
几何平均参与评价划分属性的决策树
2018-07-19 12:53罗计根
计算机工程与设计 2018年7期
王 卓,聂 斌,罗计根
(1.南昌大学 软件学院,江西 南昌 330047;2.江西中医药大学 计算机学院,江西 南昌 330004)
0 引 言
属性选择度量作为启发式方法,很大程度上决定了决策树的分类效果,是决策树研究的关注点之一。
信息增益准则对可取值数目较多的属性有所偏好,信息增益率准则对可取值数目较少的属性有所偏好[1,2],随后有CART、PUBLIC、SPRINT算法等,另外,也有从剪枝的角度优化决策树。还有一些研究者从其它方面改进决策树算法[3-15],取得了较好的效果。文中侧重折中划分属性受属性取值多少的影响,提出几何平均参与评价划分属性的决策树研究。
1 信息增益与信息增益率
常用的属性选择度量有:信息增益、信息增益率和基尼指数。为了折中划分属性受属性取值多少的影响,采用几何平均参与评价划分属性。便于描述,期望、信息增益、信息增益率的相关定义、定理、公式等请参见文献[1,2]。
1.1 信息增益
假设期望为Info(·),则对训练集D中的元组分类所需要的期望为
(1)
设按属性A划分对训练集D的元组分类所需要的期望信息为
(2)
则信息增益为
Gain(A)=Info(D)-InfoA(D)
(3)
1.2 信息增益率
分裂信息
(4)
信息增益率为
(5)
实践过程中,因为信息增益率准则对可取值数目较少的属性有所偏好,所以,C4.5算法并不是直接选择信息增益率最大的候选划分属性,而是使用了一个启发式算法。计算属性的全部未用属性算术平均信息增益方法为
(6)
2 信息增益和信息增益的几何平均值
信息增益和信息增益的几何平均值(geometric average of information gain and information gain rate,GAIGIGR)计算方法如下
(7)
(8)
3 基于信息增益与信息增益率的几何平均值建立决策树算法
为了折中划分属性受属性取值多少的影响,基于信息增益与信息增益率的几何平均值(GAIGIGR)建立决策树算法的基本思想为:首先,从候选划分属性中,筛选出高于信息增益算术平均水平的属性;然后,分别计算这些属性的信息增益率和信息增益的几何平均值,从中选择几何平均值最大的属性,建立分支决策;最后,用递归方法建立决策树。
