
改进的卷积神经网络关系分类方法研究*
2018-05-09 08:49肖卫东
计算机与生活 2018年5期
李 博,赵 翔,王 帅,葛 斌,肖卫东
1.国防科学技术大学 信息系统与管理学院,长沙 410072
2.地球空间信息技术协同创新中心,武汉 430079
1 引言
近年来,大规模知识库在自然语言处理、网页搜索和自动问答等方面得到广泛应用,典型的大规模知识库包括Freebase、DBpedia和YAGO等,这些知识库的核心是大量形如“(Mark Zuckerberg,founder of,Facebook)”的事实关系元组。目前这些知识库还远不能准确描述真实世界中的海量知识。为进一步丰富现有知识库,新近的研究希望通过机器学习的自动化方法来提升知识库的体量,尤其是增加事实关系的数量。这个过程称作关系抽取,即从无格式文本中识别并生成实体之间的语义关系。例如,输入文本“Financial stress1)粗体表示语句中已事先标注的实体。is one of the main causes of divorce.”,其中已标注实体e1=“stress”和e2=“divorce”,关系分类任务将自动识别实体e1和e2之间存在Cause-Effect关系,并表示为Cause-Effect(e1,e2)。
当前,实现关系抽取的主流方法是进行关系分类。在上述例子中,两实体对应的谓语和目标关系联系紧密,易于识别和区分;但在实际中,描述同一种关系的表达方式往往各式各样,这些在词义句法,甚至语境上的不同给正确关系分类带来了巨大的困难和挑战。一个符合直觉的想法是,不仅利用每个词的意思,而且考虑单个词(word)与句字(sentence)句法相结合。因此,已有研究提出了许多基于核(kernel)的方法,利用自然语言处理工具提取特征,包括 POS(part-of-speech)标签、NER(named entity recognition)标签、依赖分析树和组成分析等。
随着深度学习技术的发展,有研究主张不手动设计特征或者利用外部知识,而是直接使用深层神经网络来学习和表示特征。代表性工作包括基于卷积神经网络(convolution neural network,CNN)、循环神经网络(recurrent neural network,RNN)以及其他结合神经网络的方法[1-2]。其中,基于CNN的方法结构简单且效果突出,仅使用包含一个卷积层、池化层和softmax层的网络就能取得与基于RNN和LSTM(long short-term memory)等复杂模型相当的效果。但是,深入研究发现,基于CNN的方法仍存在如下问题:
(1)经常无法发现与关系紧密相关的词。譬如,“We poured the milk,which is made in China,into the mixture.”中既包含“made”又包含“into”,其中“made”与Product-Producer关系紧密相关,“pour”和“into”与Entity-Destination关系联系紧密;CNN倾向于抽取出“made”的高层特征而将“milk”和“mixture”分类为Product-Producer关系,但其实两者之间为Entity-Destination关系。换言之,将实体间的词输入神经网络,当出现从句(clauses)等实体间距较大的样本时,CNN不能正确抽取特征或抽取的特征和实体无关联。
(2)同一句子中实体对按照不同的先后顺序输入神经网络,其分类结果可能不同。例如,在“Financial stress is one of the main causes of divorce.”中,将实体“stress”当作e1,实体“divorce”当作e2,得到结果为Cause-Effect;将“stress”当作e2,“divorce”当作e1,理应得到结果Effect-Cause。但CNN实际分类过程中存在两种结果不对应的情况。
