
数据挖掘技术在油田中的应用
2018-05-22 07:24薛茹
微型电脑应用 2018年5期
薛 茹
(西北大学 现代学院,西安 710130)
0 引言
随着科技和信息化的快速发展,油田数字化建设的全面推进,进入“大数据”时代。在油田行业中,会产生大量复杂的数据,提取有价值的信息越来越困难,采用传统的数据分析和预测方法已经无法解决复杂的数据情况,如何有效提取和充分利用这些数据资源,得到尽可能多的有用信息,来提高油田企业的生产效率和质量,推动油田行业的快速发展,成为油田生产和管理中的迫切需求。而数据挖掘技术正好可以解决这一问题,可以建立数据仓库,进行数据分析处理与预测,提取和挖掘大量有价值的信息,为油田行业的发展提供有力的技术支持,能够促进油田行业快速有效的发展。因此,数据挖掘技术在油田行业中有着良好的发展前景。
1 数据挖掘技术
数据挖掘是指在实际应用的大量数据中,这些数据是模糊的、有噪声的、随机的,通过采取一定的方法,获取出隐含的、未知的并有价值的信息的过程。在数据库中,进行数据挖掘,可以把采集到的信息充分利用。在数据挖掘中[1],一定要保证数据是真实的,从而提取出有用的信息。
数据挖掘技术融入了大量的科学技术,是一种新型实用技术,技术中融合了数据库、统计分析、信息处理、人工智能等多方面的内容,能够在实际应用中,对数据进行分析,从而找到相关的规律。随着数据挖掘技术越来越成熟,已经在许多领域得到广泛的应用。数据挖掘技术包括了许多分析数据的重要方法,比如数据统计、模式识别等。在大量随机数据中,通过对数据进行分析,找到相关的内容进行研究。[2]
传统的数据分析包括如查询、报表、联机应用分析等,数据挖掘与传统的数据分析最为本质区别是在于数据挖掘是在没有明确假设的前提下去挖掘信息、发现知识。数据挖掘所得到的信息应具有先未知、有效性和实用性3个特征。
在数据挖掘过程中,首先进行数据的准备,确定需要挖掘的数据,对挖掘的样本数据进行一定的数据分析,比如统计学描述中算出均值、方差等统计量,建立成一个数据集合。然后确定数据挖掘的目的,探寻关联与规律,如分类、聚类、关联规则等。结合业务和经验选择一种或多种的分析方法,选取挖掘算法。最后求解分析模型,把数据挖掘的结果形象的表示出来,使用户更好理解,根据分析模型解释业务问题。
2 数据仓库建模及数据在线分析技术与方法研究
建立数据仓库,根据用户的需求进行相应的分析,并根据油田数据的应用进行设计,建立了油田基于数据仓库的商业智能应用总体构架,如图1所示。
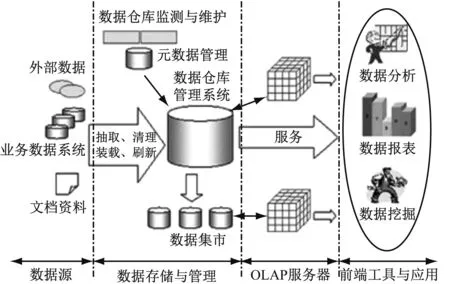
图1 基于数据仓库的商业智能应用总体架构