3.1 算法描述
GAIGIGR决策树算法描述为:
输入:训练数据集D,属性集A,阈值ε;
输出:决策树T。
(1)如果训练集D中所有元组属于同一类Cj,则置Tree为单结点树,并将Cj作为该结点的类,返回Tree;
(2)否则,没有剩余属性用以划分元组,采用多数表决方式,将训练集D中元组最多的类Cj作为该结点的类,返回Tree;
(3)否则,按式(3)计算A中各属性对D的信息增益,并从大到小排序;
(4)按式(6)计算A中各属性对D的信息增益的算术平均值;
(5)结合(3)(4),删除小于信息增益算术平均值的属性信息增益;
(6)按式(7)或式(8)求剩下属性的信息增益和信息增益率的几何平均值GAIGIGR(A),选择该值最大的属性Ag;
(7)如果Ag的值小于阈值ε,则置T为单结点树,并将D中实例数最大的类Cj作为该结点的类,返回T;
(8)否则,对Ag中的每一可能值ai,依Ag=ai将D分割为子集,即若干非空Di,将Di中实例数最大的类作为标记,构建子结点,由结点及其子结点构成树T,返回T;
(9)对结点i,以Di为训练集,以A-{Ag}为属性集,递归地调用(1)~(8),得到子树Ti,返回Ti。
3.2 算法的理论分析
信息增益与信息增益率的几何平均,参与评价划分属性,生成决策树,减少了对属性取值多与取值少的偏好,从而尽可能地减少生成不平衡树的可能性,同时减少过拟合现象,在一定程度上可以提高分类准确性和提升生成决策树的效率。
4 实验与结果
为了验证采用信息增益与信息增益率几何平均值选择分裂属性建立决策树算法有效性,选取了ID3、C4.5,以及CART这3个经典算法进行比较。
4.1 实验数据及说明
实验采用了4份数据,包括Iris数据集(http://archive.ics.uci.edu/ml/datasets/Iris),Breast Cancer Wisconsin数据集(http://archive.ics.uci.edu/ml/datasets/Breast+Can-cer+Wisconsin+%28Original%29),天气数据集(http://blog.csdn.net/czp11210/article/details/51161531),QSAR biodegradation Data Set(http://archive.ics.uci.edu/ml/datasets/QSAR+biodegradation)。
