
基于小波分析和超级向量的非对称文本相关的说话人识别模型
2018-04-19 05:09雷磊佘堃
信息安全研究 2018年4期
雷 磊 佘 堃
(电子科技大学信息与软件工程学院 成都 610054)
(worldDrifter@163.com)
说话人识别技术是一种使用说话人语音样本识别说话人身份的技术.该技术被广泛应用在身份认证系统中.为了提高识别准确性,文本相关的说话人识别模型被广泛运用到访问控制系统中,比如电话银行、声纹锁等.在传统的文本相关的识别模型中,训练语音和测试语音的内容(文本)相同且固定.由于训练语音内容通常公开,所以攻击者就可以通过合成语音的方式模仿用户而获取访问权限.换句话说,传统文本相关的说话人识别模型无法有效防止合成语音攻击.另外,外部噪音也会使得说话人模型性能下降.因此,找到一种能够防止合成语音攻击且对噪音不敏感的说话人识别模型是非常必要的.
说话人识别模型通常分为2个模块:特征提取和说话人分类.在特征提取模块中,语音样本被转化为语音特征(也被特征向量).这些特征中包含了仅和说话人相关而和语音内容无关的信息[1].在说话人分类模块中,一个学习算法对特征中的信息进行归纳并建立说话人模型.当识别未知语音时,说话人模型就和未知语音进行匹配而识别出未知说话人的身份.
目前最常用的一种语音特征是短时 谱特征向量(本文简称为短向量).它使用一组低维度向量表征说话人信息.获取短向量的传统方法是Mel倒谱系数算法(MFCC).该算法使用离散傅里叶变换(DFT)[2]对语音信号进行谱分析.但是,DFT固定分辨率的分析窗口无法满足对语音这种给平稳信号的分析要求.另外,DFT将信号投影到一个全局的频率域上.如果信号的一个频率被噪音污染,那么它无法有效阻止噪音在整个特征向量上扩散[3].目前,许多研究者使用离散小波变换[4](DWT)替换DFT对语音信号进行谱分析.DWT的可变分辨率分析窗口很适合分析非平稳信号,并且DWT将信号分解到很多局部频带上.如果一个频带被噪音污染,那么噪音只能影响这个频带而不会影响到其他频带.也就是说DWT阻止了噪音扩散到整个特征向量上.基于小波分析,研究者已经提出了很多种方案:Zhao等人[5]将小波分析用于基于语音识别系统中;Srivastava等人[6]将小波分析和倒谱分析结合改进了传统Mel倒谱算法的性能;我们也基于小波分析提出了说话人识别模型[7].
超级向量是一种基于短向量的语音特征.和短向量不同,它用一个高维度的单一向量统一地表征了语音样本中的说话人信息[8].超级向量通常考虑了背景信息,所以其可以获得较高的识别率.本文将小波分析技术和超级向量技术结合得到一种基于小波的超级向量.
说话人分类的核心就是分类器.对于短向量来说最常用的分类器为高斯混合模型(GMM).这种分类器先归纳出特征中蕴含的概率分布,然后用这个分布来判定未知语音说话人的身份.但是,超级向量由于其维度过高,会对GMM造成“维度诅咒”问题.因此,通常需要使用一些特殊的分类算法来区别超级向量.在本文中,我们采用带核函数的支持向量机(SVM)来对超级向量分类.
本文提出了一种基于小波分析和超级向量的说话人识别模型.该模型使用基于小波分析的算法提取短向量,以提高短向量的质量和抗噪性.基于这些短向量,超级向量被构建出来表征说话人的特征.超级向量考虑了背景模型而有助于提高识别性能.最后,为了防止合成语音攻击,本文采用非对称文本内容的语音作为训练语音和测试语音.训练语音内容和测试语音内容不同,且训练语音公开而测试语音内容不公开,这样就可以防止测试语音被合成.
1 基于超级向量的识别模型结构
基于超级向量的识别模型包含3个基本模块,即提取短向量、构建背景模型和构建超级向量.具体结构如图1所示.
从图1可以看出,使用基于超级向量的识别模型完成识别任务时,需要用到3种语音样本,即背景语音、训练语音和测试语音.背景语音由许多说话人的许多语音样本组成.通常,一个语音数据库中的所有样本被作为背景语音样本.训练语音是已知说话人的语音.该样本被用来构建说话人模型.测试语音即未知说话人的语音,识别的目的就是要通过语音确定未知说话人的身份.3种语音首先都通过短向量提取算法转化成短向量.然后,背景短向量用于训练背景模型.其表征了一类说话人共同的特征.基于背景模型,训练短向量和测试短向量分别用于构建训练超级向量和各测试超级向量.当超级向量构建完成后,一个分类器就被用于匹配这2种超级向量,从而得出识别结果.
