
结合类别与语义贡献度的特征权重计算方法
2018-06-19 13:11王李福何养明
计算机工程与设计 2018年6期
王 勇,王李福,邹 辉,何养明
(重庆理工大学 计算机科学与工程学院,重庆 400054)
0 引 言
在进行文本处理时,目前应用最广泛的文本表示方法是由Salton等[1]提出的向量空间模型,但是该模型在计算特征项权重时假设特征项之间相互独立,没有任何关联,是一种纯统计的表示方法。事实上,在特征项之间存在一定的语义相关性,应将特征项的语义关系引入到文本表示中[2]。另外该方法在计算tfi和idfi时未考虑特征项在不同类别的分布情况对权重的影响[3]。
针对文本处理实际应用中,各文本没有明确的类别信息以及基于传统向量空间模型的TF-IDF方法在计算特征项权重时缺乏语义关系和类别区分度的问题,姚海英[4]提出了一种基于类内信息熵和特征项频度的卡方统计方法ICHI,该方法引入了类内信息熵和特征项频度两个因子,对特征权重计算忽略低频词以及内部分布情况对权重的影响的不足进行了优化。李明涛等[5]提出了结合TF-IDF与基于WordNet的词义相似度的权重计算方法,该方法优化了权重计算时忽略特征语义相似关系影响的问题,但是该方法未考虑特征项类别分布对权重计算的影响。李学明等[6]为提高特征权重准确度,提出了一种基于信息增益与信息熵的TF-IDF计算方法。陶舒怡等[7]利用词项之间的语义关系,通过计算新增文本与已知类别簇的相关性实现聚类。翟东海等[8]通过计算平均语义相似度获得特征词和报道之间的关联度,但是该方法未考虑特征词在不同类别的分布对关联度的影响。
以上都是在知道文本集合中文本所属类别的前提下计算特征项权重,但是在文本处理实际应用中事先没有提供分类的参考模式,不知道文本属于哪一类。而模糊聚类可以得到文本属于各个类别的不确定性程度,建立起了文本对于类别的不确定性程度的描述,能够客观反映文本的类别信息。因此为先获取含有类别信息的文本,采用了模糊聚类[9]的方法,然后提出了类别信息熵,结合语义贡献度,对特征权重计算方法进行了改进。
1 改进的TF-IDF权重计算方法
