
基于高斯核函数的K—means聚类在分布式下的优化
2018-05-15 08:31赵明明张桂芸潘冬宁王蕊
软件导刊 2018年4期
关键词:分布式
赵明明 张桂芸 潘冬宁 王蕊

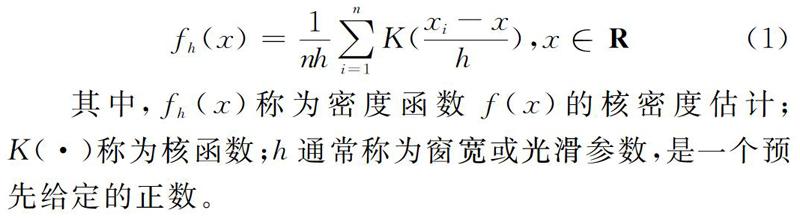
摘 要:随着如今数据量的爆发式增长,传统的数据挖掘方法已经远远不能满足人们需求,K-means聚类作为一种经典的聚类算法,其应用领域很广。但是K-means算法在随机选取初始聚类K个中心时,容易使聚类结果不稳定,因此提出基于核函数的K-means聚类算法。与此同时,结合MapReduce分布式框架对改进后的K-means聚类算法作分布式计算。研究结果表明,基于高斯核函数的K-means聚类在分布式下的计算能够加速K-means聚类过程,且结果优于单独基于核密度估计的K-means算法。
关键词:高斯核函数;K-means聚类;核密度;分布式
DOI:10.11907/rjdk.172480
中图分类号:TP312
文献标识码:A 文章编号:1672-7800(2018)004-0064-03
Abstract:With the explosive increase of data, the traditional data mining has been far from being enough to meeting the needs of people. K-means clustering is a classical clustering algorithm, and its application field is very extensive. However, when the K-means algorithm randomly selects the initial clustering K centers, it is easy to make the clustering results unstable. Therefore, this paper proposes a K-means clustering algorithm based on kernel function. In this paper, the MapReduce distributed framework is used to do the distributed calculation of the improved K-means clustering algorithm. The results show that K-means clustering based on Gaussian kernel function can accelerate the process of K-means clustering in distributed calculation, and the result is better than K-means algorithm solely based on kernel density estimation.
Key Words:Gaussian kernel function; K-means clustering; distributed
0 引言
随着科技的迅速发展,在工业、商业、医疗、工程、航天等各个领域产生了大量数据,数据规模已经从先前的GB上升到TB、PB乃至EB和ZB。据统计,在2020年全世界的数据规模将达到40ZB,相当于平均每人拥有5 247G的数据。因此,如何处理和管理如此庞大的数据是一项相当艰巨的任务,在数据量日益暴涨的场景下对客户的精准推荐服务也面临着严峻考验。为了能够从数据中获取有价值的信息,各公司开始对庞大的数据进行挖掘与分析。
K-means聚类算法是数据挖掘领域最重要的经典算法之一,与其它数据挖掘方法相比,聚类不需要先验知识即可完成数据的分类。聚类算法可以分为基于划分、密度、模型等多种类型[1]。然而在面对大规模数据时,K-means算法表现不够理想,并且在初选K值时非常困难。针对K-means的聚类数目K值难以确定和高维大数据集上的运算效率问题,本文设计了一种新型聚类算法,并且提出一种基于高斯核函数的K-means聚类在分布式下的优化算法。核函数估计又称为核密度估计(Kernel Density Estimate,KDE),是一种非参数估计方法,不需要预知数据集分布,是一种在未知数据集分布情况下进行聚类的有效方法。因此,可以采用核函数估计的方法处理高维度数据。另外Hadoop上的MapReduce框架能够快速、准确、高效地处理大量数据,所以采用MapReduce框架又可以解决在单机上运行效率低的问题。本文提出将建立好的模型运用在MapReduce分布式框架下运行。实验结果表明,该方法在不影响聚类结果的情况下,有效缩短了聚类过程所需的时间。
1 核函数估计
在给定样本集合求解随机变量的分布密度函数时会经常用到两种估计,分别是参数估计和非參数估计。由于参数模型的缺陷,Rosenblatt和Parzen提出了非参数估计方法,即核密度估计方法。由于核密度估计方法不利用有关数据分布的先验知识,对数据分布不附加任何假定,是一种从数据样本本身出发研究数据分布特征的方法,因而在统计学理论和应用领域均受到高度重视[2]。
总体而言,核函数就是将输入空间映射到高维的特征空间,然后再在高维的数据空间进行数据处理。这种映射是非线性变换的,才能将输入空间映射出不同特征的高维空间。
其中,fh(x)称为密度函数f(x)的核密度估计;K(·)称为核函数;h通常称为窗宽或光滑参数,是一个预先给定的正数。
通过以上定义可以得出,分布密度函数的核密度估计f不仅与给定的数据样本集有关,还与核函数的选择与窗宽参数h的选择有关[3]。理论上而言,窗宽h随着n的增大而减小,即当n趋近于∞时,h趋近于0。如果h取值较大,然后x经过压缩变换xi-xh后,突出了平均化,密度细节则会被淹没,使估计出来的密度曲线过于平稳,导致结果分辨率过低;如果窗宽h值太小,随机性的影响则会变大,从而形成一种非常不规则的曲线,导致密度的重要特性不会凸显出来,最终造成密度估计波动性大,稳定性不好。所以要选择一个合适的窗宽h值[4]。
如图1所示,采用不同的窗宽h值进行核密度估计,h=2时曲线较为光滑,h=0.05时,对应的核密度估计曲线上下波动较为频繁,并且这两条曲线与真实曲线相差甚远。图中的虚线是实际概率密度曲线。在h=2与h=0.05之间取h=0.337,对应的KDE密度曲线更接近于实际概率密度函数曲线。
