
局部密度峰聚类耦合字典学习的图像融合算法
2018-07-19 12:54刘国英
计算机工程与设计 2018年7期
吴 亮,刘国英
(1.安阳师范学院 软件学院,河南 安阳 455000;2.武汉大学 测绘遥感信息工程国家重点实验室,湖北 武汉 430079)
0 引 言
图像融合主要是通过特定的融合技术,把不同传感器在相同场景获得的多个图像形成一个新图像,以改善图像视觉效果[1-3]。如张鑫等[4]提出了一种基于Contourlet变换的图像融合方法,利用不同的融合准则对Contourlet系数融合,但其缺乏平移不变性,容易产生伪吉布斯现象,形成的融合图像边缘光滑性不足。M.Kim等[5]提出了基于k-均值聚类耦合PCA方法来训练多个局部块子词典的多模态图像融合,使学习字典变得紧凑,信息更加有效。然而,k-均值方法的簇数需要预先设定,很难取得最优的融合性能。吴一全等[6]提出了一种基于Shearlet变换和TV模型的医学图像融合,对Shearlet变换低频进行区域方差融合,同时,对其高频子带,通过TV进行降噪处理,最后通过改进的Laplacian完成融合。
在字典学习过程中,字典中的系数可以自适应地学习输入图像,而无需先验知识。其比现有的方法可以更好实现降噪、图像融合和分类[7]。目前,基于稀疏表示字典学习方法被广泛应用于图像融合。Liu等[8]提出了一种结构化稀疏编码方法来处理异构多模态信息融合,取得了理想的融合质量。然而,冗余字典在稀疏表示中会导致计算成本增加。因此,一个高效的字典学习在图像处理中具有重要作用。
为了优化稀疏表示的图像融合方法的性能,本文提出了基于局部密度峰聚类耦合字典学习的图像融合算法。通过信息抽样、局部密度峰聚类,构建一个完整的字典学习,对图像块进行信息采样测量,并只将有用信息的图像块被选择为字典学习的对象。基于局部密度峰的聚类方法可以在需要设置聚类数量的前提下,将图像聚类成若干个簇类。通过利用该字典,可以更好地描述每个簇类的底层结构。基于K-SVD技术,构建字典学习机制,对每个图像块簇类完成训练,输出每个簇类的稀疏系数,再利用选择最大值融合准则对稀疏系数融合,获取融合图像。最后,测试了所提融合算法的融合性能