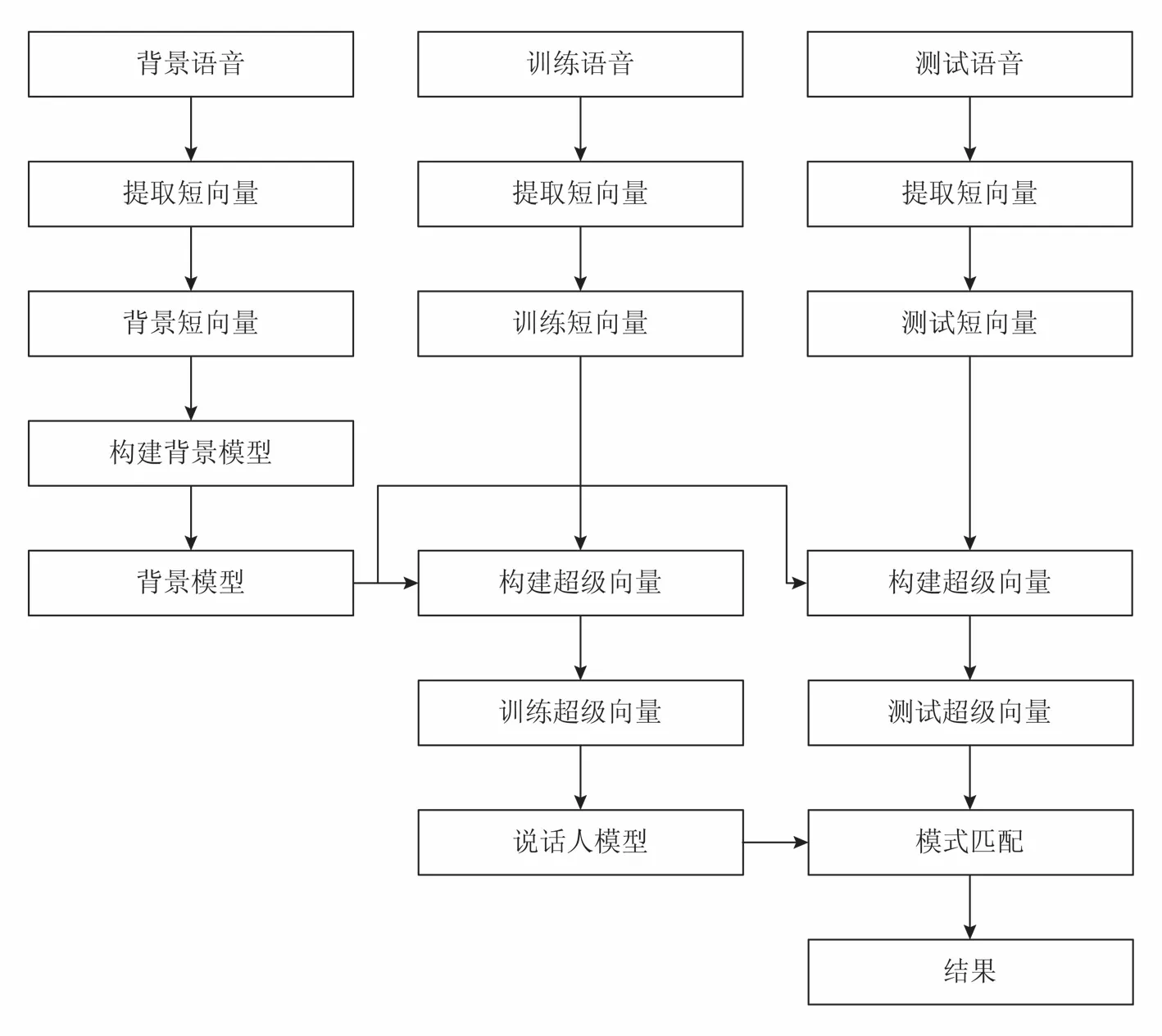
图1 基于超级向量识别模型结构
2 本文提出的模型
2.1 短向量提取算法
本文使用的短向量提取算法是基于小波分析的,因此我们先介绍小波分析的基本概念.一个离散信号x[n]的小波分析(DWT)表示为
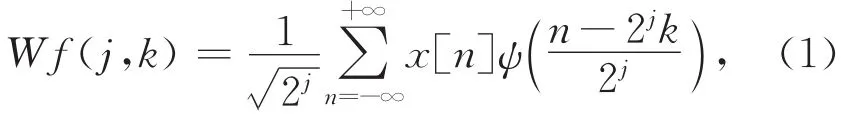
其中,ψ(·)表示母小波,j,k都属于整数集.式(1)只用于定义小波分析,而实际计算小波使用Mallet小波快速算法.该算法使用1对由母小波和对应尺度函数得到的镜像共轭滤波器实现小波分析.首先,1个待分析的信号被这对滤波器分解成低频部分和高频部分.然后,如果需要进一步提高分辨率,那么信号的低频部分继续被这对滤波器分解,而高频部分保持不变.分解过程可以由1棵如下所示的二叉树表示.
