
基于深度学习服务的遥感影像农作物分类系统设计
2018-04-24 02:45:04王丹丹莫东霖
中国农业信息 2018年6期
王丹丹,范 冲,莫东霖
(中南大学,地球科学与信息物理学院,湖南 长沙 410083)
0 引言
我国是人口大国,同时也是农业大国,各类农作物的结构、产量等种植情况,将对国际农作物价格产生较大影响。及时获取并掌握农作物生长信息,意义重大。其时效性也不可忽视,精确并快速地了解农作物情况,无论是对生产管理而言,还是对科学决策避免损失而言,都具有重要意义。
遥感应用于农业的传统方法主要依靠人工解译,由专业人员结合影像光谱特征进行目视解译来获取目标信息,相当费时、费力。后来发展出人机交互解译[1]、多种技术结合的半自动解译[2],丰富了分类方法,改善了分类效果。但由于遥感影像存在“同物异谱”和“异物同谱”的现象,精确的作物分类仍然是一项极具挑战的任务,在这样的背景下,研究者将机器学习算法如神经网络(Neural Networks,NNs)、支持向量机(Support Vector Machine,SVM)等应用于遥感影像的分类,并且在分类过程中加入影像的纹理、结构等特征[3-5]。无论是SVM 还是NNs 都属于浅层学习算法[6],由于计算单元有限,浅层学习的网络很难有效地表达复杂函数,所以随着样本数量的增大以及样本多样性增强,浅层模型也逐渐不能适应复杂的样本。而由多层非线性映射层组成的深度学习网络拥有强大的函数表达能力,最近的研究表明,通过神经网络的特征表示,在大规模图像识别方面[7-9],目标检测[10-11]和语义分割[12-13]均有应用,在复杂分类上具有很好的效果和效率[14]。2014 年,Chen Y 等[15]首次应用深度学习的自动编码器进行高光谱数据分类,并取得了良好的分类结果。赵爽[16]首次将卷积神经网络模型应用于遥感图像分类试验,将影像分为建筑、裸地、水体3 类,发现与传统分类方法相比,卷积神经网络分类结果精度较高,并且用时较短。曹林林等[17]利用卷积神经网络的方法,对高分遥感影像进行分类,提取了林地、草地、房屋、道路、裸露地表5 类地物,并验证了卷积神经网络可应用于高分遥感影像分类。Ji S 等[18]提出了一种三维卷积神经网络的方法实现了时空遥感影像农作物的自动分类。段友祥等[19]提出一种改进的Alexnet 模型,实现了油井抽油机示功图的自动识别,并与目前常用的神经网络模型进行了比较,发现改进的Alexnet模型在保证识别准确率高的同时有效降低了训练学习时间,很好地达到了实际应用要求。