本文试图通过解决上述问题给出一种更好的基于CNN的关系分类方法。针对问题(1),提出利用最短依赖路径对不同词进行选择性注意的机制;针对问题(2),重新定义该问题并提出正向实例和反向实例的概念,综合两者分类的结果以实现最终分类。本文的主要贡献包括:
(1)在经典CNN编码器中添加了选择性注意力层,利用最短依赖路径帮助CNN找到和实体关系联系紧密的关键词并提取特征,提高了处理大间距实体对的效果。
(2)设计了一种新的编码方式来融入依赖结构信息,使CNN编码器能够捕获短距离依赖结构信息。
(3)提出了一种正向和反向实例结合的方法,并且将该方法与带有选择性注意的CNN编码器配合,在SemEval 2010任务8上取得了当前最优的F1值。
本文组织结构如下:第2章介绍关系分类的研究现状,尤其是基于神经网络的方法;第3章介绍模型设计,从改进的CNN句子编码器和正反实例结合两方面进行细致阐述;第4章是模型有效性实验和比较分析;最后总结全文,并讨论下一步工作方向。
2 研究现状
关系分类是一个经典的信息抽取问题,其本质是一个有监督多分类问题,可将现有研究分为如下三类:
(1)基于特征的方法。抽取大量语言学(词义和语法)特征,组合特征形成特征向量并利用各种分类器(例如最大熵模型和支持向量机等)进行分类[3-5]。基于特征的方法在处理特定领域数据或小数据量时效果较好,但其特征集的选择依靠经验和专家知识,需要花费大量时间去设计和完善。
(2)基于核的方法。通过计算两实体在高维稀疏空间上的内积获取结构化特征。Zelenko等人设计的树核利用共同子树的加权和来计算两个浅层分析树的结构共性[6]。Culotta和Sorensen将该树核迁移到依赖树上并添加了额外语法分析信息[7]。Zhou等人则提出了内容感知卷积树核,不仅使用语法解析树,还添加了文本内容信息[8]。该类方法的分类性能很大程度上依赖于基础自然语言处理工具,而基础工具的错误可能会造成最终分类性能的下降;而对于没有完善的基础处理工具的语言,此时该方法不再适用。另外该类方法需要获取语法分析结果,前期数据预处理过程耗费时间。
(3)基于神经网络的方法。通过对每个词进行编码,克服了传统方法的稀疏问题,且能够自动学习特征。在CNN上,Zeng等人提出了一个用softmax层分类的深度卷积神经网络[1],提取词汇和句子级别特征;Santos等人提出了排序CNN模型(classification by ranking CNN,CR-CNN),使用排序层进行分类[2];肜博辉等人提出利用多通道卷积神经网络来获取更丰富的语义信息[9]。在递归神经网络上,Socher等人提出的递归矩阵-矢量模型尝试利用句法树来获取语句组成成分的语义[10];Hashimoto等人提出使用RNN在语义树上提取特征进行分类[11];此外,还有一系列的改进方法,如 Bi-LSTM-RNN[12]和 ATT-BLSTM[13]。Vu等人使用CNN和RNN两个网络进行训练,然后利用投票等方法整合分类结果[14]。相比其他两类方法,基于神经网络的方法不需要人工定义特征,利用神经网络自动抽取特征,迁移性较好,且其关系分类的效果较好。而相比其他神经网络结构,CNN的结构简单,效果突出,但存在没有综合考虑词义和句义的结合,处理大间距分类问题能力差等缺陷;并且现有的研究都忽视了同一句子中实体对按照不同的先后顺序输入神经网络,其分类结果不一致的问题。本文结合原始词序列和依赖树来解决大间距分类问题,并结合两个顺序输入实体综合训练进行关系分类,以简单模型取得良好效果。
3 模型与方法
对于每个句子S,其中包含标注实体e1和e2,关系分类的任务是从一系列候选关系集R={r1,r2,…,rm}中识别出实体e1和e2的语义关系ri。所提模型包含两部分,即在正向和反向实例结合的关系分类框架下,使用带选择性注意力的基于CNN的句子编码器。
(1)SA-CNN句子编码器。输入一个句子和两个目标实体,采用一个带选择性注意力的CNN构建低维实数向量来表示句子。