总体构架分为4个部分:数据源、数据存储与管理、OLAP服务器和前端工具与应用。第一部分数据源,存放着油田行业中大量的数据,是由外部数据、业务数据系统或文档资料提供数据; 第二部分数据存储与管理,主要由数据仓库管理系统、数据仓库监测与维护、元数据管理以及数据集市构成。数据仓库就是一个用以更好的支持企业或组织的决策分析处理的、面向主题的、集成的、随时间不断变化的但信息本身相对稳定的数据集合。数据仓库有以下几个特点:数据仓库中的数据是面向主题的、集成的、不可更新的,建立数据仓库的目的是为了更好的支持决策的制定。数据集市是基于立方体多维数据集的数据集市[3],数据挖掘都要先把数据从数据仓库中拿到数据挖掘库或数据集市中。从数据仓库中直接得到进行数据挖掘的数据有许多好处。通过对数据源进行抽取、清理、装载、刷新等操作后放入数据仓库管理系统,对数据进行存储与管理。而且数据仓库构建原则一定要准确、统一、全面、高效,通过元数据管理对数据仓库进行监测与维护;第三部分是 OLAP服务器,OLAP包括MOLAP和ROLAP两种分析处理技术,MOLAP分析处理技术,一种特殊的服务器,它直接实现多维数据和操作,ROLAP分析处理技术,即扩充的关系DBMS,它将多维数据上的操作影射为标准的关系操作。这里主要采用立方体多维数据集的MOLAP分析处理技术,因为MOLAP分析处理技术的查询速度快,稳定性强,而且节省存储空间,分析数据的精度高;第四部分是前端工具与应用,主要包括数据分析、数据报表和数据挖掘。通过进行在线分析处理数据,形成数据报表的形式,然后对数据仓库进行数据挖掘,实现多层次的数据分析与挖掘,采用相应的数据挖掘方法,挖掘出有价值的信息,在油田行业里更好的去应用这些数据信息。
3 油田数据挖掘方法研究
基于人脑的数据探索,需要多视角、多度量、多组合过滤条件地来统计分析并可视化数据,从而让用户通过这种极大的人机互动支持从而让用户得到尽可能多的价值信息。
可以把油田数据挖掘方法分为3个方面:一是基于历史经验,基于油藏事例库的推断分析;二是基于挖掘算法,包括基于采油指数递减的产量与递减预测、基于灰色模型的产量与递减预测和基于时间序列模型的产量预测。三是基于人脑探索,是基于立方体多维数据集的自定义分析。
首先,基于油藏事例库进行推断分析,所采用的技术原理为:结合已积累构建的油藏业务事例库,基于历史范例进行推理和问题的求解。简单的说,也就是利用过去的经验来解决新的问题,整个推断分析的过程可以描述为:遇到新问题,先从构建的案例库中获取,进行案例的再用、修正与更新,获取解决的方法,这就是从油藏事例库中获取的整个过程,如图2表示。
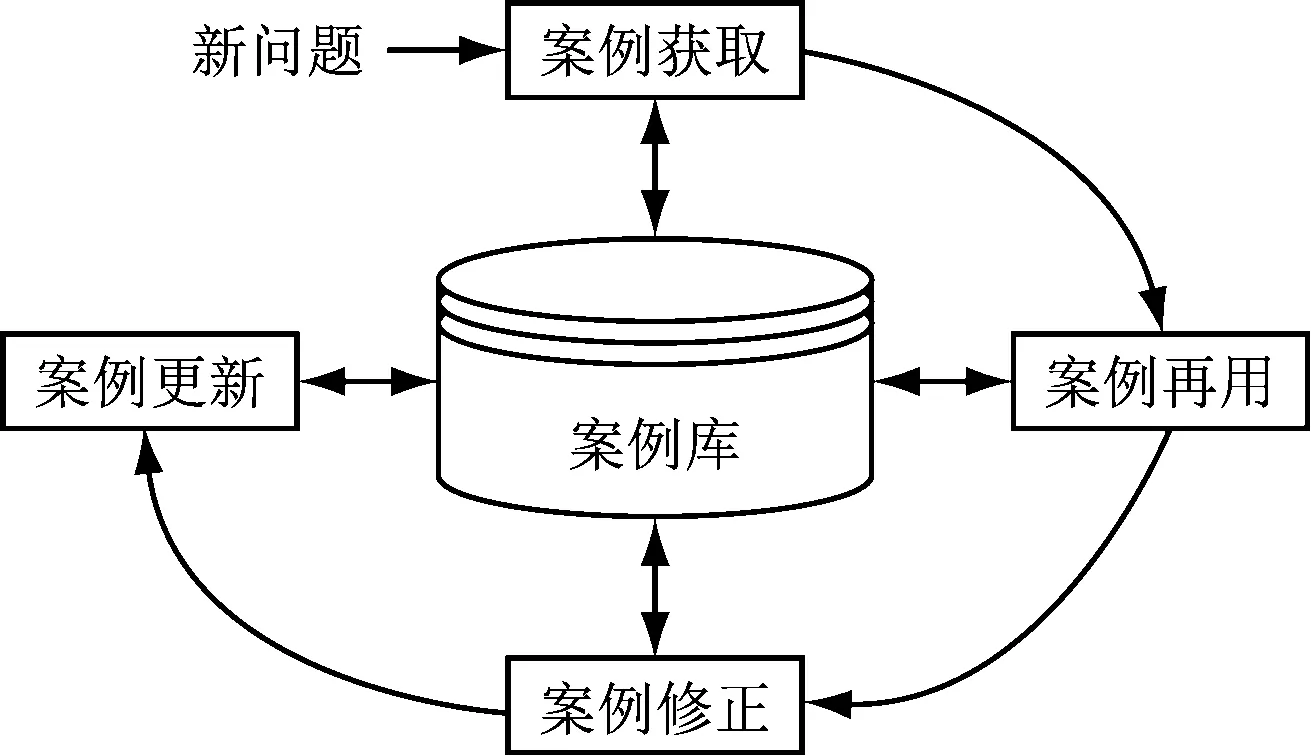
图2 从案例库获取的过程
