
Stata 中因子变量的使用方法
2018-04-24 01:00:34连玉君
郑州航空工业管理学院学报 2018年2期
连玉君,杨 柳
(1. 中山大学 岭南学院,广东 广州 510275; 2.西北大学 城市与环境学院,陕西 西安 710127)
一、问题背景
实证分析中,我们经常需要在模型中加入反映类别的虚拟变量,以便控制不可观测的组间差异。而在另一些分析中,为了刻画调节效应,尚需在模型中加入变量的交乘项或平方项。传统的做法是,预先生成虚拟变量或交乘项,进而将它们加入模型。然而,当虚拟变量或交乘项的数目较多时,上述方法就显得尤为不便,不但浪费计算机内存,也会严重降低我们的工作效率。
在Stata中,我们可以使用因子变量(Factor Variable)简化操作步骤、快捷地在回归模型中加入虚拟变量、交乘项、平方项或高次项。更为重要的是,由于引入交乘项或平方项后,解释变量对被解释变量的边际影响不再是常数,而是某个变量(调节变量)的函数,在有些模型设定下,这种关系可能是非线性的。此时,若使用因子变量,并配合Stata中的margins和marginsplot命令,可以非常便捷、直观地分析关键变量的边际效应。
本文将以文献中广泛使用的一些模型设定形式为例,来说明Stata中因子变量的使用方法。后文结构安排如下:第二部分介绍因子变量的基本用法,包括使用因子变量表示虚拟变量、交乘项和高次项;第三部分举例说明因子变量在常用回归模型中的应用;第四部分重点介绍如何使用因子变量进行边际效应分析。
二、什么是因子变量
因子变量(Factor Variable)是对现有变量的延伸,是从类别变量中生成虚拟变量、设定类别变量之间的交乘项、类别变量与连续型变量之间的交乘项或连续变量之间的交乘项(或多项式)。在Stata中的大多数回归命令和回归后的估计命令中都可以使用这些因子变量。①
因子变量的五种运算符及其含义如表1所示:

表1 因子变量的运算符及含义
注:(a) 由因子变量运算符生成的指示变量和交乘项是实际存在的变量,它们与数据表中的变量是一样的,但是在数据表中并不显示出来;(b) 类别变量的值必须是非负整数,范围介于0至32740之间;(c) 因子变量的运算符有时可与时间序列的运算符L.和F.组合在一起使用.②
以研究妇女工资的决定因素为例,使用Stata软件自带的数据文件(nlsw88.dta)。该数据包含了1988年采集的2246个美国妇女的资料,包括:小时工资wage、每周工作时数hours、种族race、职业occupation、年龄age、是否大学毕业collgrad、当前职业的工作年限tenure、是否结婚married、是否居住在南部地区south、合计工作年限ttl_exp等变量。其中,小时工资wage、每周工作时数hours、年龄age、当前职业的工作年限tenure、合计工作年限ttl_exp为连续型变量;种族race为类别变量(1代表白种人white,2代表黑种人black,3代表其他人种other)、职业occupation为类别变量(13个职业类别);是否大学毕业collgrad、是否结婚married、是否居住在南部地区south为虚拟变量。
在这份数据中有一个表示种族的类别变量race,取值为1、2、3,分别对应“白人”、“黑人”和“其他人种”。假设我们想在模型中加入一个反映种族的虚拟变量black,当某个妇女是黑人时,black取值为1,否则为零。则传统的做法如下:③
L1
. gen black=1
. replace black=0 if race!=2
. reg wage black
若延续这一思路,但使用因子变量来生成black变量,则命令为:
L2
. gen black = 2.race
只需要一条命令,而且含义非常明确。这里“2.race”本质上是一个条件判断语句:判断某一行观察值中的race变量取值是否为2,若是,则返回1到变量black中,否则返回0。
然而,在多数情况下,我们的目的只是希望得到虚拟变量black的估计系数,而不希望生成或存储这个变量。④Stata中的因子变量语法完全注意到了这个问题。使用因子变量的标准做法如下:
L3
. sysuse "nlsw88.dta", clear
. reg wage 2.race
注意,我们无需预先生成black变量,而是直接在回归模型中加入了2.race因子变量。
有些读者注意到,race变量有三个取值,因此,我们可以在模型中放入两个虚拟变量,此时可以书写如下命令:
L4
. reg wage i.race
回归结果如图1所示:
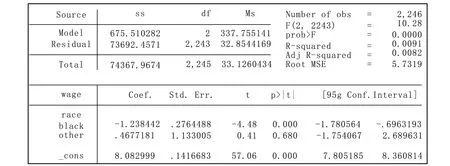
图1 模型回归结果
从图1的结果中可以看到,回归模型中加入了black虚拟变量和other虚拟变量,分别对应race变量的第二个和第三个类别,而第一个类别white被Stata默认作为基准组,目的在于防止完全共线性。black变量的系数值为-1.238,表示黑人的平均工资比白人低1.238个单位,并在统计上显著;other变量的系数值为0.468,表示其他人种的平均工资比白人高0.468个单位,但是在统计上不显著。
在实证分析中,有时会根据研究内容的需要改变基准组的设定,此时可使用ib.或b.的前缀,具体写法见表2中描述。
在实证分析中,变量的交乘项或高次项往往是重要的解释变量。以研究妇女工资的决定因素为例,若我们想在模型中加入黑人每周工作时数的变量,则传统做法是预先生成一个虚拟变量(black)代表是否黑人,再生成一个新变量(black_x_hours)表示黑人与每周工作时数的交乘项,然后再将这个新变量放入回归模型中。Stata命令为:
L5
. gen black=1
. replace black=0 if race!=2
. gen black_x_hours =black * hours
. reg wage black_x_hours
若在Stata中使用因子变量实现上述过程,则命令十分简洁:
L6
. reg wage 2.race#c.hours

表2 基准组的运算符及含义
注:(a) i可以省略不写。例如:ib2.group与b2.group的写法等价;(b) ib(#2)指使用变量值中的第二位排序的值所对应的类别作为基准组;(c) 如果想在线性回归模型中将group变量中值为3的类别设置为基准组,则命令可写为:reg y i.sex ib3.group.
