
基于非随机初始种群遗传算法的学习分类器系统
2018-05-02 03:25薛愈洁
计算机时代 2018年3期
关键词:遗传算法
薛愈洁

摘 要: 学习分类器系统能够通过简单位串规则的学习有效地引导个体在一个环境中的行为。通过分析基于遗传算法的学习分类器系统的实现原理,提出一种以规则为基础的分类系统,借助训练数据集来实现类别的精确描述,并以数据挖掘中的基准数据鸢尾花卉数据集作为应用对象,实现学习分类器中的消息与分类器系统匹配、桶队列算法信用分配以及基于遗传算法的规则发现。仿真结果表明,通过学习分类器系统优化后,鸢尾花分类的精度好于单个算法的精度。
关键词: 学习分类器; 遗传算法; 桶队列算法; 鸢尾花分类
中图分类号:TP301 文献标志码:A 文章编号:1006-8228(2018)03-60-03
The learning classifier system based on non-random initial population genetic algorithm
Xue Yujie
(School of Computer Engineering, Taiyuan University, Taiyuan, Shanxi 030001, China)
Abstract: Learning classifier system can guide the individual behavior in a random environment with simple string of rule learning. A classification system based on the rules is proposed by analyzing the architecture of learning classifier system based on genetic algorithm with training data set to improve the accurate of the classification. And the matching of message and classifier in the learning classifier system, the credit allocation in bucket-brigade algorithm and the rule discovery based on genetic algorithm are implemented by using the benchmark data in iris flower dataset. The simulation results show that the accuracy of classification is better than the precision of a single algorithm after learning classifier system optimization.
Key words: learning classifier; genetic algorithm; bucket-brigade algorithm; classification of iris flower
0 引言
分類规则是数据挖掘领域中的重要研究内容,其主要思想是通过分析训练集数据,产生关于类别的精确描述[1-2]。此类别描述通常由分类规则组成,可以对未来的做出进行分析与分类预测,有着广泛的应用前景。
分类规则的数据挖掘[3],主要方法有:决策树法、贝叶斯法、人工神经网络法、遗传算法和粗糙集方法等,在实际应用中,数据集的特征往往复杂多样,需要根据实际情况采取不同的方法进行处理。
遗传算法(GA)是一种寻找最优解的计算方法[4-5],通过模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程,得到问题的最优结果。借用生物遗传学的观点,通过自然选择、交叉、变异等操作,一代代不断地繁殖进化,最后收敛到一批最适应环境的个体上,从而求得最优分类规则[6]。