事例库定义可以分为3个方面:特征、解决方案和评价指标。我们利用事例进行问题求解的时候,首先,发布需要求解的问题,然后,根据事例的特征,利用距离算法查找最相似的事例,把找到的已有事例的解决方案作为参考,找出指定问题的解决方案。最后,对问题进行求解后,并对方案进行全面的评价。
因此,通过对油藏案例库获取过程的推导,在油田实际应用过程中能够根据已有油藏事例,快速找到问题的解决方案,便于油藏管理人员能抓住主要问题,有针对性地采取相应措施,有效进行问题的解决。
其次,基于挖掘算法,包括常用的3种算法:在挖掘算法中基于采油指数递减法的产量与递减预测、基于灰色模型的产量与递减预测和基于时间序列模型的产量预测。采用第一种算法,在挖掘算法中基于采油指数递减法的产量与递减预测,所采用的技术原理可以描述为:一个油田的年产油量可以近似地表示为采油指数和生产压差的关系,于是只要统计出采油指数和生产压差随含水的变化规律,就可以计算出年产油量,从而测算出下一年的产量了。采油指数计算如式(1)。
(1)
采用第二种算法,基于灰色模型的产量与递减预测,所采用的技术原理可以描述为:基于灰色理论构建的预测模型,将生产历史数据作为样本数据对预测模型进行训练,最后基于模型进行预测。
灰色理论是根据曲线间的相似程度来判断因素间的关联程度。灰色预测法是针对不确定因素的系统进行预测的一种方法。它能够判别因素之间的关联程度,是介于黑色和白色之间的一种系统。系统中有些信息是已知的,但有些信息是未知的,所以各因素之间存在不确定的关系。灰色预测即对已知的信息预测,也对不确定的信息预测,研究在一定时间、范围内的变化过程,进行鉴别各个因素之间发展变化的相异程度,进行一定的关联分析。为了寻找系统变动的规律,对原始的数据进行相应的处理与分析,生成了规律性很强的数据序列,从而建立出相应的模型,通过模型来预测事物的发展趋势。[4]
采用第三种算法,基于时间序列模型的产量预测,所采用的技术原理可以描述为:基于时间序列理论构建的预测模型,将生产历史数据作为样本数据对预测模型进行训练,最后基于模型进行预测。
时间序列理论是将某种现象的某一个统计指标在不同时间上的各个数值,按时间先后顺序排列而形成的序列,并从长期趋势(T)、季节变动(S)、循环变动(C)、不规则变动(I)4种构成要素分别展开建模分析,最后汇总模型分析结果得到整体的分析结果。
长期趋势(T)是指时间序列随时间的变化而逐渐增加或减少的长期变化的趋势。季节变动(S)是指时间序列在一年中或固定时间内,呈现出的固定规则的变动。 循环变动(C)是指沿着趋势线如钟摆般地循环变动,又称景气循环变动(business cycle movement) 。不规则变动(R) 是指在时间序列中由于随机因素影响所引起的变动。
