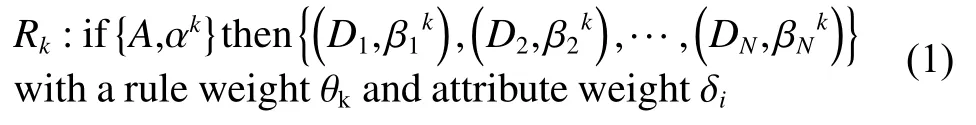
与BRB系统复杂烦琐的规则生成机制不同,Liu等[21]提出的规则生成机制简单且有效,可直接将训练数据转化为扩展置信规则。假设Ui(i=1,2,···,Tk)示 第 k 个 样本数 据的第i个 前提属性,其输入值为 xi,首先决策者或专家需要将第i个前提属性的参考值 Ai,j与数值量建立起对应关系:
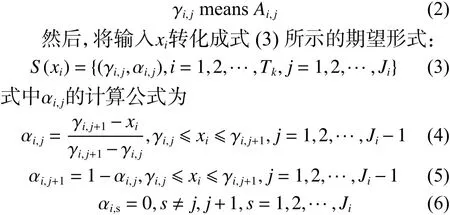
通过式(4)~(6)可得到 αi,j的具体取值从而生成规则的前件部分,相应输出的评价结果置信分布可采用同样的方法产生。
1.2 扩展置信规则库推理方法
1.2.1 激活权重的计算
假设第 i个前提属性取值 xi已经被表示成式(3)所示的形式,则 xi相 对第 k 条 规则的第i个前提属性的个体匹配度可通过两个置信分布的距离值来衡量,因为EBRB前件部分的置信分布实质上是概率分布,故可借助式(7)所示的欧氏距离来计算:


第 k条置信规则的激活权重可由式(9)得
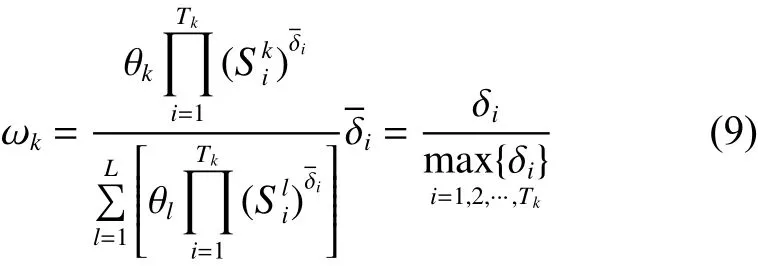
1.2.2 激活规则的合成
用证据推理方法(evidential reasoning, ER)[23]得到推理结果前,要先按式(10)~(13)计算评价结果置信度的基本可信值:

式中:n =1,2,···,N。在此基础上通过ER解析公式[24]计算评价结果的基本可信值,合成公式如式(14)~(19):

根据式(14)~(19)可得到式(20)所示的具有置信分布形式的BRB推理输出:
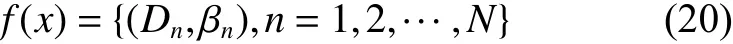
基于上述ER解析算法,Wang等[25]进一步推导出了组合所有的置信规则的计算公式,即
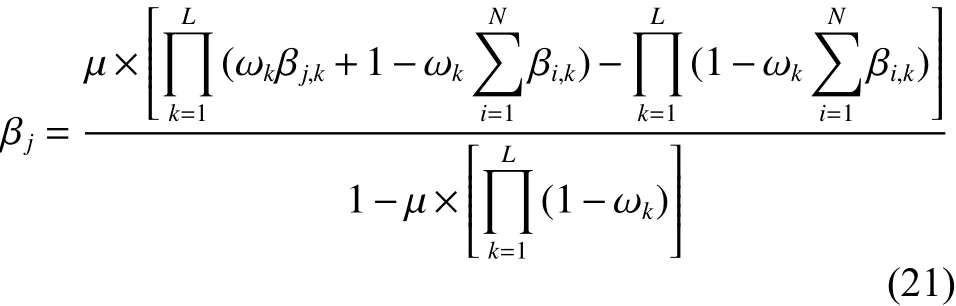

1.3 问题提出
Liu等[21]提出的EBRB规则生成机制虽然简单且有效,但也使得EBRB系统的推理性能容易受训练数据的质量影响,由于训练数据生成的扩展置信规则库可能存在不一致的规则即规则相互矛盾的问题,这些不一致的规则会降低EBRB系统的推理准确性,尤其当这些不一致规则同时成为激活规则。在EBRB中,这些激活权重大于零的规则被称为激活规则,激活规则是用来进行ER合成推理的,即EBRB系统的推理结果就是依靠这些激活规则得到的。