
MFTL:一种基于固态盘系统非对齐更新数据的合并策略
2018-07-04 10:31黄耀钦邓玉辉
小型微型计算机系统 2018年6期
黄耀钦,邓玉辉,2
1(暨南大学 信息学院计算机科学系,广州 510632)
2(中国科学院 计算技术研究所 计算机体系结构国家重点实验室,北京100190)
1 引 言
相比于传统硬盘,基于闪存的固态盘(SSD)[1,2]由于其低延迟、低能耗、体积小和优良抗震性而被广泛应用于嵌入式产品和企业级服务器中.近年来,随着闪存芯片成本和价格的下降,固态盘的可用容量也越来越高,这使得固态盘成为传统机械硬盘[3]的有力替代者.同时,对于如何结合新型存储介质来充分挖掘存储系统的性能,文章[4]也相应提出了一种利用闪存来提升磁盘性能的存储架构.但是,基于闪存的固态盘也具有一些局限性,比如在写数据前必须先擦除而无法原地更新写;由于闪存芯片具有擦写次数限制,因此需要做磨损均衡处理使得数据能平均写到所有的块中.而这些地址转换映射、磨损均衡和垃圾回收等功能都由闪存转换层FTL[5-7]来完成.另一方面,固态盘内部通常都配备有缓存模块[8],用以存放闪存转换层映射表和相关的缓存数据,由于闪存的读写单位是以闪存页为最小单位,当写回至固态盘的缓存数据大小小于闪存页大小时,便会导致写回的数据与与实际写入的数据量不对齐,现有的FTL方案都没有针对这种非对齐写更新操作进行相应的优化,而这些非对齐的写更新操作会在一定程度上影响固态盘的性能.
缓存管理算法[9,10]是提高固态盘性能的有效方法.传统的缓存管理算法都是针对磁盘以提高缓存命中率为目的而设计的,文章[11]中的PASS算法可以通过存储更新率较高的更新数据来减少对闪存的访问次数,从而直接延长了固态盘的使用寿命及性能.然而,目前针对固态盘缓存的主要研究工作主要集中在如何利用闪存特性而尽可能地减少闪存写操作,而从实际应用中大多数负载的情况来看,多数真实负载在固态盘系统中都存在部分的非对齐写操作.对于这类非对齐的写操作,现有的缓存管理算法只是考虑如何选择写回的缓存数据而减少闪存写操作,而并未对非对齐的写更新进行相应的优化.对于非对齐写操作会有三个致命的缺陷.其一,由于闪存读写是以页为单位,因此写入的数据量与闪存芯片存储规格不对齐,造成了大量的物理可用存储容量的浪费;其二,若非对齐写操作存在更新操作的话,则固态盘需要从闪存芯片中将原有数据读取至缓存中,进行更新操作后再重新写回到闪存,这个过程会使得原本的写操作附加了额外的读取操作,造成了写请求处理的延迟从而影响固态盘的性能;其三,固态盘中的闪存转换层FTL会负责将上层传入的IO请求按照闪存页级的规格划分为多个相应的子请求并逐一处理,而这些子请求在处理的过程中,都不可避免的需要占用固态盘相应的资源,如通道、芯片等独立资源.同时,每一个子请求在处理的过程中都需要经过相应的阶段转换,例如对于每一个闪存写操作过程都会被分成三个部分:命令输入阶段、数据传输阶段和写入闪存介质阶段[11].所以无论写入的数据是否为整页对齐规格,最终整个数据处理过程都会划分成以上三个部分,因此通过对非对齐写数据进行相应的合并优化后可以减少这种写入过程的冗余次数.