基于深度学习在图像分类方面的显著效果,利用深度学习的技术对遥感影像进行作物分类,但深度学习对机器的硬件配置要求很高,而且网络模型庞大,训练时间和实际运行时间都比较长。因此,系统通过搭建深度学习服务器降低对客户端机器配置的要求,并使用改进的Alexnet 深度学习模型,在保证分类精度的前提下加速了模型的收敛速度,通过客户端与服务器的交互实现了可视化的深度学习模型训练和影像分类的任务,节省人力、物力和财力,为遥感技术在农业应用中的发展、农作物面积统计工作和对农业资源进行优化配置提供重要的科学指导,解放人类劳作,变人工作业为自动化专题分类产品的生产。
1 深度学习服务器
深度学习是机器学习中的一种,其借鉴人脑结构构建多层神经网络,对数据进行不断地训练,训练过程使用特征组合、特征离散化等非线性操作获取更高抽象程度的数据特征,在一系列复杂分类问题的解决上表现优异。然而深度学习训练过程资源消耗大,其良好的性能表现是依赖大量性能强大的计算设备的支撑,为了降低对客户端的配置要求,借助云计算等相关技术搭建深度学习服务器,以容器为基础打造PaaS 平台,提供计算服务,统一处理客户端模型训练、影像分类等深度学习任务。
1.1 PaaS 平台
平台即服务(Platform as a Service,PaaS)是一种云计算服务,提供运算平台与解决方案服务。在云计算的典型层级中,PaaS 层介于软件即服务与基础设施即服务之间。PaaS 提供用户将云基础设施部署与创建至客户端,或者借此获得使用编程语言、程序库与服务。用户不需要管理与控制云基础设施(包含网络、服务器、操作系统或存储),但需要控制上层的应用程序部署与应用托管的环境。PaaS 提供软件部署平台(runtime),抽象掉了硬件和操作系统细节,可以无缝地扩展(scaling)。开发者只需要关注自己的业务逻辑,不需要关注底层。PaaS 的典型应用有Google App Engine、Sina App Engine。阿里、腾讯等的机器学习计算服务,也大多以这种形式提供。