下面,我们介绍如何在Stata中使用因子变量表示变量的交乘项或高次项。我们以研究妇女工资的决定因素为例进行说明。
1.两个类别变量的交乘项
在回归模型中加入种族和职业类别的交乘项,Stata命令为:
L7
. reg wage i.race#i.occupation
若在回归模型中既要放入种族与职业的虚拟变量,又需要同时放入这两个变量的交乘项,则在回归命令中使用“i.race##i.occupation”,相应的命令为:
L8
. reg wage i.race##i.occupation
2.类别变量与连续变量的交乘项
在回归模型中加入种族和每周工作时数的交乘项,Stata命令为:
L9
. reg wage i.race#c.hours
需要注意的是,在上例中,由于我们把hours变量视为连续变量,因此,需要在其前面加上c.符号以便告知Stata该变量是连续变量。
3.连续变量与连续变量的交乘项(高次项)
在回归模型中加入年龄age变量,以及其平方项,Stata命令如下:
L10
. reg wage c.age##c.age
上述命令中c.age表示年龄age变量被当成连续型变量。如果我们在Stata命令中使用i.age,则年龄age变量被当成类别变量处理,此时,类别的个数为年龄age变量中不同取值的个数。
三、常用回归模型的因子变量表述
范例1:邹氏检验
由于不同组别之间可能会存在差异(截距项或斜率项存在差异),因此,我们需要检验这些差异在统计上是否显著。这时,我们可以使用邹氏检验。以研究妇女工资的影响因素为例,我们可以使用chowtest命令检验工会成员与非工会成员两个样本组中工资影响因素是否存在差异(或称之为存在结构变化):
L11
. global xx "hours age tenure ttl_exp married"
. chowtest wage $xx, group(union) detail
事实上,我们也可以使用因子变量的语法,在回归模型中加入分组变量与其他控制变量的交乘项,然后再联合检验分组变量的系数以及所有交乘项的系数是否都等于0。此时,即使我们不使用chowtest命令,也可以轻松实现邹氏检验:
L12
. global xx "hours age tenure ttl_exp married"
. reg wage $xx i.unioni.union#c.($xx)
. testparmi.unioni.union#c.($xx)
范例2:双向固定效应模型