针对固态盘存在的这些问题,本文提出了一种新的FTL设计方案MFTL.与其他FTL不同,MFTL重新设计了映射机制,可以将缓存中来自多个不同的逻辑数据块中存在的非对齐写数据合并成一个闪存页的规格大小后再整页写入到闪存中,读数据时则需要根据映射关系集合判断数据是否为合并页中的数据,如果是合并页中的数据就从相应的映射关系集中依次读取更新数据,并在缓存中进行合并;同时MFTL也对写更新现象进行的针对性地优化,对于写更新操作,MFTL不会直接附加一个额外的读操作进行更新后再写入到固态盘中,而是通过保存原页级映射模块中的有效映射关系,再通过更新合并页映射模块的映射信息,从而实现了省略额外读操作进行写更新的操作.针对这些合并后的更新数据进行一种自适应的动态更新调整,可以使得无效的更新数据自动从读取更新队列中剔除,保证了读取合并页数据时节省最多的更新冗余数据量.
本文的主要内容如下所述.在第二部分,我们介绍了固态盘存储系统中存在的非对齐数据存储的原理以及写更新操作所导致的额外读操作原理.第三部分是主要介绍MFTL架构的基本思想.第四部分我们则采用了SSDsim[12]作为固态盘的实验平台进行实验测试,测试具有MFTL的固态盘系统下的实验结果,并与原FTL的固态盘的实验结果进行比较,并分析实验数据.最后我们在第五部分结合实验结果给出结论.
2 背景知识
2.1 固态盘存储系统中的非对齐写数据
目前绝大多数固态盘都是以NAND FLASH[13]为存储介质的,因此其很多工作原理都是基于NAND FLASH特性的.NAND型的闪存芯片支持三种基本操作:读操作,写操作和擦除操作.其中读写操作都是以一个闪存页为最小操作单位,擦除操作则是以闪存块为最小操作单位.当数据块的大小大于闪存页的大小时,则必须先在固态盘系统中被处理分布成页对齐的规格的多个子数据块,再逐个写入到闪存阵列中.所以底层的闪存系统在处理负载的IO请求时,都会先将每一个IO请求按照逻辑地址对齐的规格分布成多个以页为单位的子请求,并逐一挂接到相应的处理队列上由闪存控制器处理.因此上述的这些工作原理就造成了固态盘内部在实际应用中存在非对齐的数据存储.对于提供有缓存模块的固态盘,传统的缓存管理会在缓存写数据时将所有写请求的写数据优先写入到缓存中,当后续的写数据持续写入时,若当前缓存无空闲空间时则会从当前的缓存数据节点队列中选择合适的节点写回至闪存.前面也提及,缓存系统可以大大提高固态盘的整体性能.然而,由于基于页级规格的写入数据可能存在非对齐的数据量规格,因此在写入闪存时便会造成非对齐的写入.

图1 固态盘系统中非对齐缓存数据的存储分布图Fig.1 Memory allocation of non-aligned cache data in solid-state disk
图1是缓存中非对齐的写数据写回闪存阵列时的例子.我们假定每个闪存页的规格为2KB,并从真实负载中截取其中的一小段IO请求,图中缓存模块中8个缓存数据节点描述的便是取自于真实负载中数据在缓存中的存储情况,我们假设在没有任何优化策略和没有发生更新的前提下,经过闪存转换层FTL直接分布处理后写入到固态盘内部的非对齐数据存储情况.如图中所示,当缓存中的数据节点依次写回至固态盘后,若是写回数据量小于2KB大小的数据,按页对齐写入后在固态盘内部的存储情况会造成每一个闪存页剩余可用存储空间的浪费.由于非对齐写入后造成的物理空间耗费,因此在非对齐写入后势必会造成固态盘内部大量可用存储空间的浪费.
2.2 非对齐导致的额外读操作
在固态盘系统中,非对齐数据还可能会带来写更新的问题,写更新现象会导致一个写请求产生额外附加的闪存读操作.当缓存中的写数据产生写回请求需要写回至闪存阵列中时,若该缓存数据节点为非对齐格式的写数据时,则需要根据闪存转换层来判断是否需要执行写更新.此时需要分为两种情况进行处理:如果写回的有效数据可以直接覆盖原物理页的数据则不需要执行写更新,此时可以直接通过映射机制将原物理页的数据置为无效,然后将写回数据直接写入至固态盘中.否则由于非对齐的更新数据无法直接写入闪存,因此闪存的处理方式是首先从固态盘闪存阵列中读取原物理页的有效数据至内存中,与非对齐更新数据合并更新后再重新写回闪存阵列中.因此这个过程是附加了一个读操作,写更新操作必须要等读操作完成后,才能继续将数据写入至固态盘中.如图2所示,我们假定每一个扇区大小为512Byte,闪存物理页容量为2KB.图示中当写回的是该逻辑页中第二个扇区数据时,由于固态盘中逻辑页对应的原物理页数据有第三个扇区的有效数据,因此必须先从固态盘对应的物理页中读取该有效数据,随后合并更新为整页后,再写入固态盘.整个更新过程分为一次读过程和一次写过程.
