
改进的卷积神经网络在答案选择模块中的研究
2018-06-05 11:40许畅,张琳
网络安全与数据管理 2018年5期
许 畅,张 琳
(上海海事大学 信息工程学院,上海 201306)
0 引言
随着网络上数据的爆炸性增长,向用户提供准确的信息变得越来越困难。问答系统作为一种替代关键字的搜索引擎,可以理解自然语言的问题并反馈准确的答案。目前已经有很多具有影响力的问答系统,如苹果公司的SIRI、IBM的WATSON和亚马逊的ECHO。
问答系统一般包括问题分析、信息检索、答案抽取和答案选择4个主要模块。其中答案选择任务是从候选答案集中选择最佳答案返回给用户。
答案选择问题可以描述如下:给定一个问题Q和一个候选答案池{A1,A2,…,AS},目的是找到一个最佳的候选答案AK,1≤K≤S。答案是一个任意长度的记号序列,一个问题可以对应多个正确答案(真值集),若被选答案AK在真值集中,则说明问题Q被正确回答,否则问题Q没有被正确回答。
例如,下面包含关键字“Capriati”和“play”的两句话中,只有第一句话正确回答了问题“What sport does Jennifer Capriati play?”。
正确答案:“Capriati,19,who has not played competitive tennis since November 1994,has been given a wild card to take part in the Paris tournament which starts on February 13.”
错误答案:“capriati also was playing in the U.S. Open semifinals in ’91,one year before Davenport won the junior title on those same courts.”
鉴于近几年卷积神经网络和循环神经网络在自然语言处理领域任务中表现出来的语言表示能力,越来越多的研究人员尝试使用深度学习的方法完成问答领域的关键任务,例如问题分类、答案选择、答案自动生成等。本文对使用深度学习进行答案选择作了相关研究,改进了参考文献[1]提出的深度学习答案选择框架,主要对其中基于卷积神经网络的答案选择框架进行改进,以达到更好的匹配效果。
1 答案选择相关研究
答案选择任务本质是匹配问题和候选答案之间的语义联系。显然,答案选择需要语义和句法信息以便建立问题所需答案的信息,一方面是由于问题和正确答案单单通过词语匹配可能无法找到共同点,另一方面是正确答案包含信息过多,导致重点信息无法识别。遵循问题可以通过语法转换从正确答案中生成的观点,文献[2]首先提出建立一个生成模型从而匹配问题答案对的依赖树,接着提出了一个生成式的概率模型来计算问题和答案的依赖句法树的结构匹配度[3];文献[4]利用树核来搜索最小编辑解析树之间的序列,然后将从这些序列提取的特征输入逻辑回归分类器来选择最佳候选者;文献[5]在文献[4]的基础上作出了延伸,使用动态规划来寻找最佳树编辑序列,另外添加了从WordNet获取的语义特征;文献[6]将丰富的词汇语义应用到他们最先进的QA匹配模型中。这些模型通过使用诸如WordNet的词汇语义资源与用于捕获语义相似度的分布式向量的组合来匹配问答对中的对齐词的语义关系。类似地,文献[7]使用SVM树核自动学习句法的特征,从而完成问题答案对的分类。