图2中,根节点(s节点)表示待分解的信号.左孩子节点(a1,a2,a3)表示信号低频部分,而右孩子节点(d1,d2,d3)表示信号高频部分.左树枝和右树枝分别表示滤波过程.由于母小波满足容许性条件,所以小波变换保持能量守恒.那么,分解树的叶节点就代表了小波分析获得的局部谱.而短向量正是基于这些局部谱计算得到的.
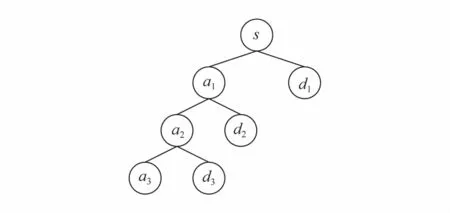
图2 小波分解树
下面介绍短向量提取算法.短向量提取算法一般分为4个主要步骤,即预处理、谱分析、Mel滤波和倒谱计算.具体计算过程如图3所示.首先,语音信号进入预处理过程.在预处理中,语音信号被切分成短的语音帧,而每帧中包含512个采样点.当分帧后我们需要计算每帧能量.能量定义如下:
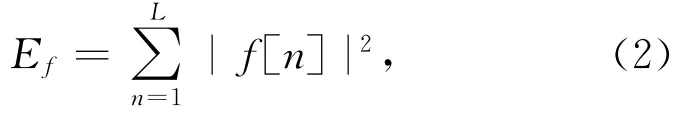
其中,f[n]表示帧,L为帧长度.如果1帧能量小于1个阈值(本文为0.001),那么就舍弃该帧,如果帧能量大于阈值则保留.保留下来的帧称为有效帧.然后,对每个有效帧作归一化处理以消除音量对识别的影响.归一化公式(3)为
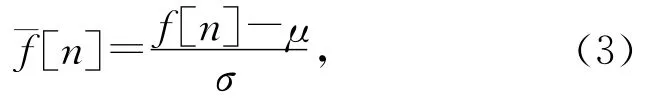

其中,K为Mel能量的个数.z[i]即为倒谱系数.假设一共得到了I个倒谱系数,那么最终得到的短向量表示为[z1,z2,…,z I],mk为第k个Mel滤波能量[9].

图3 短向量提取算法流程
2.2 构建背景模型
为了构架超级向量,背景模型(universal background model,UBM)需要被事先构建.通常,背景模型由高斯混合模型(Gaussian mixture model,GMM)表示.这种由GMM模型表示的背景模型被称为GMM-UBM.和分类器GMM不同,GMM-UBM通常包含大量的高斯函数(本文中GMM-UBM包含2048个高斯函数).每个高斯函数的协方差都相同且为对角阵.一个GMM-UBM被定义为权重,且满足表明GMM-UBM本质是一个概率分布.基于背景短向量,GMM-UBM中的参数通过EM算法[10]获得.