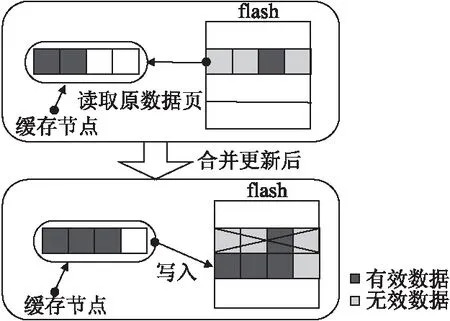
图2 固态盘非对齐写更新的处理过程Fig.2 Processing of non-aligned write update operation on solid-state disk
3 MFTL系统设计
3.1 核心思想
本文提出的MFTL可以将固态盘缓存中来自不同逻辑数据页中的非对齐写数据通过合并后写入至闪存中,由于这个合并写入过程中,同一个物理闪存页中的数据可能来自于多个不同的逻辑页,因此需要重新设计地址映射关系.在设计过程中,我们基于页级映射的地址映射机制进行设计,页级地址映射具有最小的映射粒度,映射的基本单位是物理页.传统的页级映射是一对一的映射关系,也就是每一个逻辑页都可以基于这种映射关系一一对应到闪存中唯一的一个物理页.由于具备最小的映射粒度,因此其寻址能力和性能也是最好的.
3.2 MFTL系统架构设计
图3是MFTL的系统架构图,在MFTL中,主要由映射模块、缓存模块、合并缓冲区及固态盘存储的闪存阵列构成.其中,映射模块分为页级映射表和合并页映射表,页级映射表即是一对一的逻辑页到物理页的映射,合并页映射表则是用来记录已经合并写入过的逻辑页的更新子数据与对应闪存物理页的映射关系集.缓存模块则是所有缓存数据节点的存储区域,合并缓冲区则是其中的一个页级规格大小的缓存空间,用来将多个逻辑页的非对齐数据合并后写入至该区域,而后通过MFTL写回至闪存阵列中.

图3 MFTL系统架构图Fig.3 System architecture diagram of MFTL
在MFTL中,对于系统上层发布至固态盘的所有IO请求,首先通过缓存模块判断是否命中.由于MFTL主要针对写操作进行优化,因此当通过判断模块判定该请求项为写操作类型时,因为在MFTL系统中缓存模块是优先为写请求服务,所有的写请求都会先写入到缓存区域中,而后根据缓存空闲空间的大小动态地执行缓存LRU队尾数据节点的写回操作.因此主要的写操作是发生在缓存节点写回固态盘的过程,由于在MFTL系统中,对于缓存模块中的所有缓存节点数据,都按照对齐数据与非对齐数据进行分类划分,因此相应会有两个缓存数据区域,而对于合并写过程中缓存替换的策略,缓存替换的时间设定在于当前非对齐缓存节点是否能满足写回的触发条件,对于非对齐数据比例较大的缓存,那么此时会达到很好的合并效果,而反之对于非对齐数据比例较小的缓存则有较好的持久性.并且在缓存管理的过程中,非对齐数据有可能会随着后续的IO请求操作而重新从非对齐数据区域置换至对齐数据区域,因此整个缓存的管理过程是比较动态化的.如图4所示,MFTL首先也是通过映射模块判断是否需要执行合并写操作:对于写回节点是对齐的写操作的情况,那么MFTL会进行相应的判断:如果写回的逻辑页之前发生过合并写操作,那么MFTL就需要重新刷新合并页映射模块中与该逻辑页相关的映射信息;否则的话,MFTL会直接执行写回操作.而如果是非对齐的写操作,则需要进行合并写,同时MFTL会判断该写回操作是否有发生写更新,根据是否产生写更新操作,MFTL会做出两种处理方式:一种是无写更新时,MFTL会直接从缓存区域中继续筛选出另一个合适的合并节点,并与之前的写回节点合并,同时更新合并页映射模块的相关信息.另一种是发生写更新时,MFTL会先从页级映射模块中保存该逻辑页的有效映射信息,然后再进行合并写回,并同时更新合并页映射模块的相关信息.