(2)正向和反向实例结合。当得到句子的正向实例表示和反向实例表示后,同时结合正反实例来选择最合适的关系分类结果。
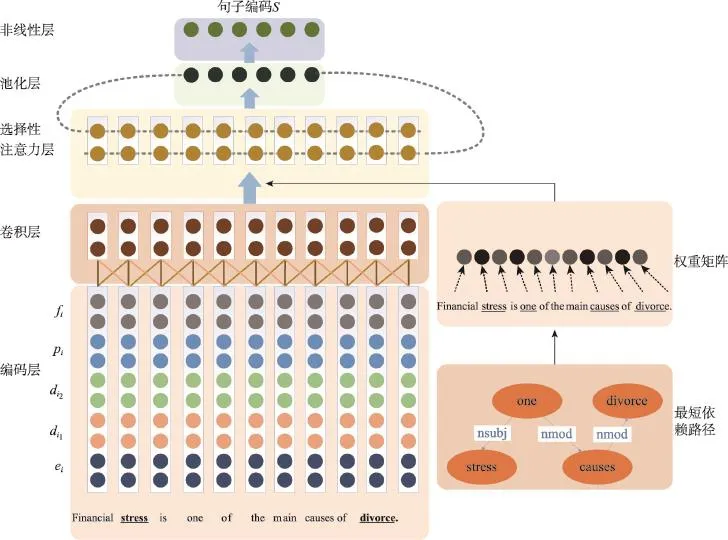
Fig.1 Structure of SA-CNN sentence encoder图1 SA-CNN句子编码器结构
3.1 SA-CNN句子编码器
设计的句子编码器结构如图1所示,称为SA-CNN(selective attention-convolution neural network)。
首先,嵌入(embedding)层将句子中的词转换为低维实数向量,之上的卷积(convolution)层获取每个词的高层特征;接着,通过最短依赖路径找出与两实体语义联系最紧密的词,由权重矩阵表示;然后,通过选择性注意力(selective attention)层提高编码器对关键词注意力;最后,经由池化(pooling)和非线性层构建出句子向量表示,编码后的向量记作s。
3.1.1 输入表示和卷积层
SA-CNN的输入是原始句子文本。CNN只能处理定长输入,因此在输入之前将原始句子填充为长度一致的词序列。这里设置目标长度为数据集最长句子长度n,填充词为“NaN”。
在输入表示层,每个词通过词向量矩阵转换为低维向量。为标识实体位置,给每个词添加位置特征向量;为提高系统对句子依赖结构的理解,还给每个词添加依赖方向向量和依赖特征向量。
(1)词编码。已知一个句子x其包含n个词,表示为x=[x1,x2,…,xn],其中xi表示在该序列中第i个词,n为预先设定的填充截取长度。每个词xi通过查找词向量表W获得其对应词向量表示ei,即ei=Wxi。实验操作中使用预训练的词向量数据。
(2)位置编码。实体在句子中的位置影响实体间的关系。不添加位置特征向量时,CNN将无法识别句中哪个词为实体,导致分类效果差。位置特征向量可以帮助CNN知道每个词到两个关系实体的距离。受文献[1]启发,利用每个词与实体的距离生成位置特征向量。例如,在句子“Financial stress is one of the main causes of divorce.”中,词“main”与实体“stress”距离为5,与实体“divorce”距离为-3。具体地,使用每个词xi与两个实体在句子中的距离i-i1和i-i2对应在位置特征编码表D中的向量作为位置编码,记作。位置特征编码表使用随机值初始化。
(3)依赖编码。基于依赖分析树的依赖编码包括依赖方向向量和依赖特征向量。依赖分析树是对句子结构分析后根据词之间相互依赖关系构成的树,是句义理解的基本工具。如图2所示,在依赖分析树中,每一节点(除根节点)与上级节点之间存在依赖关系,依赖关系不仅包含其上级节点还包括依赖标签。具体地,使用词与上层节点的距离生成依赖方向向量,利用词之间依赖关系的标签生成依赖特征向量。
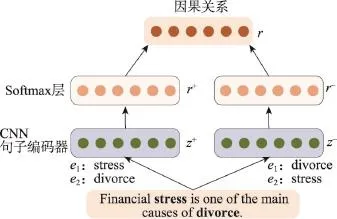
Fig.2 Classification framework of combining forward and backward instances图2 正向和反向实例结合的关系分类框架
借鉴位置编码的方式,利用每个词与上一词的距离dip对应在依赖方向编码表P中的实数向量作为pi,利用依赖标签对应在依赖特征编码表F中的向量作为fi。依赖方向编码表和依赖特征编码表使用随机值初始化。
至此,将每个词的词编码、位置编码和依赖编码串联在一起作为该词的编码表示。对于填充词,设置唯一向量进行标识。具体地,对每一个词,串联词向量ei,与两实体的位置向量di1和di2,依赖方向向量pi和依赖特征向量fi得到该单词的表示向量,即:
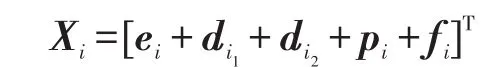
而句子的编码表示则为:
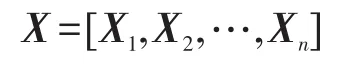