在油田实际应用过程中,这3种数据挖掘算法都是很有效的。通过基于采油指数递减法的产量与递减预测,根据采油指数和生产压差,很方便的就计算出年产油量,在应用中证明该方法是可行的。而基于灰色模型的产量与递减预测,则建立了较高预测精度的灰色模型,并且该模型计算简捷,具有很好的实用性,使得油田产量预测精度明显提高,因此该算法在石油行业中有着非常大的应用领域。对于基于时间序列模型的产量预测,在应用中,该模型的预测值最接近于实际值,实现了油田产量随时间的变化的预测,该模型的拟合效果最好,能够有针对性地采取相应措施减缓产量递减,提高经济效益和开发管理水平。
最后,基于人脑探索,也就是基于立方体多维数据集的自定义分析,是自助式商业智能的一个具体实现,如图3所示。
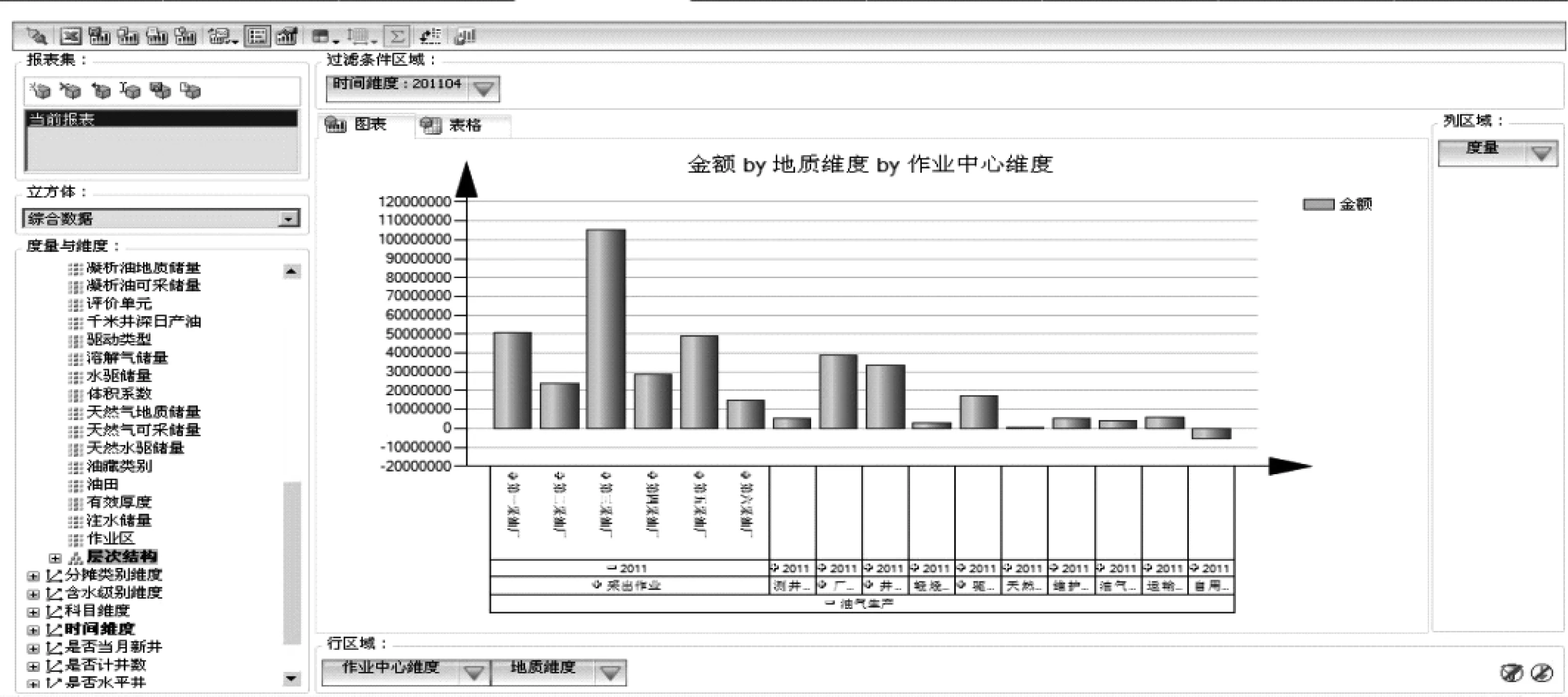
图3 基于立方体多维数据集的自定义分析
基于立方体多维数据集的自定义分析所采用的技术原理为:基于包含油藏开发生产、财务等各业务主题数据的立方体多维数据集,提供给用户自定义角度、过滤条件和结果视图的能力,以满足进行各种自定义统计分析和生成各种分析报表的需要,从而充分调动数据分析专家和爱好者的兴趣,让他们通过人为手段挖掘出潜在数据价值。
这种基于人脑探索的数据挖掘方法,在油田实际应用中,能够通过立方体多维数据集的分析,得到月产油量与相对应的金额,以及金额与地质维度和作业中心维度的关系,能够很方便的进行分析,生成相应的报表,在油田行业中有很大的实用性。
4 总结
综上所述,在油田企业的信息处理中,需要采用一定的数据挖掘技术,通过使用合理的数据挖掘方法,对相关数据进行有效的分析,使得石油开采更加可靠,更好的完成油田企业中的信息处理,能够提升油田企业的经济效益和社会效益,让油田企业更好地发展下去。
参考文献
[1] 陈玉涛. 数据挖掘技术在油田企业生产中的应用[J].仪表电气,2014(4):53.
[2] 李佳旭. 数据挖掘技术在油田开发中的应用[J]. 技术研究,2016(7):139.
[3] 曲道庆. 油田信息数据仓库与数据挖掘[J]. 油气田地面工程,2007(7):45.
[4] 朱志香.油气田产量递减灰色系统模型的建立及预测[J]. 科技创新导报,2010(24):62.
猜你喜欢
水泵技术(2021年2期)2021-07-31
大众投资指南(2021年35期)2021-02-16
电子乐园·下旬刊(2021年3期)2021-02-08
中学生数理化·中考版(2020年11期)2020-12-14
中国交通信息化(2020年1期)2020-07-27
自然资源信息化(2019年4期)2019-03-29
动漫星空(兴趣百科)(2017年5期)2017-10-30
山东工业技术(2016年15期)2016-12-01
能源(2016年1期)2016-12-01
信息通信技术(2015年6期)2015-12-26