1 聚类算法
聚类是通过样本间的相似性,将样本分成不同种族,同一种族中的元素相似度高,不同种族中的元素相似度低[9]。基于密度的聚类技术可较好发觉任意形状,在参数设定合适时能有效发觉含噪声的聚类[10]。但是在参数设定时具有一定的难度,无法使得最优的参数值。近邻传播聚类方法是对所有的对象作为网络中的一个点,利用迭代变换对数据信息联络,搜索最优的代表集[11]。从而使得与最近的对象的相似度最高。AP具有良好的簇类效果,操作简单,效率高。其不足之处是对任意形状的聚类效果不佳。Rodriguez等[12]提出了一种基于密度峰聚类(density peaks clustering,DPC)方法。DPC能够发觉不同形状样本的密度峰值,同时对样本分配和异常点消除,可用于大量元素的聚类计算。但是DPC具有一些不足之处,主要表现为:没有设定一致的密度衡量标准,其根据样本容量使用不同的密度衡量标准。在容量较小时,截断距离对聚类性能影响较大。在对象分配中,其通过当前对象与最近对象密度比较,容易形成连锁错误反应,从而降低了聚类的准确度。特别是当对象间有重叠时,聚类性能大大降低。DPC的主要过程如下:
对于一个图像块i,计算其局部密度ρi,定义如下
(1)
式中:drij为块i,j的Euclidean距离。drc为截止距离。如果(drij-drc)<0, 则λ(drij-drc)=0, 反之,则λ(drij-drc)=1。 基本上,ρi等于点drc接近点Xi的数量。该算法只对相对大小不同的图像块ρi和强大的drc的集合。对于块i,到局部密度大于i的最近快j的距离δi,表示为
(2)
最小距离δi是来寻找聚类中心,δi是通过计算图像块i和其它高密度块最小距离。具有最高密度的图像块δk和其它图像块的距离最大,如式(2)表示。
2 本文图像融合算法设计