在实证分析过程中,经常需要在模型中加入反映年度、公司或行业特征的虚拟变量。当虚拟变量的数目众多时,采用手动输入变量的方式会非常耗时。例如,下述模型(1)是文献中广泛应用的“双向固定效应模型”:
(1)
上式等价于
(2)
其中,Di是对应于每家公司的虚拟变量,对于公司i,Di=1,否则Di=0。对于一个N=1000家公司的面板数据而言,共有1000个虚拟变量。Wt是T-1个年度虚拟变量,⑤定义方式与Di相似。
若使用因子变量,则语法很简单:⑥
L13
. reg y x1 x2 x3 i.id i.year
其中,i.id表示N个公司虚拟变量,即(2)式中的αi。
当然,我们也可以用xtreg命令自带的fe选项来控制个体效应αi,同时使用因子变量来加入年度虚拟变量λt,命令如下:
L14
. xtreg y x1 x2 x3 i.year, fe
范例3:DID模型
在实证分析中,常常需要分析政策实施后带来的效果。这时,我们就需要采集实验组与控制组两组样本(实验组的样本代表政策实施前后的情况,控制组的样本代表不实施政策的情况),再把这两组样本合并为一份数据后进行回归分析。在建模时,我们需要设定一个是否为实验组或控制组的处理虚拟变量放入模型,还需要设定一个反映政策实施时间前与实施后的时间虚拟变量放入模型,此外,还需要在模型中加入变量与变量的交乘项,该交乘项的系数估计值就是政策实施后带来的效果,即实验组在政策实施后相对于政策实施前的差异。回归模型如式(3)所示:
y=α0+α1Treat+α2Time+α3Treat×Time+xβ+ε
(3)
在Stata中的命令写法如下:
L15
. reg Treat Time Treat#Time x1 x2 x3
*-或者写为
. reg Treat##Time x1 x2 x3
在多期DID分析中,我们常常需要加入年度虚拟变量与处理变量的交乘项来检验“共同趋势假设(common trend)”以及政策效果。例如,在Acemoglu and Angrist(2001)文中,作者采集了1988年至1997年的人口调查数据,将样本分为残疾人与非残疾人,使用多期DID模型研究了1992年美国对残疾人工作保护法案(ADA)的实施效果。文中模型设定如下:
其中,i为残疾人个体;t为年份;yit为工作周数或周平均工资;xi为一系列控制变量,πt为时间趋势项;di为是否残疾,其系数为δ;αt为随年份变化的实施ADA与未实施ADA对残疾人工作保护效应的系数。当t≥1992年时,ai量化了实施ADA之后对残疾人工作保护的效应(使用非残疾人作为控制组);当t<1992年时,ai检验了实施ADA之前的各年份中残疾人和非残疾人的工作周数或周平均工资是否具有统计上显著的差异,相当于同时进行了DID模型的“共同趋势假设”的检验。使用如下命令即可得到Acemoglu、Angrist(2001)文中表2第(1)列中的结果。⑦
