
基于CBOW模型的个人微博聚类研究
2018-07-10 09:25:54宋添树李江宇张沁哲
电脑与电信 2018年4期
宋添树 李江宇 张沁哲
(内蒙古科技大学 信息工程学院,内蒙古自治区 包头 014010)
1 引言
微博是一种以140个字符为上限的新兴的网络社交平台,根据应用目的分为官方微博和个人微博两种。其中官方微博主要发表与其所在单位相关的广告、通告以及其领域内事件等等,官方微博的内容随时间顺序排列整齐、不容易混乱。近年来,随着个人电脑、智能手机的普及,人们逐渐将社交眼光放在了微博平台上。由于微博平台的便利性和计算机网络的发展,个人微博的数量和事件的复杂度逐年增加,如果用户想了解一个人的专业领域、兴趣爱好以及表达方式方法等内容需要逐条浏览每条微博,不易查询,费时费力,如果将相似事件的微博聚类在一起可以极大地解放劳动力,快速地对博主形成认知,还可以为其他应用软件提供数据便利。当前国内外的聚类算法大都基于字数较长的文档类型,主要方法有词共现法、词频-文档频率法等刻画空间点的分布再根据各类聚类算法对距离的不同应用进行聚类,此类方法聚类精确度较低,只能应用于粗放型的分类,对于个人微博字数较少的特殊情况来看,矩阵和二维表中出现0的情况十分普遍,因此并不十分适用个人微博中语义复杂、事件多变的情况。
因此本文依上述问题提出了基于语义相似度的个人微博聚类算法,将语义相似度大的微博聚类在一起。首先将个人微博进行分词并去除停用词;其次使用机器学习CBOW模型训练词语向量;再次使用改进的曼哈顿距离法计算相似度;最后使用clarans法进行聚类。
例如冯小刚微博:
(1)“《芳华》是一封情书,写给青春的,写给军队的,写给那些女兵的大荧幕作品。”
(2)“青春不老,佳音终传,谁的等待都不愿辜负。12月15日,电影全国及北美地区同步上映。”
按照词频-文档频率以及词共现法分析,这两条微博并不相关,但是在语义层面上来看这两句话都与“电影”相关,因此本文的研究目的就是将语义层面上相似度大的微博聚类在一起,使用户可以分类查看自己感兴趣的内容。综合考虑了个人微博特点,采用python语言爬取个人微博;使用jieba分词工具进行精细分词并去除停用词;形成0、1组成的向量空间;使用CBOW模型训练词语向量,缩短训练窗口,降低维度;根据较低维度的向量距离计算文本相似度;最后进行聚类。
2 相关工作
文本聚类工作应用十分广泛,主要针对论文一类的文档归类;将混杂在一起不同领域的文章有效地分开,根据用户设定的聚类粒度大小将文档聚类。有相同属性的文章聚类在一起,不同属性的文档则不属于一类。
他人的相关研究对本文起了重要的作用。在中文语义相似度计算方面,赵世奇等人提出了LFIC(Linguistic Features Indexing Clustering)方法进行文本聚类,提取了文本的主题,同时基于汉语语言学将语义层面的相似度考虑进去[1]。刘群、李素建等人创建了How Net词汇库将词语之间的关系用树状关系或网状关系表示,根据从属关系和并列关系计算词语之间的相似度。这种体系对语义相似度的影响十分深远[2]。王小林等人根据How Net体系结构运算量较大的弊端改进了语义相似度的计算公式,使相似度更加精确[3-4]。
在文档聚类方面,Vesanto J等人提出了一种自组织映射数据挖掘(SOM)算法,该算法可以有效利用数据原型来可视化和探索数据的属性,与传统k-means算法相比有了明显的提高[5]。Ding C H等人主要针对k-means聚类算法中高维灾难问题提出了优化算法PCA(Principal Component Analysis),通过降维降噪算法优化聚类结构,实验数据使用DNA和互联网新闻数据证明了PCA算法比传统k-means算法有更快的聚类速度和准确程度[6]。Elhamifar E等人针对现如今高维数据集合,如图像、视频、文本和网页文档,以及DNA微阵列数据等等,这些高维数据大多是多个低维数据的子集组成的集合,提出了一种稀疏子空间聚类的算法对位于低维子空间联合中的数据点进行聚类[7]。Vimalarani C等人和Zhang D等人采用支持向量机SVM无监督学习结合一般聚类算法应用于文本聚类运算中,并取得了良好的效果[8-9]。
3 微博聚类
聚类过程主要分为五个部分:(1)预处理阶段分词并去除停用词,汉语语言处理主要基于词语来进行,将微博语句分词将很大程度上方便计算过程。本文采用python语言调用jieba分词词库将微博句子分词;(2)将分词结束后的微博文本形成一个词汇-文档0,1分布的二维表格,将这个二维表格作为机器学习的输入端;使用CBOW机器学习方法训练词汇向量,缩短微博所代表的向量维度;(3)由词汇向量可以算得微博语句向量;(4)句子向量代表了空间中的一个一个的点,采用本文改进的曼哈顿距离计算微博之间的相似程度;(5)根据所计算的相似程度最后采用clarans方法聚类。示意图如图1所示。
3.1 预处理
个人微博的聚类算法首先要获取数据集合,本文主要基于用户数量最多的新浪微博获取个人微博数据。首先将个人微博数据集合按照时间顺序排列形成最初的数据集合。最初的数据集合中含有无法处理的杂质内容,例如表情、图片、视频、音频等。预处理的过程就是将这些无法通过正常自然语言处理进行计算的部分去除,过滤掉微博中的杂质之后形成个人微博集合T={t1,t2,...,tn}。此时个人微博集合中仅含有汉字部分。
将个人微博集合进行分词、去除停用词处理,将处理之后的集合表示为Tr={tr1,tr2,...,trn}。
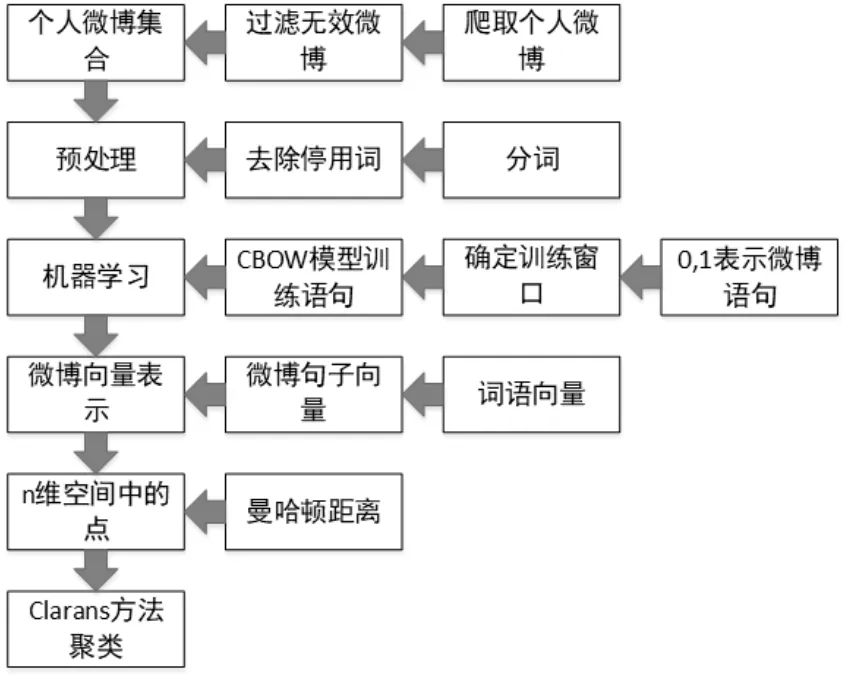
图1 个人微博聚类示意图
3.2 机器学习
CBOW模型(Continuous Bag-of-Words)是一种用于神经网络的语言模型。CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是特定的一个词的词向量。其中,输入词向量为词袋模型刻画的词向量,输出为Softmax函数的浮点数降维的词语向量。若给出训练词序列w1,w2,...,wn,CBOW的训练目的是使每个词语的平均对数概率最大化。