为了对图像达到一个更好的融合效果,对图像中的功能信息与解剖信息有效结合,本文引入一种新的字典学习方法。字典学习主要包括3部分:①信息采样;②局部密度峰值聚类;③基于K-VSD的字典构建。图1中显示了提出的字典学习的流程,首先,通过信息采样选择图像的信息区域。其次,利用提出的局部密度峰的聚类算法对图像块聚类。最后,根据K-VSD构建了新的字典学习方法。每个部分详细描述如下。
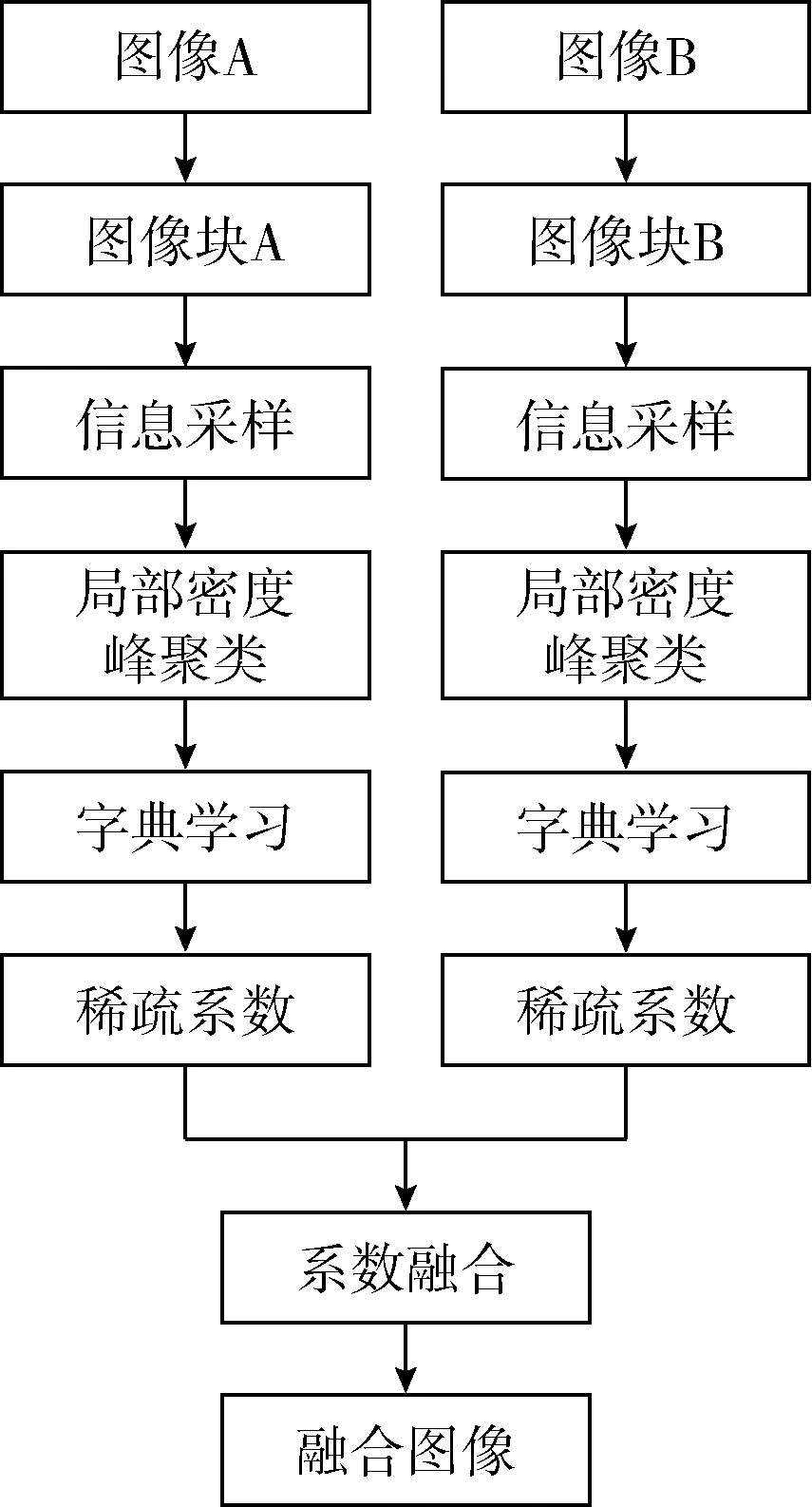
图1 本文图像融合算法
2.1 信息采样
对于多模态图像,不同的图像块所携带的特征具有很大差别,每个图像块所表示的信息有限。因此,在字典学习中,利用所有的图像块可能会导致信息冗余,一般不能产生最佳的图像融合结果[13]。为选择有用信息图像块,提出了一种信息采样方法。步骤如下:首先,通过式(3)构建矩阵T,其中包括每个图像块之间的Euclidean距离,表示如下
(3)

设图像块之间的最小距离为Di,定义如下
(4)
式中:Di是由计算图像块Si与其它残留图像块Sk的最小距离。
对于每个图像块Si,设置一个截止阈值τ,定义如下
(5)
如果Di>τ,则Sj=Si,否则Si=0。然后,剔除所有的零图像块。因此,通过提出的信息采样法,只选择有用信息的图像块,提高了信息的有效表达,降低了冗余信息。
2.2 局域密度峰聚类
对于不同模态图像,图像块具有不同的结构。因此,对于不同的图像块,需要将其分为不同的组,并通过不同的字典进行训练[14]。为了将图像块按结构相似度划分为特定的组,本文提出了一种局部密度峰聚类(local density peaks based clustering,LDPC)方法。该聚类算法的优点是图像块对起始点不敏感,聚类前不需要知道聚类的数目,能迅速寻找不同形状元素的密度峰值,并有效对样本分配和离群点消除。在DPC算法的基础上,为了降低截断距离对聚类性能的影响,对于样本容量小的DPC,利用指数核[15]测量密度
(6)
因此,聚类中心的δ较大,具有较高的ρ。通过建立块距离δ相对ρ的判断图,选取较大的ρ、δ作为聚类中心。对于其它对象j,通过与j的密度和距离进行判断。