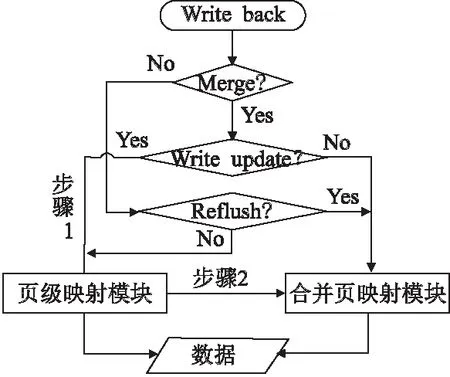
图4 写操作处理流程图Fig.4 Write operation flow chart
3.3 MFTL映射模块
MFTL的映射模块架构由页级映射模块与合并页映射模块组成.页级映射模块存放的是未发生合并写操作的对齐数据与相应的映射关系集,合并页映射模块存放的则是已经发生过合并写的非对齐数据与其相应的映射关系集.在MFTL系统中,当发生多个非对齐更新数据的合并操作时,会将合并页缓存区按照sector(512字节)的粒度将多个非对齐更新数据存储至合并页缓存中,对于不足一个sector的非对齐更新数据则默认按照一个sector的规格进行存储.对于缓存中的非对齐请求数据比较大的情况,MFTL会按照闪存页大小规格的划分粒度将较大的数据切割成多个子数据,这些子数据中对齐数据将会被缓存至对齐缓存区域中,而非对齐的子数据则被缓存至非对齐缓存区域.另外,当发生同一数据块的多次非对齐更新时,合并页映射模块将会不断添加新的相应索引表项,图5 是合并页表项的结构,每一个合并页表项由多个逻辑页号与对应的位图索引,表示在该合并页结构中占据的sector区域.

图5 合并映射表页表项Fig.5 Merge map table page entry
而对于非对齐更新数据合并策略的研究,文章[14]利用了紧凑合并的方式对多个非对齐更新数据进行合并操作,对存储空间的利用率是最高的.而本文针对非对齐数据的合并策略是首先将多个非对齐数据按照sector(512 byte)的划分粒度存放至同个闪存页区域中,在这个存放的过程中,对于不足sector的数据则默认按照以sector的规格存放,因此多个非对齐数据存储之间并不是完全紧凑的存放,如图6所示,其中具有来自多个逻辑页的多个非对齐更新数据,这种合并策略可以减少映射索引的复杂度.
3.4 针对写更新的合并优化
MFTL系统针对固态盘中存在的写更新现象做出了相应的优化.当发生写更新时,由于对应的非对齐写操作的合并写入,MFTL并不会直接先从原物理页中读取数据,而是通过合并写入后,通过保存原页级映射表的信息,而直接忽略这部分额外读操作过程.因此在MFTL中,对于非对齐的读操作而言,又会有两种情况出现:

图6 非对齐更新数据合并方式Fig.6 Non-aligned update data merge mode
1.如果合并页中的数据是发生过写更新时,则MFTL会根据映射表中原物理页获取得到的源数据页信息,随后根据合并页映射表的信息获取到相应的读取队列,而后逐一从各个闪存页中读取数据.当发生一个写更新合并页的读取操作时,MFTL首先会先根据页级映射模块从固态盘中读取原数据页,随后根据合并页映射表中获取相应的合并页数据,对这些数据进行合并后返回需要读取的数据.