Iris数据集:条件属性(自变量)4个,分类属性(因变量)1个,样本总数为150条。
Breast Cancer Wisconsin数据集:条件属性有肿块厚度、细胞大小的均匀性、细胞形状的均匀性、边际附着力等9个,分类属性1个,样本总数为699条。
天气集数据:4个自变量,并且全部为离散型自变量,因变量1个,样本总数13条。
QSAR biodegradation Data Set:41个自变量(属性),样本总数1055条。
以上数据集实验验证时,按7∶3比例,随机将样本分成训练集和测试集建模,叶子节点最大容许个数为3;叶子节点最大容许误差为0.001。另外,天气数据集样本较少,用五折交叉验证的方式进行建模,其它数据集采用十折交叉验证的方式进行建模。
4.2 实验结果
计算设备配置为:AMD A10-8700P Radeon R6,10Compute Cores 4C+6G 1.80 GHz,RAM 8.00 GB,64位操作系统。对以上4份实验数据,利用信息增益和信息增益的几何平均值GAIGIGR、信息增益(information gain,IG)(ID3)、信息增益率(information gain rate,IGR)(C4.5)以及GINI指数(CART)作为属性划分的标准,建立决策树模型。分别就不同数据集的分类准确性、计算时间等方面进行比较分析,比较的结果如图1至图7,图表采用Microsoft Office excel 2007编辑制作,图中下半区为实验结果的数据信息,上半区是以柱形和颜色为标识的图形区;横坐标为各种划分属性的方法,纵坐标表示分类准确度;上半区柱形从左至右排列,对应下半区数据从上至下的行,并与颜色对应。图表相关的表述说明:(ID3+C4.5+CART)/3是ID3、C4.5、CART这3种方法结果的平均数。
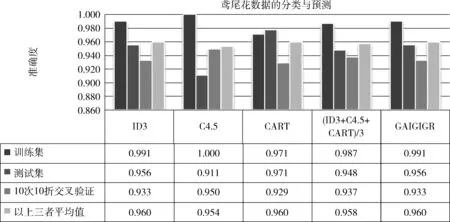
图1 鸢尾花数据集的分类预测结果比较
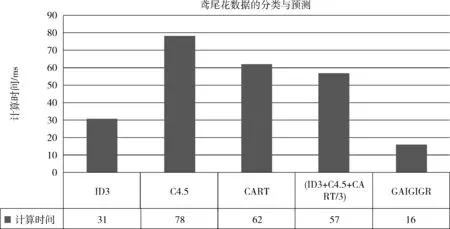
图2 鸢尾花数据集的计算时间结果比较
(1)Iris数据集的实验结果