为了降低噪声的干扰,在LDPC算法中规定了聚类边界条件,即通过属于该簇类但和其它簇类距离小于drc组成。设每个簇边界条件中密度最大对象为ρm,对于大于ρm的为该簇类的核,那么其它对象为噪声。
图2展示基于图像块的局部密度峰聚类的工作原理。图2(a)是输入MRI图像和图2(b)为PET图像。当局部密度ρi和距离δi通过计算可以构造局部密度图。局部密度图如图2(c)所示。在图2(c)中,垂直轴是局部密度ρi和水平轴的最小距离δi。结合密度聚类和距离的聚类,具有较大密度ρi和异常大的最小距离δi的图像块被定义为聚类中心。较大相对密度ρi和异常大的最小距离δi标记的方块图,如图2(c)右上角。当聚类中心被选中时,其余的图像块根据聚类中心的距离进行分组。
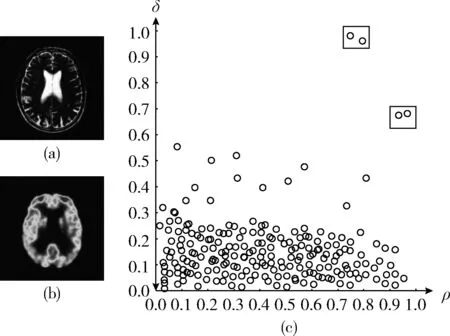
图2 局部密度峰聚类过程
2.3 基于K-SVD的字典学习
在局部密度峰的聚类过程中,图像块被分为不同组,为了有效地描述不同组中的图像块,通过K-SVD算法构建一个新的字典学习。K-SVD是最受欢迎的统计学习算法,可以最大限度地减少学习过程的重建误差[16]。通过2.1部分描述的信息采样方法得到输入图像块,利用基于K-SVD的子字典训练更加紧凑,但仍然含有图像的信息成分。此外,由于每个聚类中的图像块的结构是相似的,子字典学习方案可以得到输入图像块的更准确的结构描述。基于K-SVD的子字典学习表示如下:
就字典学习中,设计的目标函数满足以下条件
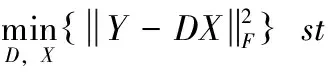
(7)
式中:Y为信号;D为字典;X是系数矩阵。此处中X与Y是列对应的,即字典中通过Xi完成线性变换,获得Y。构建一个字典需要通过稀疏表示和更新来完成。
对于稀疏表示,将字典D初始化,再将DX当作为D中的列和X中的行相乘。从而,完成DX的分片,表示为
(8)
在字典更新中,通过K次迭代进行更新。通过剥离K次目录,式(7)会导致一个空洞。因此,需要计算新的di与xi修复空洞,使其完成收敛,表示如下
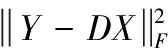
(9)
式中:E为误差矩阵;将E进行SVD分解得到