2.若合并页中的数据并未发生写更新时,那么读取的过程会忽略原物理页中的数据,即此刻页级映射模块中有关该逻辑数据页的映射是失效的,此时MFTL会直接根据合并页映射表从固态盘中读取一个或多个相应的数据,在缓存中进行合并后返回读操作所需的数据.
4 实验评估和分析
4.1 实验环境
为了验证本文提出的MFTL优化方法的有效性,我们的实验在SSDsim[12]系统上进行相关的实验测试,并在SSDsim系统中构建本文所提出的MFTL架构.SSDsim是一个遵循ONFI协议的开源固态盘模拟系统,具有高准确性、模块化、可配置的优点,并且同时也通过相关实验验证了其有效性.我们在其架构基础上加入了合并页更新映射模块及相关的缓存管理模块等功能,并对比原系统中FTL和本文所提MFTL在不同负载中性能上的表现.
本文实验基于SSDsim模拟了一块较新的SSD固态盘,型号为浦科特M6S Plus.该固态盘容量为256GB,配置有256MB的海力士H5TC2G63FFR.主控芯片采用Marvell 88SS9188的4通道主控,闪存颗粒采用东芝A15nm MLC颗粒,64Gbit Die,每颗内部封装8个Die,内部4CE,组成32GB容量,4个颗粒组成128GB容量,4KB的Page,16MB的Block,2个分组plane.
4.2 实际负载数据集中的非对齐数据存储
我们所采用的数据集是来自微软剑桥研究院[15,16]提供的负载数据集,这些负载数据均采集于真实的服务器磁盘中,每一个trace请求的信息包括了:时间戳,服务器名,磁盘号,读/写类型,逻辑块开始地址,操作数据大小,响应时间等.为了便于SSDsim进行模拟实验,我们对其中的数据集进行了格式的转换处理,只取每一条trace数据中的开始处理时间戳、逻辑块开始地址、操作数据长度和操作类型这四种关键的参数.由于全部的数据集过大,因此我们只选取了其中4段数据集进行实验.
根据存储系统的局部性原理,同一个逻辑数据块在短时间内很可能会被反复访问操作,这就对缓存系统提出相当严峻的要求.而目前的缓存策略针对非对齐数据时,并没有根据固态盘系统存储的特殊性进行相应的优化.而大多数实际负载中的确存在相当部分的非对齐数据.Zhang[17]等人通过对几个典型的随机负载分析后发现有接近90%的逻辑块会有多次非对齐更新的操作.D.Campello[18]等人的研究显示,实际上超过60%的写操作都会有非对齐的更新操作,并且其中更新的长度不超过10个字节大小.
为了进一步验证实际负载中存在的非对齐写数据对实际固态盘的影响,我们对上述微软-剑桥研究院提供的4个企业级负载进行测试.由于我们的实验主要针对非对齐写操作进行优化,因此当一个IO请求被FTL分布成一个或多个写子请求到固态盘中处理时,若该子请求的操作长度小于一个闪存页的大小,则定义为一个非对齐写操作.同时,由于部分非对齐写请求在进行更新操作时会导致写更新的现象,因此通常来说若非对齐写操作发生写更新时,则需要额外附加一个读请求操作.我们测试的实验平台选取了SSDsim固态盘系统,在Ubuntu系统(内核版本为4.4.0)中进行实验测试,并且同时模拟前面所提出的浦科特M6S Plus固态盘硬件配置.表1是4个负载数据集的相关测试信息,为了保证实验数据的可靠性,我们对这4个数据集的所有写数据进行统计,其中No.of program是代表每个数据集中固态盘的实际写入次数,每一个program操作都是对固态盘内部的一个物理闪存页进行一个写入操作.No.of noalign即表示写子请求中操作长度小于4KB的数量,也就是非对齐写操作的数量.Read.of wirteupdate代表其中由于非对齐更新操作所带来的额外读操作数量.Avg.write size则代表写请求操作的平均长度,单位是扇区512Byte.