L16
. use "ABA_JPE2001.dta", clear
. global controls "i.age_Gi.edu_Gi.race_Gi.region"
. reg y i.year##($controls) Treat i.yeari.Treat#i.year
范例4:超越对数生产函数
很多文献使用超越对数生产函数估计生产效率,模型中会包含投入要素K和L的高阶项,包括平方项和二者的交乘项⑧。例如在Kumbhakar(1989)中,作者通过在模型中加入二次项来捕捉要素的交互影响和潜在的非线性关系,模型如式(5)所示。
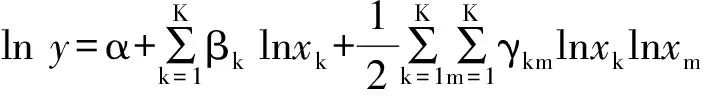
此时,使用因子变量会让Stata中的命令变得异常简洁,如下所示:
L17
. webuse frontier1.dta, clear
L18
. global y "lnoutput" // y
. global x "lnlaborlncapital" // x1 x2
*-超越对数生产函数
. sfcross $y c.($x)##c.($x) // Eq.
(5)
四、边际效应分析和图形化呈现
一些实证研究的文献中常常加入变量的交乘项以反映可能存在的调节效应,例如Faulkender and Wang(2006),戴魁早与刘友金(2016),张苏与高扬(2012)⑨,此时最重要的是分析x对y的边际效应。
y=α+xβ1+(x·z)β2+ε
(6)
x对y的边际影响为:
显然,∂y/∂x取决于z的取值。这种边际效应分析若是采用手动计算会非常烦琐,而后续的图形呈现则更为复杂。然而,若是借助因子变量,并配合Stata中的margins和marginsplot命令,对于包含交乘项的模型中的边际效应的分析和图形化展示都变得异常轻松。
下面,我们以研究妇女工资的决定因素为例进行说明。使用Stata软件的自带数据nlsw88.dta(1988年美国妇女小时工资),以wage(妇女的小时工资)作为被解释变量,以race(种族类别)、collgrad(是否大学毕业)、race与collgrad的交乘项作为解释变量建立线性回归模型,Stata中的命令如下:
L19
. sysuse"nlsw88.dta", clear