在卷积层,关系分类的最大挑战源自语义表述多样性,重要信息在句中的位置不是固定的。因此,考虑在模型中采用一个卷积层来融合所有局部特征,卷积层通过一个大小为w的滑窗来抽取局部特征。当滑窗在边界附近可能越界,可在句子两边填充零向量来保证卷积后维数不变。
具体地,卷积核为矩阵f=[f1,f2,…,fw],则在卷积之后得到特征序列s=[s1,s2,…,sn],其中:
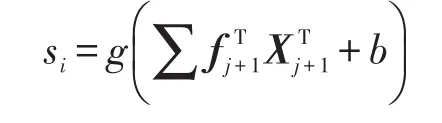
其中,b为偏置项,g是一个非线性函数。使用不同的卷积核和窗口大小可获取不同的特征。
3.1.2 选择性注意力层
经典CNN在卷积过程中对所有词进行无差别特征抽取,然而通过研究发现,每个词对实体关系的贡献度是不同的,有区别地对待可能提升分类效果。已有研究[15]表明,实体间的最短依赖路径直接影响关系分类结果。因此,考虑使用最短依赖路径生成权重矩阵,并通过权重矩阵实现对关键词进行选择性关注。
两实体之间的最短依赖路径定义为该句的依赖分析树中两实体的最短路径,表示了两实体的最短依赖关系;最短依赖路径上的词为关键词。例如,“A thief,who intends to go to the city,broke the ignition with screwdriver.”,在依赖分析树中“thief”和“screw-driver”的最短依赖路径为“thief-nsubj-broke-nmodscrewdriver”。最短依赖路径上词对关系分类影响最大,“thief”和“screwdriver”之间为 Instrument-Agency关系,而关键路径上的“broke”也和该关系联系紧密。该句中还包含“go”,该词和Entity-Destination关系联系紧密。若不考虑关键词对关系分类的影响,很可能会判断为Entity-Destination关系,造成错误分类。
具体地,对关键词和非关键词分别进行加权。由于决定实体间关系的词序列不仅是一个词,将处于关键词附近的词也进行选择性注意。设置关键词权重系数α(α>1)及距离衰减系数β(0<β<1),对于每一单词其权重为qi,由该单词到最短依赖路径上单词的最短距离dq决定,即:
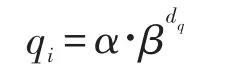
则选择性注意权重矩阵为:
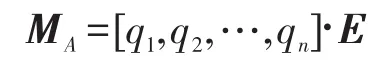
因此,经过该层后的特征矩阵为:
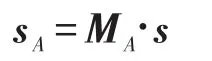
3.1.3 池化和非线性层
在池化层,使用max函数获取最重要特征,则对于每一卷积核其卷积分数为:
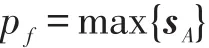
每一卷积核得到的池化分数串联形成,表示该句子的特征向量z=[p1,p2,…,pm],其中m为卷积核数量。
最后,给特征向量加上非线性函数作为输出,该输出即为输入句子的编码表示。
3.2 正向和反向实例结合
已知句子的编码表示,通过一个多层感知器配合一个softmax层即得到关系分类。然而,研究发现,这种分类能导致不同的结果。例如,“Financial stress is one of the main causes of divorce.”中,“stress”与“divorce”有Cause-Effect关系,而“divorce”与“stress”有Effect-Cause关系2)由于关系具有方向性,Cause-Effect关系和Effect-Cause关系非同一类关系。。在SA-CNN句子编码器中,两种顺序情况下实体的位置编码不同,进而造成句子编码不同,但其实两种顺序情况都是表示“stress”与“divorce”间存在Cause-Effect关系。
为此,考虑结合这两种情况来判断实体关系。首先给出两个定义。
定义1(正向实例)给定一个已标注两个实体的句子,根据句中词的前后线性顺序,把对应词在前出现的实体作为e1,另一个实体作为e2的实例,称作正向实例。