表1 数据集信息Table 1 Information of data sets
我们同时也对数据集中的所有非对齐写操作进行了一个存储分布情况的统计.图7是固态盘系统中非对齐数据的存储情况分布图,其中其他非对齐写操作指的是所有非对齐写操作中未发生写更新的那部分写操作,而非对齐写更新操作代表发生过写更新操作的那部分写操作.经测试后发现在每个数据集中都存在部分非对齐写操作,而这些非对齐写操作中还包含了相当部分写更新操作导致的额外读操作.比如在图7负载sm0和sm1中,分别存在占比接近13%和16.9%的写更新操作.

图7 数据集中非对齐写数据的存储分布图Fig.7 Storage distribution of non-aligned write data in data set
从上述的实验测试数据可以看出,在实际的数据集中都或多或少存在非对齐写操作,这部分操作会由于固态盘的特殊存储性质导致大量的可用存储空间的浪费,同时其中写更新操作导致的额外读操作会延迟写操作的处理过程.这也说明了MFTL针对这部分非对齐写操作优化的必要性.
4.3 实验结果分析
为了更好的评估MFTL的优化性能,我们通过实现SSDsim原来的FTL与整改后的MFTL同一实验环境下进行测试对比.
4.3.1 MFTL在不同数据集下的写性能测试
图8(a)中给出的分别是测试的4个数据集在FTL和MFTL的SSDsim上得到的固态盘写入次数.从图中我们可以看出各个数据集在MFTL中测试的写入次数结果都要比FTL低,平均优化的写入次数为198298次.由于实验所测试的数据集IO请求数量过于庞大,因此我们可以看出,在图中最明显的优化出现在hm1数据集中,此时MFTL比FTL降低了317039次写入次数,主要的原因是在hm1中非对齐写操作的比例较大,具有接近72.1%的非对齐写操作,这些非对齐写操作在MFTL中当缓存满足合并页写回时会被处理,因此我们可以看出在非对齐写操作比例较大的数据集中,当缓存中有足够的非对齐数据时合并的效果会更好.从前面数据集的特征可以看出,在这两个数据集这部分非对齐写操作之中有超过65%的部分是写更新操作,这部分操作会额外导致附加的读操作请求.为了测试MFTL在优化写更新操作方面的效果,我们需要对这4个数据集中的写更新操作进行一个写更新操作的测试.
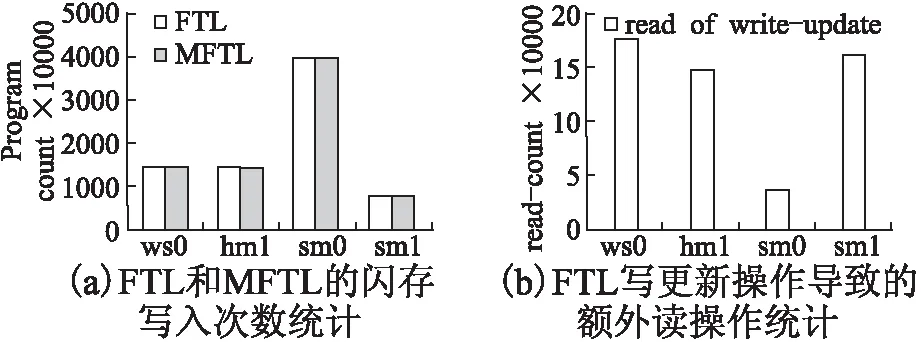
图8 两种FTL在各个数据集下的写性能比较Fig.8 Comparison of performance of two kinds of FTL in data sets
如图8(b)所示,在原FTL系统中,每一个测试的数据集中都存在相当数量的写更新导致的额外读操作,而在MFTL的SSDsim系统中,这部分额外的读操作全部都会被优化处理,直接省略了100%的写更新额外读操作,主要原因是当发生写更新操作导致的额外读操作请求时,MFTL将不会产生附加的读请求操作,而是通过保存原页级映射表中相关的映射信息,同时继续执行合并写回操作,并且更新合并页映射表中新的非对齐子页数据的映射关系,此时整个逻辑数据页的有效数据将会被划分成主要的两个部分,一部分是需要通过原页级映射表获取的数据,另一部分则是要通过合并页映射表获取的非对齐更新数据.因此通过这种优化策略,MFTL可以省略所有的写更新额外读操作,由于在固态盘中,写更新操作需要等对应的额外读操作完成后才能继续执行写操作,因此MFTL针对这种额外读操作的优化可以直接提高固态盘处理写操作的整体反应时间.因此在后续的实验中我们也对写操作的整体反应时间进行一个测试,来验证这个优化过程.