鉴于近几年卷积神经网络和循环神经网络在自然语言处理领域表现出来的语言表示能力,越来越多的研究人员尝试使用深度学习的方法完成问答领域的关键任务。比如,基于卷积神经网络的短文本匹配[8];用包含多个卷积核的网络结构来处理句子匹配[9];用卷积神经网络来进行情感预测和文本分类等[10]。
利用深度学习技术处理答案选择任务主要有以下3种方法:(1)在问题和答案的基础上构造一个联合特征向量,然后将任务转化为一个分类或排序问题;(2)这种方法是最近提出的,即用于文本生成的模型在本质上可以用于答案选择和答案生成;(3)问题和答案向量表示是可以被学习的,并且通过特定的余弦相似度进行匹配。本文采用第三种方法处理答案选择任务,主要是用卷积神经网络来将问题和答案进行向量表示,之后通过计算二者余弦相似度来确定问题和答案的匹配度。
2 答案选择框架
2.1 ArchitectureII
本文将基于参考文献[1]提出的框架进行改进,首先介绍Feng Minwei等提出的ArchitectureII。框架结构如图1所示。
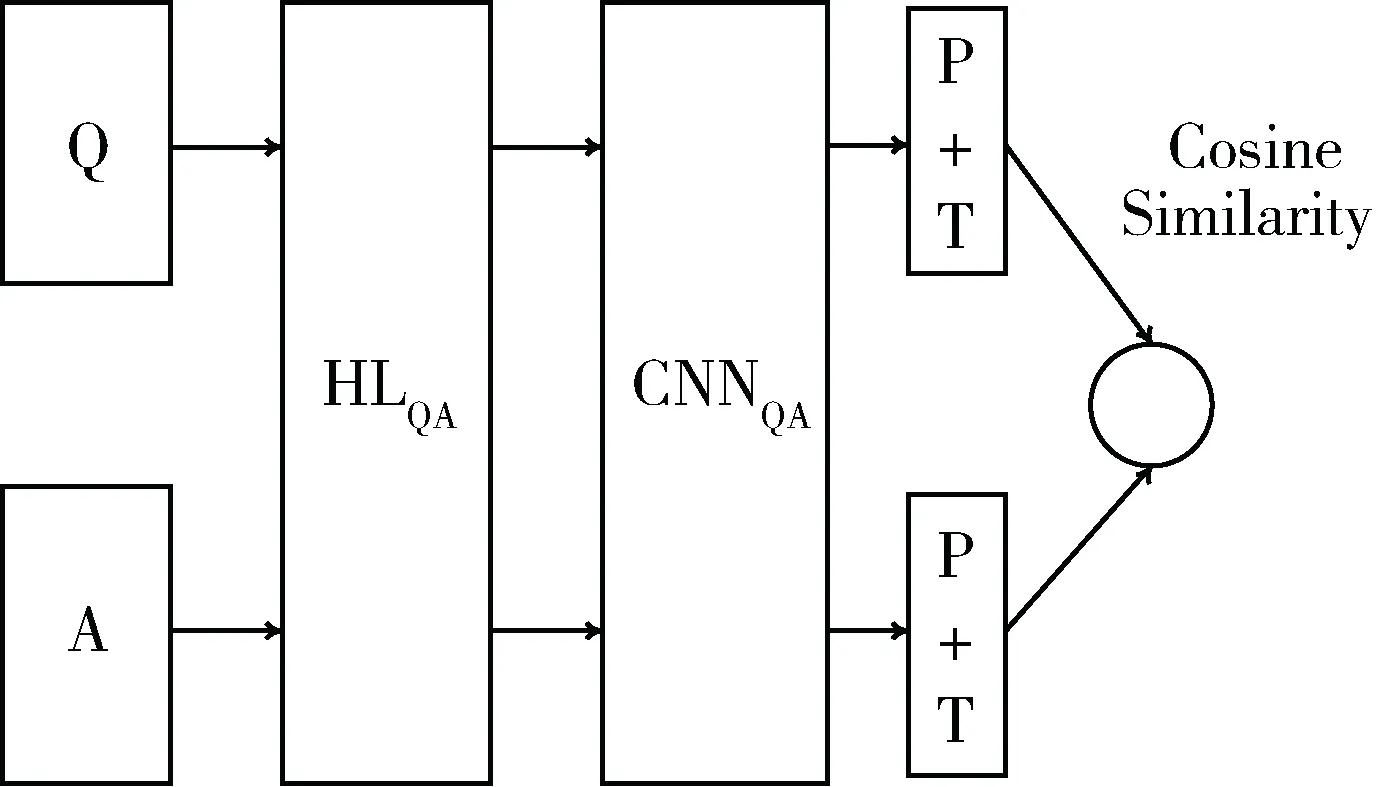
图1 ArchitectureII
Q作为输入将问题提供给第一个隐藏层HLQ。隐藏层HL的定义为z=tanh(Wx+B),其中W为权重,B为偏向量。z作为激活函数tanh的输出传递给卷积神经网络层CNNQ,用于抽取问题的特征;P是1-MaxPooling层,T是tanh层。类似地,答案A由隐藏层HLA处理,其输出结果由CNNA进行特征抽取,而1-MaxPooling层和tanh层将在最后一步发挥作用,其结果是将问题和答案进行向量表示。该框架最终的输出结果是问题和答案的余弦相似度。在2.2节将对Feng Minwei等人提出的框架中的卷积神经网络进行简单的介绍。
2.2 卷积神经网络
BENGIO Y认为卷积神经网络有3个重要的特点:稀疏交互、参数共享和等变表示[11]。稀疏交互和传统的神经网络中的每个输入都要与输出进行全连接形成对比,即在卷积神经网络的卷积层中,一个神经元只和部分邻层神经元相连接;参数共享是指在一次卷积过程中重复使用滤波器的参数,这里共享的参数就是卷积核;等变表示类似于经常在卷积神经网络中提到的k-MaxPooling的思想。本文中将一直使用1-MaxPooling,因此进行卷积操作之后,1-MaxPooling保留的是特征最强的值。具体卷积神经网络卷积过程如式(1)所示:

(1)
权值W表示输入的句子,每个单词用一个三维的词嵌入向量表示且输入长度为4。权值F表示滤波器,这里滤波器大小为3×2。因此一次卷积操作的结果输出是一个三维向量O,如式(2)所示:
(2)
在经过1-MaxPooling后,滤波器中将保留特征最强的3个值,即表明滤波器F与输入W的最高匹配度。
