
从Alpha go看大数据背景下图书馆智能化发展
2018-05-14 10:51俞鹏
中国民族博览 2018年1期
俞鹏
【摘要】智能围棋软件Alpha-go与围棋九段李世石的人机大战将人工智能带入我们的视野,为图书馆大数据挖掘、大数据分析、图书物联网提供了新的解决方案,未来图书馆服务的提供将从人力向人力与计算机分工合作的方向发展,在保证服务数量的同时提高服务准度和精度。
【关键词】alphago;人工智能;大数据;数据挖掘;数据分析;智能算法
【中图分类号】G251 【文献标识码】A
2016年3月的一场人机世纪之战,将Alpha-go这个名字带入到世人的眼中,也将人工智能的火热程度推向了一个新的高度,深度学习网络(CNN)、蒙特卡罗搜索树(MCTS)这些计算机领域的专业技术进入了图书馆人的视野,为图书馆智能化服务发展提供了一条可行的道路。
一、图书馆大数据发展现状及不足
图书馆目前的大数据工作主要集中在两个层面:收集层面和应用层面。收集层面有以下3个方面:一是依赖图书管理系统的读者基本信息的数据收集;二是依赖图书管理系统的读者行为记录的收集;三是依赖网站、微信、APP的读者行为记录的收集;四是文献资源的数字化。应用层面有两个方面:一是依赖图书管理系统的数据统计和分析;二是由读者实时流量、图书借阅排行榜、借阅分类排行榜、周期统计等数据组成的数据大屏等。
就目前图书馆大数据发展的状况而言存在以下三个不足:
(一)读者基本信息的数据收集不足
以汇文系统读者注册为例(如图1所示),读者信息包括姓名、性别、身份证号、职业、职称、专业、电话、移动电话等,系统所规定的基本信息已经很完整。但关键在于很多图书馆在读者注册时没有将信息填写完整,一般只填姓名、身份证号、移动电话等,有的连性别、职业都没有填写。这样就造成了图书馆拥有大量的读者,可没有足够的读者信息,无法对读者进行聚类分析和关联度挖掘。
(二)读者行为信息的数据收集不足
目前大部分图书馆对读者行为信息的收集还主要是收集读者的借阅行为信息。但是有很多更为重要的行为信息被资源供应商掌握在手中,如什么读者在什么时间下载过什么论文、阅读过哪些绘本、观看过哪些视频,这些行为数据全部掌握在资源商的手中。同时,随着科技的发展,新技术为我们提供了更多的行为信息收集手段来,如读者在哪类书架前停留了多长时间、读者在OPAC里搜索过什么词条等等。因为没有足够的行为信息,我们对读者的借阅行为还原度不足,分析素材不全。
(三)资源的数据标引不足
在这里我说的数据不足主要有三点:一是MARC数据的标引在数据分析领域的应用缺陷。这么多年来,我们图书馆一直在很注重纸质图书的书目数据,每个图书馆都形成了一大批MARC数据,但对于书的内容,我们只是按照中图法进行了分类,但同类书中内容的好与坏、内容的涉及面以及面对不同读者产生的阅读观感都是不同的,所以现有MARC数据没有办法对很好的满足在阅读分析时的一个图书定位分析需求;二是電子资源的数据标引不足。现在读者的需求不仅仅局限在图书、期刊、报纸,网页、视频、图片等资源也进入到了读者需求的范围,但对于这方面的电子资源数据标引很多的图书馆还是一片空白;三是不同资源类型之间的数据挖掘不足,没有很好地建立一个数据体系架构,没有办法提供给图书馆工作人员进行数据分析。
(四)图书馆数据的智能分析方法不足
