
基于大数据和机器算法的规划需求价值评估研究
2018-04-19 06:15胡博赵兰奇张丹
电信工程技术与标准化 2018年4期
胡博,赵兰奇,张丹
(中国移动通信集团陕西有限公司,西安 710077)
为支撑滚动规划需求流程,提供规划站址审核参考依据,体现规划站址建设价值,利用全省现网站点模拟规划需求站址评分,从网络覆盖结构、容量、客户价值、潜在价值需求等多方面,引入机器学习算法,进行流量预测,实现基于价值的规划评估体系。
通过机器学习建模分析无线区域规划流量价值的准确性、高效性是本技术方案的关键所在。由于无线网络在不同环境和状况下存在很大差异,为了保证不同场景、不同区域、不同网络的规划区域流量预测的准确性真实性,需要建立一套客观准确的模型。因此,传统的基于比重因子的评估算法不能完全有效的解决流量价值评估真实有效的问题,从而无法达到指导各地市准确建设目的。
使用全省共78 623个4G和2G基站的基础数据,以4G基站所在经纬度和区域类型分类,对4G和2G基站分别进行统计,并去除覆盖范围内站点数为0及其它指标正常而流量为0的基站等异常数据,通过相关性研究,最终确定特征变量:使用MR弱覆盖比例、平均RSRP、2G高倒流时长、平均站间距、2G流量、4GRRC用户数量、4G客户、4G累计驻留时长、4GDOU等9个特征变量,采用“决策树”算法作为预测基站价值(流量)算法,通过提取现网指标、数据,完成机器学习,并对算法进行验证分析,准确率达到87%。
同时,为避免原规划价值评分体系中的人为因素,本次在价值评分体系搭建时充分利用其它平台可利用数据来源代替手工填写,并完成数据的自动匹配与计算。数据主要来源于FAST平台、网优平台2.0及ATU测试管理平台。避免了原价值评分体系信息大多数来自各地市规划人员手工填写,既减少了地市规划人员工作量又提高了价值评分可参考性。
1 研究背景与意义
1.1 规划需求日益增多
随着全省规划工作的持续开展,种类繁多的站点需求不断增多,全省规划质量管控平台逐步代替了传统方式规划站址的工作,在历届工期规划中,来源于全省规划质量管控平台的站址数占比增幅明显截至5-2期已达到94.08%,已经实现了站址规划全面管控,在需求大量累积,审核任务繁重的情况下,需要平台提供一种客户价值依据,为站址规划、站址审核提供参考,提高站址规划及审核效率。
1.2 减少人工干预因素
原规划评分体系中,价值评分项13项,除部分网络数据可从系统提取外,其它市场、建设数据均为人为填写,数据准确性及可靠性均存在较大争议。
因此,为体现站址规划需求的客观价值,需要一套尽量避免人工干预,数据可信、统计科学、评分切合实际价值的价值评分体系。
1.3 提供站址审核的刚性标准
目前全省规划质量管控平台站址需求审核基本由人工完成,审核人员对站址需求理解各有差异,多数依靠站址需求描述和测试报告等,在审核标准上缺少完善的刚性尺度,经常造成审核过度严格或过度宽松,因此需要一套客观价值数据为审核人员提供站址需求参考,使站址需求能够切合实际现场环境。
1.4 潜在价值的主动规划
通过一套完善的价值评分体系,可以尽早的发掘出具备较大规划价值的潜在规划需求,改变以往存在价值再规划,建设周期长导致客户流失或感知下降的恶性习惯,通过主动推送潜在价值规划促进网络建设。