2.3 损失函数
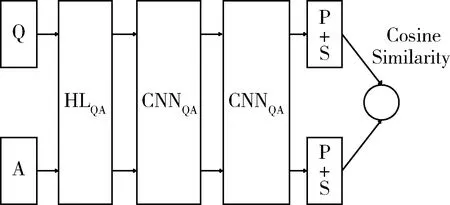
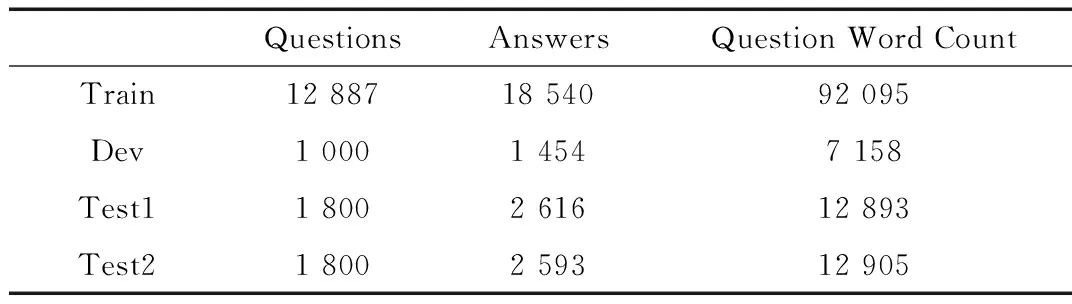
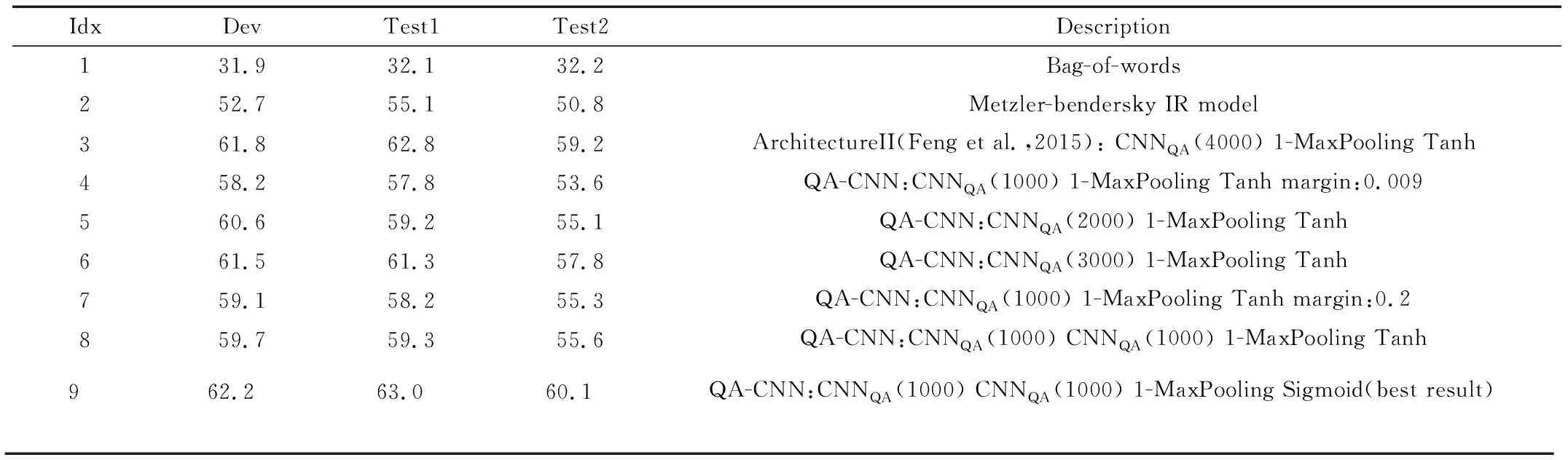
一个训练实例是由从答案集中取样的正例A+和负例A-构造的。在训练过程中,将问题和两个候选答案生成向量表示:VQ,VA+和VA-,通过计算余弦相似度cos(VQ,VA+)和cos(VQ,VA-)并将二者之间的距离与margin进行比较。若cos(VQ,VA+)-cos(VQ,VA-) 本文中使用的损失函数定义如式(3): L=max{0,m-cos(VQ,VA+)+cos(VQ,VA-)} (3) 本文中采用的框架是基于Feng Minwei等提出的ArchitectureII进行改进的,改进如下:(1)在ArchitectureII的基础上增加一层卷积神经网络;(2)修改原结构中的T层,将激活函数换为sigmoid函数。具体框架如图2所示。 图2 QA-CNN框架 本文中使用的数据集是InsuranceQA,如表1所示。该数据集是由Feng Minwei等提出,它包含保险领域的问题答案对,由训练集、验证集和两个测试集组成。在InsuranceQA数据集中,一共包含24 981个答案,在实验中将整个答案空间作为候选池并不实际。因此,在实验中将候选池的大小设置为500。首先将真值放入候选池中,然后再随机从答案空间中抽样错误的答案放入候选池中,直到候选池大小为500。 表1 InsuranceQA 为了进行对比,表2给出了3个基线模型的效果: Bag-of-word:该模型用IDF加权的词向量作为特征向量。候选答案根据余弦相似度排列。 Metzler-Bendersky IR model:一种最先进的加权依 赖模型,它采用基于术语和基于接近度的特征的加权组合来评分每个候选者。 ArchitectureII:提出一个基于卷积神经网络的框架将问题和答案进行向量表示,最后计算余弦相似度来确定问题和答案的匹配度。 本文中使用Tensorflow和Python来实现QA-CNN框架。首先,使用word2vec[12]来对数据进行预处理且词向量大小为100;然后,在实验过程中,尝试了不同的margin值,如0.009、0.05、0.1和0.2,Feng Minwei使用的是0.009,实验最终将margin值设为0.2;最后,滤波器数量设置为1 000个。另外训练中尝试加入L2 范式和skip-biagrams,但是鉴于对实验效果没有较好的提升,所以最终在实验中未采用。 在本小节将对实验结果进行详细阐述。第一,增加滤波器的数量可以捕获更多的特征从而一定程度上提升了实验效果(表2,第5行与第6行);第二,在滤波器数量相同的情况下,margin值设为0.2要比Feng Minwei设置margin值为0.009有一定效果上的提升(表2,第4行与第7行);第三,两个卷积层可以在输入范围广时表示更高层次的抽象,因此考虑使用多个卷积层可以在一定程度上提高精确度(表2,第4行与第8行)。 