. reg wage i.race##collgrad
回归结果如图2所示:
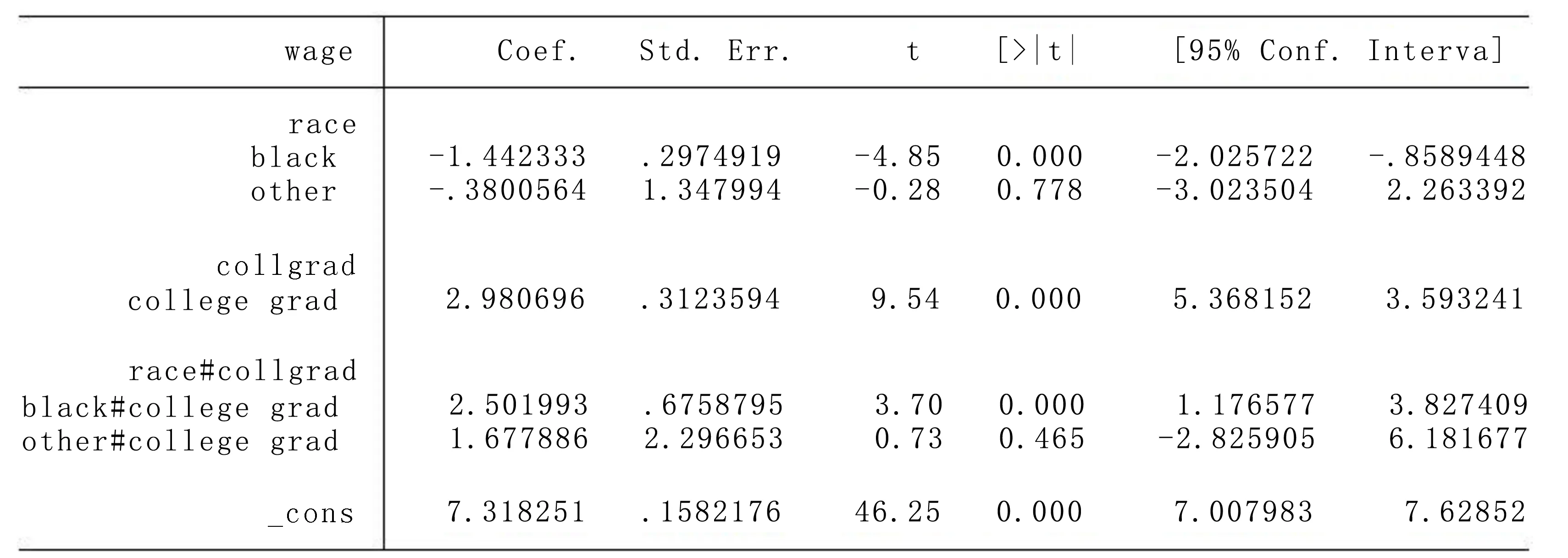
图2 模型回归结果
我们使用margins命令来计算种族(race)与是否大学毕业(collgrad)的交乘项的各个类别对妇女小时工资(wage)的平均边际效应,Stata命令和结果如下所示:
L20
. margins i.race#collgrad
计算结果如图3所示:
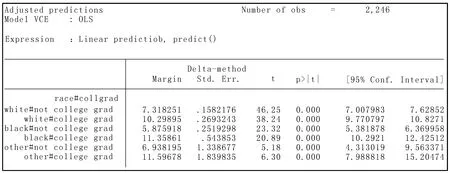
图3 边际效应计算结果
使用marginsplot命令将计算结果用图4的形式表示,Stata命令和结果如下所示:
L21
. marginsplot
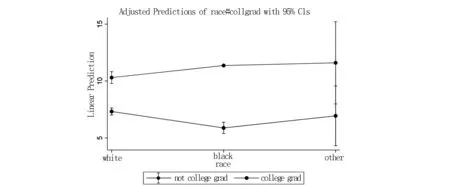
图4 种族与是否大学毕业的交乘项对妇女工资的平均边际效应
从图4中可以直观地看到,不论种族类别,大学毕业的妇女的平均工资高于非大学毕业的妇女,该结果符合我们的一般认知;另外,我们从图中还发现一个有趣的结果,当妇女为非大学毕业时,白人的平均工资高于黑人,而当妇女为大学毕业时,白人的平均工资低于黑人。
下面,我们使用margins命令附加atmeans选项来计算当其他变量取均值时不同种族类别对妇女工资的平均边际效应,Stata命令和结果如下所示:
L22
. margins i.race, atmeans
*-或者写为:
. margins race, atmeans
计算结果如图5所示。
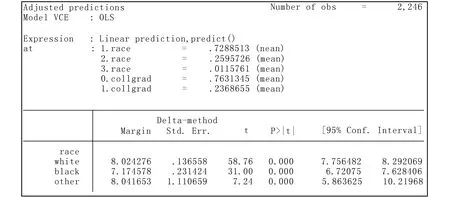
图5 边际效应计算结果
使用marginsplot命令将计算结果用图6的形式表示,Stata命令和结果如下所示:
L23
. marginsplot
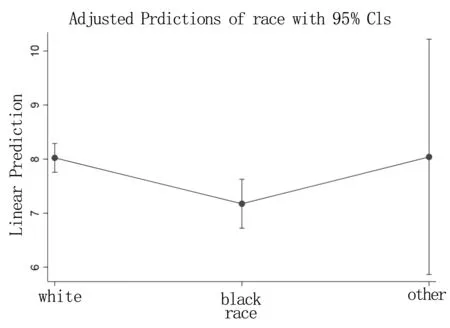
图6 种族对妇女工资的平均边际效应
从图6中可以直观地看到,白人与其他种族妇女的平均工资高于黑人妇女。
两个连续变量的交乘项对被解释变量的边际效应也可以使用margins命令来计算。我们仍以研究妇女工资的决定因素为例进行说明。在回归模型中加入ttl_exp(合计工作年限)及其平方项,并将hours(每周工作时数)、age(妇女年龄)、tenure(当前职业的工作年限)、married(是否结婚)、south(是否居住在南部地区)、race(种族类别)作为控制变量,Stata命令如下所示:
L24
. global xx "hours age tenure married south i.race"