机器学习特别是深度学习是一个复杂的探索性过程,其新理论、新方法正不断涌现。新方法的爆炸性增长意味着需求频繁变动,这给系统的开发、维护带来极大的困难。在极为有限的资源下,稳定性、可维护性和弹性这些对于深度学习服务器来说是至关重要的指标了,因此服务器选择开发难度适中、安全性适中、资源调配灵活且能最大化满足未来需求的PaaS 形式。
1.2 隔离
由于PaaS 系统是一个多租户系统,意味着多个用户的任务共享同一套执行环境。这种情况下,用户蓄意或者无意的破坏执行环境,进而影响到其他用户使用计算服务甚至导致其他用户数据泄露、丢失,这些都是必须着重考虑的问题。为此,必须引入一个机制隔离不同用户的资源,服务器选择了成熟的Docker 容器。
容器在系统内核命名空间层面完成了进程间的隔离。容器内运行的程序有自己的根目录、自己的网络连接且无法直接访问容器外的进程,一般情况下容器内所做的更改不影响实际操作系统。容器在外部表现上像是一个轻量化的虚拟机,得益于容器是位于系统内核之上的隔离,用户程序的依赖库均可部署也必须部署在“容器镜像”中 ,因为用户程序无法直接访问容器外的环境。部署时只需要安装Docker 管理器和任务管理器,与用户程序有关的东西(如Caffe、GDAL 等)均位于容器镜像中,容器镜像只需拷贝并导入Docker 管理器即可立即使用。
目前,市面上主流的深度学习框架包括包括TensorFlow、Caffe、Keras、Torch、MXNet、Theano 等,Caffe 是其中较为成熟和完善的一个深度学习框架。考虑到遥感影像复杂的特性和Caffe 性能强大且简单易用的优点,系统目前提供的是Caffe 这个主流的深度学习框架。后期若需加入对Tensorflow、PyTorch 等主流的深度学习框架,只需一次性修改或者创建对应的镜像,并导入服务器。不需要在服务器上重复进行繁琐的依赖库编译、部署操作,保证系统部署和维护的简便性。
2 深度学习模型
基于卷积神经网络(Convolutional Neural Network,CNN)的深度学习算法,可以自主学习农作物特征减少人工干预,对于复杂背景的遥感影像能排除噪声干扰等,提高识别效率。CNN 有很多模型,其中Alexnet 就是经典的CNN 模型。AlexNet 是2012 年ImageNet 竞赛冠军获得者Hinton 和他的学生Alex Krizhevsky 设计的[7]。目前,AlexNet深度神经网络已广泛应用于图像识别方向,是近年来计算机视觉领域取得的一项重要突破。