定义2(反向实例)给定一个已标注两个实体的句子,根据句中词的前后线性顺序,把对应词在后出现的实体作为e1,另一个实体作为e2的实例,称作反向实例。
譬如,在前述例子中,以“stress”作为e1、“divorce”作为e2的为正向实例,正向实例有Cause-Effect关系;以“divorce”作为e1、“stress”作为e2的为反向实例,反向实例有Effect-Cause关系。研究发现,正向实例的语义关系和反向实例的语义关系是相互对应的。一个优秀的分类系统应确保正向实例和反向实例分类结果亦相互对应,鉴于此,设计了正向和反向实例结合的关系分类框架,如图2所示。
首先,对于任一句子,其正向实例的编码特征向量为,反向实例的编码特征向量为zi-,正向实例关系为,反向实例关系为ri-。由于存在正向实例和反向实例不对应的情况,设置其有ω概率正向实例正确,有1-ω概率反向实例正确。然后,利用交叉熵设计目标函数为:
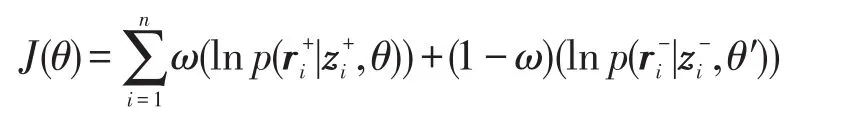
其中,n为句子数量;θ和θ′分别为正向实例和反向实例模型中所有参数。
为解决上述优化问题,使用随机梯度下降法来最小化目标函数。具体地,从训练集中随机选择mini-batch个样本进行训练直到收敛;在测试时,正向实例分类概率向量为C+=[c1,c2,…,cr],反向实例分类概率向量为C-=[c1,c2,…,cr],ci表示该句子中实体e1与e2之间存在关系ri的概率。因此,分类的结果是:
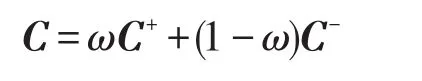
最终,通过最大值反函数i=argmax(C)获取对应的分类结果ri。
4 实验与分析
实验旨在证明:(1)引入依赖分析树能够提高基于CNN的方法在处理大间距关系分类上的效果;(2)正向实例和反向实例结合的分类框架可以改进关系分类效果。首先介绍实验数据集、评价指标和设定的超参数;然后分别测试SA-CNN句子编码器和正向反向实例结合框架的性能和有效性;最后与其他典型方法进行横向对比评测。
4.1 数据集
本文采用了广泛用于关系分类评测的SemEval 2010任务8作为实验数据集,共包括标注好实体位置及实体间关系的10 717个样本,其中8 000个样本为训练集,2 717个样本为测试集,详细分布信息如表1所示。该数据集标注关系包括9种语义关系及Other关系(表示实体间不存在语义关系),9种语义关系分别是Cause-Effect、Component-Whole、Content-Container、Entity-Destination、Entity-Origin、Product-Producer、Member-Collection、Message-Topic和 Instrument-Agency。每个样本仅包含一个句子,且句中已标注两个实体及其关系。在该任务中,不仅需要预测实体间的关系,还需预测关系的方向。因此,实际关系分类系统中共有2×9+1=19种关系。在评价分类结果时,使用9种语义关系的macro-F1值作为评价指标。
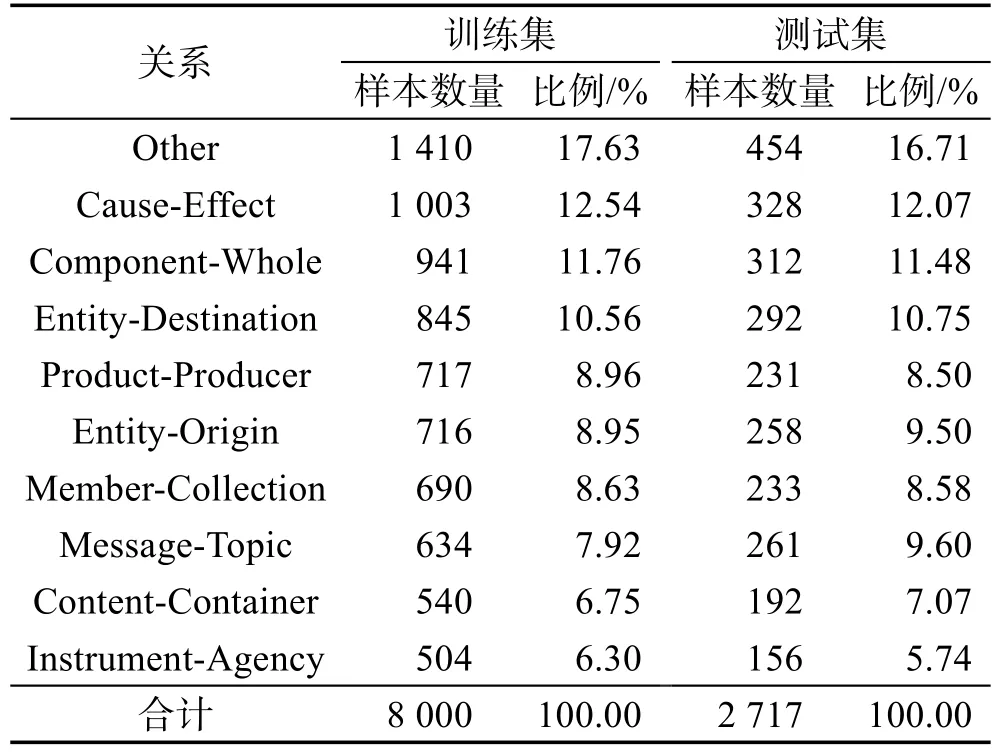
Table 1 Dataset statistics of SemEval 2010 task 8表1 SemEval 2010任务8数据集分布
4.2 基础配置及超参数
词向量编码使用预训练词向量进行初始化,而词向量使用了开源word2vec工具(https://code.google.com/p/word2vec/)对英文维基百科进行训练。对于CNN,采用4折交叉验证方法来调节网络参数,并使用了early stop策略,监控值为验证集loss值。使用tanh函数作为非线性函数,卷积时设置4个滑动窗口,窗口大小分别为2、3、4和5,卷积核数目为256,权重衰减L2的超参数设置为0.4,关键词权重系数α为1.2,距离衰减系数β为0.9。词向量和位置特征向量分别设为300维和40维,依赖方向向量和依赖特征向量均为30维。此外,其他参数与文献[16]中一致,例如dropout设为0.5,mini-batch设为50等。
