
基于Python的微博发表意向预测研究
2018-05-15 10:10陈智梁娟谢兵傅篱
物联网技术 2018年4期
陈智 梁娟 谢兵 傅篱
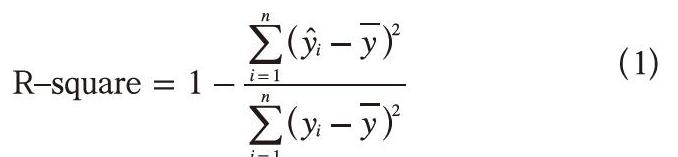
摘 要:微博的庞大数量以及微博文本的多样性,给微博舆情监控和预测带来较多困难,如果能够预先判断用户发表微博的意向,那么就可以进行更有针对性的引导和控制。文中根据微博用户数据的主要特征,使用Python的scikit-learn包中的主要回归预测模型,对用户发表微博的意向进行预测分析,评价不同回归预测模型预测微博发表意向的能力以及用户特征对微博发表意向的影响。通过实验研究发现,用户的微博发表意向更多取决于用户关注数,而梯度提升回归模型对此问题有更好的适应性。
关键词:微博发表意向;Python;回归预测模型;特征贡献度
中图分类号:TP391 文献标识码:A 文章编号:2095-1302(2018)04-00-03
0 引 言
作为虚拟社交的重要方式之一,微博在主导舆论方面的作用越来越重要。微博舆论具有扩散圈层化、传播裂变化等特征[1],社会影响巨大。如何监测和控制微博舆论,避免恶意言论和谣言在微博传播,成为微博舆情监控的重要研究内容。目前,已有不少微博舆情分析[2]、垃圾信息检测[3]、传播趋势预测[4,5]、舆论引导[6]等研究,但由于微博数据量庞大,且具有形式多样化的特点,使得各种舆情监控算法在效率和性能方面都面临着巨大压力。如果可以预先判断用户发表微博的意向,进而进行引导和控制,那么就可以在一定程度上将恶意言论或谣言控制在产生初期并遏制其传播,提高微博舆情监控的效率。
本研究从爬盟[7]获取微博用户数据,提取微博用户数据的特征,并使用Python机器学习回归预测模型分析这些数据与微博用户发表意向之间的潜在规律,进而对用户可能发表微博的意向进行预测,为微博舆情控制提供更细化的数据参考。
1 数据预处理
通过爬盟获取的新浪微博用户数据包括24个数据项,即用户ID,屏幕名,用户名,是否VIP,VIP描述,自我介绍,性别,地区,工作,教育,头像,生日,QQ,MSN,Email,标签,关注数,粉丝数,微博数,创建时间,关注列表,是否会员,是否达人,等级。在这些数据项中,用户ID,屏幕名,用户名都可以看作是用户的唯一标识,作为一个数据项处理;是否VIP,VIP描述反映用户加入VIP的情况,作为一个数据项处理;性别,地区,工作,教育,头像,生日,QQ,MSN,Email,创建时间可以看作自我介绍的明细和补充内容,根据其详细程度统一处理为自我介绍;关注列表是关注该用户的其他用户ID,对判断用户微博发表意向及后续研究没有直接作用。因此,对微博用户数据进行筛选后,只留下用户ID、自我介绍、关注数、粉丝数、微博数、是否VIP、标签、是否会员、是否达人、等级共10个数据项,对其进行必要的规范化转换。
(1)用户ID、关注数、粉丝数、微博数、是否VIP、是否会员、是否达人、等级:这些数据项保留其值,不做进一步转换;
(2)自我介绍:根据相关数据项(自我介绍,性别,地区,工作,教育,头像,生日,QQ,MSN,Email)是否為空,即根据用户是否有介绍的相关数据项值来赋值,如果相关数据项中至少6项有值,则赋值为1,否则赋值为0;
(3)标签:标签在微博用户相似度分析、博文推荐、影响力研究等领域都有较重要的作用,用户添加标签的个数反映了用户兴趣领域的深度或广度,同地区数据类似,考虑后续分析中数据维过于分散的问题,以用户标签个数作为参考值。
此外,在获取的用户数据中,有一部分数据存在数据缺失的情况,可直接删除。
在本实验中,共从爬盟获取了2 021个.csv格式的用户数据文件,包括用户数据共3 583 677条,在预处理过程中,删除了不完整数据共126 097条,最后获得3 457 580条用户数据为后续分析使用。
2 预测分析的方法及过程
用户微博发表意向可以看作是一个回归预测问题,以用户发表的微博数作为输出,以除了用户ID之外的其他数据项作为高维输入。即:
X= {[自我介绍,关注数,粉丝数,标签数,是否VIP,是否会员,是否达人,等级]}
Y={微博数}
F(X)→Y的映射关系即为回归预测模型,需要通过实验确定。在Python的scikit-learn包[8]中,包含了多个回归预测模型,因此可以直接使用scikit-learn包中的模型,通过输入用户相关数据,估计用户发表微博数。通过模型评价选取其中最合适的一个或多个模型。
线性回归模型是回归分析中最基本、最简单的模型,其模型预测能力的评价结果体现了X和Y满足线性关系的程度;随机梯度下降回归模型采用随机梯度下降参数估计算法,适用于输入数据较多的回归预测,可以看作是线性回归模型的有力补充。
K近邻回归模型和回归树模型虽然能够较好地解决非线性数据的建模问题,但是当数据量过大时,其训练效率低下。因此,综合考虑模型的可用性和实现效率,采用集成模型中常用的随机森林回归模型、梯度提升回归模型和极端随机森林回归模型作为参与比较的模型。
选取了以下模型进行对比分析:
(1)线性回归模型(Linear Regression);
(2)随机梯度下降回归模型(SGDR egressor);
(3)随机森林回归模型(Random Forest Regressor);
(4)梯度提升回归模型(Gradient Boosting Regressor);
(5)极端随机森林回归模型(Extra Trees Regressor)。