模糊集相关定义及定理参见文献[9],由模糊集定义及定理可知,任意一个模糊相似矩阵可以经过处理得到一个模糊等价矩阵。因为在采用模糊聚类分析时,需要找到论域中各元素的等价关系,但是它们通常不是等价关系。因此需要将标准化后的数据处理成模糊相似矩阵,然后将模糊相似矩阵处理成模糊等价矩阵,最后进行聚类得到聚类簇。模糊聚类的步骤参见文献[10]。
在文本处理前,获得文本数据集合的类别信息可以提高文本表示的准确程度;同时考虑到特征项语义关系对特征项权重计算造成的影响,本文提出了一种有效的特征权重计算方法。
1.1 类别信息的获取
一篇文本通过向量空间模型表示,并且一篇文本表示一个概念,因此组成向量空间模型的各个特征项就共同表示了该篇文本。针对文本的概念受到各个特征项之间语义关系影响的问题,提出了一种语义贡献度的特征词权重计算方法。
在计算语义贡献度的过程中需要知道两个词语之间的相似度,由于一个词语通常表达了很多意思,也即有多个义项,因此在进行特征项相似度计算时需要考虑所有的义项,本文在计算特征词之间相似度时采用文献[11]的方法。
在向量空间模型中的m(本文m取10)个特征词之间计算相似度,用m阶方阵表示它们之间的相似度,如下所示
(1)
对称矩阵Sm×m的行、列数为特征词的个数m,第i和j个特征项之间的相似度用sij表示。如果一个特征项的语义由该特征项和其余特征项相似程度关系的集合组成,则该特征项与其余特征项的语义关系为它在语义上所做出的贡献。
本文提出了一种语义贡献度的计算方式
(2)
其中,φ(ti)为特征项ti的语义贡献权重因子。
为了得到含有类别信息的文本集合,在数据标准化过程中各个元素的权重按照式(3)计算
wi=TF×IDF×φ(ti)
(3)
其中,wi为特征项i的特征权重。
采用文献[9]中第2.5节的模糊聚类方法,就能够得到带类别信息的文本数据集合。
1.2 改进的权重计算
由于在采用TF-IDF方法计算向量空间模型中特征项权重的IDF时未考虑特征项在类别之间的分布情况。如果所计算的特征项集中出现在某一个类别中,则计算出来的IDF值可以代表该类别,但是当该特征项在不同类别中均匀分布,并且出现的该特征项次数和相同时,得到的IDF值也与集中分布的值相同,显然不能代表该类别。因此在权重计算时应当考虑特征词在不同类别中的分布情况,增加集中分布特征词的权重,降低没有集中分布特征词的权重。