4.3 实验结果及分析
该组实验以文献[16]中的方法作为基准,实验得到该方法的F1值为82.1%,与原论文中结果相当。
4.3.1 评价SA-CNN句子编码
该组实验中不使用正向实例和反向实例结合框架。实验结果如表2所示,只在词编码过程添加依赖编码,F1值为82.6%;添加了选择性注意力层后,F1值提升到84.1%。

Table 2 Experiment results of SA-CNN sentence encoder表2 SA-CNN句子编码实验结果
由实验结果可见,增加依赖编码提高了系统分类效果。其原因在于,卷积过程中,基准CNN只能抽取基于词序列的高层特征,而改进的模型还能抽取基于依赖关系的高层特征。另一方面,尽管该种依赖编码的方式已经将全部依赖树信息编码为句子表示,但分类效果提升并不显著。通过分析发现,当依赖关系两词位置较近时(处于CNN滑窗之内),CNN能够抽取该词组内部的依赖结构,而当依赖关系较远,CNN很难抽取其依赖结构。另外,增加选择性注意层能提高分类效果的原因在于,它提高了大间距实体上的分类效果。CNN可能会将有极强关系信号但不是描述两个实体间关系的词抽出作为特征,例如从句中包含“cause”使得CNN很容易判断其为Cause-Effect关系,因而导致关系分类不准确。而改进的模型在抽取特征时,考虑了每一个词与实体的依赖关系,从而减少了此类错误。
为进一步证明设计的句子编码器能更有效地处理大间距实体样本,对比分析了不同距离样本的F1值。首先关注数据集的实体距离(两个实体之间包含词数量)分布,结果如图3所示3由于实体距离大于15的样本较少,本文将距离大于15的样本全部统计为15。)。分别测试了基准系统和基于SA-CNN编码器的分类系统在不同实体距离数据上的F1值。如图4所示:(1)当实体距离超过5时,随着距离增大,基准系统分类准确率显著降低;在距离为14时,F1值为0.83,但此时样本数量仅有9个,分类准确率偶然性较大,不具有代表性。(2)改进的系统相比基准系统显著提高了大间距实体样本的F1值,特别是当距离处于6至12之间时。(3)当实体间距过长时,虽然改进的系统效果减弱,但仍略优于基准系统。其原因在于当句子较长时,句法分析的准确率下降,造成最短依赖路径分析不准确,进而使得效果减弱。
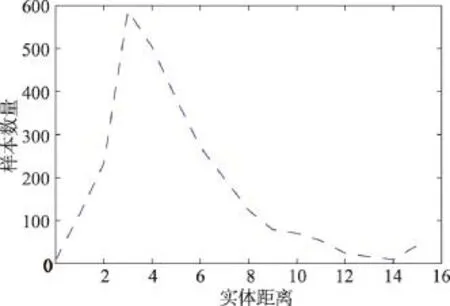
Fig.3 Distance distribution of entities图3 实体距离分布
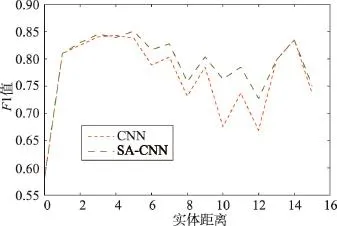
Fig.4 Comparison of classification effect图4 分类效果对比
该组实验说明,SA-CNN句子编码器在处理实体间距较大的样本时,能抽取出更代表两者关系的特征来进行句子表示,从而证明了SA-CNN编码器模型的有效性。
4.3.2 正向反向实例结合实验
在该组实验中不使用依赖特征和选择性注意层,实验结果如表3所示。注意到,在基准系统上添加正向反向实例结合框架使得F1值提高了1.4%。

Table 3 Experiment results of combining forward and backward instances表3 正向反向实例结合对比实验结果
分析原因,主要包括:(1)使用结合反向实例的方法可以避免正向实例和反向实例分类结果不一致的错误分类,使得训练出的模型更具有鲁棒性。如前文所述,基准系统分类时,可能出现实体“stress”和实体“divorce”有Cause-Effect关系,但实体“divorce”和实体“stress”有Component-Whole关系的情况。这种正向实例和反向实例分类结果不对应,也即对一个样本的两种表示分类结果不同,表明其模型不稳健。(2)由于每一样本都包含反向实例,训练集由原始的8 000样本扩大到了16 000样本。因此,结合正向实例和反向实例的分类框架是一个简单却行之有效的改进方案。