2 数据处理与大数据分析模型
2.1 数据清洗
根据可能会影响流量的因素去预测基站建站后的流量,但在分析数据时,我们发现存在一些数据的数值显然不能反映预测的一般趋势,属于异常数据,需要将它们剔除(如图1所示)。
(1)某些基站在其它因素都正常的情况下出现流量为零的情况。
(2)基站平均站间距不正常(工参不准)的区域予以剔除,例如某些基站的平均站间距超过了10 000 m。
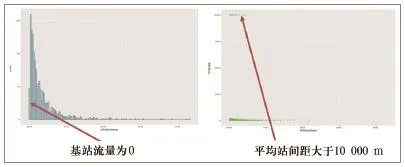
图1 数据清洗
2.2 变量相关性分析
剔除不合理数据后分析下变量间的相关性。由相关性分析,我们发现流量与用户数量,4G流量等相关性较强。可以从如图2所示的所有变量间的散点图上看出。
2.3 基于大数据分析
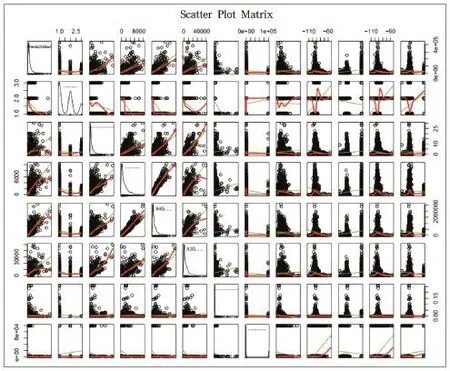
图2 变量相关性分析
数据来源:为确保数据的客观性和真实性,此次基于大数据的规划价值评估体系使用的数据均来自系统相关平台,其中MR弱覆盖比例、平均RSRP来自于FAST平台;2G高倒流时长、4G客户数、4G累计驻留时长、4G客户数来自于经分统计数据;4G流量、2G流量、4GRRC用户数量来自于网优平台;平均站间距来自于规划系统。
数据数量:全省共78 623个4G和2G基站数据,其中4G基站数量46 088个,4G小区数量112 291个,2G基站数量32 535个,2G小区数量75 123个。并通过网优平台提取日均流量、RRC连接数等指标,FAST平台计算4G小区RSRP10×10 m栅格数内的平均电平,以及RSRP值小于等于-105 dB的10×10 m栅格数占总栅格数的比例,经分系统中的每小区下的4G客户数、4G累计驻留时长、4G客户数等,充分运用大数据分析,提高价值评估的合理性和准确性。
使用全省共78 623个4G和2G基站的基础数据,使用MR弱覆盖比例、平均RSRP、2G高倒流时长、平均站间距、2G流量、4GRRC用户数量、4G客户、4G累计驻留时长、4GDOU等9项指标,进行数据分析,得到相关较强的评分项目。
3 构建机器学习模型预测基站流量
3.1 决策树算法
3.1.1 决策树思想
决策树是一类常见的机器学习算法,是指对一个问题进行决策时,我们通过一系列判决或子决策,进而得到最终决策。
一棵决策树包含一个根节点,若干个内部节点和若干个叶节点;叶节点对应于决策结果,其它每个节点对应于一个属性测试;每个叶节点的路径对应一个判定测试序列。其基本流程遵循简单且直观的“分而治之”策略。
决策树学习的关键是如何选择最优划分属性:随着划分过程的不断进行,决策树分支节点所包含样本尽可能属于同一类别,即节点的“纯度”越来越高。基尼指数反映了从某一数据集中随机抽取两个样本,其类别标记不一致的概率。因此,基尼指数越小,数据集的纯度越高。CART (Classification And Regression Tree)算法是一种决策树分类方法,使用基尼指数来选择划分属性。
3.1.2 CART算法
CART算法是一种决策树分类方法,使用基尼指数来选择划分属性。CART算法的目的是使分支节点所包含样本尽可能属于同一类别,即节点的“纯度”越来越高。具体算法如下。