信息熵表示能量在空间中分布的均匀程度[12]。根据其定义,信息熵可以用来描述特征项在不同类别之间的分布情况。因此应当降低分布在不同类别的特征项即信息熵较大的特征项权重,提高分布在同一类别的特征项即信息熵较小的特征项权重。因此提出了一种IDF权重调节系数的计算方法
(4)
其中,Tj表示是否在第j篇文档中出现特征词ti,如果不出现为0,出现为1;NCi表示在类别Ci中出现特征词ti的文本数;N表示文档总数;k表示类别总数。
改进后的特征项权重计算公式如下所示
1.3 改进的特征权重计算方法流程
改进的特征权重计算方法的流程具体如下:
(1)将原文档分词、去停用词处理;
(2)计算各特征项的TF-IDF值,将得到的值从高到低排序;
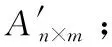
(4)经平移标准差变换将数据标准化,再根据建立模糊相似矩阵的步骤将矩阵变成模糊相似矩阵Rs,将得到的模糊相似矩阵采用平方自合成法得到模糊等价矩阵Re;
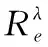
(6)据式(4)计算ti的I(ti);
(7)据式(5)计算ti的权重值;
(8)重复(6)、(7)计算文本向量空间模型中各个特征项新权重。
2 实验结果及分析
文本采用包括环境(200)、计算机(200)、经济(325)、交通(214)、艺术(248)、军事(249)、政治(505)、教育(220)、体育(450)、医药(204)这10个类别文档的复旦大学中文文本分类语料库数据集进行测试。本文在4个类别中分别选取20篇文档作为测试数据集,分别是医药、计算机、艺术、经济。实验采用聚类效果通用测试指标准确率(9)和召回率(10)进行评价。准确率和召回率计算方法如下所示
Precision=TP/(TP+FP)
(6)
Recall=TP/(TP+FN)
(7)
其中,FN为同一类的样本点被分到不同类别的样本点个数;TP为同一个类别的样本点被分配到同一个类簇的样本点个数;FP为不同类别的样本点被分配到同一个类簇的样本点个数。
(1)考虑语义关系与不考虑语义关系的模糊聚类的实验效果对比,实验结果见表1。
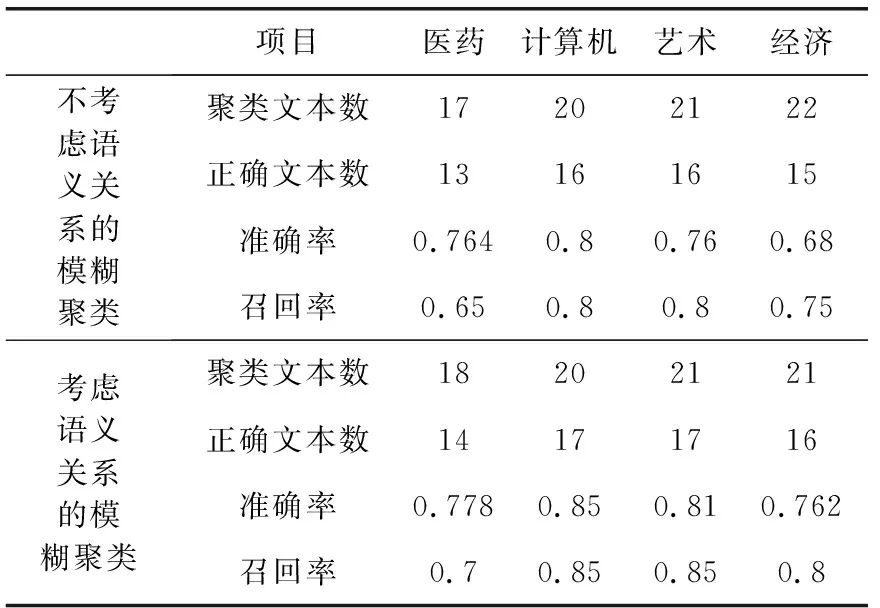