但Alexnet 模型比较庞大,训练时间和实际运行时间都比较长,不适合实际的农作物自动分类的应用要求。因此,系统使用简化的AlexNet 深度学习模型,减少了模型层数和参数,模型结构如图1 所示。
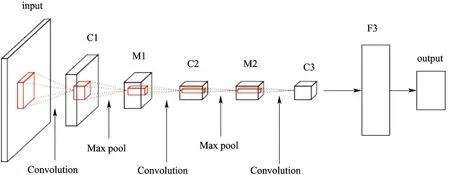
图1 网络模型Fig.1 The network model
网络总共有4 层,其前3 层是卷积层,后一层是全连接层,全连接层输出的softmax数即农作物类别数。第一个卷积层C1 中,得到基本卷积数据后,先进行pooling,然后进行一次Relu 以及Norm 变换,作为输出传递到下一层。第二个卷积层C2,对M1 进行一次Relu 后,进行pooling 池化,然后进行Norm 变换。第三个卷积层C3 与第二个类似,对上层进行一个Relu 后,进行pooling 池化。全连接F3 是接上一个C3 进行池化后的全连接层。最后输出为融合label 的softmax loss。网络中各个层发挥的作用如表1所示。

表1 网络结构Table1 The network architecture
3 系统开发
3.1 系统运行环境
该系统运行环境规定一台储存服务器、一台计算服务器以及客户机若干,储存服务器使用标准FTP 协议,计算服务器使用XML-RPC 协议,只支持HTTP 基本认证(RFC 1945)。服务器和客户端通过异步RPC 实现网络通信,FTP 实现数据传输,可以实现多用户的并发访问。系统的总体架构如图2 所示。
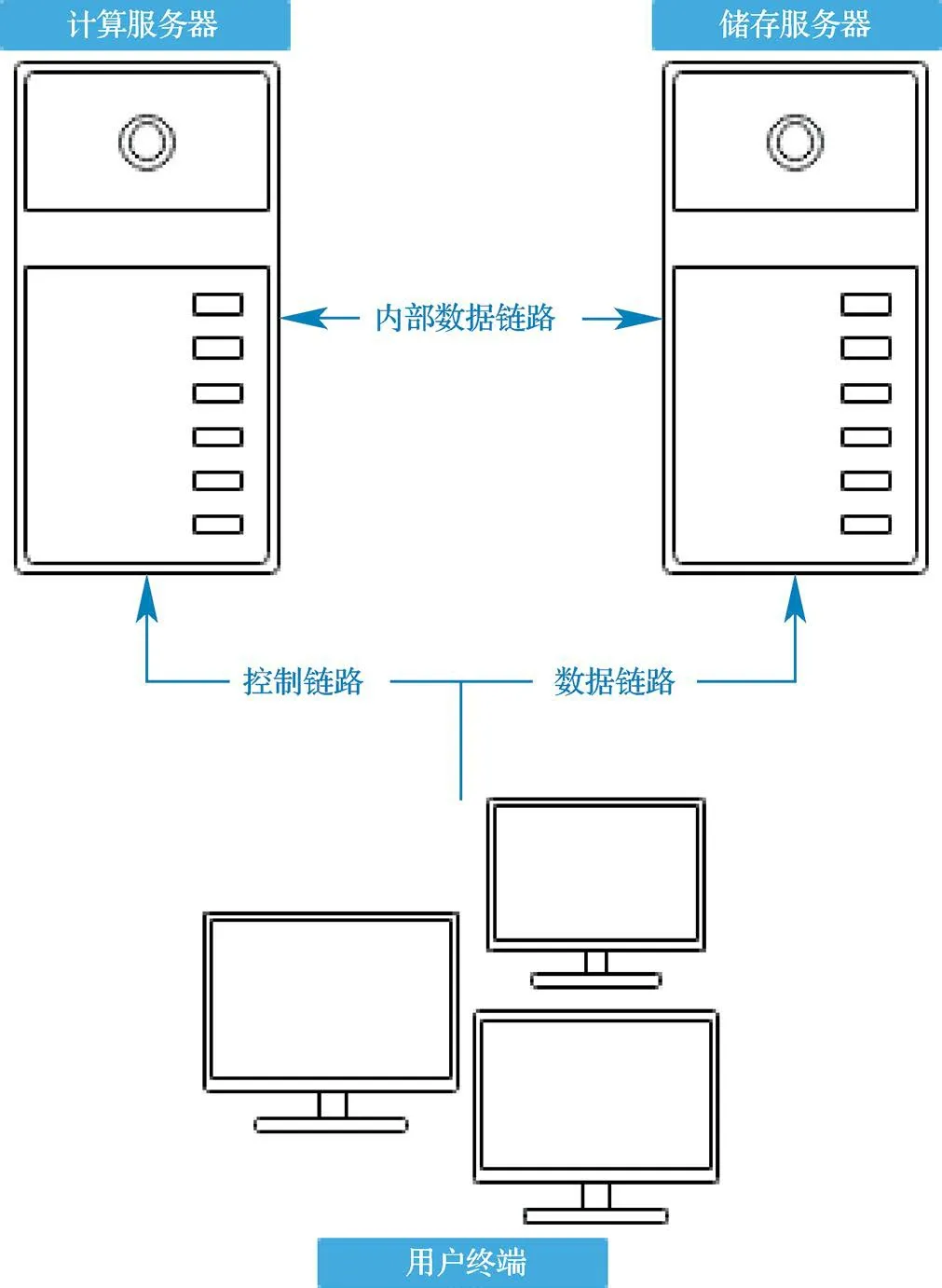
图2 系统的总体架构Fig.2 The overall architecture of the system
系统运行的基本性能要求包括桌面式服务器(1 个8 核Intel Core I7-7700 3.6 GHz、32GB 内存、1 个240G SSD、1 个4T HDD、1 个NVIDIA GeForce GTX 1080 Ti)、客户端操作系统要求WIN10/WIN7、内存2G、CPU 双核处理器。
3.2 系统功能设计
基于深度学习服务的农作物分类系统主要包括地图操作、数据传输、深度学习模型参数自适应、自动识别分类和成果展示与制图五大模块(图3)。