本文通过分析基于遗传算法的学习分类器系统的体系机构,以规则为基础,给出一种基于非随机初始种群遗传算法的分类规则数据挖掘算法,通过训练数据集来实现类别的精确描述,采用数据挖掘中的基准数据鸢尾花卉数据集作为应用对象,实现学习分类器中的消息与分类器系统匹配、桶队列算法信用分配以及基于遗传算法的规则发现等关键技术,提高了分类规则挖掘的效率和准确性。
1 学习分类系统
1.1 基本原理
学习分类器系统[7-9]由属于三层次结构,第一层是规则库及信息系统,是一种基于规则(即分类器)的形式特殊的产生式系统,直接与环境发生作用;第二层是信用分配系统,其主要作用是对分类器做性能测评,每条分类器根据其性能而得到一个规则强度;第三层是规则生成与更新系统,规则库中可用规则数量庞大,而分类器库中的规则数有限,通常采用遗传算法对规则进行处理,不断产生新的、性能好的规则代替规则中性能差的规则以提高系统的性能。
1.2 规则及信息系统
规则及信息系统是一种特殊的产生式系统,其中的消息是长度确定的字符串,字符串中的字符一般用二进制:
符号“:=”表示“定义成”,{0,1}m表示字符串message的长度为m,而字符取0或1。
一个分类器(classifier)是一条特殊的产生式规则:
它的语义是:如果分类器地条件满足,分类器将向系统提供一条消息。
符号“#”表示通配符,即“0”“1”都匹配“#”。如条件#01#与消息0010,1010,0011,1011都匹配。
2 基于遗传算法的学习分类器系统
2.1 规则生成与系统更新
当规则和消息系统和环境进行一段时间的交互作用后,经过信任分配,规则库中的规则都有了能体现其性能的规则强度,此时使用遗传算法来产生新的规则替代性能不好的规则,其中的主要过程如下。
第一步:根据规则强度的大小,按照概率值大小随机选取两条规则r1和r2,规则强度大的规则选中的可能性大,反之则小。
第二步:将选中的两条规则进行交叉和变异,产生两条新规则,R1和R2,随机保留其中的一条规则,设为R1,新规则的强度取为规则库的平均规则强度。
第三步:R1取代规则库中性能最差(规则强度最小)的规则。
第四步:回到第一步,直到规则库中一定比例(G)的规则被替换。
需要注意的是,由于分类器系统使用三个字符 0、1、#,因此当某一个字符发生变异时,它将以相同的概率变化为其他两个字符中的一个。
2.2 工作过程
基于遗传算法的学习分类系统(Learning classifier system based on genetic algorithm,LCS)流程如下。
Step1:检测器对环境输入进行位串编码,形成环境消息,存储于消息列表中。
Step2:环境消息与分类器规则库中分类器的状态部分进行匹配,匹配成功的分类器组成匹配分类器集合。
Step3:匹配的分类器根据自身强度值进行投标,中标的分类器称为激活的分类器,激活的分类器允许将其动作部分作为新消息向外发送,所发送的新消息为外部消息或内部消息。
Step4:清空消息列表。如果Step3中产生的是内部消息,则将内部消息放入消息列表中。内部消息需再与分类器规则库中的分类器进行匹配,激活下一个分类器,产生新的消息,由此构成一个内部消息链,直至最后形成外部消息。
Step5:运用桶队列算法(Bucket brigade algorithm,简称BB算法)对激活的分类器进行回报的信用分配。如果激活的分类器产生的是外部消息,则该分类器直接得到环境回报;如果激活的分类器产生的是内部消息,它将在下一个周期中,其他分类器匹配该内部消息后才能得到回报。这两种激活的分类器分别用“t时刻激活的分类器”和“t-1时刻激活的分类器”加以区分。
Step6:当执行子系统和桶队列信用分配子系统运行一定的时间间隔后,启动遗传算法的规则发现子系统。对分类器规则库进行遗传操作,选择优良的分类器作为父辈个体,运用交叉和变异操作产生新的分类器子个体,加入到分类器规则库中。
Step7:返回至Step1。
3 实验结果及分析
3.1 实验准备
选用Iris数据集作为处理对象,使用C5.0算法生成初始规则集。Iris数据集包含150个数据对象,分为三类,分别为:Iris setosa,Iris versicolour,Iris virginica。C5.0是决策树模型中的算法,主要针对离散型属性数据,C5.0是C4.5应用于大数据集上的分类算法,主要在执行效率和内存使用方面进行了改进。
3.2 实验结果及分析
由C5.0生成的规则集的精度如表1所示。
表1 C5.0规则的精度
