
基于社会信任和隐式项目的协同过滤推荐算法的研究
2018-04-26 01:46:46朱爱云任晓军
现代计算机 2018年5期
朱爱云,任晓军
(潍坊科技学院计算机软件学院,寿光 262700)
0 引言
个性化推荐系统作为信息过滤的有效工具越来越受到人们的关注。因为它能帮助用户从海量的数据中迅速查找出他们所需要的信息,在推荐系统中,协同过滤是一种广泛使用的推荐技术,但是传统的协同过滤算法通常存在着数据稀疏和冷启动等问题。为了处理这些问题,许多信任感知的推荐方法随之出现,在这些信任感知的推荐方法中许多都是以矩阵分解技术[1]为基础。这种推荐方法的出现往往是根据社交网络中的朋友会具有相似的偏好,并且用户的偏好也会受朋友的偏好所影响,这表明增加用户之间的额外信息能提高推荐性能。然而,依赖社会关系可能限制基于信任的推荐方法在其他社交网络场景下的应用,在社交网络中的潜在噪音和弱社会关系进一步也会阻碍这些推荐方法的应用[12]。同理,利用增加项目的边信息能提高推荐系统的性能[1,2,4,8,12],这个假设是用户倾向于对一组相关的项目有类似的偏好。例如:一个人如果喜欢电影《魔戒》,他/她可能会喜欢这一系列电影,甚至会欣赏相关的背景音乐。在这些推荐方法中文献[2-4]提出了通过使用显式项目关系(如:类别、类型、位置等)来提高推荐系统的性能,而在文献[1,10,12]提出并验证了隐式项目关系对推荐系统的价值。
虽然融合信任到推荐系统中能缓解数据稀疏性和冷启动问题,但是通过在三个真实的数据集(Film-Trust,Epinions,Flixster)上分析,首先,信任信息是非常稀疏,因此,如果在预测准确度上重点关注一种信息可能会产生一种边际效益。其次,针对极少的信任网络存在,最好是有一个更一般的信任模型能够处理信任邻居和相似信任的邻居。这些分析激发我们考虑评分的显示影响(评分值)、隐式影响(对什么评分)和信任的显式影响(信任值)、隐式影响(对谁信任)。评分的隐式影响[1]和信任的隐式影响[12]已验证能提高推荐的准确度。
因此,针对以上情况我们结合基于项目的协同过滤思想和社交网络信息,在文献[1,4,12]基础上提出了一种新颖的基于信任和项目关系的推荐模型。并通过在三个真实的数据集上进行训练测试,实验结果表明我们提出的方法推荐性能优于相比较的传统方法。
1 相关工作
额外的边信息是通常结合在协同过滤推荐方法中来提高推荐的性能,首先,信任感知推荐系统考虑额外的用户信息是一个值得关注的研究领域,近年来,许多这样的方法已提出,Ma等人[5]提出了RSTE方法,该方法是通过线性结合信任邻居到矩阵分解模型中,后来Ma等人发现使用社会关系构建正则化模型比结合信任邻居到矩阵分解模型中的推荐性能好。Jamali等人[6]提出了一个用户的潜在特征向量能够被他所信任的用户所正则化。Guo等人[12]认为用户的兴趣受隐式信任用户的偏好所影响。
其次,现已有许多研究人员已尝试使用项目关系来提高推荐性能,在本文中,我们把项目关系分成两类:即显式和隐式。典型的显式项目关系的例子包括属性(分类、位置、标签等),例如,Hu等人[4]认为一个商店的商品质量与它所在地理邻居的其它商店有一些隐式的指示,Shi等人[3]认为用标签来桥接跨领域的知识能提供更好的推荐。隐式项目关系指的是项目之间不能显式看到的那种关系,一个直接定义隐式项目关系的方法就是比较项目相似度[14]。