. reg wage c.ttl_exp##c.ttl_exp $xx
由于在模型中加入了ttl_exp的平方项,因此,ttl_exp对wage的边际效应将会受到ttl_exp取值的影响。上述Stata命令对应的模型设定如下:
wage=α+ttl_expβ1+(ttl_exp·ttl_exp)β2+β3x3+…+β8x8+ε
(7)
ttl_exp对wage的边际影响为:
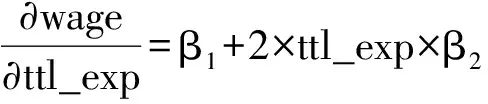
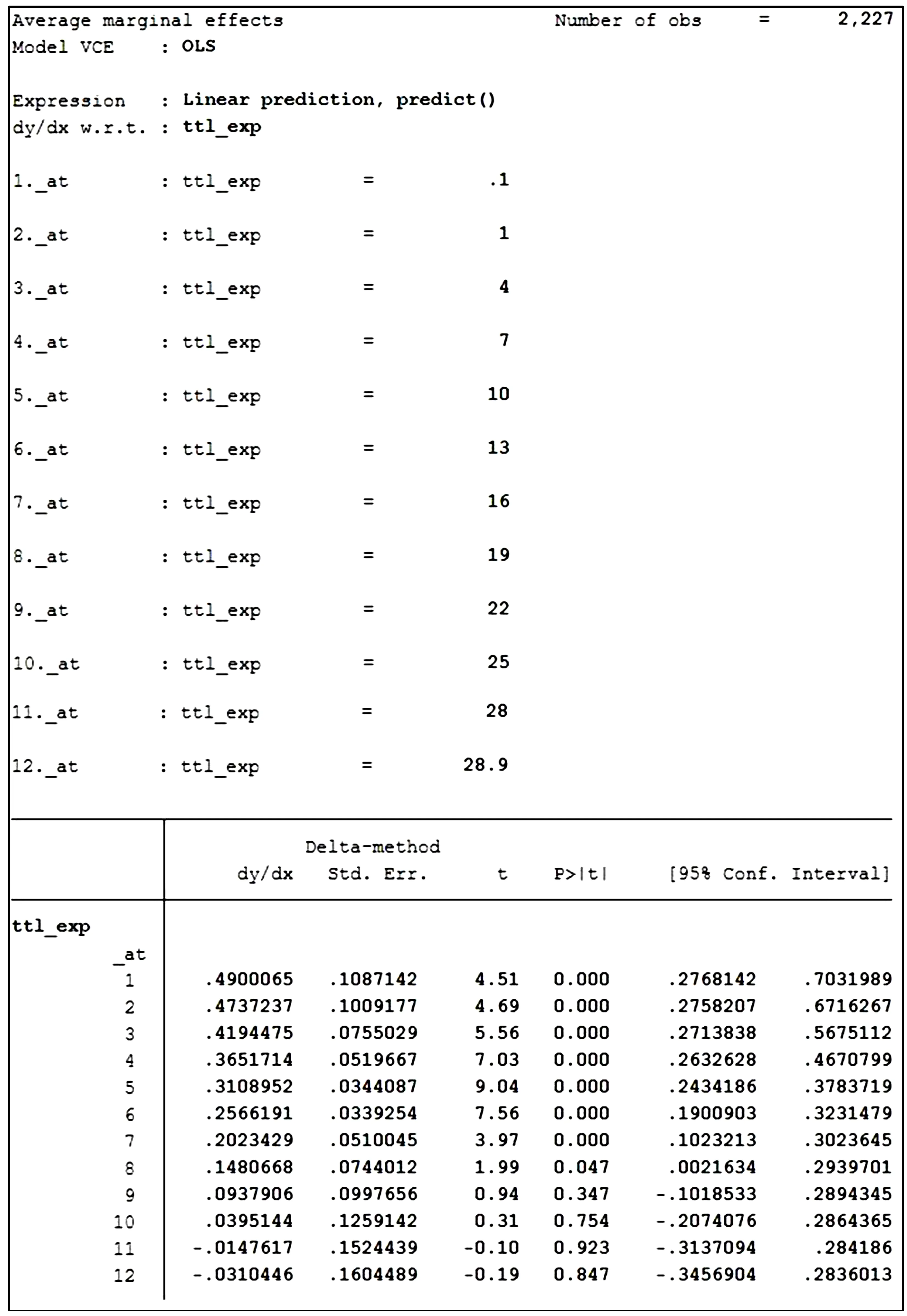
显然,当ttl_exp取值不同时,ttl_exp对wage的边际效应是不相同的。因此,需要先使用描述性统计分析的命令(如sum ttl_exp)查看ttl_exp取值的范围,然后再计算当ttl_exp取不同的值所对应的边际效应,Stata命令如下:
L25
. sum ttl_exp
. margins, dydx(ttl_exp) at(ttl_exp=(0.1 1(3)28 28.9))
计算结果见附录1。
使用marginsplot命令将计算结果用图7的形式表示,Stata命令和结果如下所示:
L26
. marginsplot, xlabel(,format(%3.1f) angle(60))
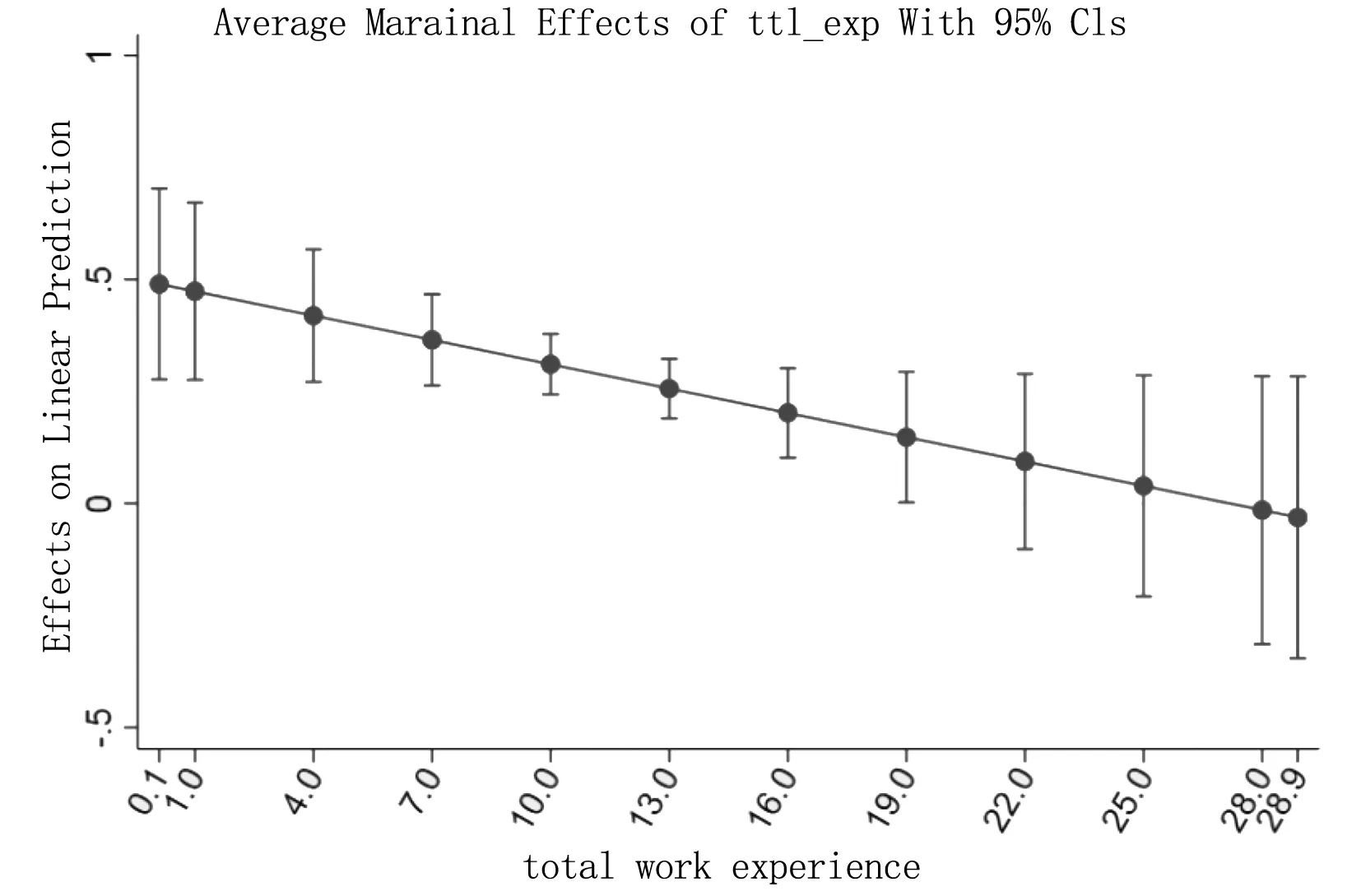
图7 合计工作年限对妇女工资的平均边际效应
Stata中的多数命令都支持margins和marginsplot命令。因此,即使对于非线性模型,如logit, tobit等,我们仍然可以借助这两个命令很方便地分析边际效应。
五、输出回归结果时的问题及解决办法
以研究妇女工资的决定因素为例。wage(妇女的小时工资)作为回归模型的被解释变量,race(种族类别)、collgrad(是否大学毕业)、race与collgrad的交乘项作为解释变量,并将回归结果输出到Excel中,Stata命令和结果如下:
L27
. reg wage i.race##collgrad
. est store R1
. esttab R1 using D:/Table_factor_1.csv, nogap replace
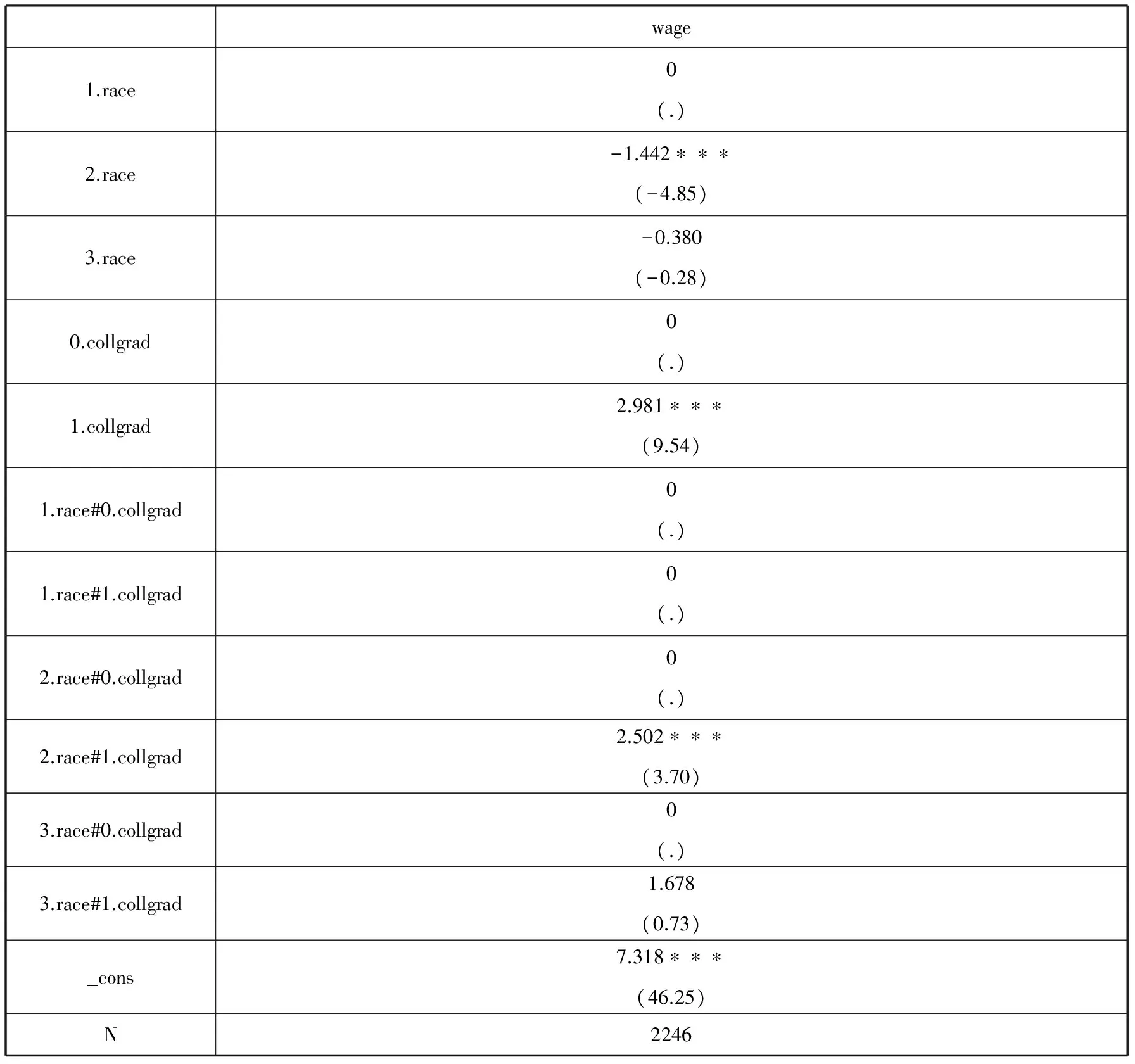
表3 1988年美国妇女工资模型结果
注:括号内为t统计量;* p<0.05, ** p<0.01, *** p<0.001.