地图基本操作。各个用户功能界面基本都有地图操作的功能,地图显示的数据主要包括遥感影像底图、农田地块图斑矢量数据和分类结果数据,视图操作包括放大、缩小、全图、平移、固定比例放大、固定比例缩小、前一视图、后一视图、标识等功能,数据查询主要包括属性查询。通过地图基本操作模块可以实现数据的可视化和属性查询功能。
数据传输。数据传输模块主要包括数据的上传和下载两部分,实现用户、客户端和服务器之间的通信。
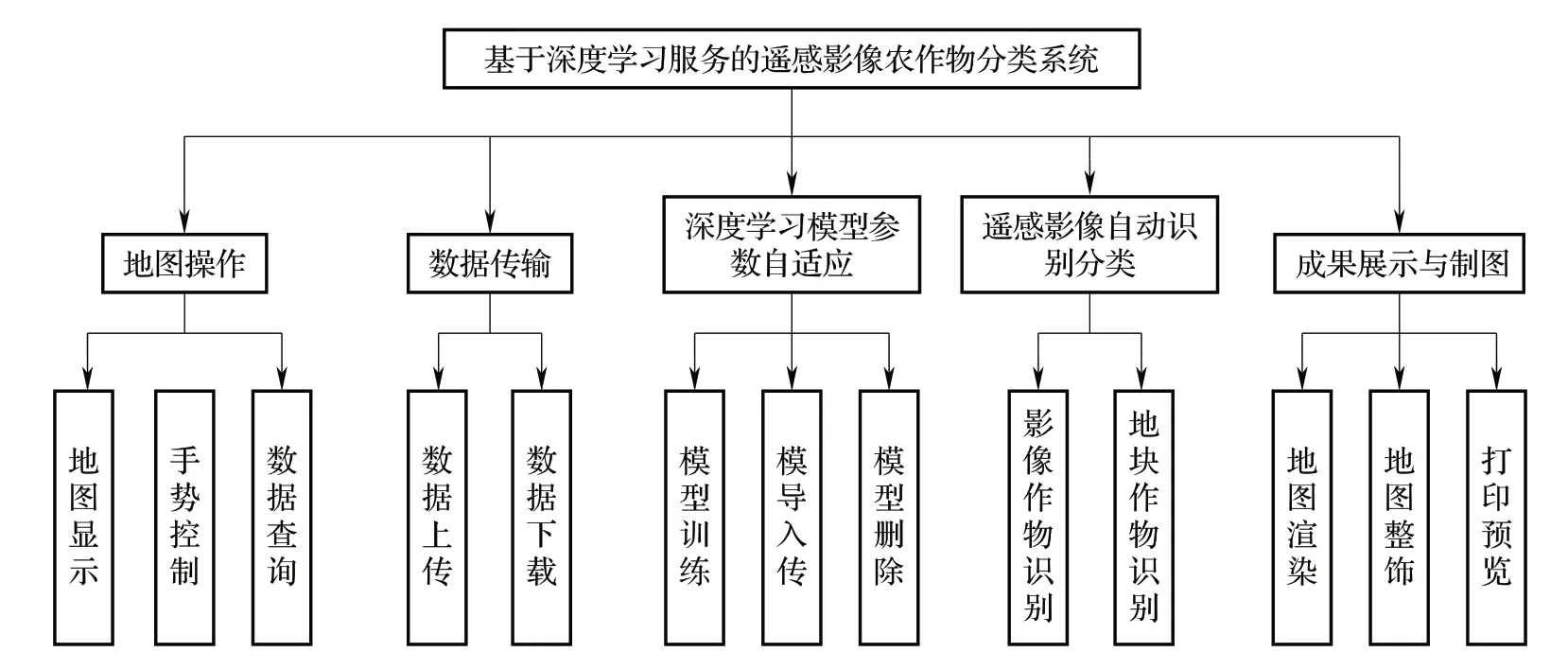
图3 系统的功能模块Fig.3 The function module of the system
深度学习模型参数自适应。由于现有模型的自适应能力不够,导致外界情况改变时,特征技术无法对外界变化产生同步调整,存在过拟合现象。因此,深度学习模型参数自适应模块通过持续的训练,研究确定适合当前样本数据的卷积神经网络参数,主要包括学习率、动量等超参数,从而进一步优化遥感数据光谱和空间分辨率组合,获取最优的农作物分类结果。本模块包括模型训练、模型导入和模型删除等功能。
自动识别分类。模块主要包括遥感影像农作物分类和地块作物识别两部分,选择训练好的农作物分类模型,输入待分类数据,即可实现遥感数据的农作物自动分类,得到高精度的分类结果。
成果展示与制图。模块通过导入农作物分类结果,采用分级设色、唯一值等渲染方式进行栅格数据显示,并可以添加图例、指北针、比例尺等地图要素后输出农田作物覆盖专题图。
3.3 测试应用
结合野外样方采集成果数据和2015 年的GF-2 卫星4 m 分辨率的多光谱遥感影像数据,共提取4 m×4 m 大小的训练样本428144 个(玉米134824 个,大豆85336 个,水稻101424 个,建筑物17520 个,林地59416 个,水体29624 个),其中358016 个样本用于模型训练,另外70128 作为模型训练过程中的测试数据。实验采用快速训练策略,共计完成10 万次训练。系统训练时间是1.12 h,仅为单机训练(3.283 h)的1/3。模型训练过程的loss 和accuracy 如图4 所示,在前14000 次训练中,loss 迅速降低,模型精度逐渐提高,之后,模型整体精度达到了0.93,loss 下降缓慢,到最后基本维持在0.95 左右。