[类型 C5.0规则集精度 训练集 测试集 Iris-Setosa 25/25 25/25 Iris-Versicolour 24/25 23/25 Iris-Virginica 25/25 24/25 Total 74/75 72/75 98.67% 96% ]
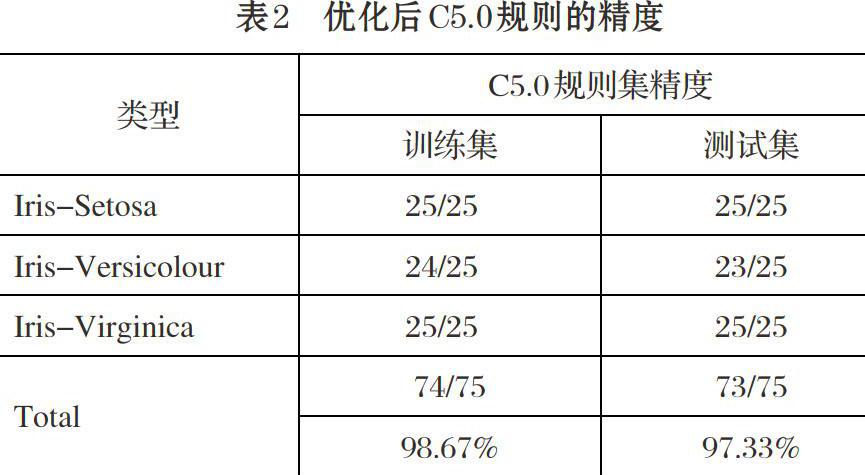
表2 优化后C5.0规则的精度
[类型 C5.0规则集精度 训练集 测试集 Iris-Setosa 25/25 25/25 Iris-Versicolour 24/25 23/25 Iris-Virginica 25/25 25/25 Total 74/75 73/75 98.67% 97.33% ]
优化以后,规则具有与C5.0相同的形式。规则集中属性左右边界的值都会发生改变,值的改变导致了分类准确度的提高,表2是优化后的规则在训练集和测试集上的精度。
表1和表2的结果表明,遗传算法优化后的精度好于单个算法的精度。测试集的分类精度从96%提升到97.33%。需要注意的是,在测试数据中Iris—Versicolor类的两个例子被误分为Iris—Virginia类、其原因在于这两个例子中的属性值极为相似,因此,用基于单属性来生成规则集(决策树算法把每次把一个属性作为分枝的标准)的算法是无法区分的,只有通过属性值的组合才可以把它们进行区分。
4 总结
本文将分类技术与进化方法结合起来,把遗传算法作为一种优化技术应用于多分类器上,实验结果表明,这样的结合可以得到较好的分类效果,即得到更精确或更易理解的结果。分类器系统从一个更高层次对规则集进行优化,通过优化规则的条件部分的边界值来提高预测精度,具有全局最优性和鲁棒性,对于大规模的数据集极为适合。
参考文献(References):
[1] Wah Y B, Ibrahim I R. Using data mining predictive models
to classify credit card applicants[C]. International Conference on Advanced Information Management and Service. IEEE,2010:394-398
[2] Singh V, Midha N. A Survey on Classification Techniques
in Data Mining[J]. International Journal of Computer Science & Management Studies,2015.16.
[3] 鄧桂骞,赵跃龙,刘霖等.一种优化的贝叶斯分类算法[J].计算
机测量与控制,2012.20(1):199-201
[4] 金敏,鲁华祥.一种遗传算法与粒子群优化的多子群分层混
合算法[J].控制理论与应用,2013.30(10):1231-1238
[5] 徐胜,马小军,钱海等.基于遗传-模拟退火的蚁群算法求解
TSP问题[J].计算机测量与控制,2016.24(3):143-144
[6] 于光帅,于宪伟.一种改进的自适应遗传算法[J].数学的实践
与认识,2015.45(19):259-264
[7] 邢乃宁,孙志挥.基于增量式遗传算法的分类规则挖掘[J].计
算机应用研究,2001.18(11):13-15
[8] 廖萍.遗传算法学习分类器系统的研究与应用[D].华东师范
大学硕士学位论文,2013.
[9] 季文赟,周傲英,张亮等.一种基于遗传算法的优化分类器的
方法[J].软件学报,2002.13(2):245-249
猜你喜欢
测控技术(2018年2期)2018-12-09
石油地球物理勘探(2017年2期)2017-11-23
池州学院学报(2017年3期)2017-10-16
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
统计与决策(2017年2期)2017-03-20
水利规划与设计(2016年9期)2017-01-15
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
现代计算机(2016年34期)2016-02-28
舰船科学技术(2016年1期)2016-02-27
智能系统学报(2015年4期)2015-12-27