由此可见,激活规则对于最终推理结果的重要性,而相互矛盾的、不一致的激活规则会对最终的BRB系统推理结果造成一定的干扰,进而影响BRB系统的推理能力。为此,Alberto等[22]对式(8)进行改进,提出动态规则激活方法,通过不断重复的搜索过程以找到不一致性最小的激活规则集合,该方法能够有效减小激活规则之间的不一致性,但其参数取值需要不断迭代,而且参数增加和减小幅度也较难确定。此外,实际工程应用中,训练数据总数都比较多,当采用Liu等[21]提出的规则激活方法时,多数规则的激活权重都会大于零,激活规则数量的增多,意味着规则间的不一致性增大。要减小激活规则之间的不一致性,最简单的方法就是尽可能多地减少激活规则的数量,不一致性较高的这部分激活规则不参与最终的合成推理过程,但这种方法不一定有效,因为激活规则数量一旦减少,原有激活规则集合中包含的信息就会减少,如果这些不参与最终合成推理过程的激活规则包含了原有激活规则中绝大部分重要信息,则EBRB的推理准确性也会受到一定程度的影响。在EBRB中,激活规则的激活权重代表激活规则的重要性,激活权重越大,说明该激活规则越重要,其中包含的重要信息越多。鉴于此,为了减小激活规则之间的不一致性,同时保留住原有激活规则集合的绝大部分重要信息,本文提出激活规则多目标优化方法,把激活规则之间的不一致性以及激活规则的激活权重总和作为优化目标,通过NSGA-II来求解较优的激活规则集合用于最终的合成推理。
2 基于NSGA-II的EBRB激活规则多目标优化方法
2.1 多目标优化问题
在实际应用问题中,所求解的优化目标通常包含多个,且它们之间经常是相互矛盾、冲突的。也就是说,对于这一类问题,几乎找不到一个可以同时满足所有优化目标的最优解。一个由m个决策参数和n个目标变量组成的多目标优化问题的数学表达式[26]为
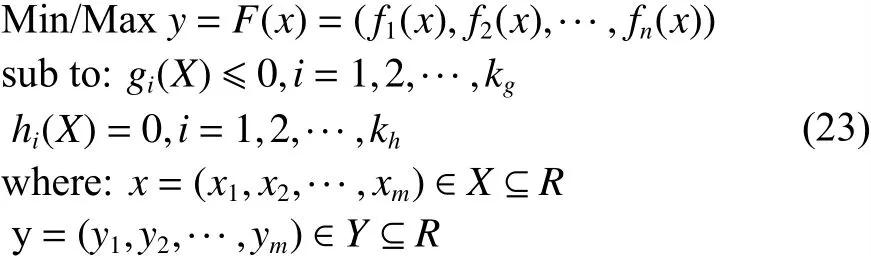
式中: x =(x1,x2,···,xm)表 示 m 维 的决策参数;y=(y1,y2,···,yn)表 示 n 维 的目标变量;F(x)=(f1(x),f2(x),···,fn(x))表 示所有的目标函数; gi(X)≤0表示所有的不等式约束条件; hi(X)=0表示所有的等式约束条件。
定义 1 (可行解)如果存在一个决策参数 x它满足所有不等式约束条件和等式约束条件,则称 x为可行解。
定义 2 (可行解集合)可行解集合是指所有可行解组成的集合,记作 xf(xf⊆X)。