4.3.3 与其他方法的对比
将所提两种改进结合,形成本文的方法SA-CNN+FBI(selective attention-convolution neural network+forward and backward instances),并与其他关系分类方法进行横向比较。下列典型方法参与了对比实验。
(1)SVM[4]:该方法通过人工定义和其他工具抽取大量新的特征,通过支持向量机训练来进行分类。
(2)CNN[1]:该方法使用CNN学习句子中词的词向量表示,将词表示串联形成句子表示。为了输入实体位置信息,使用了一个特殊的位置向量来表示每一单词距离实体的距离,并且将该位置向量和词向量结合构成单词特征向量,然后通过CNN学习每个句子的特征表示,最后输入softmax分类器。
(3)CR-CNN[2]:该方法关注于人工定义的Other关系对实验的影响,通过重新定义排序损失函数,在CNN后使用排序层替换softmax层,提高分类效果。
(4)depLCNN+NS[17]:该方法在反向监督的框架下,使用实体间的最短依赖路径作为输入,通过CNN学习其编码表示,然后输入softmax分类器进行分类。
(5)MV-RNN[10]:该方法为了获取长短语的编码表示,通过RNN由每个词的向量表示构成词块编码表示和句子编码表示,然后通过分类器进行分类。
(6)Bi-LSTM-RNN[12]:该方法依据两个实体将句子分为5部分作为序列特征,通过双向LSTM和RNN进行关系分类。
(7)ATT-BLSTM[13]:该方法在双向LSTM上添加注意力层,提高分类系统对关键部分词的注意力。
在结合正向和反向实例关系分类框架下,使用带有选择性注意的卷积神经网络,并且添加依赖方向向量和依赖特征向量,SA-CNN+FBI在SemEval 2010任务8数据集上F1值为85.8%。如表4所示,SA-CNN+FBI的结果达到了当前的最优效果;与SA-CNN+FBI结果最接近的是depLCNN+NS方法,因为它不仅考虑了关系的方向性,并且还添加了WordNet特征。同时还注意到,经典CNN以十分简单的网络结果就取得了良好的初始分类效果,这也是SA-CNN+FBI选择CNN作为基础开展改进研究的原因。
5 结束语
本文针对现有基于CNN的关系分类方法难以处理包含大间距实体样本的问题,提出了利用实体间的最短依赖路径构建选择性注意权重,对关键词进行选择性注意的SA-CNN句子编码器。在此基础上,针对现有方法难于解决句中正反实例分类结果不一致的问题,设计了一种将正向实例与反向实例结合进行关系分类的框架。在公开数据集上,对比验证了所提模型SA-CNN+FBI的效果,其在SemEval 2010任务8数据集上获得了当前最优结果。实验证明,SACNN+FBI在维持模型结构简单性的同时,不需要提供额外的人工特征即可取得优秀的性能。注意到,这种依赖树与输入词序列相结合的方法,其实质是利用CNN捕捉句子的词义和句义两方面的特征,因而能提高模型对句子的理解能力。在下一步工作中,将探索该模型在其他自然语言处理任务中的应用,例如情感分类和文本分类等。
[1]Zeng Daojian,Liu Kang,Lai Siwei,et al.Relation classification via convolutional deep neural network[C]//Proceedings of the 25th International Conference on Computational Linguistics,Dublin,Aug 23-29,2014.Stroudsburg:ACL,2014:2335-2344.