E=U∧VT
(10)
式中:U,V分别为矢量;∧为对角矩阵。如果∧中元素按从大到小排布,那么E的能量也是从大到小排布。设U的开始列向量为di,V中开始列向量与∧的积为xi,从而进行了字典的目录更新。
X为一个稀疏矩阵,根据以上方法获得的X可能不符合稀疏条件。因此,只需要对xi的非0列求解。通过xi的非0元素建立新的矩阵Γ,因此,E与x可分解表示为
(11)
通过对E的SVD分解,得到了新字典的目录。通过Γ相乘,消除了无用的向量。
本文提出的图像融合框架如图3所示。主要由字典学习,稀疏表示和系数融合部分组成,在稀疏表示中,图像被划分为若干个图像块,通过字典训练进行稀疏表示。在系数融合阶段,通过选择最大值融合准则对稀疏系数融合,表示如下
(12)
式中:F-1SBk×l表示大小为k×l图像块的系数,通过最大值融合规则可较好保留源图像的细节特征。
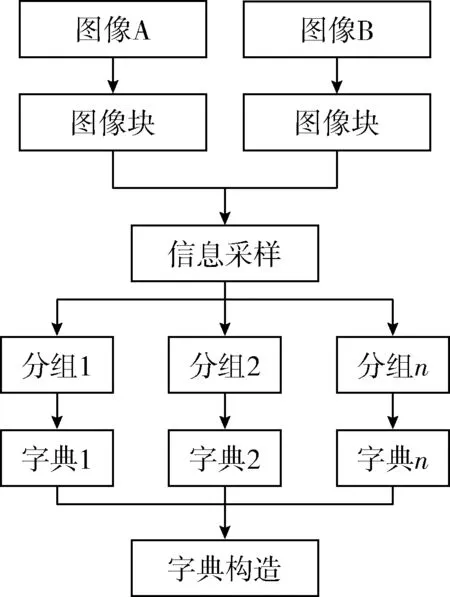
图3 字典学习结构
3 实验与分析
为了显示所提字典学习的方法的有效性,利用常见的医学图像进行实验,并分别与基于Contourlet融合方法[4]、基于k-均值的融合方法[5],基于Shearlet的融合方法[6]进行对比。实验环境为:Intel(R)I3,3.30 GHz,四核CPU,8 GB的RAM,WIN7操作系统,借助MATLAB7.0软件进行仿真分析。
3.1 评价指标
为了对提出的融合方法进行定量分析,引入了图像融合中流行的客观评价指标:均方根误差(root mean square error,RMSE),相关系数(correlation coefficient,CC),平均梯度(average gradient,AG),边缘强度(edge strength,ES)。分别表示如下:
均方根误差(root mean square error,RMSE)衡量融合图像与参考图像间的差异[17]。RMSE越小,表示差异值越小,融合图像质量越好,表示为
(13)
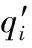