C(wn)为模型输出词语向量结果,N为训练词语的个数,k为训练窗口的大小。给出词语wn从训练窗口-k到k之间计算正确预测词语wn+j的对数概率。概率函数p通过Softmax函数刻画。

使用CBOW模型,给出大量语料库训练词语向量,获得个人微博语句中每一个词的词语向量的值。本文实验综合考虑计算机性能以及算法优化这两方面内容给定训练窗口为50维度。
3.3 个人微博句子向量
通过3.2节中利用CBOW模型训练得出词语向量。每一个词语都有一个特定的向量表示,每个个人微博语句都有一个或多个词语组成,下面的过程就是将词语向量合理地表示为句子向量。
词语向量的本质是预测这个词语上下文出现其他词语的可能性,因此将句子向量看作是词语向量的平均值能够有效地表达出这种关系。

图2 句子向量

其中vec(sentence)是句子向量,vec(wsi)是一个句子中的词语向量。
每个个人微博语句向量表示完成之后,每个向量可以视作一个n维空间中的一个点。因此多个个人微博相当于在同一个n维空间中点的集合。将这些点合理地划分粒度大小以及根据粒度大小合理地聚类。
3.4 聚类
获得个人微博所代表的点之后进行个人微博之间相似度计算,句子之间的相似度归结为两个点之间的距离大小,普通的距离算法例如欧几里得距离会产生大量的浮点数运算,在空间维度较高的条件之下会消耗大量的时间,因此优化距离算法是个人微博这类短文本聚类的首要工作。
曼哈顿距离(Manhattan distance)又称为出租车距离,描述的是两个点之间横纵坐标之间距离而并非两个点之间直线距离。利用曼哈顿距离计算两点距离可以节省大量的计算机浮点运算。