定义 3 (Pareto占优)假设 xA,xB(xA,xB∈Xf)是多目标优化问题的两个可行解,若 xA相 对 xB是Pareto占优(或称 xA支 配 xB, 记作 xA≻xB) ,则 xA,xB需要同时满足以下两个条件:

定义 4 (Pareto最优解)若多目标优化问题的一个可行解 xC(xC∈Xf)是 Pareto最优解,则 xC需要满足条件 ¬ ∃x∈Xf:x≻ xC。
2.2 带精英策略的快速非支配排序遗传算法
2000年Kalyanmoy Deb等[27]首次提出了带精英策略的快速非支配排序遗传算法(简称NSGAII),该方法是众多求解多目标优化问题方法中应用最为广泛的一种。NSGA-II算法是非支配排序遗传算法(non-dominated sorting genetic algorithm,NSGA)的改进,运行速度更快,复杂度更低,且其求解的Pareto最优解集收敛性更好。算法首先随机产生一定规模数量的初始种群,然后利用非支配排序方法对种群中所有个体进行分层,接着执行遗传算法的选择、交叉和变异3个操作产生第一代子群。从第二代子群开始,先将父代种群和子代种群中所有个体合并在一起,然后利用快速非支配排序方法对其进行分层,并计算每个非支配分层中所有个体的拥挤距离,在此基础上从中选出较优的个体组成新的父代种群,接着执行遗传算法的选择、交叉和变异3个操作产生下一代子群,直至达到程序结束条件时终止,算法的具体流程如图1所示。
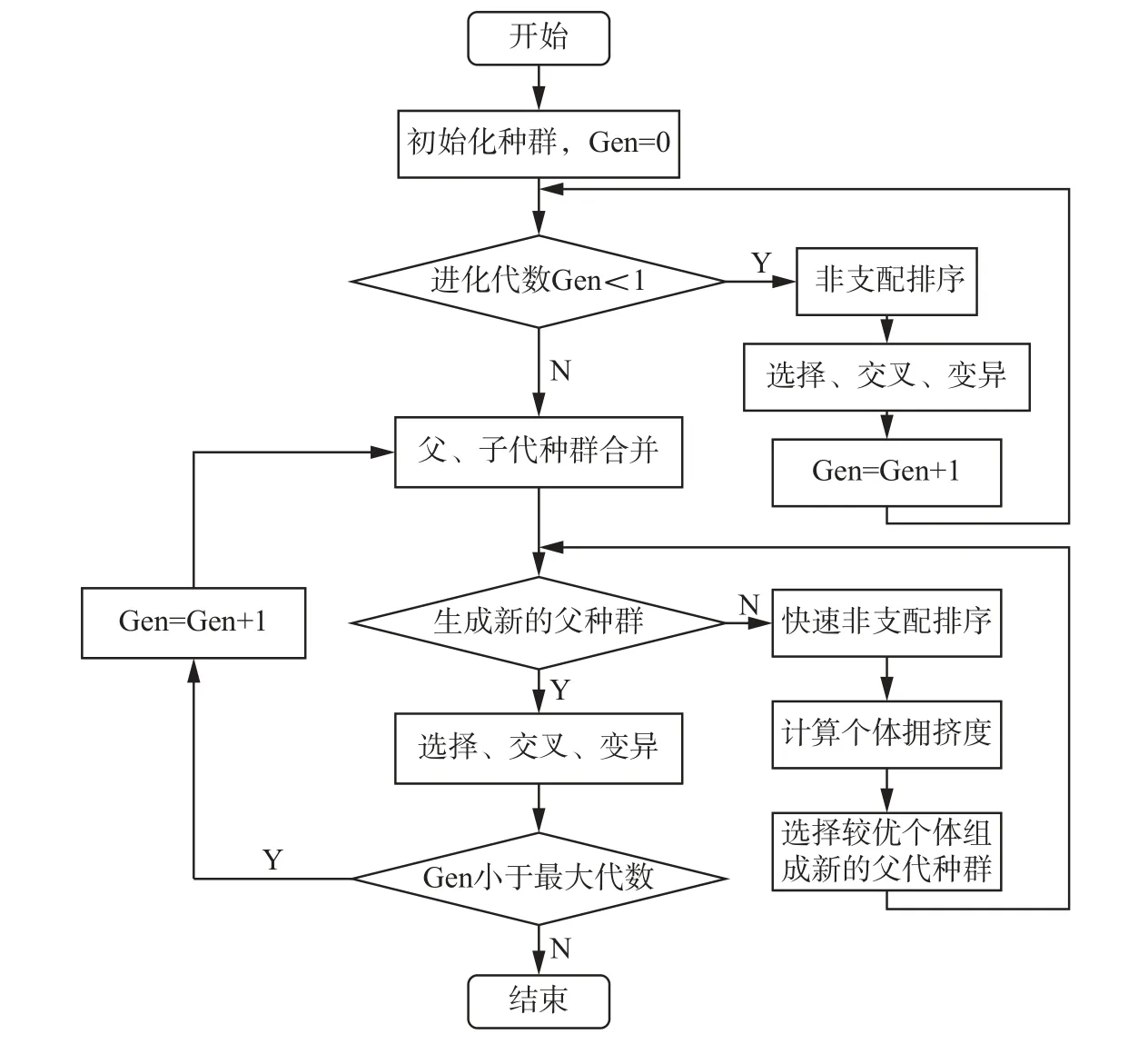
图1 NSGA-II算法流程Fig. 1 The process of NSGA-II
NSGA-II算法中个体的优劣之分主要由个体的两个属性取值来决定,一个是其所在的非支配分层级别,另一个是个体的拥挤距离。前者是通过快速非支配排序方法确定,NSGA-II的快速非支配方法与NSG(A的非) 支配排序(方法)相 比,计算复杂度从原先的 O MN3减少至 O MN2(其中 M 为种群大小,M为目标函数的个数)。计算处于同一个非支配分层的个体拥挤距离之前,需要先对所有个体的拥挤距离进行初始化,然后根据目标函数将其按照升序进行排序,接着再计算每个个体的拥挤距离。详细的快速非支配排序算法以及个体拥挤距离的计算过程可参见文献[27]。