[2]Santos C N,Xiang Bing,Zhou Bowen.Classifying relations by ranking with convolutional neural networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing,Beijing,Jul 26-31,2015.Stroudsburg:ACL,2015:626-634.
[3]Kambhatla N.Combining lexical,syntactic,and semantic features with maximum entropy models for extracting relations[C]//Proceedings of the ACL 2004 on Interactive Poster and Demonstration Sessions,Barcelona,Jul 21-26,2004.Stroudsburg:ACL,2004:22.
[4]Rink B,Harabagiu S.UTD:classifying semantic relations by combining lexical and semantic resources[C]//Proceedings of the 5th International Workshop on Semantic Evaluation,Uppsala,Jul 15-16,2010.Stroudsburg:ACL,2010:256-259.
[5]Gan Lixin,Wan Changxuan,Liu Dexi,et al.Chinese named entity relation extraction based on syntactic and semantic features[J].Journal of Computer Research and Development,2016,53(2):284-302.
[6]Zelenko D,Aone C,Richardella A.Kernel methods for relation extraction[J].Journal of Machine Learning Research,2003,3:1083-1106.
[7]Culotta A,Sorensen J S.Dependency tree kernels for relation extraction[C]//Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics,Barcelona,Jul 21-26,2004.Stroudsburg:ACL,2004:423-429.
[8]Zhou Guodong,Zhang Min,Ji Donghong,et al.Tree kernelbased relation extraction with context-sensitive structured parse tree information[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,Prague,Jun 28-30,2007.Stroudsburg:ACL,2007:728-736.
[9]Rong Bohui,Fu Kun,Huang Yu,et al.Relation extraction based on multi-channel convolutional neural network[J].Application Research of Computers,2017,34(3):689-692.
[10]Socher R,Huval B,Manning C D,et al.Semantic compositionality through recursive matrix-vector spaces[C]//Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning,Jeju Island,Jul 12-14,2012.Stroudsburg:ACL,2012:1201-1211.
[11]Hashimoto K,Miwa M,Tsuruoka Y,et al.Simple customization of recursive neural networks for semantic relation classification[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing,Seattle,Oct 18-21,2013.Stroudsburg:ACL,2013:1372-1376.
[12]Li Fei,Zhang Meishan,Fu Guohong,et al.A Bi-LSTMRNN model for relation classification using low-cost sequence features[J/OL].arXiv:1608.07720v1,2016.
[13]Zhou Peng,Shi Wei,Tian Jun,et al.Attention-based bidirectional long short-term memory networks for relation classification[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics,Berlin,Aug 7-12,2016.Stroudsburg:ACL,2016:207-212.
[14]Vu N T,Adel H,Gupta P,et al.Combining recurrent and convolutional neural networks for relation classification[C]//Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies,San Diego,Jun 12-17,2016.Stroudsburg:ACL,2016:534-539.
[15]Kim Y.Convolutional neural networks for sentence classification[C]//Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing,Doha,Oct 25-29,2014.Stroudsburg:ACL,2014:1746-1751.
[16]Nguyen T H,Grishman R.Relation extraction:perspective from convolutional neural networks[C]//Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing,Denver,Jun 5,2015.Stroudsburg:ACL,2015:39-48.
[17]Xu Kun,Feng Yansong,Huang Songfang,et al.Semantic relation classification via convolutional neural networks with simple negative sampling[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing,Lisbon,Sep 17-21,2015.Stroudsburg:ACL,2015:536-540.
附中文参考文献:
[5]甘丽新,万常选,刘德喜,等.基于句法语义特征的中文实体关系抽取[J].计算机研究与发展,2016,53(2):284-302.
[9]肜博辉,付琨,黄宇,等.基于多通道卷积神经网的实体关系抽取[J].计算机应用研究,2017,34(3):689-692.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小学生学习指导(中年级)(2021年12期)2021-12-30
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