其中Dis(p1,p2)为两个个人微博所代表的点之间的曼哈顿距离。D1至Dn为n维向量空间,1到n维之间距离之差求和就是两个点之间的具体距离,即个人微博之间的相似度。
得出两个微博相似度之后采用clarans算法对个人微博进行聚类工作。
clarans(A Clustering Algorithm based on Randomized Search,基于随机选择的聚类算法),中心思想是随机选择一定数量的聚类中心,然后不停地移动聚类中心使得每个簇的成员到聚类中心的距离最小。每次计算两个点的距离时,使用公式(4)计算。
算法1 clarans聚类
输入:聚类中心的个数n,每个中心最大半径maxneighbor
输出:聚类结果
1 获得聚类中心{vec1,...,vecn}
2 for n←1 to n
3Do←n
4 直到每个簇的成员到聚类中心距离最小时停止循环
5 do for n←1 to n
6 do ωk←{}设置第n个簇为空集
7 for n←1 to N
8 计算空间点到中心距离
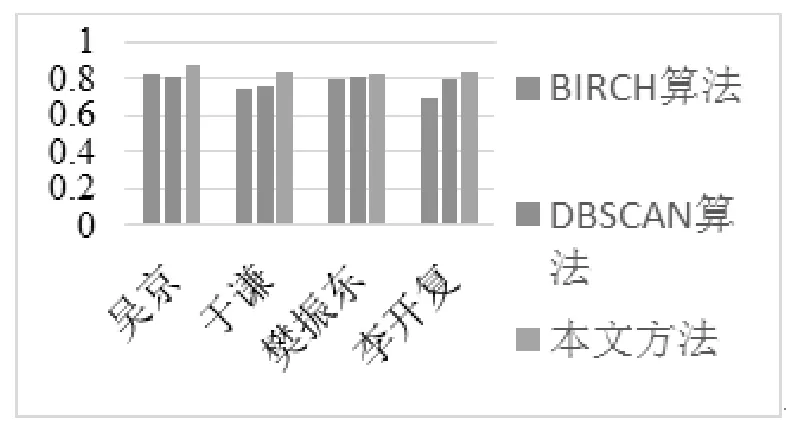
9 if(veci 10 归于此类 11 返回结果 新浪微博是近几年来新兴的即时网络分享平台,其用户数量庞大、内容复杂多样为本文提供了良好的数据来源。因此使用新浪微博作为测试数据很具有代表性。 本文采用python语言编写爬取程序,再根据微博爬取结果进行聚类。 实验节选自吴京,于谦,樊振东,李开复4人总计5000条左右的微博作为实验数据。本文采用对比实验来分析研究结果,分别采用BIRCH算法、DBSCAN算法进行对照。 实验使用F值度量,F值为准确率与召回率的调和平均值。 图3 对比实验 如图3所示,本文方法相比BIRCH聚类算法以及DBSCAN聚类算法有较为明显的提高,其中樊振东的个人微博信息按时间顺序排列较为整齐,因此三种聚类算法区别不明显。因此本文方法在个人微博时间线较为混乱时更加有效。 本文采用CBOW模型训练个人微博文本取得词语向量,句子由词语组成,将词语向量计算获得个人微博句子向量。个人微博向量可以视作空间中的一个点。根据曼哈顿距离计算个人微博相似度以此简化算法,计算完相似度之后,根据clarans聚类算法将个人微博聚类。实验结果表明,本文方法比传统聚类算法BIRCH聚类算法以及DBSCAN聚类算法有较为明显的提高。 研究工作的数据来源相对较少,聚类结果准确度依然有待提高;聚类数据量大时,会造成时间消耗量大的问题。因此找到精度以及时间消耗平衡是下一步研究的工作。 [1]赵世奇,刘挺,李生.一种基于主题的文本聚类方法[J].中文信息学报,2007,21(2):58-62. [2]刘群,李素建.基于《知网》的词汇语义相似度计算[C].第三届汉语词汇语义学研讨会.台北,2002:59-79. [3]王小林,王义.改进的基于知网的词语相似度算法[J].计算机应用,2011,31(11):3075-3077. [4]王小林,王东,杨思春,等.基于《知网》的词语语义相似度算法[J].计算机工程,2014,40(12):177-181. [5]Vesanto J,Alhoniemi E.Clustering of the self-orga-nizing map[J].IEEE Transactions on Neural Networks,2000,11(3):586-600. [6]Ding C H,He X.K-means clustering via principal component analysis[C].International conference on machine learning,2004. [7]Elhamifar E,Vidal R .Sparse Subspace Clustering:Algorithm,Theory,and Applications[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(11):2765-2781. [8]Vimalarani C,Subramanian R ,Sivanandam S N,et al.An Enhanced PSO-Based Clustering Energy Optimization Algorithm for Wireless Sensor Network[J].The Scientific World Journal,2016. [9]Zhang D,Chen S.Clustering Incomplete Data Using Kernel-Based Fuzzy C-means Algorithm[J].Neural Process-ing Letters,2003,18(3):155-162.4 实验

5 结束语
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
智富时代(2019年6期)2019-07-24 10:33:16
电子测试(2017年15期)2017-12-18 07:19:27
高中生·天天向上(2016年9期)2016-11-22 09:10:34
现代语文(2016年21期)2016-05-25 13:13:44
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
大连民族大学学报(2015年2期)2015-02-27 08:28:11
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