训练过程中没有出现过拟合现象,网络参数设置也比较合理,得到的模型满足精度要求。实验表明,系统使用服务器进行训练,与单机训练相比,不仅提高了模型训练的速度,还降低了客户端的配置要求。同时系统使用的简化的Alexnet模型在保证识别准确率高的同时也有效降低了训练学习时间,很好地达到了实际应用要求。
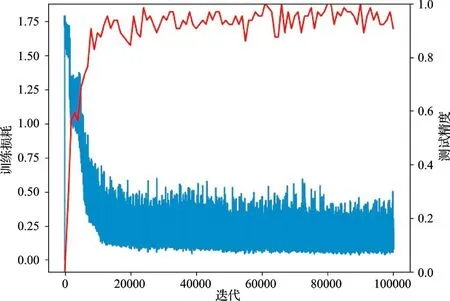
图4 深度学习模型损失值和精度曲线Fig.4 The loss value and accuracy curve of deep learning model
4 主要功能展示
4.1 模型训练
遥感数据具有高维、多尺度、非平稳的内部特性和海量、多源、异构的外部特征,包含丰富的空间信息。经典深度学习的方法通过分层学习来得到一种高级抽象数据的架构,模型训练通过优化学习率、动量、迭代次数等超参数,确定适合当前样本数据的最优参数,得到适合遥感数据效果最优的分类模型。模型训练的过程中,服务器每隔1000次会返回训练的精度和损失值,客户端实时显示(图5),帮助用户更加方便直观的观测训练的整体趋势从而判断分类模型的好坏。若用户觉得模型不收敛,可以修改参数重新训练;若模型分类精度高,通过模型导入到遥感影像自动识别分类模块,即可用于遥感影像或者地块的农作物自动分类识别。
4.2 遥感影像农作物识别
像元是遥感影像中最基本的单元,遥感影像农作物分类采用像元级分类的方法,综合考虑窗口内部的结构纹理以及相邻像元之间的关联信息,将窗口的分类结果赋予中心像素,从而得到像元级的分类结果(图6)。分类结束,系统会根据标签文件对分类结果进行栅格渲染后加载到视图中,以便用户更加直观、形象地了解作物的种植结构。
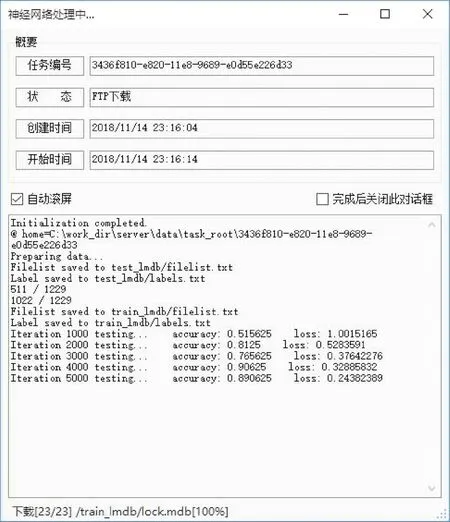
图5 神经网络处理对话框Fig.5 The dialog box for neural network processing
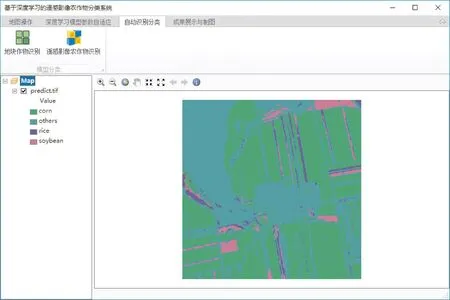
图6 影像分类结果Fig.6 The result of image classification
4.3 地块作物识别