我们发现在表3中有很多变量的系数值为0,并缺失t统计量。造成这种情况的原因有二:一方面是由于有些虚拟变量作为基准组,例如:1.race,0.collgrad与1.race#0.collgrad,Stata默认将它们作为基准组,所以就缺失这些基准组的估计系数值和标准误;另一方面是由于有些交乘项中的其中一个因子变量是基准组,其他变量与这个作为基准组的因子变量交乘后的交乘项就被忽略了,所以其估计系数值和标准误就会缺失,例如:1.race#1.collgrad,2.race#0.collgrad与3.race#0.collgrad。此时,可以使用esttab命令的drop()选项来屏蔽这些系数的显示,还可以使用nobase和noomit的选项,Stata命令和结果如下所示:
L28
*-输出结果(不显示基准组和忽略组的系数)
. esttabR1 using D:/Table_factor_2.csv, nogap///
drop(1.race 0.married 1.race#0.married ///
1.race#1.married 2.race#0.married ///
3.race#0.married) replace
*-输出结果(不显示基准组和忽略组的系数,使用nobase与noomit的选项)
. esttabR1 using D:/Table_factor_3.csv, nogapnobasenoomit replace
删除缺失估计系数值后,模型结果呈表4所示。
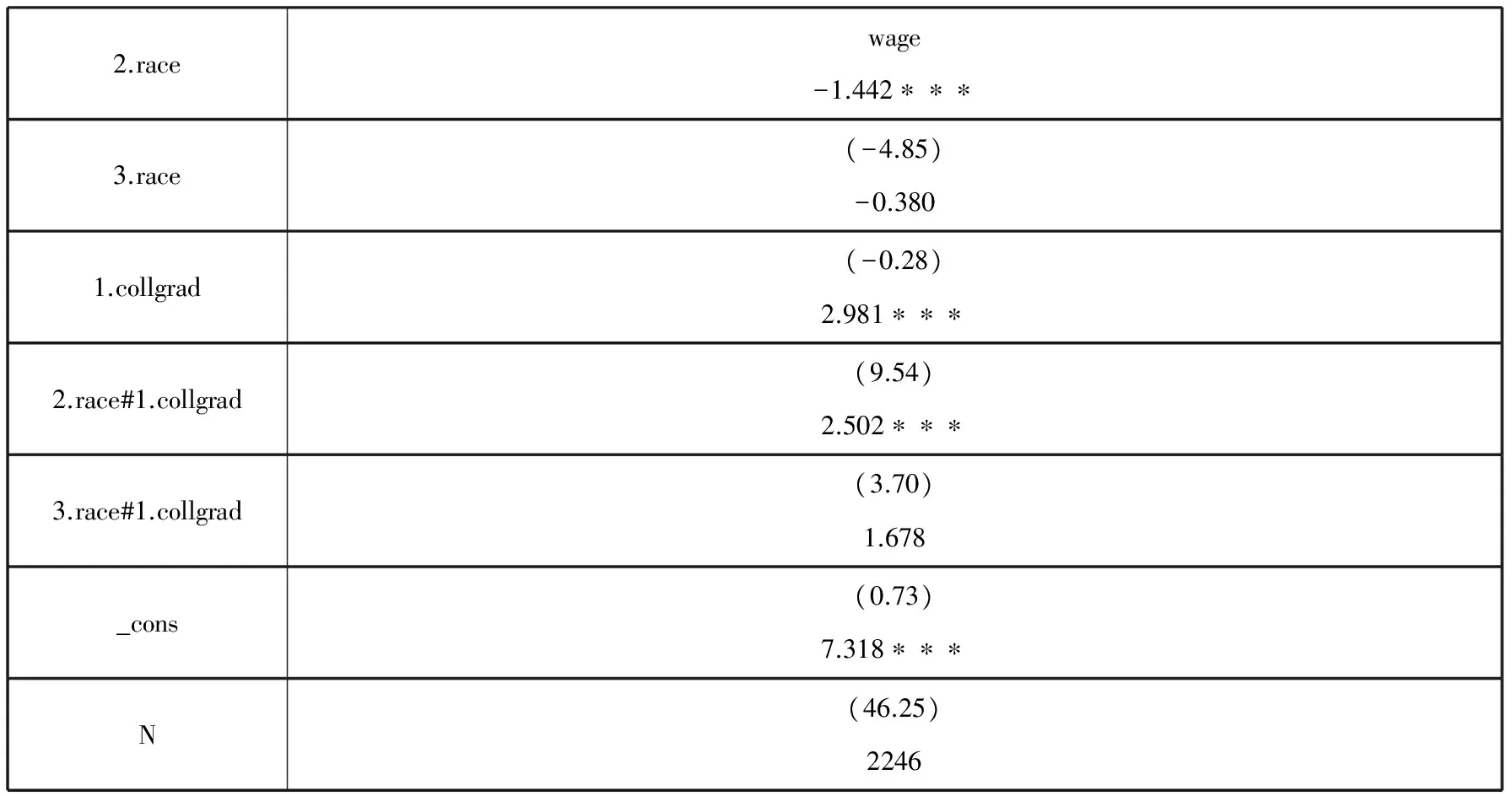
表4 1988年美国妇女工资模型结果(删除缺失估计系数值的变量)
注:括号内为t统计量;* p<0.05, ** p<0.01, *** p<0.001.
