
自然语言处理在网站分类中的应用
2018-05-22 01:17:54中国信息通信研究院产业与规划研究所工程师
信息通信技术与政策 2018年5期
李 曼 中国信息通信研究院产业与规划研究所工程师
1 引言
为了防止在网上从事非法的网站经营活动,打击不良互联网信息的传播,2005年,工信部(原信息产业部)公开发布《非经营性互联网信息服务备案管理办法》(第33号令),要求从事非经营性互联网信息服务的网站进行备案登记。据中国互联网协会和国家互联网应急中心联合发布的《互联网行业运行指数——中国网站》报告统计,截至2017年年底,我国网站数量达到526.06万个。网站备案信息是分析信息产业发展水平,区域、行业信息化水平的重要数据来源之一。但是,由于网站备案机制本身的限制以及历史数据质量等原因,网站备案信息存在滞后性、准确率低、信息缺失、信息颗粒度大等问题。由于网站数量庞大,通过自动化的方法解决这些问题满足数据需求是关键。
2 需求分析
2.1 问题描述
本文要解决的是网站分类问题,即根据实际业务需求将多个网站按照一定的标准进行分类。例如,按照行业划分为农业、制造业、资源、能源的生产和供应、建筑业、交通邮电、信息传输、计算机服务和软件业、金融地产租赁、生活服务、教育科研、文体娱乐、公共服务等11类。
2.1 输入
(1)网站地址列表信息:S={Si},1≤i≤N,其中N表示网站总数、Si表示第i个网站的网站地址。
(2)目标分类信息:C={Ck},1≤k≤M,其中M表示总类别数、Ck表示第k个分类。目标分类信息就是分类参考的标准。
2.2 输出
分类结果:每个网站对应的目标分类SC={SCi}={Si->C(i)},1≤i≤N,C(i)ÎC,其中 C(i)表示网站 Si对应的分类。
3 基于自然语言处理的网站分类方法
3.1 总体思路
网站分类是一种利用文本信息的分类问题,其关键点主要在于网站特征提取、网站分类算法、训练集获取3个方面。在网站特征提取方面,由于网站地址中携带的信息量较少,考虑将网站内容作为网站的特征用于网站分类,将网站首页的关键词作为量化特征。在网站分类算法方面,通常选择常用的分类算法,但需要根据网站特征定义两个样本之间的距离。在训练集获取方面,由于没有现成的训练集,采用人工标识的方法会耗费大量人力,本文采用分类映射法,即将具备训练集的细颗粒度分类映射到目标分类,从而可以间接获取到训练集。
3.2 网站特征提取
选取网站首页内容(以下称“网页文档”)的关键词作为网站特征,具体可以采用TF-IDF(Term Frequency-Inverse Document Frequency)方法计算得到。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。其主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。从计算公式来讲,TF-IDF=TF×IDF,TF(Term Frequency)表示词频,如果一个词出现在文档里的频次越高,则认为该词越重要,IDF(Inverse Document Frequency)表示逆向文件频率,如果一个词出现在文档的数量越多,则认为该词越不重要。
采用TF-IDF方法提取网站特征的具体步骤包括统计词频、计算TF-IDF值、特征值标准化3个方面。
(1)统计词频。通过网页文档分词处理得到网站的词频,网站Si的网页文档词频wordfreqi={(wordij,freqij)},1≤j≤WNi,其中WNi表示网站Si的网页文档包含的不同词语数。
(2)计算TF-IDF值。利用TF-IDF方法计算每个网页文档中每个关键词的TF-IDF值,并在按照TF-IDF值在文档内进行排序,可以根据关键词个数或TF-IDF值大小选取前KWNi个作为网页文档的关键词,得到tfidfi={(keywordij,tfidfij)},1≤j≤KWNi,KWNi表示网站Si的网页文档关键词的个数。
(3)特征值标准化。将上一步计算得到的TFIDF值进行单位化tij=tfidfij/sqrt(Sj(tfidfij)^2),得到最终的网站特征值ti={(keywordij,wij)},1≤j≤KWNi。
3.3 网站分类算法
本文网站分类算法采用K最近邻(kNN,k-NearestNeighbor)。kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的k个样本的类别来决定待分样本所属的类别。
kNN算法中需要找到最邻近的k个样本,因此我们要定义两个样本之间的距离。定义距离的核心思想是如果两个网页文档具有相同的关键词越多,关键词权重分布越接近,则认为两个文档越相似,文档距离越近。具体公式如下:
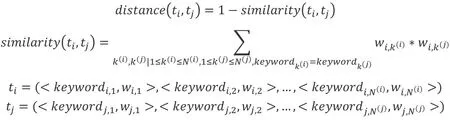
其中,ti、tj分别是两个网页文档的特征值向量,N(i)、N(j)分别网页文档中的关键词数量。
3.4 训练集获取
本文采用分类映射法间接获取训练集。分类映射法的核心思想是若已知分类方式C1、C2,其中C1的分类颗粒度比C2小,则对目标集进行C2分类时可以采用C1的训练集。因此,考虑使用公开的细颗粒度网站分类目录,作为分类算法的训练数据。
定义目标分类是C2,也就是最终需要的分类方式,把相对细颗粒度的分类C1叫做中间分类,也就是我们根据C1的训练集训练模型得到的分类。采用分类映射法后,我们的网站分类在模型训练过程和模型分类过程均需要进行相应的调整。
(1)模型训练过程调整。采用C2的训练集数据得到分类模型。
(2)模型分类过程调整。根据分类模型得到每个网站的中间分类C2,然后根据C2与C1的唯一映射关系得到每个网站的目标分类C1。
4 应用实现
网站分类作为一种大数据分析应用,具有典型的6个环节(见图1),分别是数据采集、数据清洗、数据存储、数据处理、数据分析、可视化,其中数据采集是确定数据源并且从数据源获取数据,数据清洗是对数据采集的原始数据中不规范的内容进行过滤、清洗,数据存储是通过关系型数据库、文本数据等不同形式将数据存储起来,数据处理是数据的基本处理,主要是为了下一步的数据分析做准备,数据分析是为了实现最终的分析目标而进行的业务层面的数据分析,可视化是应用最终的输出,可根据业务实际需求选择不同的展现方式。本节主要从这6个环节介绍利用前文提出的网站分类方法实现的一个应用案例:针对某省7万多个备案网站按照行业分类,共分类11个类别。
4.1 数据采集
(1)网站列表数据。网站列表数据由需求方提供。
(2)网站页面文档数据。网站页面文档数据通过网站地址爬取所有网站首页内容(即网页文档)获得。
(3)训练集数据。训练集数据经过两步获得。首先找到训练集数据源,然后采用爬虫的方法获取训练集数据,包括网站列表、网站页面内容以及网站对应的分类。
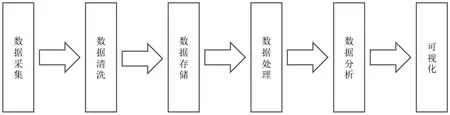
图1 网站分类6个环节
4.2 数据清洗
(1)网站地址数据清洗。针对网站地址的不规范情况进行处理,例如将网站的多个网址拆分、将网址统一为以“http://”开头、去除网址收尾空白符等。
(2)网页文档数据清洗。针对数据采集环节中获得的网页文档进行内容清洗、提取,具体包括去除网页文档中的标签符、去除首尾空白符、对于无法访问的网页进行标记、选择网页文档中的Keyword、Title、Description以及全文内容作为有效内容等。
(3)训练数据清洗。与网站内容数据做相同方式的清洗。
4.3 数据存储
采用MySql数据库存储数据。目标网站、训练网站数据分别存储在Site目标网站表、Sitetrain训练网站表。
4.4 数据处理
利用中文信息处理方法对网页文档进行分词,统计词频。下面以山猫电影(http://www.bobmao.com)为例,其网页文档见表1。
(1)中文分词。使用中文分词器lucene对网页文档进行分词,根据业务需求配置自定义词库、停用词,得到网页文档的分词结果,具体参见表2。
(2)统计词频。根据网页文档分词结果统计词频,具体参见表3。