2 融合用户信任和隐式项目关系的社会化推荐模型(SocialSVD)
在这一部分我们首先介绍融合信任和隐式项目关系的推荐模型,然后通过实验比较我们提出的方法与其他经典方法的性能。
2.1 问题定义
矩阵分解技术已广泛的应用在推荐系统中,这个潜在的假设是一个用户的偏好能够被少数潜在的特征所表示。基于用户-项目评分矩阵和用户间的信任矩阵,设想一个推荐系统包含m个用户,n个项目,假定用表示用户-项目评分矩阵,其中ru,i表示用户u对项目i的评分。矩阵分解的实质[6]是找到两个低维的矩阵即用户特征矩阵P∈Rd×m和项目特征矩阵Q∈Rd×n,然后两者相乘近似于评分矩阵R使R≈PTQ,其中PT是矩阵P的转置矩阵,因此用户u对项目 j的预测评分为,对于我们推荐的主要任务是预测评分尽可能的接近于真实值ru,j。
同理,我们把社交网络用一个图G=(v,ε)表示,其中v是一个有m个用户的集合,ε是用户之间的有向信任关系,用一个邻接矩阵描述这些边 ε的结构,其中tu,v表示用户u信任用户v的程度,pu,wv分别是信任人u,被信任人v的d维潜在特征向量,为了能够联系信任矩阵中的信任者和评分矩阵中的活跃用户,限定他们拥有相同的特征空间。因此,我们得到信任特征矩阵Pd×m和被信任人特征矩阵Wd×m。然后利用低维矩阵分解,可以得到信任矩阵公式如下:T≈PTW ,即一个信任关系能够预测为。最后通过最小化损失函数不断学习得到矩阵P和矩阵W。
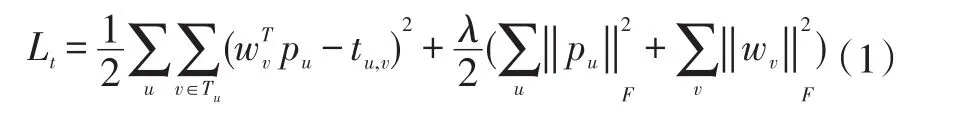
其中,Tu是用户u信任的用户集合。
Guo等人[12]提出了用户的兴趣受隐式信任用户的偏好所影响。即预测评分为:


为了连接评分矩阵和信任矩阵,我们限制评分矩阵中分解的用户特征向量和从信任矩阵中分解的用户特征向量具有相同的特征空间。因此最小化目标函数如下:
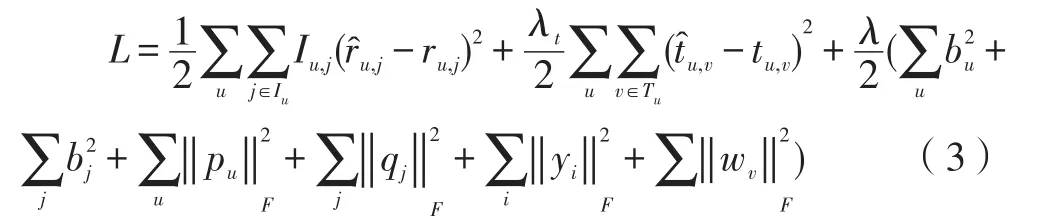
虽然增加社会网络信息能大大提高推荐的准确度,也能缓解数据稀疏性和冷启动问题,然而有时社会关系可能在许多实际系统中不可用,并且从三个真实的数据集(FilmTrust,Epinions,Flixster)中的信任数据分析,信任数据是非常稀疏。因此,受增加社交网络信息[8,13]和增加项目[4,7,10,11]的边信息能大大提高推荐的准确度的影响。针对社会推荐中仅仅融合好友的推荐方法的不足,忽视用户推荐的物品之间的关联关系也会对推荐结果产生影响,提出了一种基于用户信任和隐式项目关系的个性化推荐方法。该方法不仅利用了用户的信任关系,同时也结合了基于项目的协同过滤思想,考虑到与用户喜欢的项目相似的项目用户也会喜欢,即与用户评过分的项目所关联的项目也会影响用户的偏好。因此,在公式(3)的基础上增加了隐式项目关系,一个直接定义隐式项目关系的方法就是比较项目相似度。因为如果许多人都喜欢这两个项目,则表明这两个项目有共同的相似性。这种直观的判断是基于项目的协同过滤,最流行的相似度衡量是皮尔逊相关系数(PCC)和余弦相似度(COS),而在本文中我们使用COS来计算项目间的相似度。