为了解决窗宽h的选取问题,需要引入积分均方误差的概念。积分均方误差可以判断估计所得的概率密度函数(x)和真实概率密度函数f(x)存在的差异,其表达式为:
2 MapReduce
由于 Hadoop 没有针对迭代计算作特殊优化,因此利用 Hadoop 的核心算法 MapReduce 进行K-means迭代设计[5],将原有串行算法中每一次迭代计算过程对应一次MapReduce计算过程,以此完成数据点到邻近簇中心的距离,然后把每一次迭代过程封装成一个MapReduce作业K-meansJob。为了得到更优的聚类效果,需要创建多个K-meansJob。
图2描述了基于高斯核函数估计的K-means聚类并行化计算流程:从HDFS上读取数据集后进行高斯核密度估计,获取数据集密度分布;然后由密度分布设定密度阈值和半径阈值,由这两个阈值获取K值和初始聚类中心;把K值作为初始值输入,然后启动K-meansJob,每一次聚类都包括Map和Reduce两部分,每个Reduce汇总一个簇的数据点集,然后计算更新该簇的中心点;每一次聚类结束后,都根据当前结果判断是否收敛;如果聚类结果没有满足收敛条件,则Hadoop会再次创建K-meansJob,把上一次的输出结果作为本次输入;重复执行聚类任务,直到聚类结果满足最大迭代次数或收敛条件为止。
3 实验结果分析
本次实验在经典K-means算法和本文算法上各实验50次,每10次为一组求平均值,得出5组平均值。在经典K-means中对初始值非常敏感,并且迭代次数较多。然而本文算法先进行高斯核密度估计,然后再进行K-means聚类,这样不用赋初始K值,并且移植到MapReduce分布式框架下的运行效率也大大提高。通过表1可以看出,本文算法相比于经典K-means算法,迭代次数少,误差率低,运行结果的正确率也更高。
4 结语
针对传统K-means聚类算法的初始K值选取困难,且对于高维大数据的聚类效果不太明显,以及在传统K-means有时会形成局部最优,而非全局最优的缺点,本文采用基于高斯核函数密度估计的方法在Hadoop平台下进行K-means聚类。实验结果显示,本文算法明显优于传统的K-means聚类算法,并且运算效率也优于单机下运行高斯核密度估计的K-means聚类。
参考文献:
[1] 翟东海,鱼江,高飞,等.最大距离法选取初始聚类中心的K-means文本聚类算法的研究[J].计算机应用研究,2014,31(3):713-715,719.
[2] ROSENBLATT M. Remarks on some nonparametric estimates of a density function [J]. The Annals of Mathematical Statistics,1956,27(3):832-837.
[3] JONES M C, MARRON J S, SHEATHER S J. A brief survey of bandwidth selection for density estimation [J]. Journal of the American Statistical Association,1996,3(433):401-407.
[4] 杨茹.核函数的密度估计算法[D].哈尔滨:哈尔滨理工大学,2016.
[5] 江小平,李成华,向文,等.K-means 聚类算法的MapReduce并行化实现[J].华中科技大学学报:自然科学版,2011, 39(1):120-124.
[6] 熊开玲,彭俊杰,杨晓飞,等.基于核密度估计的K-means聚类优化[J].计算机技术与发展,2017,27(2):1-5.
[7] 雷小鋒,谢昆青,林帆,等.一种基于K-means局部最优性的高效聚类算法[J].软件学报,2008,19(7):1683-1692.
[8] 谢娟英,高红超.基于统计相关性与K-means的区分基因子集选择算法[J].软件学报,2014,25(9):2050-2075.
[9] MACQUEEN J B. Some methods for classification and analysis of multivariate observation [C].Proceedings of 5th Berkeley symposium on mathematical statistics and probability. California: University of California Press,1967:281-297.
[10] DUDOIT S,FRIDLY J.A prediction-based resampling method for estimating the number of clusters in a dataset [J]. Genome Biology,2002,3(7):1-21.
[11] BUCH-LARSEN T, NIELSEN J P, GUILLEN M. Kernel density estimation for heavy-tailed distributions using the champernowne transformation[J]. Statistics,2005,39(6):503-518.
[12] RASHMI C. Analysis of different approaches of parallel block processing for K-Means clustering algorithm[J]. Computer Science,2017.
[13] NIU B, DUAN Q, LIU J, et al. A population-based clustering technique using particle swarm optimization and k-means[J]. Natural Computing,2017,16:45-59.
(责任编辑:黄 健)
猜你喜欢
湖南电力(2022年3期)2022-07-07
制导与引信(2017年3期)2017-11-02
通信电源技术(2016年6期)2016-04-20
通信电源技术(2016年5期)2016-03-22
雷达与对抗(2015年3期)2015-12-09
自动化博览(2014年12期)2014-02-28
汽车电器(2014年5期)2014-02-28
智能系统学报(2011年4期)2011-02-17