假定样本集合D中第k类样本所占比例为:pk(k=1,2,…,|y|),则集合D的基尼指数可表示为:
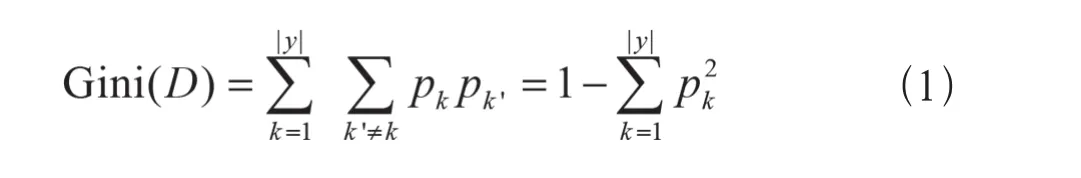
由上述公式可知,基尼指数表征随机抽取两个样本,类别不一致的概率。所以最优划分属性的计算,就是寻找基尼指数最小的划分,即类别尽量一致。
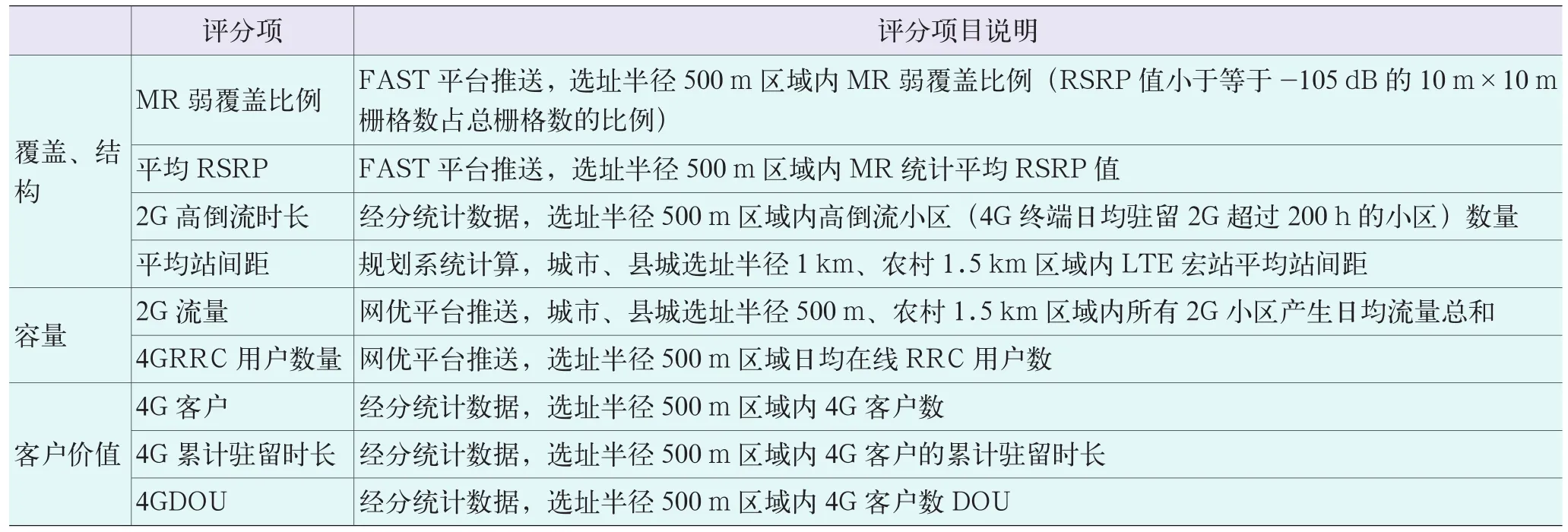
表1 评分项目说明
若使用属性a来对样本集D进行划分,产生V个分支节点,其基尼指数为:
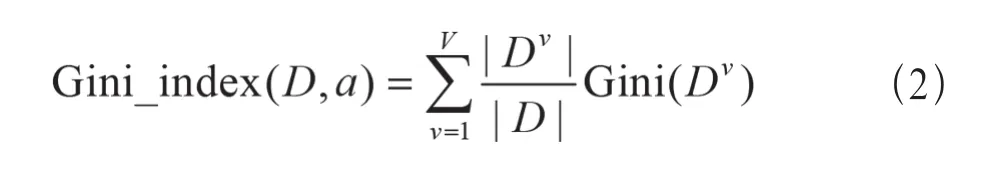
则最优划分集为:
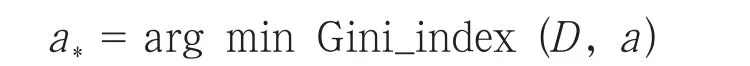
3.2 构建决策树
3.2.1 决策树模型建立
确立算法后,构建决策树模型的流程如下。
(1)根据CART算法选择最优划分属性。
(2)对于不能再切分的节点,则将该节点存为“叶子节点”。
(3)对于可以再切分的节点,按照最优划分属性将数据集切分成若干个子树。
(4)对每个子树进行“构建树”。
根据9个相关变量:MR弱覆盖比例、平均RSRP、2G高倒流时长、平均站间距、2G流量、4GRRC用户数量、4G客户、4G累计驻留时长、4GDOU,根据CART算法构建决策树模型。图3为一棵决策树的一枝子树的构建结果。
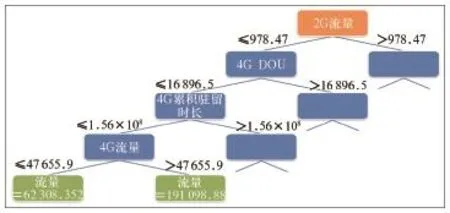
图3 决策树的一枝子树的构建
3.2.2 剪枝
(1)为防止模型把训练集自身的一些特点当做所有数据都具有的一般性质而导致过拟合,需要去掉一些分支降低过拟合的风险,去掉分支的这个过程即为剪枝。
(2)剪枝之后的决策树,可作为机器学习的模型进行试用,对测试样本进行预测,并统计误差。
3.2.3 随机森林
(1)森林:为保证模型的可泛化性,构造500棵决策树,决策结果为500棵的统计平均值。
(2)随机:从总测试样本中随机抽取样本集合,作为每棵树的根节点样本集。
在建立每一棵决策树的过程中,有两点需要注意——采样与完全分裂。首先是两个随机采样的过程,Random Forest对输入的数据要进行行、列的采样。
对于行采样,bootstrap方式:采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。
注: bootstrap方式采取有放回抽样,因此,针对N个样本中的某一个样本,可能不被选中,也可能被选中多次,这样组合成为一组训练集(N个样本)。
然后进行列采样,m个feature就是用来做决策的:从M个feature中,选择m个(m<< M)。之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本都是指向的同一个分类。一般很多的决策树算法都有一个重要的步骤——剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现过拟合。
3.3 基于决策树的流量预测
通过构建树、剪枝等方式,建立基于决策树的预测。预测是指利用机器学习建立的模型,对新入数据集进行判决,所得到的结果即为预测结果。对于决策树而言,就是让数据集进过若干次属性判决,直至到达某一叶子节点,即为预测结果。