表1 网页文档示例

表2 分词结果示例
4.5 数据分析
(1)计算特征值。根据前一环节词频统计结果,进行标准化处理得到特征值,具体参见表4。
(2)进行分类。设置参数k,根据前文中样本间距离的定义,采用kNN算法进行分类,得到中间分类结果C2。

表3 词频统计示例

表4 特征值示例

表5 分类映射关系(部分)
4.6 可视化
(1)定义分类映射关系。根据经验定义中间分类到目标分类的映射关系,具体参见表5。
(2)输出结果。根据分类映射法,将中间分类映射到目标分类,以表格形式输出分类结果。
5 结束语
本文提出了一种基于自然语言处理的网站分类方法,在网站特征提取、网站分类算法以及训练集获取等关键问题上进行了分析,最后给出基于该方法的应用实现。随着大数据技术和概念的普及,人们的大数据意识也在不断提升,将会发掘出更多的应用场景。
参考文献
[1]卢卫等.互联网行业运行指数报告——中国网站[EB/OL].北京:中国互联网协会,国家计算机网络应急技术处理协调中心,2018[2018-01-09].http://index.isc.org.cn/.
[2]中华人民共和国信息产业部.非经营性互联网信息服务备案管理办法[EB/OL].北京:中华人民共和国信息产业部令(第33号),2005[2005-02-08].http://www.gov.cn/gongbao/content/2005/content_93018.htm.
[3]施聪莺,徐朝军,杨晓江.TFIDF算法研究综述[J].计算机应用,2009(z1):167-170,180.
[4]张宁,贾自艳,史忠植.使用KNN算法的文本分类[J].计算机工程,2005(8):171-172,185.