确定完每个个体所在的非支配分层级别以及拥挤距离之后,就可以确定种群所有个体的优劣,假设其中两个个体 i和 j,其所在非支配分层级别为irank和 jrank, 拥挤距离为 idistance和 jdistance,如果这两个个体满足以下两个条件中的一个条件:

则称个体i优 于 j, 表示成 i≺nj。
2.3 基于NSGA-II的激活规则多目标优化方法
数据驱动型的EBRB规则数量等于训练数据集数量,每条置信规则对应一个训练数据,当训练数据过多时,由式(9)计算得到的激活规则数量也会比较多,但很多激活规则之间存在相互矛盾、不一致的情况,这些激活规则会对推理造成一定的干扰。为了减少不一致激活规则对EBRB推理准确性的影响,本文提出基于NSGA-II的激活规则多目标优化方法,因此,多目标优化的两个目标函数分别为激活规则集合的不一致性以及激活权重和,其中,激活规则集合的不一致性用Liu等[21]提出的方法来衡量,假设 RP,Rq为扩展置信规则库中的两条规则,二者的不一致性可通过前提属性相似度SRA和评价结果相似度SRC来衡量,规则 p 和 规则 q的SRA和SRC计算公式如下:
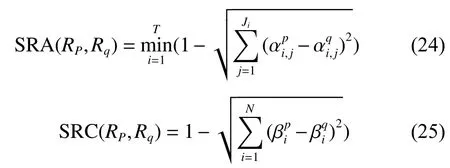
根据文献[21],规则 p 和 规则 q之间的一致性可根据式(26)计算得到:
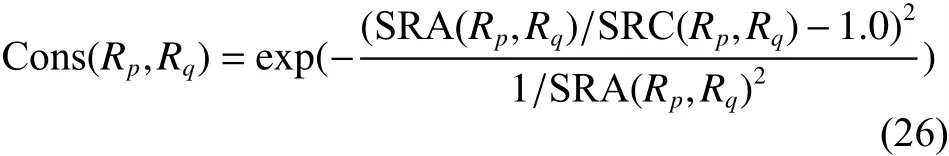
那么,第i条规则的不一致性为

由此可得NSGA-II的优化目标为

式中:R表示最终参与ER合成推理的激活规则集合;l表示参与ER合成推理的激活规则总数。O(MN);2)NSGA-II算法中非支配排序方法复杂度O(MN2);3)NSGA-II算法中拥挤距离计算复杂度O(MNlogN);4)NSGA-II算法中个体优劣排序复杂度O(NlogN)。 因此整体复杂度为O (MN2)。
基于NSGA-II的激活规则多目标优化方法具体流程如图2所示,该方法根据激活规则集合的不一致性以及激活权重和来求解最终参与ER合成推理的激活规则集合R。本文方法首先计算每条扩展置信规则的激活权重,激活权重大于零的规则组成激活规则集合,然后对激活规则集合进行二进制编码,1表示该激活规则参与最终ER合成推理过程,0表示该激活规则不参与ER合成推理,不同的激活规则集合,其中被标识为1和0的规则不同,根据式(27)计算得到的规则不一致性以及激活权重和也不同,故接下来需要利用NSGA-II算法求解最优化目标(式(28))的Pareto最优解集,这些Pareto最优解集中编码为1对应的激活规则之间的不一致性既要最小同时激活权重和也要最大,然后从最优解集中选择一个合适的Pareto最优解,该最优解中编码为1对应的激活规则组成最终的激活规则集合并用于ER合成推理得出结果。本文方法的整体时间复杂度包括:1)EBRB系统查询激活规则复杂度