这么多年来,我们一直在说读者借阅行为分析、借阅行为预测、阅读倾向分析、阅读倾向预测,但我们的数据分析大多还只停留在统计分析层面,只是拿出数据进行对比、类比、环比,这只是分析的一个初级阶段或者是统计阶段,预测一下来馆人流量的走向、排一下借阅排行榜等,最大的问题在于我们没有引入当下比较行之有效的智能算法,还没有一套完整的图书馆数据分析评价体系。
二、Alpha-go工作原理
从图2中,我们不难看出Alpha-god其实包含两个阶段:一是线下学习,二是在线对弈。
线下学习又分三个阶段:一是通过专业棋手的3万多幅对局棋谱的全局特征和深度卷积网络来训练策略网络,用局部特征和线性模型快速走棋策略网络;二是利用第t轮的策略网络与先前训练好的策略网络互相对弈,利用增强式学习来修正第t轮的策略网络的参数,最终得到增强的策略网络;三是先利用普通的策略网络来生成棋局的前U-1步,然后利用随机采样来决定第U步的位置(这是为了增加棋的多样性,防止过拟合)。随后,利用增强的策略网络来完成后面的自我对弈过程,直至棋局结束分出胜负。此后,第U步的盘面作为特征输入,胜负作为label,学习一个价值网络(Value Network),用于判断结果的输赢概率[1]。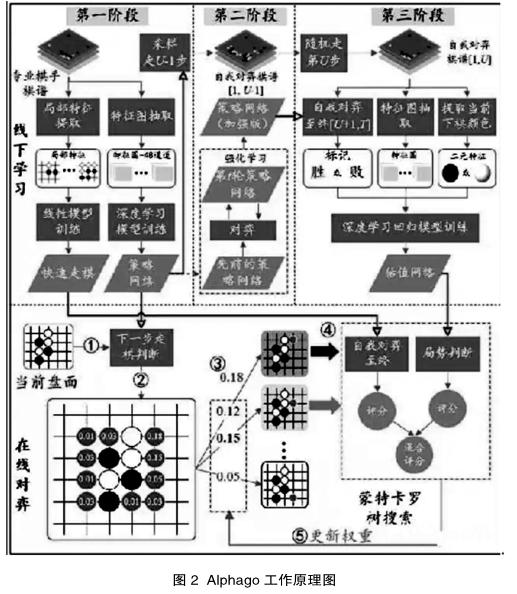
在线对弈包含五个步骤:深度神经网络引入到蒙特卡罗搜索树(MCTS)中,以压缩搜索范围。一是根据当前盘面情况提取相应特征;二是利用策略网络估计出棋盘其他空地的落子概率;三是根据落子概率来计算此处往下发展的权重;四是利用价值网络和快速走棋网络分别判断局势,两个局势得分相加为此处最后走棋获胜的得分。五是利用第四步计算的得分来更新之前那个走棋位置的权重,当某节点的被访问次数超过了阈值,则在蒙特卡罗树上进一步展开下一级别的搜索。
三、图书馆大数据服务模型
从上面的Alpha-go的原理与图书馆大数据服务模式相比还是有很大的区别的:
(一)规则体系明确程度不同
围棋有明确的规则体系,这个规则体系让电脑在走每一步棋之前可以有一个具体的预判。而图书馆数据分析没有明确的规划体系,书、报、视频等资源在被读者获取前没有明确预判。但相反,电脑判断每一步棋的真实好坏要在很多步之后,而资源在到达读者手上之后便可立即评判这个资源是不是符合读者要求。
(二)预测方向复杂程度不同
围棋一共有361个点,则围棋下一步可能性的极限值是361个,而资源单从分类来说,以图书分类来说就远远高出这361种可能性;另外,可能性的层级不同,围棋每一步只有361种可能性,但资源借阅就比这个更复杂。以书为例,除了不同分类的可能性,还有相同类下不同作者的可能性以及相同作者不同书的可能性等等。
(三)外延支撑不相同
Alpha-go的外延支撑相对简单,专业棋手的3万多幅对局棋谱,但对于图书馆的大数据服务模型来说,除了对读者行为数据要进行线下学习外,还要针对读者信息数据进行数据挖掘建立读者关联模型,针对资源建立大数据资源描述模型,这三个模式要相互适应。
读者基本信息的数据收集不足。综上可见,我们可以借用Alpha-go的原理,但要对Alpha-go进行模型改造,首先要解决先天的不足。
读者基本信息的数据收集不足。这个不足其实很简单,建设统一认证系统的同时与市民卡中心或者移动公司合作,通过第三方机构的用户信息来完美自己的信息不足。
读者行为信息的数据收集不足有两种方式解决。一是要求资源商开放用户原数据或者访问日志,再进行数据或日志的分析集成;二是在建立统一认证平台的基础上建立统一访问平台,将资源统一集成到访问平台上,实现统一检索统一访问,行为数据由图书馆后台记录。