假设两个项目 j,k隐式关联的强度为sj,k,且sj,k值越大,我们认为这两个项目的特征向量应该是越接近,项目 j与项目k的关联程度越大,即隐式项目关系越密切。在文献[15]使用社会关系的启发下,我们提出了在融合社会关系的基础上再增加隐式项目关系到矩阵分解模型中,然后构建正则化模型生成用户的潜在特征和项目的潜在特征。通过正则化来调整评分矩阵的分解,因此给出的模型如下:

其中,Iu,j是一个指示函数,如果用户u对项目 j已评分,则Iu,j=1,否则Iu,j=0,β>0是一个正则化参数,它用来控制隐式项目关系正则化的重要性;sj,k表示项目 j与项目k的关联程度,Aj是与项目 j的最关联的项目集合。
2.2 模型学习
为了使目标函数(4)最小化,执行梯度下降法分别对参数bu,bj,qj,pu,wv求偏导数得到如下公式进行训练:

3 实验分析
3.1 数据集与比较方法

表1 三种数据集的统计数据
对每种方法的最优实验设置都是通过我们的实验验证或以前的文章提供的建议得到的。在本文中,潜在的特征数选择d=5,学习速率为α=0.4,迭代次数为100次。其中,RSTE方法在三种数据集中均设置λ=0.001,SoRec方法 在FilmTrust,Epinions,Flixster数据集中分别设置为λc=0.1,1.0,0.001;SoReg 方法在数据集Flixster中β=1.0而在其它数据集中设定为β=0.1;SocialMF方法在三种数据集中设定λt=1;SVD++方法在FilmTrust,Epinions,Flixster数据集中分别λ=0.1,0.35,0.03;SocialMF+方法在FilmTrust数据集中λ=1.2,λt=0.9,在 Epinions数据集中 λ=0.9,λt=0.5在Flixster数据集中λ=0.8,λt=0.5。
为了说明我们提出的方法的有效性同以下方法进行了比较。
1.RSTE:这种方法是Ma等人[5]提出的,通过利用线性结合信任邻居与矩阵分解构建模型,这是一个信任感知推荐方法,模型用户的评分平衡用户自己的品味与他所信任用户的品味间的差异。
2.SoRec方法是Ma等人在2008年[9]提出的,利用概率矩阵分解通过共享一个潜在低维特征矩阵融合用户评分矩阵与用户社会信任网络。
3.SoReg方法是Ma等人在2011年[8]提出的,利用矩阵分解融合用户的品味和他们所信任的朋友以此构建正则化模型。
4.SocialMF方法是Jamali等人[6]提出的,在社交网络中利用矩阵分解模型做出推荐。
5.SVD++方法是Koren等人[1]在2008年提出的,融合用户评分的显式和隐式影响做出推荐。
翻耕整地期间应施加足量的腐熟有机肥作底肥,不但肥效长而且可改善土壤结构。小麦播种时应施加种肥,一般使用尿素或复合肥,可以在较短时间内发挥最大肥效,以利于种子发育出苗。出苗后至收割期间要合理追肥。
实验结果如表2所示,在表2中所有比较的方法中SocialSVD方法在三种数据集(FilmTrust,Epinions,Flixster)中性能是最好的(MAE或RMSE值是最小),虽然相对提高的比例很小,但是文献[9]已经指出MAE或RMSE值很小的改善也可能大大提高推荐的性能。
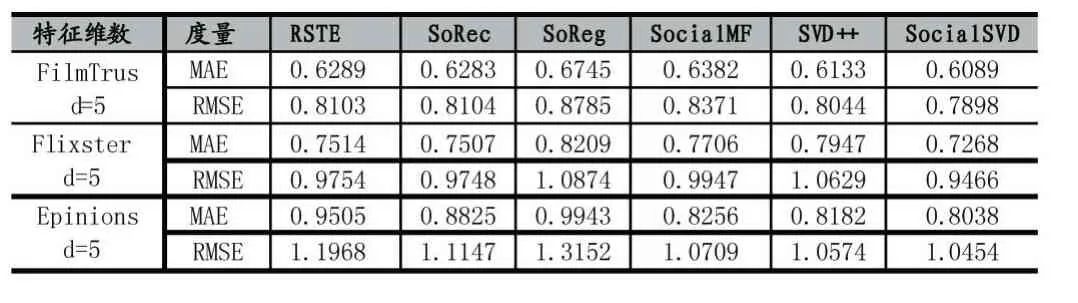