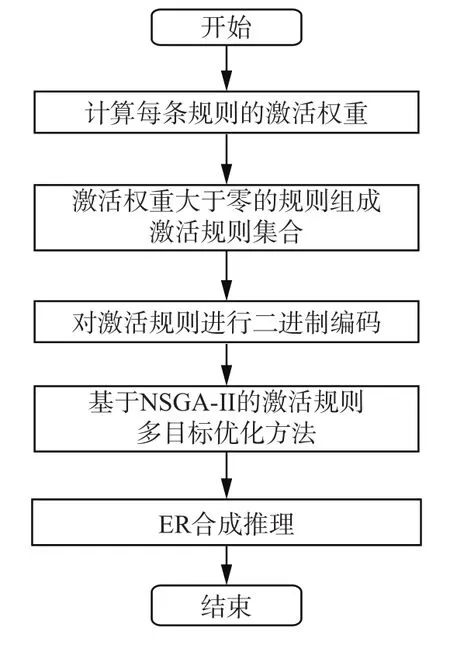
图2 激活规则多目标优化方法Fig. 2 The activated rules multi-objective optimization approach
3 实例分析
本文引入非线性函数和输油管道检漏实例为研究对象以验证本文方法的有效性。实验中用到的NSGA-II算法的各个参数值分别为:个体交叉概率为0.9,个体变异概率为0.03,种群规模为100,进化代数为1 000。实验环境为:Inter(R) Core(TM) i5-4570 CPU @ 3.20 GHz;8 GB 内存;Windows 10 操作系统;算法实现平台Visual Studio 2010。
3.1 非线性函数问题
为了验证本文方法的有效性,引入一个非线性函数作为基准测试函数进行测试以说明本文方法的性能。非线性函数的数学表达式为

在EBRB系统构建中,选取函数的自变量 x作为前提属性,并从其定义域中均匀选择7个数值作为其参考值,即 {0 ,0.5,1.0,1.5,2.0,2.5,3.0},然后根据函数值设定评价结果等级数及相应效用值为{−2.5,−1.0,1.0,2.0,3.0}。 该实验的测试数据是从 x的定义域中均匀选取的500组数据,训练数据是从 x的定义域中均匀选取的1 000组数据,因此,构建的EBRB系统总共有500条规则,然后根据Liu等[21]提出的方法和本文提出的方法构建EBRB系统,实验结果衡量的指标为系统的推理输出和真实输出之间的均方误差(mean squared error,MSE)、激活规则总数(Activated_rules)、参与合成推理的激活规则数(ER_rules),实验结果如表1所示。
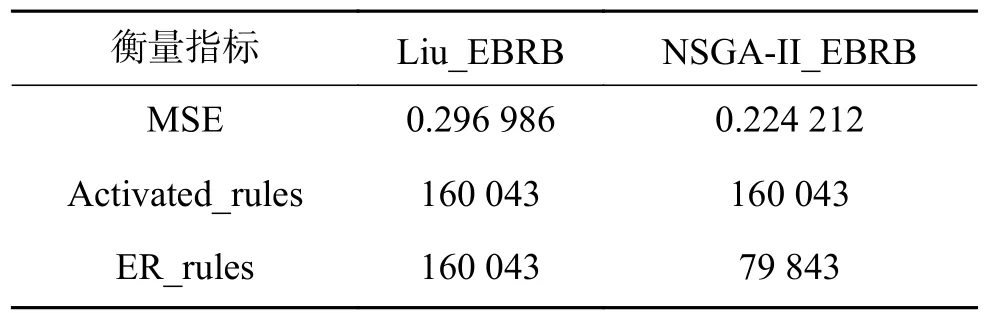
表1 非线性函数问题实验结果Table 1 The results on nonlinear function