CC表示两图像相关关系的密切程度,CC越逼近1,表示图像的接近度越好,定义如下[18]
(14)
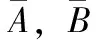
AG主要反映图像中细微特征差异,AG越大,说明图像越清楚,其定义为[19]
(15)
式中: ΔIx(i,j) 与ΔIy(i,j) 分别为图像x,y上的差分。
ES描述了输入图像与融合图像边缘信息的相对量[20]
(16)
式中:QXF(i,j)、QYF(i,j) 分别图像X,Y的边缘保持值,wX(i,j)、wY(i,j) 分别为QXF(i,j)、QYF(i,j) 的权重。ES的值越高,表示融合图像边缘质量越好。
3.2 实验结果
CT图像对骨组织成像清楚,但对病灶表示较模糊。MRI对软组织成像清楚,显示病变部位。PET表示新陈代谢功能,但无法对解剖信息表示。单一的图像无法准确提供准确、完整的信息,通过将不同图像融合,进行信息互补,提高医学图像在疾病诊断中的作用。为了验证算法的融合性能,进行2组实验:①CT与MRI融合;②MRI与PET融合。
图4为CT与MRI融合实验。图4(a)、图4(b)分别是CT、MRI图像,图4(c)~图4(f)分别是基于Contourlet、基于k-均值、基于Shearlet的融合方法与本文算法的融合结果。依据图4(f)中得出,提出的字典学习方法得到的CT与MRI融合图像的细节丰富,清晰度良好,很好保留了源CT与MRI中的骨组织与软组织,融合了CT与MRI中的有效信息。图4(c)中对比度降低,部分细节特征丢失,并且出现了伪吉布斯现象。图4(d)中得到的图像清晰度不足,细节区域表现不佳。图4(e)中得到的骨组织出现了弱化现象,分别如图4中方框所示。
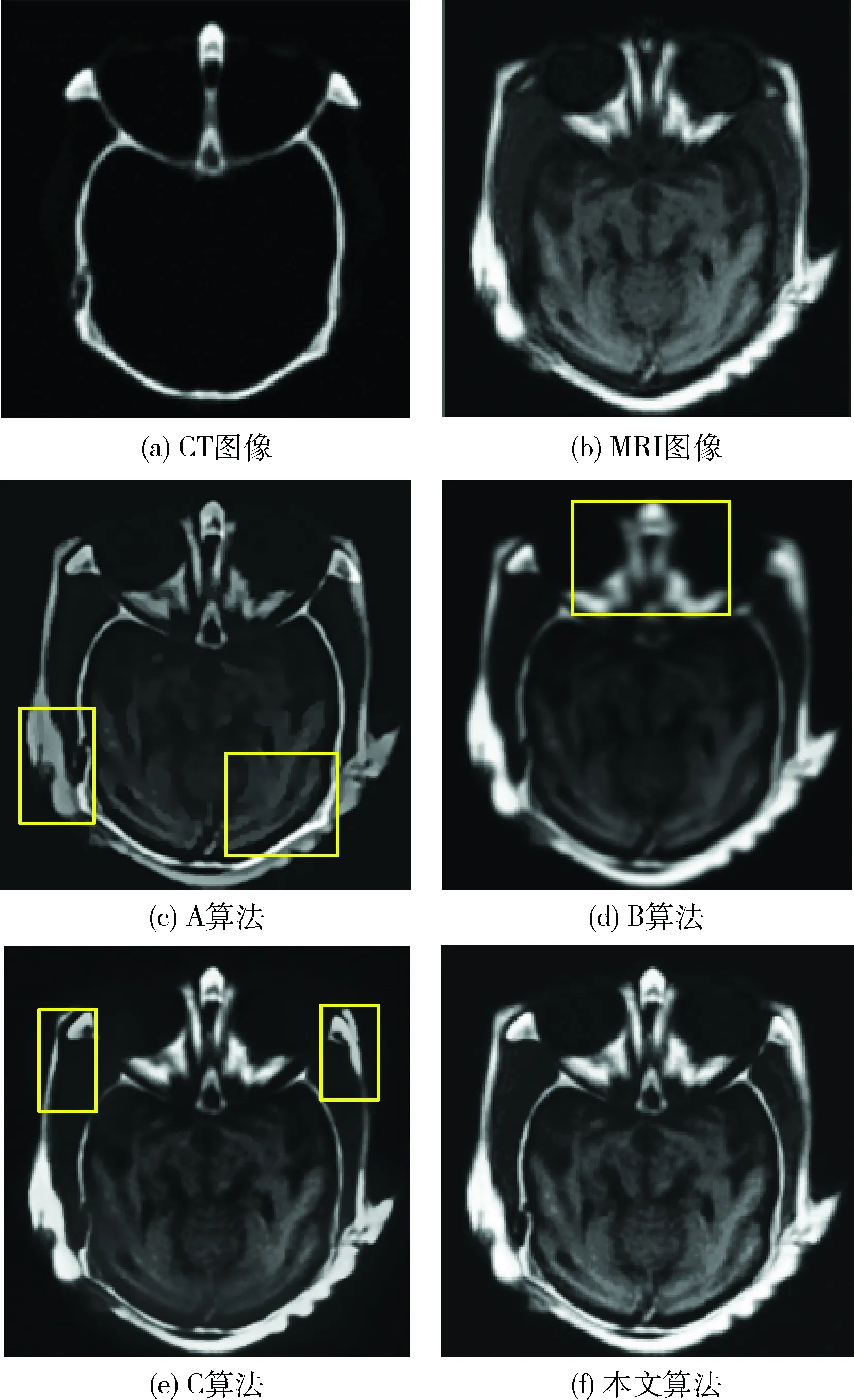
图4 CT与MRI融合实验结果