表2 本文提出的方法与其他典型方法的比较
3.2 信任度的比较
本文中把一个特定用户所信任邻居的数量作为这个用户的信任度,为了验证信任度对预测准确度的影响,把信任度分为5类,划分如下:1-5人,6-10人,11-20人,21-40人,41-100人,特征维数d=10。基于信任度模型的结果如图1、2、3,从图1、2、3中可以看出,在通常情况下,我们提出的方法不管在哪种数据集和哪种信任度下RMSE都是最小的,并且对于同一种方法,随着信任度的增加(用户的好友数越多),RMSE的值就越小,表明在实际的协同过滤推荐系统中,只要用户具有很多的好友,则用户可以从好友的偏好中学习到丰富的个人偏好特征信息,以此做出更加准确的推荐。
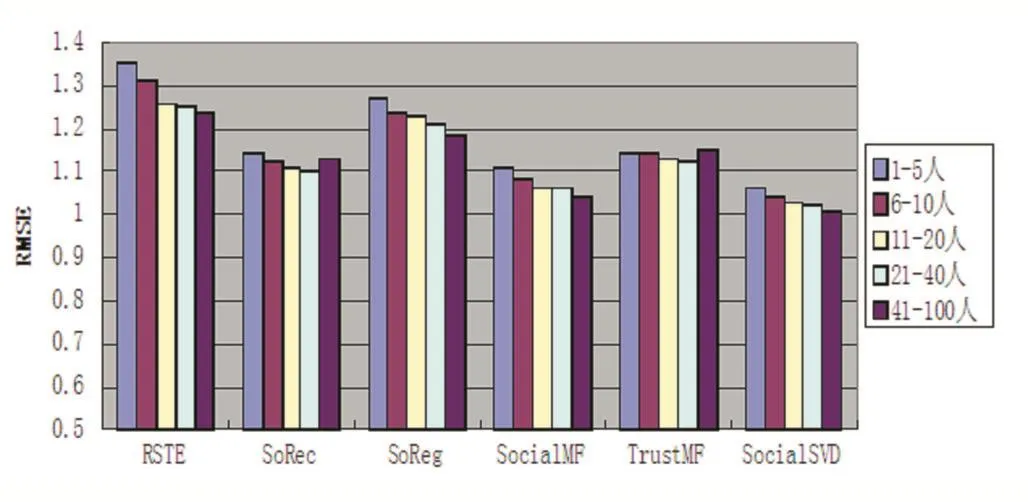
图1 Epinions数据集中不同信任度的性能比较(d=10)

图2 Flixster数据集中不同信任度的性能比较(d=10)
3.3 项目关系正则化参数 β的影响
参数β在公式(4)中控制着项目关系正则化的重要性,为了验证隐式项目在推荐过程中所起的作用以及对推荐准确度的影响,我们分别选择 β=0.001,0.001,0.01,0.1,0.2,0.5,1.0 在三种真实的数据集 Epinions、FilmTrust、Flixster上进行测试,迭代次数为100,特征维数为10,目的是寻找β取何值时能达到最佳状态,实验结果如图4、图5所示。从图4、图5可以看出在Epinions数据集上 β大约取0.5,在FilmTrust数据集上β大约取0.1,在Flixster数据集上 β大约取0.2。这也表明隐式的项目对推荐结果有重要的影响。

图3 FilmTrust数据集中不同信任度的性能比较(d=10)
4 结语
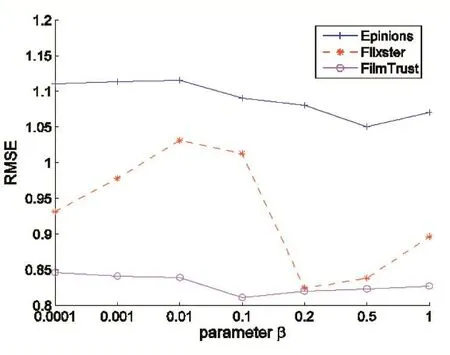
图4 参数β对RMSE的影响
本文通过融合用户的信任关系和隐式项目关系,提出了一个新颖的矩阵分解模型。首先通过定义引入了矩阵分解在推荐系统中的应用,接着结合社交网络中的信任关系,引入了信任特征矩阵;其次,考虑到用户对项目的评分不仅与自己的兴趣有关,还与所评分的项目、所信任的朋友的兴趣以及所评分的项目的相似项目有关;最后,结合基于项目的协同过滤中的项目之间存在相似性的思想,在传统的奇异值(SVD)矩阵分解模型中融合了社交网络中的信任关系和隐式项目关系构建正则化模型的方法。通过在Flixster、Film-Trust、Epionions三个真实的数据集上进行大量的实验,验证了我们提出的推荐模型在准确性和效率方面都有较大的提升。对于将来的工作,我们打算融合隐式项目和显示项目关系进一步提高推荐系统的性能。
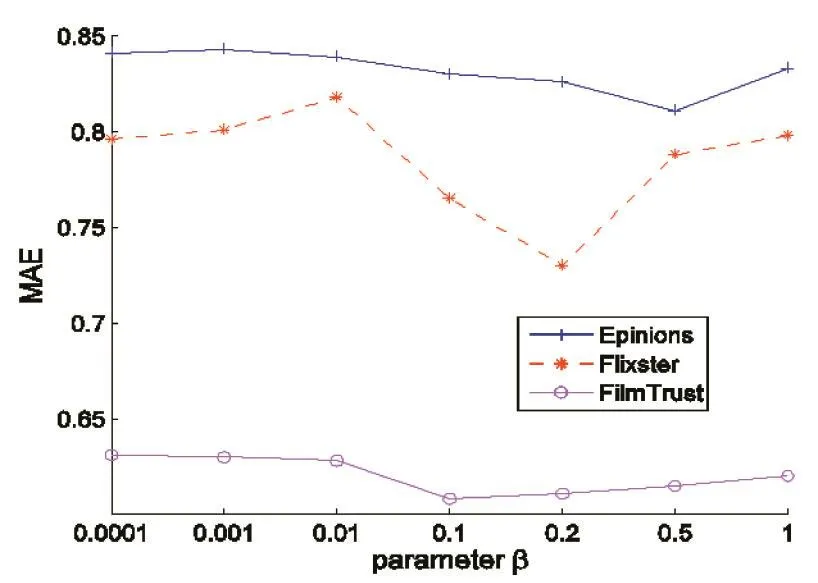
图5 参数β对MAE的影响
参考文献:
[1]KOREN Y.Factorization Meets the Neighborhood:a Multifaceted Collaborative Filtering Model[C].In:Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(KDD),2008:426-434.