从表1可以发现,NSGA-II_EBRB系统的推理准确性要比Liu_EBRB系统的推理准确性高,这主要是因为Liu_EBRB系统中用来参与ER合成推理的规则是所有激活权重大于零的激活规则,这部分规则的不一致性较高且会降低EBRB系统的推理能力,而NSGA-II_EBRB通过减少激活规则的不一致性,选择不一致性更小同时拥有原来激活规则中绝大部分信息的激活规则进行ER合成推理,最终合成推理的激活规则数只占原来激活规则总数的49.89%,这些激活规则不一致性较低,从而提高EBRB系统的推理能力。
3.2 输油管道检漏实例
为了验证本文所提方法的有效性,引入一个具体的实际问题——输油管道泄漏问题[7]作为实例。该实例的研究对象为安装在英国的一条1 000多米长的输油管道,当输油管道发生泄漏时,管道的泄漏大小(leak size,LS)会随输油管道输入输出的流量差(flow difference,FD)和输油管道内的平均压力差(pressure difference,PD)变化而变化,因此,该实例的EBRB系统的前提属性为FD和PD,结果属性为LS。其中FD、PD的参考值由专家根据经验给出,分别为 {− 10,−5,−3,0,1,2,3}和 {−0.042,−0.025,−0.01,0,0.01,0.025,0.042},LS的评价等级为零、很小、中、高、很高,其数值效用值为 {0 ,2,4,6,8}。
该实验的测试数据是发生泄漏的2 008组数据,训练数据按照一定比例分别从3个时间段随机选取500组数据,因此构建的EBRB系统总共有1 500条规则,然后利用本文提出的方法构建NSGAII_EBRB系统,并将实验结果和Liu_EBRB系统相比较,衡量的指标为平均绝对误差(mean absolute difference,MAE)。
Liu_EBRB系统、NSGA-II_EBRB系统产生的推理输出和测试数据的真实输出对比如图3、4所示。分析图3、4可以发现,Liu_EBRB系统在PD∈[–0.02,0.04],FD∈[–10,0]附近产生的推理输出和测试数据的真实输出有较大差距,尤其是PD∈[–0.02,0],FD∈[–10,5]附近的数据。而NSGA-II_EBRB系统推理输出总体上和真实输出相接近。这是因为,本文方法减少了不一致规则对于推理结果的影响,从而进一步提高了算法的推理性能。
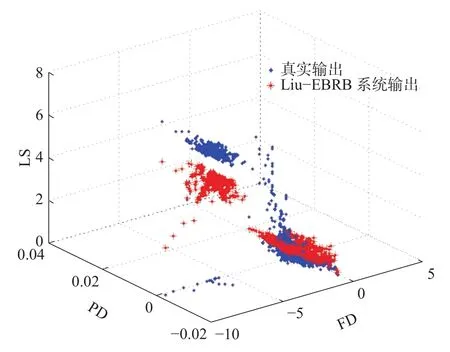
图3 Liu_EBRB输出和真实输出Fig. 3 Liu_EBRB output and real output