图5是MRI与PET融合结果。图5(a)为MRI图,图5(b)为PET图,图5(c)~图5(f)分别为基于Contourlet、基于k-均值、基于Shearlet方法与本文方法的融合结果。图5(f)为本文方法得到的融合图像,从5(f)中可得出,本文算法有效结合了MRI与PET的有效信息,得到了图像清晰度良好,较好呈现了解剖细节与功能信息。图5(c)中边缘连续性不佳,对源MRI与PET的表现不足。图5(d)中产生了边缘模糊,细节保护不足。图5(e)中较好保持了MRI与PET中的有效信息,但在一些细节区域表现力还有待加强,不足之处如图5中方框所示。
为了对融合算法进行定量评价,利用当前流行的评价指标RMSE,CC,AG,ES对CT与MRI和MRI与PET得到的融合图像定量测量,结果见表1与表2。依据表1与表2中数据得出,与基于Contourlet、基于k-均值、基于Shearlet方法比较,本文算法在CT与MRI,MRI与PET融合图像中的RMSE,CC,AG,ES均具有良好表现,同时也与图4、图5中的实验结果相互印证。表明了提出基于字典学习的融合算法性能优异。能够有效结合源图像有用信息,获得了细节丰富,边缘清晰,光谱信息良好的融合图像。
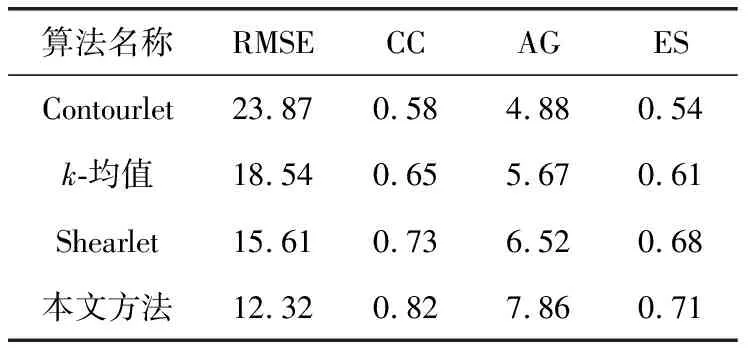
表1 CT与MRI图像融合实验结果对比
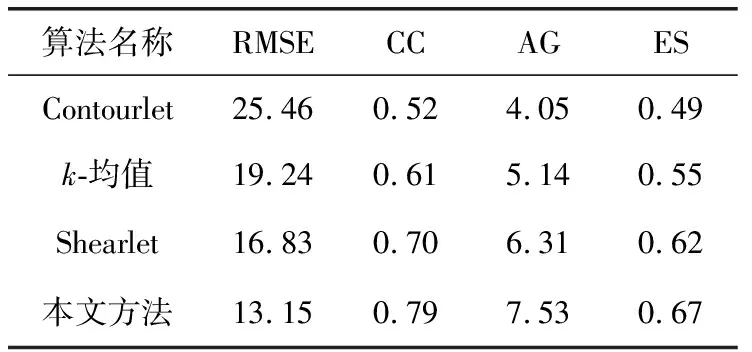
表2 MRI与PET图像融合实验结果对比
为了进一步测量融合算法的性能,以图4(a)、图4(b)中的CT与MRI为对象,通过PS加入不同大小高斯噪声(噪声大小从0到10,步长为1),分别测量在不同噪声下的RMSE,CC,AG,ES值,得到的结果如图6所示。从图6可得出,随着噪声的增加,RMSE的值逐渐增大,CC,AG,ES的值逐渐降低,说明融合性能受到噪声干扰,曲线下降的越快,算法对噪声越敏感。从图6中得知,基于Contourlet、基于k-均值、基于Shearlet方法受噪声影响较大,而提出的基于字典学习方法的抗噪声性较强。
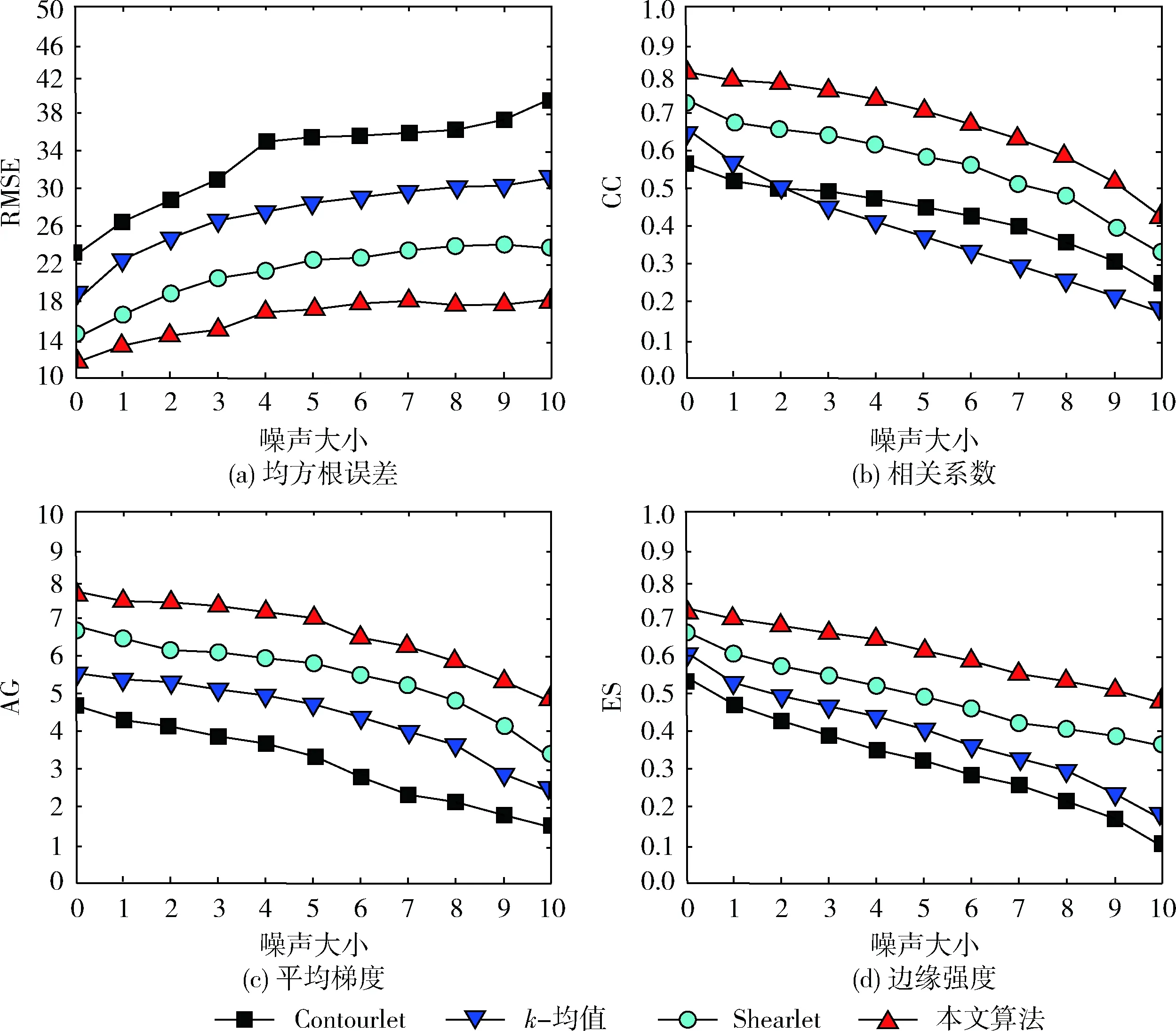
图6 CT与MRI融合抗噪性测试