[2]KIMCKIM J.A Recommendation Algorithm Using Multi-Level Association Rules[C].In:Proceedings of 2003 IEEE/WIC International Conference on Web Intelligence(WI),2003:524-527.
[3]SHI YLARSON M,HANJALIC A.Tags as Bridges Between Domains:Improving Recommendation with Tag-Induced Cross-Domain Collaborative Filtering[C].In:Proceedings of the 19th International Conference on User Modeling,Adaptation and Personalization(UMAP),2011:305-316.
[4]HU L,SUN A,LIU Y.Your Neighbors Affect Your Ratings:on Geographical Neighborhood Influence to Rating Prediction[C].In:Proceedings of the 37th International ACM SIGIR Conference on Research&Development in Information Retrieval(SIGIR),2014:345-354.
[5]MA H.KING I.,LYU M.Learning to Recommend with Social Trust Ensemble[C].In:Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval(SIGIR),2009:203-210.
[6]JAMALI M,ESTET M.A Matrix Factorization Technique with Trust Propagation for Recommendation in Social Networks Systems(Rec-Sys),2010:135-142.
[7]FANG H,BAO Y,ZHANG J.Leveraging Decomposed Trust in Probabilistic Matrix Factorization for Effective Recommendation[C].In Proceedings of the 28th AAAI Conference on Artificial Intelligence(AAAI),2014:30-36.
[8]MA H,ZHOU D Y,LIU C.Recommender Systems with Social Regularization[C].In Proceedings of the 4th ACM International Conference on Web Search and Data Mining,2011:287-296.
[9]MA H,YANG H,LYU M.SoRec:Social Recommendation Using Probabilistic Matrix Factorization[C].In Proceedings of the 31st International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2008:931-940
[10]WANG D,Ma J,LIAN T,L G.Recommendation Based on Weighted Social Trusts and Item Relationships[C].In Proceedings of the 29th Annual ACM Symposium on Applied Computing(SAC)ACM,2014:2000-2005.
[11]FOUSS F,PIROTTE A,RENDERS J M,et al.Random-Walk Computation of Similarities Between Nodes of a Graph with Application to Collaborative Recommendation[J].IEEE Transactions on Knowledge and Data Engineering,2007,19(3):355-369.
[12]GUO G,ZHANG J,YORKE S N.Trustsvd:Collaborative Filtering with Both the Explicit and Implicit Influence of User Trust and of Item Ratings[C].In Proceedings of the 29th AAAI Conference on Artificial Intelligence.AAAI,2015.
[13]王瑞琴,蒋云良,李一啸.一种基于多元社交信任的协同过滤推荐算法[J].计算机研究与发展,2016,53(6):1389-1399
[14]Wang,D.,Ma,J.,Lian,T.,L.,G.:Recommendation Based on Weighted Social Trusts and Item Relationships.In:Proceedings of the 29th Annual ACM Symposium on Applied Computing(SAC),2000-2005(2014)
猜你喜欢
少年博览·小学高年级(2018年10期)2018-12-10 09:00:04
环球时报(2018-01-23)2018-01-23 05:25:53
桃之夭夭B(2017年2期)2017-02-24 17:32:43
知音海外版(上半月)(2016年12期)2017-01-13 13:10:09
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
计算机工程(2015年4期)2015-07-05 08:27:45
高中生·青春励志(2014年11期)2014-11-25 10:07:54