1)准确性比较:①在训练集、测试集及十次十折交叉验证单方面:4种属性划分的准确性都很高,稍各有优势;②在训练集、测试集及十次十折交叉验证的平均数方面:GAIGIGR在3种测试方法中的准确性平均值最高;③在信息增益、信息增益率以及GINI指数三者结果的平均值而言:GAIGIGR的准确性在训练集、测试集稍高,在10次10折交叉验证稍低。
2)计算时间比较
采用4种属性划分标准建立决策树、计算其准确性、生成决策树图等,GAIGIGR方法的运行时间仅为16 ms,是4种方法中时间最少的,且优势明显。
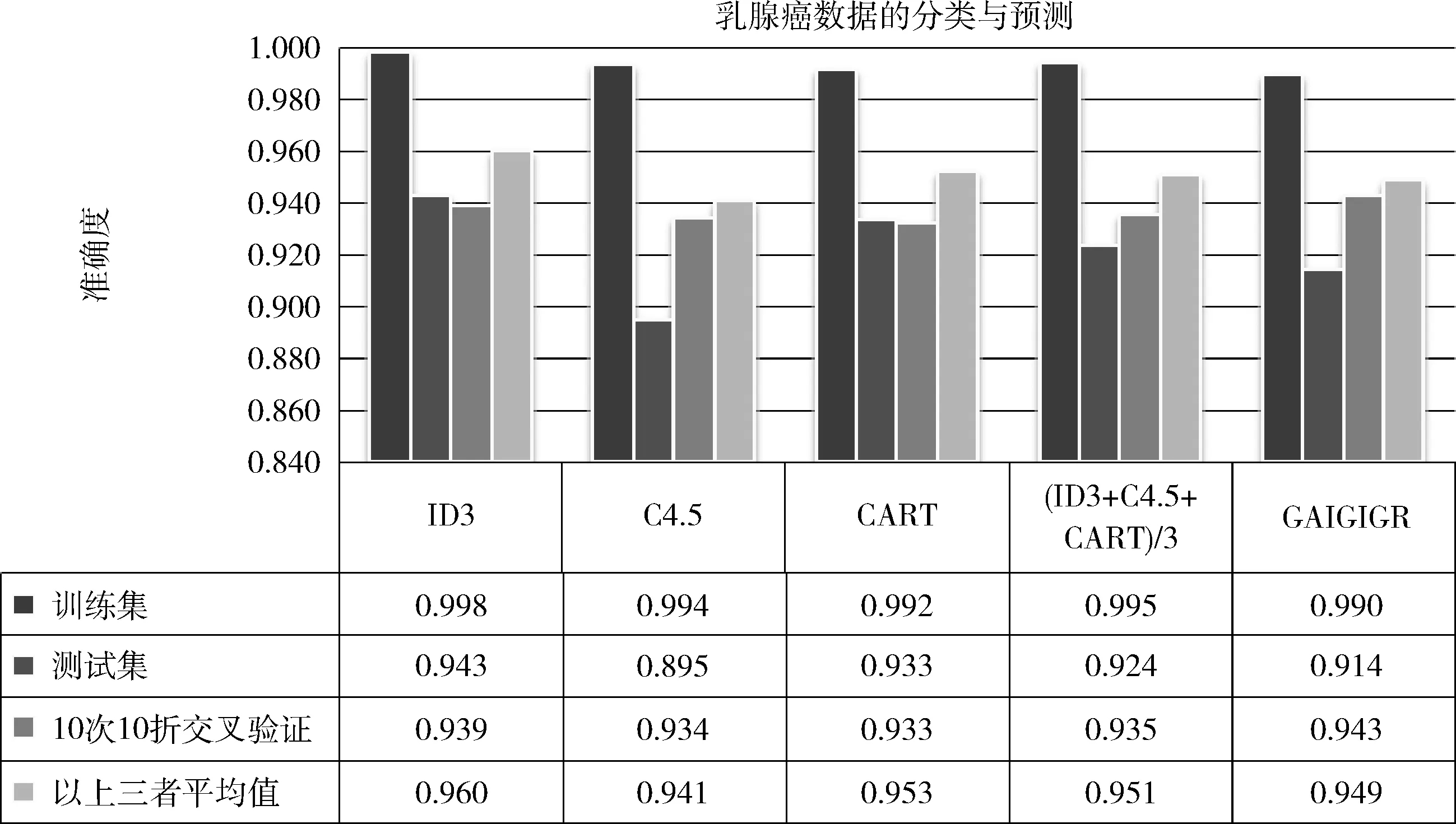
图3 乳腺癌数据集的分类预测结果比较
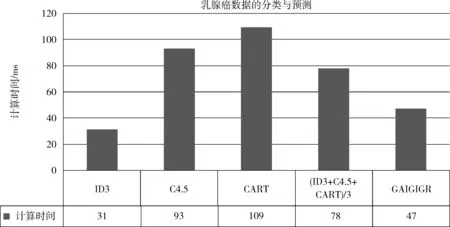
图4 乳腺癌数据集的计算时间结果比较
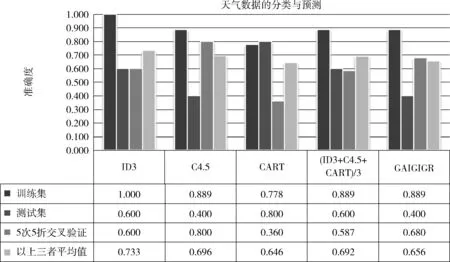
图5 天气数据集的分类预测结果比较
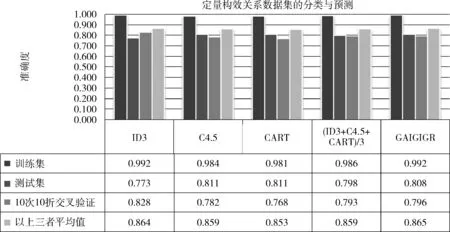
图6 QSAR biodegradation 数据集的分类预测结果比较
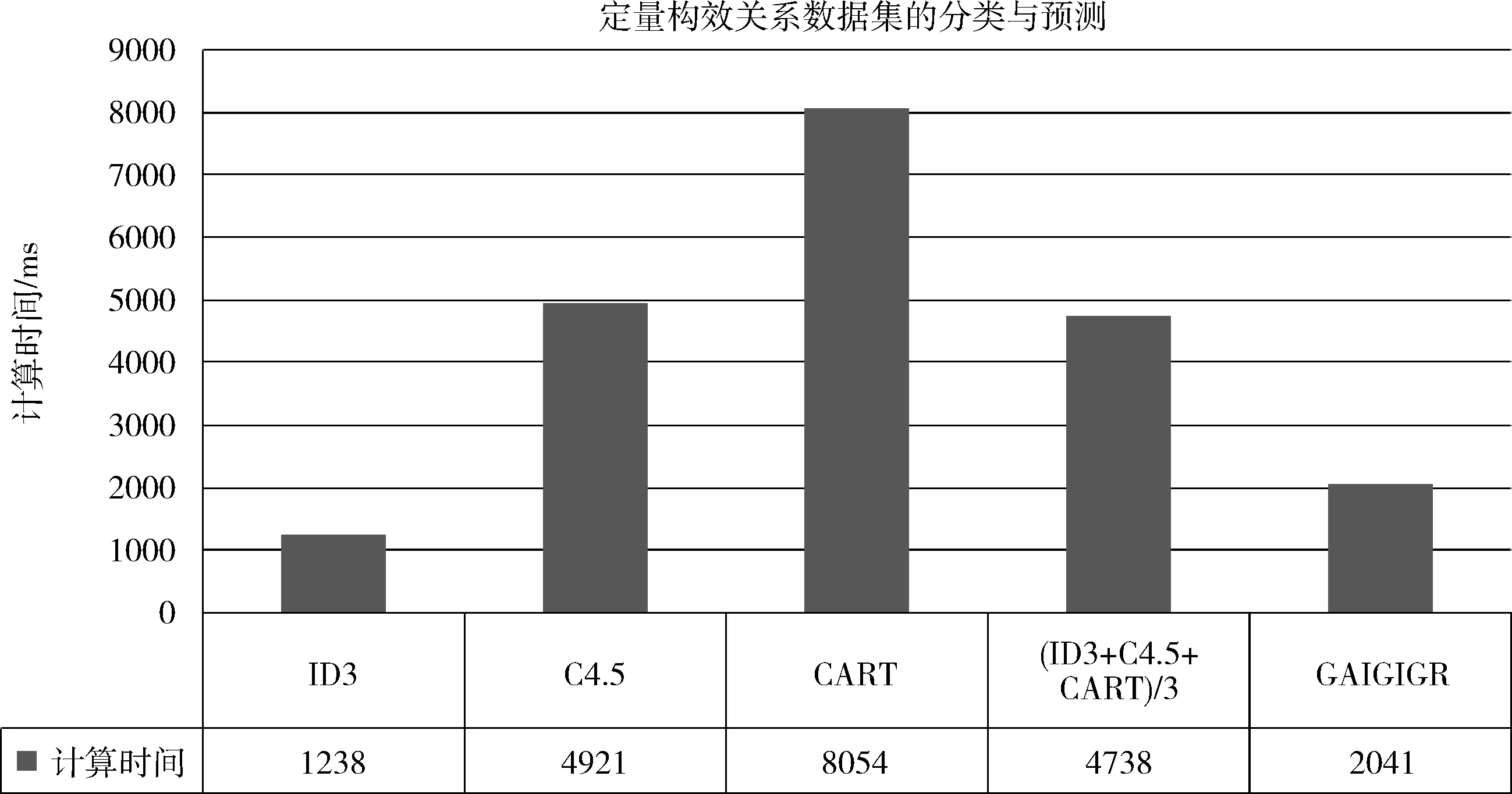
图7 QSAR biodegradation 数据集的计算时间结果比较
(2)Breast Cancer Wisconsin数据集的实验结果
1)准确性比较:①在训练集、测试集及10次10折交叉验证单方面:4种属性划分的准确性都很高,稍各有优势;②在训练集、测试集及10次10折交叉验证的平均数方面:GAIGIGR方法比C4.5方法好;③在信息增益、信息增益率以及GINI指数三者结果的平均值而言:GAIGIGR的准确性在训练集、测试集稍低;在10次10折交叉验证稍高。
2)计算时间比较
采用4种属性划分标准建立决策树、计算其准确性、生成决策树图等,GAIGIGR的计算时间比信息增益稍高,但比信息增益率以及GINI指数计算时间要低得多。
(3)天气集数据的实验结果
1)准确性比较:①在训练集、测试集及10次10折交叉验证单方面:4种属性划分的准确性都不稳定,在训练集上较高,在测试集及5次5折交叉验证方面,波动较大;②在训练集、测试集及10次10折交叉验证的平均数方面:GAIGIGR方法比CART方法好;③在信息增益、信息增益率以及GINI指数三者结果的平均值而言:GAIGIGR的准确性在训练集持平,在测试集稍低,在5次5折交叉验证稍高。