预测模型数据源及特征变量参数如下。
(1)数据:全省共78 623个4G和2G基站。
(2)数据处理:以4G基站所在经纬度和区域类型分类,对4G和2G基站分别进行统计,并去除覆盖范围内站点数为0及其它指标正常而流量为0的基站等异常数据。
(3)特征变量:MR弱覆盖比例、平均RSRP、2G高倒流时长、平均站间距、2G流量、4GRRC用户数量、4G客户、4G累计驻留时长、4GDOU。
(4)设置森林树木为500棵。
(5)样本与测试集:选取70%数据作为训练集,另外30%数据作为测试集。
预测结果如图4所示。
真实标记若为预测值的1/2~2倍之间,则认为预测合理。从图中可以看到,87%的测试样本分布在实际值的1/2倍线和2倍线之间。
3.4 交叉验证
我们对原始数据进行了4次随机抽样,可以看到如图5所示,大部分点仍然在两条线之间。
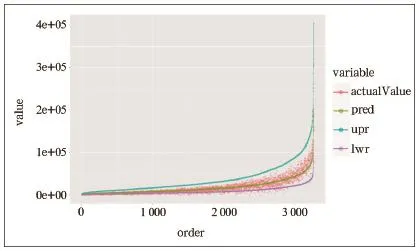
图4 决策树预测结果
4 应用情况
4.1 完成需求流量预测,并输出价值评分
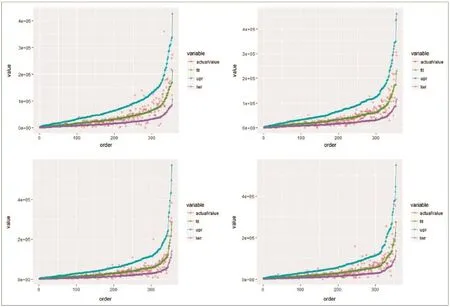
图5 交叉验证输出结果
如图6所示,原规划需求中的评分项多为人为填写,因此价值评分结果较高,基本达到60分以上,对规划的价值参考意义不大。为了减少人为主观因素对规划站址的影响,引入机器学习算法,客观评估规划站点价值,由人工审核价值变为智能线上审核。价值审核更为客观,准确性、可靠性强。
在全省规划管控平台上,已完成基于价值的规划需求评估算法的实现,并根据流量预测进行价值的评分。系统根据得分,自动完成需求的价值判决,将价值评分低于60分的需求,在需求提出后,不纳入预批复环节,将自动进入需求资源库,确保规划调整资源的效益。通过流量预测得到的价值评分,目前需求库中共有2550个需求分值小于60分。
4.2 提高规划需求评分的精准性,确保网络质量
全省现网宏站日均流量18.1 GB,规划需求价值评估体系落地后,新增宏站日均流量达27.9 GB,每日高出9.8 GB。说明基站建设在更有客户需求的地点,规划点位精准,有效提升了网络质量。
4.3 经济效益
规划需求价值评估体系落地后,新增宏站日均流量每日将高出9.8 GB,按每M流量收入0.01元,业务收入无线再分配系数为38%,若每年新增4G基站6 000个,则预计每年将新增效益:
(27.9-18.1)×1 024×365×0.38×0.01×6 000=8 351.29万
针对系统投入后3季度已入网的3 357个基站进行流量统计,较去年同期入网基站,日均增加9.8 GB,则3季度较去年同期新增效益:
9.8 ×1 024×0.01×0.38×3 357×92=1 177.73 万
4.4 社会效益
基于大数据和机器学习的规划需求价值评估体系,有效解决了公司投资效益和规划需求价值之间的矛盾,针对全省的上万个规划需求,通过引入大数据分析和机器学习算法,实现规划站点的流量预估和价值评分,科学、合理的选取预期价值较高的规划需求进行解决,实现了以价值为导向,在满足业务发展的同时,确保了投资收益的最大化。在实际应用中,2017年3季度入网基站的日均流量,较去年同期提升18%;此外,本项目的流量预估和价值评分结果获得各分公司相关部分的高度认可,协助了各分公司规划部门更加高效的对LTE规划需求、规划变更目标进行价值判决。