六、小 结
本文介绍了Stata中因子变量产生虚拟变量与交乘项的使用方法,以常用经典回归模型为例,提供了它们的Stata命令,并进一步提供了因子变量与margins及marginsplot命令相配合分析边际效应的示例。在Stata中的大多数命令中都可以使用因子变量的表述方法。该方法可以使Stata命令更加简洁,并能够大幅度提高实证分析的效率,但需要注意分析使用因子变量表述方法后得到的模型设定结构。
注释:
①详情参阅Stata帮助文件(help fvvarlist).
②详情参见Stata帮助文件help varlist.
③为了便于说明,后续多数回归命令中都省略了控制变量.
④事实上,只要你的数据中存储了race变量,我们只需要保存好dofile,就无需生成black这个中间比变量.
⑤之所以加入T-1个年度虚拟变量,是为了防止完全共线性.
⑥此处设定i.year会自动加入T个年度虚拟变量,但Stata会自动删除一个,以防完全共线性.
⑦文中实证分析所用的原始数据和相关程序可以从作者主页上下载:http://economics.mit.edu/faculty/acemoglu/data/aa2001.
⑧例如,Altunbas, Liu, Molyneux and Seth(2000)使用超越对数成本函数估算了日本银行的效率和风险;Wang(2007)则使用超越对数生产函数研究30个国家R&D效率;王德祥、李建军(2009)基于超越对数生产函数估算了我国的税收流失率.
⑨Faulkender and Wang(2006)检验了由公司融资约束对现金持有边际市场价值的影响。戴魁早和刘友金(2016)研究发现了要素市场扭曲对创新效率的影响存在着企业差异,企业规模在规避要素市场扭曲对创新效率的抑制效应中具有积极作用。张苏和高扬(2012)的实证研究发现了学生来源于城市或农村地区对国家竞争力的影响作用受到每周上网时间的影响,如果上网时间在每周8小时以下时,城市大学生的学习行为落入“增进国家竞争力导向”上高效率区域而不是低效率区域的概率比农村大学生要高,否则要低.
参考文献:
[1]Acemoglu D, Joshua D Angrist.Consequences of employment protection? The case of the americans with disabilities act[J].Journal of Political Economy,2001,109 (5): 915-957.
[2]Altunbas Y, M-H Liu, P Molyneux, R Seth.Efficiency and risk in japanese banking[J].Journal of Banking & Finance,2000,24 (10): 1605-1628.
[3]Faulkender M,R Wang.Corporate financial policy and the value of cash[J].Journal of Finance,2006,61 (4): 1957-1990.
[4]Kumbhakar S C.Estimation of technical efficiency using flexible functional forms and panel data[J].Journal of Business and Economic Statistics,1989,(7):253-258.
[5]Wang E C.R&d efficiency and economic performance: A cross-country analysis using the stochastic[J].frontier approach,Journal of Policy Modeling,2007,29 (2): 345-360.
[6]戴魁早, 刘友金.要素市场扭曲与创新效率——对中国高技术产业发展的经验分析[J].经济研究,2016,(7): 72-86.
[7]连玉君,廖俊平.如何检验分组回归后的组间系数差异[J].郑州航空工业管理学院学报,2017,(6):97-109.
[8]王德祥, 李建军.我国税收征管效率及其影响因素——基于随机前沿分析(sfa)技术的实证研究[J].数量经济技术经济研究,2009,(4): 152-160.
[9]张 苏,高 扬.大学生学习行为与国家竞争力关联关系的实证研究[J].管理世界,2012,(4): 175-176.
附录1边际效应计算结果
猜你喜欢
娃娃乐园·综合智能(2022年3期)2022-04-19 12:57:10
英语文摘(2021年11期)2021-12-31 03:25:30
反歧视评论(2018年0期)2019-01-23 06:47:22
英美文学研究论丛(2018年2期)2018-08-27 01:56:52
军营文化天地(2018年2期)2018-04-20 07:07:49
时代英语·高一(2017年5期)2017-11-14 05:45:14
现代农业科技(2017年11期)2017-07-14 22:24:01
新闻界(2016年11期)2016-11-07 21:27:56
中国老区建设(2016年9期)2016-02-28 09:34:00
福建农业科技(2015年3期)2015-02-27 10:20:45