表1 语义贡献度的模糊聚类实验对比
为增加实验效果的直观性,采用折线图方式呈现实验结果,如图1所示。
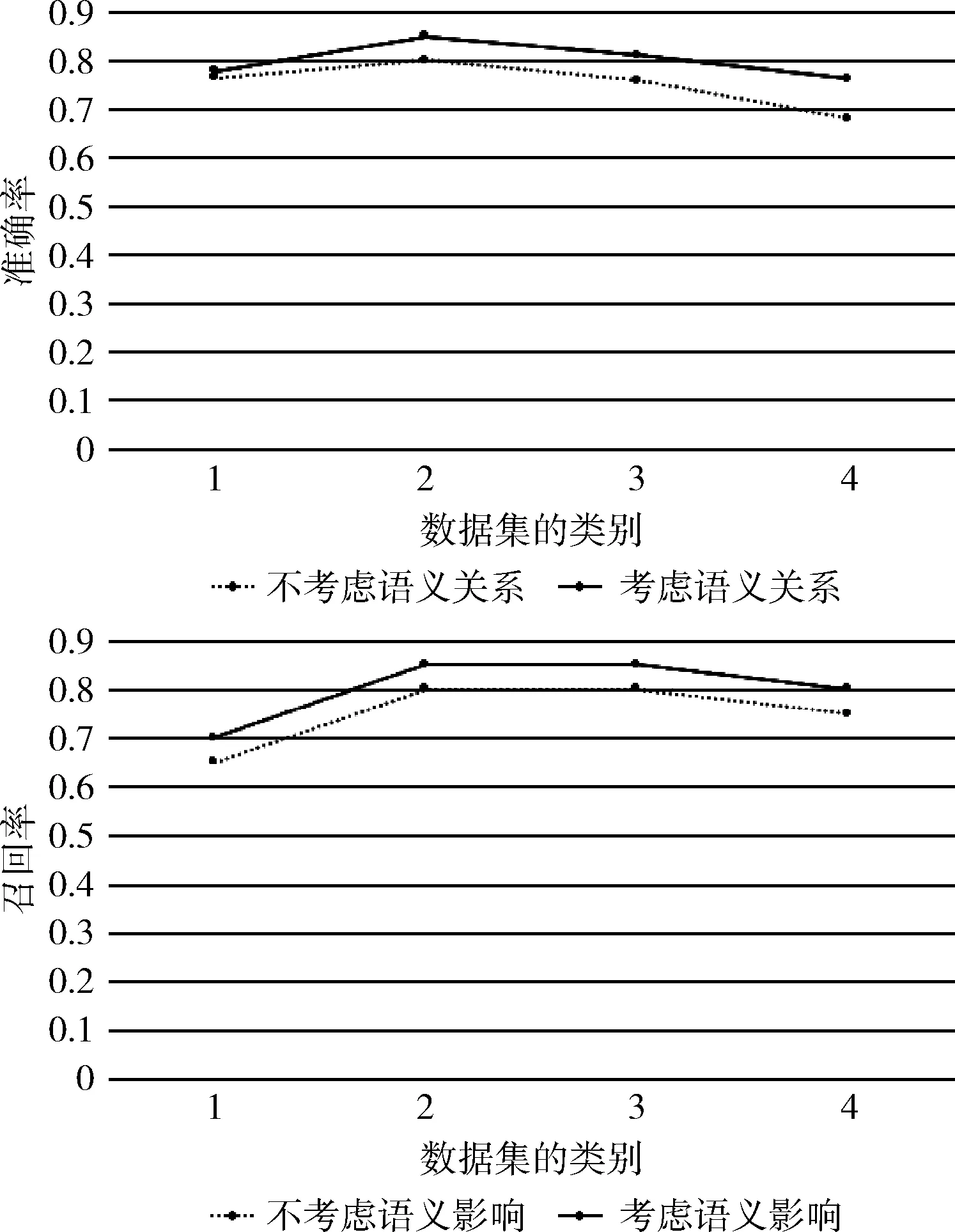
图1 语义贡献度的模糊聚类实验对比
医药、计算机、艺术、经济分别用1、2、3、4表示。实验结果表明,考虑特征项的语义贡献度实验效果更好。
(2)将得到的含有类别信息的文本集合用新的特征项权重计算方法得到每篇文档的向量空间模型,采用经典的K-means算法测试算法类别影响的改进效果。类别对特征项权重影响的实验结果见表2。
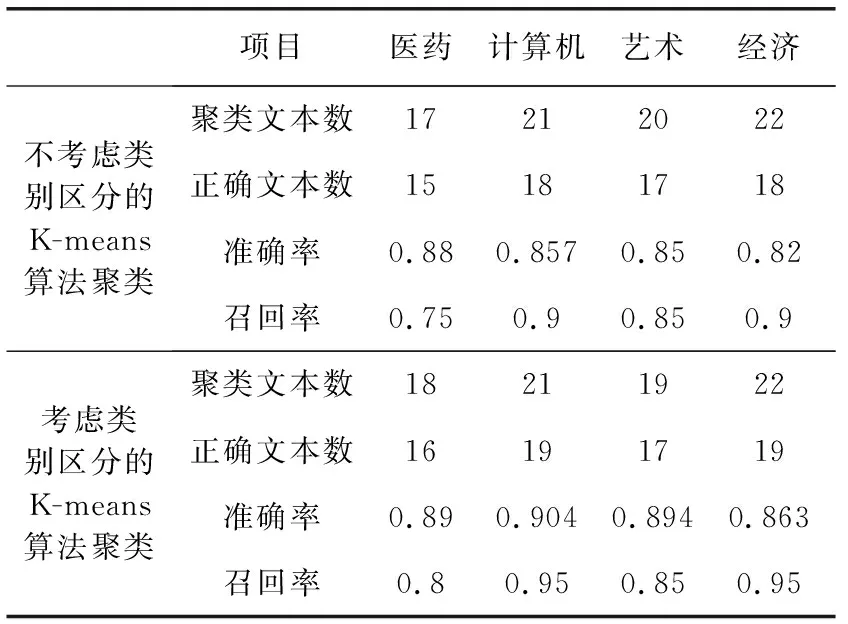
表2 采用K-means聚类算法测试类别区分实验对比
为增加实验效果的直观性,采用折线图的方式呈现实验结果,如图2所示。
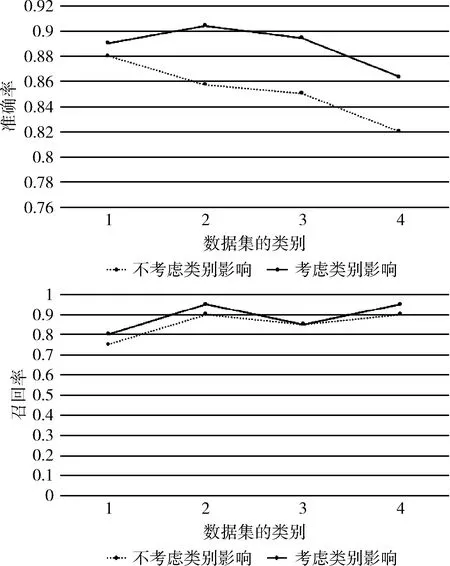
图2 采用K-means聚类算法测试类别区分实验对比
医药、计算机、艺术、经济分别用1、2、3、4表示。实验结果表明,考虑特征项在类别之间的分布情况时效果更好。
3 结束语
本文针对文本聚类实际应用中大量文本类别信息未知,并且基于向量空间模型的TF-IDF方法进行特征项权重计算只考虑统计信息而不考虑特征项在类别分布对权重影响的问题,提出了一种结合类别信息熵和语义贡献度的特征权重计算方法。该方法在计算向量空间模型中的特征项权重时不仅仅考虑了统计信息,特征项之间的语义关系对文本表示的影响同样作为考虑的因素,因此提出了文本表示的特征项语义贡献度的方法,结合模糊聚类得到文本的类别信息;在得到类别信息后,根据特征项在不同类别的分布情况,提出了类别信息熵的方法,对特征项权重的计算进行优化。实验结果表明,该方法是有效的。
在后续的研究中,将在如何得到更加合理的特征项个数m,能否找到一个合理的取值模型而不是靠人为给定的方面重点考虑;此外特征项在文本中的词性以及出现的位置对权重计算的影响也将纳入考虑,得到更加合理的权重计算方法。
参考文献:
[1]Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the Acm,1975,18(11):613-620.