在建立模型的过程中,首先对获得的用户数据进行分割和规范化处理,然后用训练集数据训练各模型的参数,最后使用测试集数据,用R-square评价函数进行模型能力评价,其函数定义见式(1)。
其中:n为用户数据的条数;yi为第i个用户实际发表的微博数;为第i个用户发表微博数的预测值;为用户发表微博数的平均值。
R-square评价函数既考虑了预测值的内部差异,也考虑了预测值与真实值之间的回归差异,其数值表明模型回归结果可被真实值验证的百分比。
3 回归模型的预测能力分析
确定回归模型预测能力的实验基于经过预处理的所有用户数据进行,首先对这些数据进行分割,选择其中90%的数据作为训练集,10%的数据作为测试集,并使用随机数种子35进行随机分割。分割之后的数据提供给5个回归模型训练模型参数,使用R-square评价函数评价模型预测能力。
此外,在所有采集的3 457 580条用户数据中,存在发表微博数为0的数据。为确定发表的微博数为0对模型是否有影响,以及影响程度,在对所有数据执行回归分析后,排除了其中发表微博数为0的数据,以剩下的2 882 839条数据再次进行实验。两种情况下各种模型的预测能力比较见表1所列。
从表1的实验结果可以看出,两种线性模型(线性回归模型和随机梯度下降回归模型)对用户微博发表意向的预测能力均较差。在集成模型中,随机森林回归模型和梯度提升回归模型的预测能力较强,而极端随机森林回归模型在包含微博数为0和不包含微博数为0的情况时,预测能力差异较大。
数据中是否包含微博数为0的数据对模型预测能力的影响并不明显,但倘若不包含微博数为0的数据,模型能够得到更好的预测结果。
各种模型的R-square评价函数值最高为0.486 783 374 421,说明模型预测能力差强人意。一个可能的原因是:微博发表的数量一定为整数,而回归预测模型的预测结果为实数,影响了评价函数的计算结果。
4 各数据项贡献度分析
对3种集成回归模型(随机森林回归模型、梯度提升回归模型和极端随机森林回归模型)做进一步分析,可以得到输入的各数据项对模型的贡献度,进而确定哪些数据项对模型预测能力有决定性作用。
使用3种集成模型,包含微博数为0的数据时,各数据项贡献度见表2所列。
使用3种集成模型,不包含微博数为0的数据时,各数据项贡献度见表3所列。
综合表2与表3的结果可以看出,“是否会员”数据项对模型贡献度为0;“是否VIP”“是否达人”数据项对模型贡献度约等于0。对模型贡献度最大的是“粉丝数”和“关注数”,除了用包含微博数为0的数据训练的梯度提升回归模型之外,其他模型中,“关注数”的贡献度均大于“粉丝数”,即关注其他用户越多的用户,发表微博的热情越高;而不是粉丝越多的用户,发表微博的热情越高。
5 数据分割对预测能力的影响
集成模型得到的回归模型并不是确定不变的,使用不同的训练集或者在模型训练过程中选取的随机值不同,都会对模型的参数造成影响,从而影响模型的预测效果。因此,在后续实验中,采用不同的随机数种子多次分割数据,训练3种集成模型并评价其性能,可更全面地说明模型的预测能力。
在实验中,从[0,100]之间随机选取随机数种子,作为Python中train_test_split()函数的参数,得到不同训练集情况下,3种集成回归模型的R-square值变化趋势如图1所示。
从图1可以看出,排除少数孤立值,随机森林回归模型和梯度提升回归模型的R-square值均在0.4~0.5之间变化,且梯度提升回归模型的R-square值变化更集中,在预测微博发表意向时表现更加稳定,而极端随机森林回归模型受测试集数据影响较大,其R-square值主要在0.35~0.5之间浮动。
6 结 语
综合以上实验研究可以发现,关注数、粉丝数是用户微博发表意向预测模型的主要特征项,特征贡献度最高的是用户关注数,即关注其他用户越多的用户,越有可能发表新的微博。在各种回归预测模型中,3种集成回归模型(随机森林回归模型、梯度提升回归模型和极端随机森林回归模型)具有更好的模型预测能力。当训练集变化时,梯度提升回归模型表现最稳定。但是,各种回归预测模型的预测能力都不尽如人意,一个可能的原因是:回归预测模型的结果为实数,而微博发表数据为整数。模型的适应性以及如何提高模型预测能力还需要今后进一步的研究和探讨。
参考文献
[1]王慧.微博舆论的传播特征及社会影响[J].合肥学院学报(综合版),2017,34(4):65-68.
[2]张露晨,张良,孙昊良,等.基于领域文法的微博舆情分析方法及其应用[J].计算机应用与软件,2016,33(8):43-49.
[3]邹永潘,李伟,王儒敬.基于多特征的垃圾微博检测方法[J].计算机系统应用,2017,26(10):184-189.
[4]刘巧玲,李劲,肖人彬.基于参数反演的网络舆情传播趋势预测——以新浪微博為例[J].计算机应用,2017,37(5):1419-1423.
[5]李文娟. 基于灰色模型的微博舆情预测研究[J]. 开封教育学院学报,2017,37(1):280-282.
[6]张明旺. 基于微博的网络舆情监测与引导机制探索[J].电脑知识与技术,2015,11(31):32-34.
[7]中国爬盟[DB/OL].http://www.cnpameng.com/
[8] Scikit-learn: machine learning in Python[DB/OL].http:// scikit-learn.org/