2)计算时间比较
采用4种属性划分标准建立决策树、计算其准确性、生成决策树图等,计算时间都接近于0,效果都很好。
(4)QSAR biodegradation Data Set的实验结果
1)准确性比较:①在训练集、测试集及10次10折交叉验证单方面:4种属性划分的准确性都不够稳定,在训练集上较高,在测试集及10次10折交叉验证方面,波动较大;②在训练集、测试集及10次10折交叉验证的平均数方面:GAIGIGR方法最好;③在信息增益、信息增益率以及GINI指数三者结果的平均值而言:GAIGIGR的准确性在训练集持平,在测试集稍低,在5次5折交叉验证稍高。
2)计算时间比较
对于本数据集而言,GAIGIGR的计算时间比信息增益稍高,但明显优于信息增益率以及GINI指数计算时间。
5 结束语
通过4份不同规模数据实验,利用GAIGIGR,信息增益,信息增益率,GINI指数作为属性划分的标准时:①在训练集、测试集及10次10折交叉验证单方面:4种属性划分的准确性都较高,偶尔波动较大;②在训练集、测试集及10次10折交叉验证的平均数方面:GAIGIGR方法最好;③比较信息增益、信息增益率以及GINI指数三者结果的平均值而言:GAIGIGR方法准确性较好;④在运行时间方面:GAIGIGR方法有明显优势。
文中采集的一次实验结果表明,利用GAIGIGR,信息增益,信息增益率,GINI指数作为属性划分的标准的准确率都很高,而GAIGIGR能很好地解决属性值倾向的问题,稳定性好,可行有效。
在研究和实验中发现,每次随机将样本分成训练集和测试集建模时的结果会有一定的差异,如何使得实验结果相对稳定,是下一步研究的重点。
猜你喜欢
武汉工程职业技术学院学报(2022年1期)2022-04-13
北京航空航天大学学报(2021年6期)2021-07-20
电子制作(2019年19期)2019-11-23
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年19期)2018-11-14
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
中学数学杂志(高中版)(2014年2期)2014-05-26
电测与仪表(2014年6期)2014-04-04