在本文中,改进了由Feng Minwei等提出的一个用于答案选择的深度学习框架,QA-CNN框架不依赖于任何语言工具并且可以应用到任何语言和领域。可以发现,增加滤波器的数量可以在一定程度上帮助卷积神经网络捕获更多的特征,从而在答案与问题匹配度上有较好的提升。实验证明,Feng Minwei在训练中加入L2-norm和skip-biagrams对实验效果没有较好的提升;其次,两个卷积层对输入可以在更广的范围内进行特征抽取,因此在训练中增加卷积层的数量可以在一定程度上提高精确度。 表2 实验结果 本文运用深度学习框架,从问答选择的角度对问答系统中答案选择模块进行了研究。本文主要工作是对Feng Minwei等提出的深度学习框架进行改进,以达到更好的精确度。实验表明,改进后问题答案匹配度达到了62.2%,比Feng Minwei等文献中提到的最好结果高出0.4%。另外,在实验中也尝试使用其他技术来提高实验效果,如增加卷积层数来对特征更好的提取、加入L2-norm和skip-biagrams、增加滤波器数目等,可以看出,增加滤波器数目和卷积层层数在一定程度上可以提高问题和答案的匹配度。后续研究会集中于改变网络结构框架如增加长短期间记忆网络等,以获得更好的突破。 [1] Feng Minwei, Xiang Bing, GLASS M R. et al. Applying deep learning to answer selection:a study and an open task[C]//IEEE Automatic Speech Recognition and Understanding Workshop,2016:813-820. [2] Wang Mengqiu, SMITH N A, MITAMURA T. What is the jeopardy model? a quasisynchronous grammer for qa[C]//EMNLP-CoNLL,2007:22-32. [3] Wang Mengqiu, MANNING C D.Probabilistic tree-edit models with structured latent variables for textual entailment and question answering[C]//Proceedings of COLING,2010:1164-1172. [4] HEILMAN M, SMITH N A.Tree edit models for recognizing textual entailments,paraphrases,and answers to questions[C]//Proceedings of NAACL,2010:1011-1019. [5] Yao Xuchen,Benjamin Van Durme, CLARK P.Answer extraction as sequence tagging with tree edit lexical semantic models[C]//Proceedings