资源的数据标引不足。这项相对较难,目前的文献资源标引体系没有办法揭示关联数据和提供有效的评价信息,需要自上而下地对标引体系进行改革,当然,有一个更好的方法是引入评论分析体系,如引入豆瓣的书评[2]、各大网站的相关评论进行分析,辅助建立分析体系。
图书馆数据的智能分析方法不足。目前对于图书馆数据分析的研究尚显不足,但其他领域的智能分析已经开展了很多,也有很多已经成型的我们可以借鉴的智能模型,这里就不多赘述。
(四)图书馆大数据服务模型[3]
从上文我们不难看出,图书馆智能服务模型(如图3所示)共有三个阶段: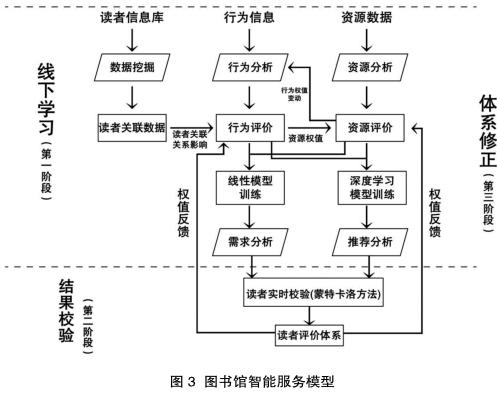
第一阶段有三个体系:读者内联分析体系,主要挖掘读者之间的内在联系,揭示读者的相互影响度;读者行为分析体系,主要分析读者借阅行为,形成读者行為的初步预测,同时对资源分析体系中的资源权值进行反馈[4];资源分析体系,对资源进行合理评分,同时对读者行为分析体系中对行为权值进行反馈;将读者内联分析体系和资源分析体系分别纳入线性模型训练和深度学习模型训练,分别形成读者需求分析预测和推荐分析预测[5]。
第二阶段预测校验:读者需求分析预测和推荐分析预测进入阅读推荐模型,根据读者的搜索进行优先推荐,根据读者的选择情况进行预测判断的评价,同时,评价反馈给读者行为分析体系和资源分析体系,对行为权值和资源权值进行修正。
第三阶段体系修正:将第二步新的权值带入第一阶段的三个体系中进行再次的体系修正和权值更新[6]。
这样的服务模型可以依据以往数据建立一个自适应的智能服务模式,并可以根据实时情况对预测体系进行权值更新修正,保证预测的准确率。
Alpha-go将人工智能带入到我们图书馆人的视野中,我们通过Alpha-go了解到了深度学习网络(CNN),了解到了蒙特卡罗搜索树(MCTS),通过进一步学习,让我们了解人工智能,了解到智能算法,其实我们可以在服务的过程中更多地引入当下主流的、行之有效的智能算法,如粒子群算法、鱼群算法、蚁群算法和神经网络算法等,当然我们不是都要用这些算法,只需要选择其中合适的算法来构建适合我们的方式和策略。
参考文献:
[1]郑宇,张钧波.http://www.thebigdata.cn/YeJieDongTai/29392. html,一张图解AlphaGo原理及弱点,2016(3):16.
[2]严志永.基于豆瓣笔记的纸质书读者阅读行为研究[J].科技与出版,2016(4).
[3]何都益. 融合人工智能的图书馆资源建设问题反思[J].科技情报开发与经济,2011(11).
[4]陈臣.基于大数据的图书馆个性化服务用户行为分析研究[J].图书馆工作与研究,201(2).
[5]吴凯,季新生,刘彩霞.基于行为预测的微博网络信息传播建模[J].计算机应用研究,2013(6).
[6]陈爱军.高校馆藏文献资源的质量评价[J].图书馆学研究,2009(11).
猜你喜欢
速读·下旬(2016年8期)2017-05-09
电子技术与软件工程(2016年24期)2017-02-23
价值工程(2016年32期)2016-12-20
电脑知识与技术(2016年24期)2016-11-14
中国市场(2016年36期)2016-10-19
商场现代化(2016年22期)2016-10-18
哈尔滨理工大学学报(2016年2期)2016-09-12
电脑知识与技术(2016年8期)2016-05-19
物联网技术(2015年11期)2015-11-26
计算机教育(2006年9期)2006-09-22