[2]ZHU Jianlin,YANG Xiaoping,PENG Jingqiao.Research on effect of adding internal semantic relationship into text categorization[J].Computer Science,2016,43(9):82-86(in Chinese).[朱建林,杨小平,彭鲸桥.融入内部语义关系对文本分类的影响研究[J].计算机科学,2016,43(9):82-86.]
[3]ZHANG Yufang,WAN Binhou,XIONG Zhongyang.Research on feature dimension reduction in text classification[J].Application Research of Computers,2012,29(7):2541-2543(in Chinese).[张玉芳,万斌候,熊忠阳.文本分类中的特征降维方法研究[J].计算机应用研究,2012,29(7):2541-2543.]
[4]YAO Haiying.Research on chi-square static feature selection method and TF-IDF feature weighting method for Chinese text classification[D].Changchun:Jilin University,2016(in Chinese).[姚海英.中文文本分类中卡方统计特征选择方法和TF-IDF权重计算方法的研究[D].长春:吉林大学,2016.]
[5]LI Mingtao,LUO Junyong,YIN Meijuan,et al.Weight computing method for text feature terms by integrating word sense[J].Journal of Computer Applications,2012,32(5):1355-1358(in Chinese).[李明涛,罗军勇,尹美娟,等.结合词义的文本特征词权重计算方法[J].计算机应用,2012,32(5):1355-1358.]
[6]LI Xueming,LI Hairui,XUE Liang,et al.TFIDF algorithm based on information gain and information entropy[J].Computer Engineering,2012,38(8):37-40(in Chinese).[李学明,李海瑞,薛亮,等.基于信息增益与信息熵的TFIDF算法[J].计算机工程,2012,38(8):37-40.]
[7]TAO Shuyi,WANG Mingwen,WAN Jianyi,et al.An incremental text clustering algorithm based on cluster congruence[J].Computer Engineering,2014,40(6):195-200(in Chinese).[陶舒怡,王明文,万剑怡,等.一种基于簇相合性的文本增量聚类算法[J].计算机工程,2014,40(6):195-200.]
[8]ZHAI Donghai,CUI Jingjing,NIE Hongyu,et al.Topic link detection method based on semantic similarity[J].Journal of Southwest Jiaotong University,2015,50(3):517-522(in Chinese).[翟东海,崔静静,聂洪玉,等.基于语义相似度的话题关联检测方法[J].西南交通大学学报,2015,50(3):517-522.]
[9]CHEN Donghui.Research of key techniques in fuzzy clustering based on objective function[D].Xi’an:Xidian University,2012(in Chinese).[陈东辉.基于目标函数的模糊聚类算法关键技术研究[D].西安:西安电子科技大学,2012.]
[10]WANG Lifu.Research on clustering algorithm of K-medoids and its application in text clustering[D].Chongqing:Chongqing University of Technology,2017(in Chinese).[王李福.K-medoids聚类算法研究及其在文本聚类中的应用[D].重庆:重庆理工大学,2017.]
[11]TIAN Jiule,ZHAO Wei.Words similarity algorithm based on tongyici cilin semantic web adaptive learning system[J].Journal of Jilin University(Information Science Edition),2010,28(6):602-608(in Chinese).[田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报信息科学版,2010,28(6):602-608.]
[12]ZHOU Wei,LI Xiaojing.Comprehensive evaluation method based on information entropy theory[J].Science Technology and Engineering,2010,10(23):5839-5843(in Chinese).[周薇,李筱菁.基于信息熵理论的综合评价方法[J].科学技术与工程,2010,10(23):5839-5843.]
猜你喜欢
中学生数理化·八年级物理人教版(2022年5期)2022-06-05
军民两用技术与产品(2022年1期)2022-06-01
计算机技术与发展(2018年8期)2018-08-21
电子测试(2017年12期)2017-12-18
中国机械工程(2017年22期)2017-12-02
雷达学报(2017年6期)2017-03-26
现代工业经济和信息化(2016年2期)2016-05-17
池州学院学报(2015年3期)2016-01-05
中国医学影像学杂志(2015年9期)2015-12-15
中文信息学报(2015年4期)2015-04-21