4.3.2 不同数据集规模下MFTL的读写性能测试
为了获取可信度更高的实验数据结果,我们在SSDsim系统上测试在同一个数据集中不同操作规模的数据集对非对齐写操作的影响.由于文章篇幅所限,因此我们只选取3个数据集进行一个分段测试,并且将同一个数据集划分成具有不同规模大小的多个数据集进行一个分段测试.比如数据集hm1中总共约有1200万条IO请求,我们将其按照IO请求数量划分为8个数据集,其中每一段数据集都是属于hm1的数据子集,且从第一个数据集开始IO请求数量为150万,第二个为300万,第三个为450万,以此类推.为了验证在非对齐更新比重较大的数据集中MFTL对写性能的优化,我们也对写请求处理的平均反应时间进行一个分段测试,我们定义每一个写请求被处理的时间为Twi(其中i表示第i个写请求),则特定负载下固态盘写请求处理的平均反应时间为

图9(a)给出的是不同数据规模数据集中两种FTL固态盘系统写入次数的情况,我们可以看出基本在具有非对齐更新数据的数据集中,相比于FLT,MFTL可以有效减少固态盘的实际写入次数,从而充分延长了固态盘的使用寿命.原因在于在这些数据集中,对于一些非对齐更新数据,MFTL可以通过合并写回时有效减少写入次数.
图9(b) 是关于写请求处理的平均反应时间,我们可以看出在持续写入数据量后,总体上MFTL的写请求处理时间均低于FTL.原因是MFTL系统中针对非对齐写操作中的写更新操作做了优化,对于写更新操作所带来的额外读操作请求,MFTL通过映射模块的设计直接优化了这部分额外读操作;另外,对于非对齐数据更新比重较大的场景中,MFTL系统通过合并这些非对齐数据,可以减少固态盘底层系统对每个非对齐写操作的处理,从而降低了整体的写请求处理时间.

图9 两种FTL在不同规模数据集下的写性能测试Fig.9 Performance test of two kinds of FTL in different scale data set

图10 两种FTL在不同数据集下的读性能测试Fig.10 Two FTL read performance tests under different data sets

实验结果如图10所示.我们可以看到,整体上相比于FTL,MFTL系统会有额外的读开销损耗,导致这部分额外读开销的原因在于有部分的逻辑块数据曾被多次合并写入,因此当发生这部分逻辑块的读取操作时,MFTL需要从页级映射表和合并页映射表中分别读取该逻辑块的多个合并页数据,通过重组合并后得到相应的数据.因此在发生合并页中的逻辑块数据读取操作时,会额外产生多个读操作请求,因此MFTL系统中会有这部分额外的读取开销.从实验结果我们可以看到,相比于写性能的提升,这部分额外的读性能损耗是在可接受范围内的.
5 结 论
本文提出了一种MFTL的固态盘闪存转换层方案来对非对齐写操作进行合并优化,并针对固态盘中由非对齐写操作引发的写更新额外读操作进行了优化,MFTL可以通过直接省略额外读操作,提高了固态盘的写性能,合并优化功能模块则充分减少了固态盘的写入次数,延长了固态盘的使用寿命.
通过实验结果也证明了MFTL相对FTL在固态盘写入次数上可以减少最多28.6%的非对齐写操作,写请求操作平均反应时间最多减少了24.57%,并可以充分利用映射机制直接避免非对齐写更新操作所导致的额外读操作开销.实验表明,MFTL可以适合不同的数据集,与FTL系统相比,对于具有非对齐更新数据的数据集中,MFTL具有更好的写性能,通过减少固态盘写入次数,间接扩大了固态盘的可用存储容量,延长了固态盘的使用寿命.