of NAACL-HLT,2013:858-867. [6] YIH W T, CHANG M W, MEEK C,et al.Question answering using enhanced lexical semantic models[C]//Proceedings of ACL,2013:1744-1753. [7] SEVERYN A, MOSCHITTI A.Automatic feature engineering for answer selection and extraction[C]. EMNLP,2013. [8] BAHDANAU D,CHO K, BENGIO Y.Neural machine translation by jointly learning to align and translate[C]//Proceedings of International Conference on Learning Representations,2015. [9] YIH W T, ZWEIG G, PLATT J C.Polarity introducing latent semantic analysis[J].Proceedings of EMNLP-CoNLL,2012,25(3):553-558. [10] SOCHER R,PENNINGTON J,HUANG E H,et al.Semi-supervised recursive autoencoders for predicting sentiment distributions[C]//EMNLP, 2011:151-161. [11] BENGIO Y, GOODFELLOW I J, COURVILLE A. Deep learning[M].MIT Press,2015. [12] MIKOLOV T, SUTSKEVER I, CHEN K,et al. Distributed representations of words and phrases and their compositionality[C]//International Conference on Neural Information Processing Systems, 2013:3111-3119.2.4 QA-CNN框架
3 QA-CNN实验
3.1 基线
3.2 实验搭建
3.3 实验结果
4 结束语
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2020年3期)2020-07-27
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
系统工程与电子技术(2016年7期)2016-08-21
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
长江学术(2016年4期)2016-03-11
火控雷达技术(2016年2期)2016-02-06