为了进一步验证本文方法的有效性和可行性,表2列出了Liu_EBRB系统、BK_EBRB系统和NSGA-II_EBRB系统产生的推理输出和测试数据的真实输出的MAE值,其中BK_EBRB系统是指根据文献[28]中的方法构建的EBRB系统。如表2所示,和Liu_EBRB系统的MAE相比,NSGA-II_EBRB系统比Liu_EBRB系统的MAE值减小了61.61%;和BK_EBRB系统相比,NSGA-II_EBRB系统要比BK_EBRB(theta=0.7)的MAE值减小56.92%;和BK_EBRB(theta=0.4)的MAE值相差无几。
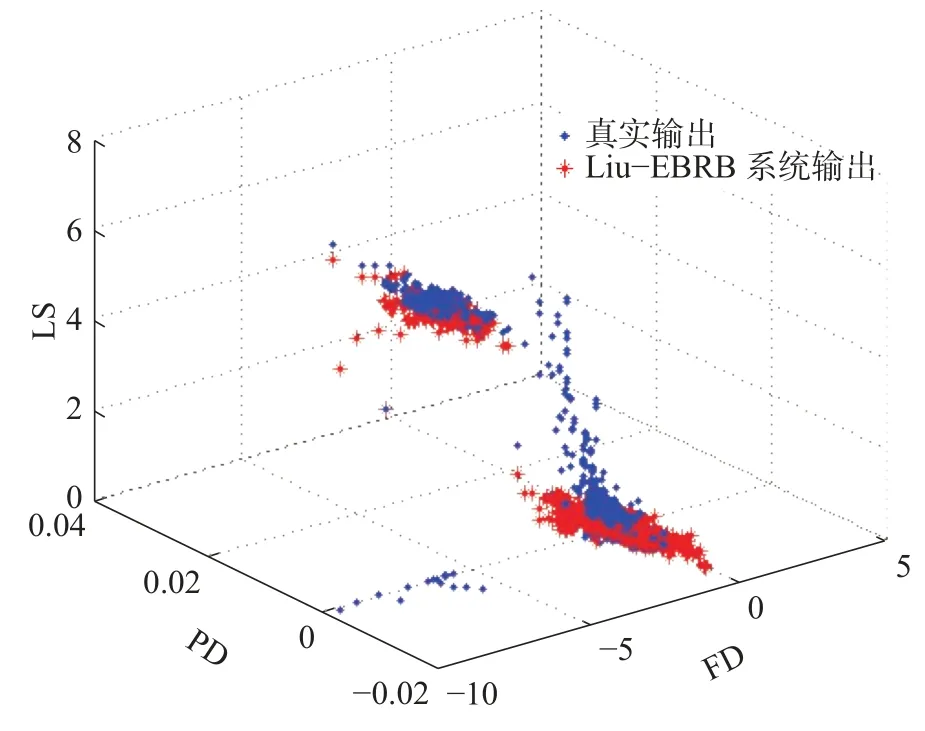
图4 NSGA-II_EBRB输出和真实输出Fig. 4 NSGA-II_EBRB output and real output

表2 输油管道泄漏实例实验结果Table 2 The results on pipeline leak detection
4 结束语
数据驱动型的扩展置信规则库系统易受数据质量的影响,其推理能力常因不一致的数据而降低。因此,本文提出基于NSGA-II的扩展置信规则库激活规则多目标优化方法,通过NSGA-II来求解不一致性更小的激活规则集合,该方法既筛选出了不一致性更小的激活规则,同时又保留了原来激活规则集合中绝大部分信息,这些最终参与ER合成推理的激活规则一致性更高,更具代表性,能有效提高EBRB系统的推理能力。然而,本文方法还有许多需要改进的地方,如何从Pareto最优解集中选择一个最合适的解,如何减少算法的复杂度等,这些都是将来的研究工作重点。
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
小猕猴智力画刊(2022年3期)2022-03-29
陶瓷学报(2021年2期)2021-07-21
数学小灵通(1-2年级)(2021年4期)2021-06-09
劳动保护(2019年7期)2019-08-27
福建基础教育研究(2019年11期)2019-05-28
Coco薇(2017年11期)2018-01-03
北京航空航天大学学报(2017年7期)2017-11-24
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
中学科技(2015年1期)2015-04-28