精确的规划价值预估,为打造良好的LTE网络规划质量奠定了坚实的基础,为陕西建设精品4G网络创造了良好的条件,陕西4G网络建设、运行质量显著提升;用户4G业务体验良好,改善了用户对4G网络的感知度,为陕西移动4G品牌创立良好口碑打下坚实基础。

图6 全省规划管控平台规划需求评估
5 结论
本文从网络覆盖结构、容量、客户价值、潜在价值需求等多方面切入,基于大数据分析,并引入机器学习算法,进行规划站址的流量预测,实现基于价值的规划评估体系。本文使用陕西全省共78 623个4G和2G基站的基础数据,通过数据清洗和相关性研究,以现网指标及数据构建机器学习模型,采用“决策树”算法作为预测基站价值(流量)算法。并对算法进行验证分析,准确率达到87%。该研究目前已全面投入应用,为规划需求价值评估提供科学合理的评分预测,为规划投资效益参考提供有力的评估依据。
(1)本评估方法准确率高,经过大范围验证可达到87%,比传统方法至少提升2倍。同时,通过机器学习技术对现网不同场景、地域的小区相关数据进行学习,找出不同区域、场景的实际特征,进而针对不同环境下的小区得出一个分析模型,可完全真实反映实际的价值情况。
(2)该评估方法非常客观真实,中间过程不会涉及到人工参与,对于规划价值评判起到标尺作用,可以有效把控规划评估的关键环节。
(3)数据处理的效率高,通过自动的方式从不同系统接入数据,通过机器学习科学建模,并且自动修正,进而得到客观真实结果。可以有效减少规划评估工作的周期。
(4)可以有效的减少人工环节,降低工作量,节省人力成本。
[1] 周志华. 机器学习[M]. 北京: 清华大学出版社, 2016.
[2] Stefania Sesia, Issam Toufik, etc. LTE-The UMTS Long Term Evolution:From Theory to Practice[M]. US: Wiley, 2009.
[3] Peter Harrington. Machine Learning in Action[M]. US: Manning Pubns Co,2012.
[4] Simon Haykin. 神经网络与机器学习[M]. 北京: 机械工业出版社,2014.
[5] Daniel,D., Gutierrez. 机器学习与数据科学—基于R的统计学习方法[M]. 北京: 人民邮电出版社, 2015.
[6] LTE无线网络规划与设计编委会. LTE无线网络规划与设计[M].北京: 人民邮电出版社, 2012.
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
安徽农业科学(2016年4期)2016-10-21
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
中国交通信息化(2016年8期)2016-06-06
水利规划与设计(2015年5期)2015-12-15
移动通信(2015年17期)2015-08-24
郑州大学学报(医学版)(2015年1期)2015-02-27