:
[1] Deng Y,Zhou J.Architectures and optimization methods of flash memory based storage systems[J].Journal of Systems Architecture,2011,57(2):214-227.
[2] Lu You-you,Shu Ji-wu.Survey on flash-based storage systems[J].Journal of Computer Research & Development,2013,50(1):49-59.
[3] Deng Y.What is the future of disk drives,death or rebirth?[J].Acm Computing Surveys,2011,43(3):1-27.
[4] Deng Y,Wang F,Helian N.EED:energy efficient disk drive architecture[J].Information Sciences,2008,178(22):4403-4417.
[5] Shin J Y,Xia Z L,Xu N Y,et al.FTL design exploration in reconfigurable high-performance SSD for server applications[C].International Conference on Supercomputing,Yorktown Heights,Ny,Usa,2009:338-349.
[6] Shin J Y,Xia Z L,Xu N Y,et al.FTL design exploration in reconfigurable high-performance SSD for server applications[C].International Conference on Supercomputing,Yorktown Heights,Ny,Usa,June,2009:338-349.
[7] Chung T S,Park D J,Park S,et al.A survey of flash translation layer[J].Journal of Systems Architecture,2009,55(5-6):332-343.
[8] He D,Wang F,Feng D,et al.2QW-clock:an efficient SSD buffer management algorithm[C].IEEE,International Conference on High Performance Computing,IEEE,2015:47-53.
[9] Megiddo N,Modha D S.ARC:a self-tuning,low overhead replacement cache[C].Usenix Conference on File and Storage Technologies,USENIX Association,2003.
[10] Hu Y,Jiang H,Feng D,et al.PASS:a proactive and adaptive SSD buffer scheme for data-intensive workloads[C].IEEE International Conference on Networking,Architecture and Storage,IEEE,2015:54-63.
[11] Open NAND flash interface specificarion[EB/OL].http://onfi.org/wp-content/uploads/,2017.
[12] Hu Y,Jiang H,Feng D,et al.Performance impact and interplay of SSD parallelism through advanced commands,allocation strategy and data granularity[C].International Conference on Supercomputing,ACM,2011:96-107.
[13] Kang J U,Jo H,Kim J S,et al.A superblock-based flash translation layer for NAND flash memory[C].ACM & IEEE International Conference on Embedded Software,EMSOFT,Seoul,Korea,2006:161-170.
[14] Lu You-you,Shu J,Zheng W.Extending the lifetime of flash-based storage through reducing write amplification from file systems[C].Usenix Conference on File and Storage Technologies USENIX Association,2013:257-270.
[15] Chan J C W,Ding Q,Lee P P C,et al.Parity logging with reserved space:towards efficient updates and recovery in erasure-coded clustered storage[C].Usenix Conference on File and Storage Technologies,2014:163-176.
[16] Narayanan D,Donnelly A,Rowstron A.Write OFF-loading:practical power management for enterprise storage[C].Usenix Conference on File and Storage Technologies,2008:256-267.
[17] Zhang X,Li J,Wang H,et al.Reducing solid-state storage device write stress through opportunistic in-place delta compression[C].Usenix Conference on File and Storage Technologies USENIX Association,2016:111-124.
[18] Campello D,Lopez H,Koller R,et al.Non-blocking writes to files[C].Uesnix Conference on File and Storage Technologies,USENIX Association,2015:151-165.
附中文参考文献:
[2] 陆游游,舒继武.闪存存储系统综述[J].计算机研究与发展,2013,50(1):49-59.
猜你喜欢
法律方法(2022年2期)2022-10-20
今日农业(2022年14期)2022-09-15
消费电子(2022年6期)2022-08-25
核安全(2022年2期)2022-05-05
中学生百科·大语文(2021年11期)2021-12-05
纺织科学研究(2021年7期)2021-08-14
纺织科技进展(2021年5期)2021-07-22
陶瓷学报(2021年1期)2021-04-13
陶瓷学报(2021年1期)2021-04-13
家庭影院技术(2019年8期)2019-08-27