从图4、图5得到的实验结果以及表1、表2的定量测量数据得知,提出的基于局部密度峰聚类耦合字典学习的图像融合算法能够有效完成CT与MRI融合,MRI与PET融合,保留了源图像的骨组织信息、软组织细节与功能信息,具有更清晰边缘,符合视觉效果,能够为疾病诊断提供全面、完整的依据。主要是本文为提高信息的有效表达,将图像被划分为若干个图像块,利用信息采样法,选择有用信息的图像块,降低冗余信息。并且设计了局部密度峰聚类方法,对具有相似结构信息的图像块分类,得到不同的图像块簇类。通过K-SVD构建字典学习,对每个簇类训练,得到每个簇类的稀疏表示。为了得到融合图像,通过最大值融合准则融合重构。由于本文通过图像分块与字典学习,大大降低了信息冗余,从而提高了计算效率。而基于Contourlet方法无平移不变性,易导致伪吉布斯,边缘光滑性不足。
4 结束语
为了改善图像的融合质量,本文通过构建新的完备字典,提出了一种图像融合技术。首先,将输入图像被划分为子块,引入信息采样法,从子块中择取有用信息的图像块;并定义了局部密度峰聚类方法,对具有相似结构信息的图像块进行分类,获取不同的图像块簇类;同时,引入K-SVD技术,建立字典学习机制,对子块簇类完成训练,获取每个簇类的稀疏系数;引入最大值融合准则,对子块的稀疏系数进行融合,输出重构图像。测试数据显示:与当前图像融合技术相比,本文方法在RMSE,CC,AG,ES的定量评价中具有更大的优势。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-22
数学物理学报(2021年2期)2021-06-09
小学阅读指南·低年级版(2019年11期)2019-07-01
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
创新作文(小学版)(2016年19期)2016-08-22
发明与创新(2016年38期)2016-08-22
艺术生活-福州大学厦门工艺美术学院学报(2016年3期)2016-07-31
读者(2016年14期)2016-06-29
电子设计工程(2015年6期)2015-02-27