地块是农作地区最重要的景观要素,传统的地块分类采用人工的方式,耗时耗力。地块作物识别利用深度学习的方法快速准确的判断地块的作物类型。地块作物识别采用随机取样的方法,从每个地块均匀的选取若干个样本,然后利用训练好的深度学习模型对样本进行分类,最后用多数投票的原则确定地块最终种植的作物类型(图7)。地块作物识别克服了人为干扰,准确性好,同时节省了大量的人力、物力和财力。
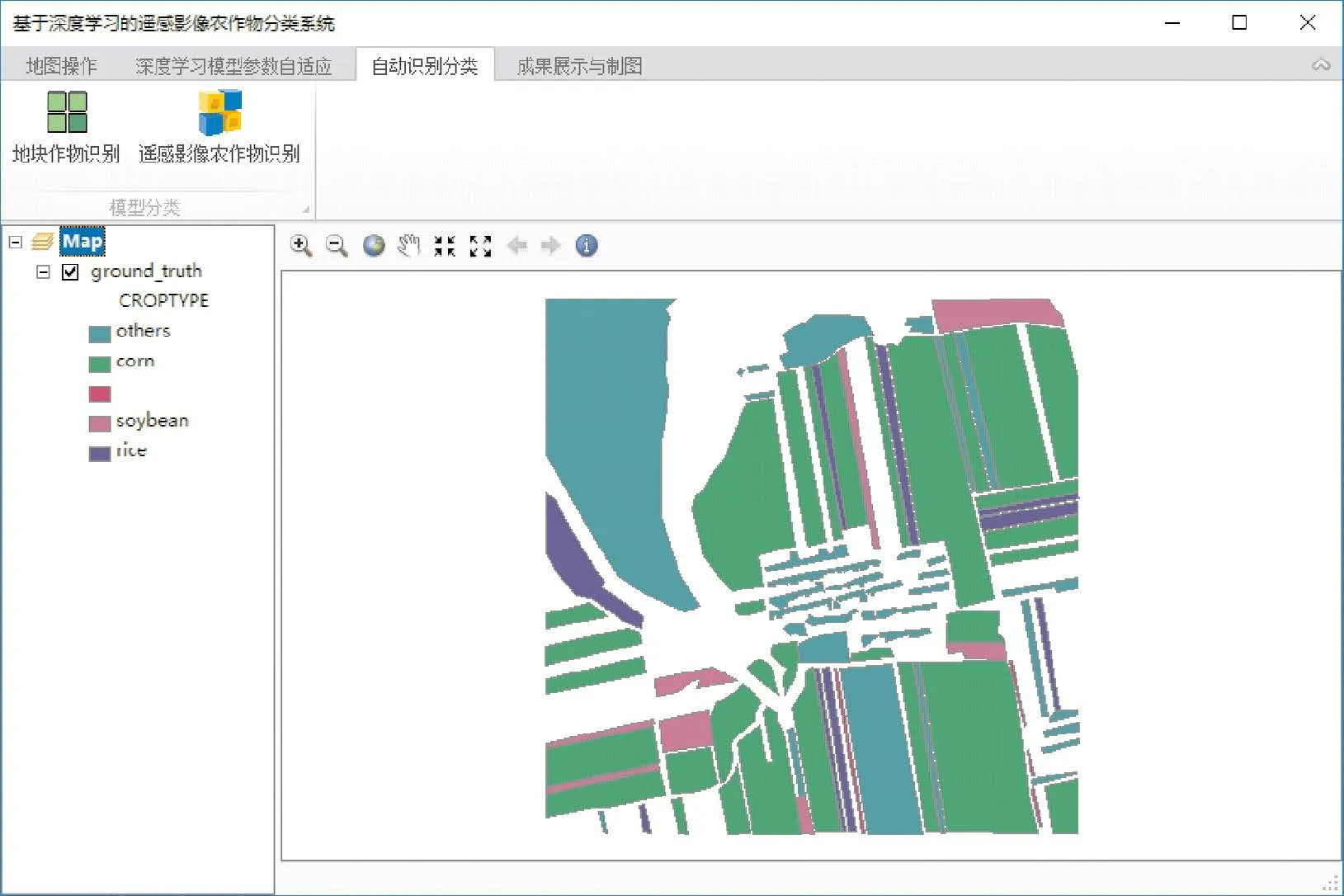
图7 地块识别结果Fig.7 The result of block classification
5 结束语
该系统采用时下流行的深度学习技术对遥感影像进行农作物分类,顺应了遥感农业智能化的趋势。同时考虑到深度学习对机器配置要求很高,系统部署深度学习服务器,提供主流的Caffe 深度学习框架,通过PaaS 提供计算服务,统一处理客户端的深度学习任务,从而降低客户端的IT 成本。服务器采用容器隔离解决资源冲突的问题,保证了系统的灵活性和可扩展性。系统利用CNN 的深度学习方法进行模型训练得到分类模型,然后进行遥感影像农作物识别,得到精确的农田作物覆盖的专题图,为作物的生产管理提供空间尺度的有效指导。
服务器目前仅部署了Caffe 的深度学习框架,今后将集成更多主流的深度学习框架,如TensorFlow、Keras、PyTorch 等。此外,为了保证农作物分类的时效性,系统使用简化的AlexNet 网络结构,今后将考虑应用深度学习分类效果更好的算法,比如利用深度学习影像分割技术,提高大规模作业的效率。
猜你喜欢
军事文摘(2024年6期)2024-02-29 10:01:50
今日农业(2022年16期)2022-11-09 23:18:44
今日农业(2022年15期)2022-09-20 06:54:16
今日农业(2022年13期)2022-09-15 01:19:08
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
传媒评论(2018年4期)2018-06-27 08:20:24
传媒评论(2018年4期)2018-06-27 08:20:16
电子测试(2018年10期)2018-06-26 05:53:34
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