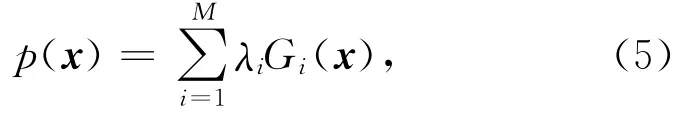
2.3 构建超级向量
当获得GMM-UBM后就可以基于这个背景模型构建超级向量.超级向量构建过程如图4所示:
其中,M为包含高斯函数的个数,被称为混合数,Gi(·)表示GMM中第i个高斯函数,λi表示混合
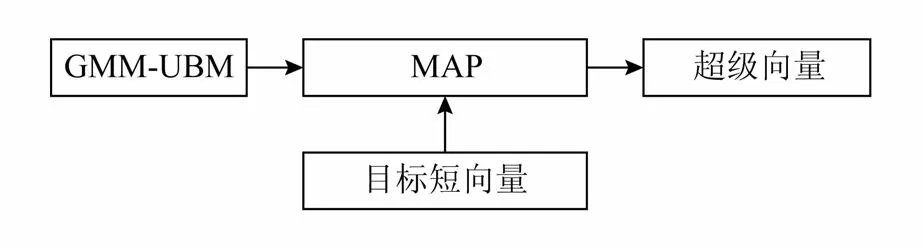
图4 超级向量构建过程
图4中,目标短向量即训练或者测试短向量.超级向量的构建过程被称为最大化调整过程(maximized adaptation processing,MAP).这个过程通过目标短向量对GMM-UBM的均值向量进行调整,使得GMM-UBM可以表征一个说话人的语音样本.MAP过程如下:
1)计算后验概率

这个后验概率表示了GMM-UBM中的i个高斯函数对表征目标短向量x的贡献度.
2)基于上述后验概率,计算Baum-Welch统计量
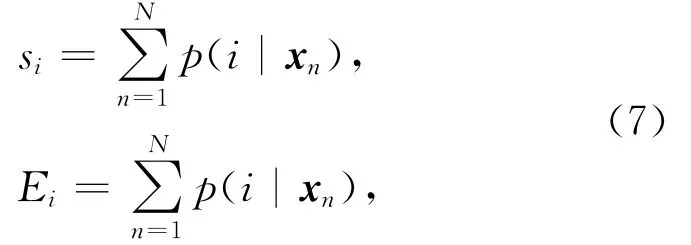
其中,x n表示第n个目标短向量,N为目标短向量的个数.
3)调整GMM-UBM的均值

其中,r表示调节率,当r=0时MAP就成了EM算法.表示调节前的GMM-UBM均值向量.调整后的模型被称为目标模型,它表征了一个说话人.从上面MAP过程可以看出,MAP只调整了GMM-UBM的均值向量,而混合权重λi和协方差矩阵∑保持不变,所以目标模型可以用其均值进行区别.假设目标模型的均值向量表示为{m1,m2,…,m I}(向量均为列向量),则对应超级向量表示为

2.4 模式匹配算法
由于超级向量的维度过高,所以不能使用传统的分类器如GMM对其进行分类.本文使用带核函数的SVM.SVM依靠一个分类平面对未知类进行分类,这个分类平面定义为
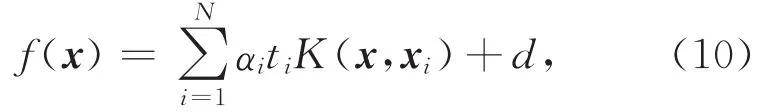
其中,αi>0为累加权重,ti为支持向量x i的类型标签,且满足d为学习常数.当对超级向量分类时,训练超级向量即为支持向量[8],K(·,·)为核函数.在本文中为
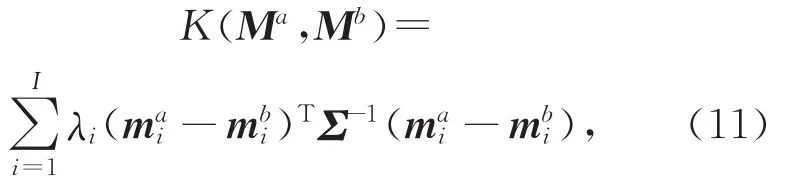
其中,M a,M b分别为2个超级向量分别为M a,M b的第i个分量.
3 实验和结果
3.1 实验数据集与平台
本文实验数据来自TIMIT语音数据库[11].数据库中包含了630名说话人的语音样本.每人提供10句样本,而每句样本长度为5 s.所有样本采样率为16 k Hz的单信道语音,且在安静环境下录制.本文首先使用所有语音作为背景语音构建2个性别相关的背景模型.一个表征女性语音的共同特征,另一个表征男性语音的共同特征.然后,从语音库中随机选取192名女性说话人的语音和192名男性说话人的语音作为目标语音.
本文的所有实验硬件平台为一台配有Intel core5 CPU和8 GB内存的PC机.软件平台为Window7操作系统和MATLAB2012b数学仿真软件.
3.2 最优小波
在基于小波分析的算法中,母小波的性能决定了小波分析的性能.Daubechies方程已经指出Daubechies小波家族和Symlet小波家族是最优小波.在实验中,能熵比(ESER)被用来定量这2个小波家族的性能.ESER定义如下:E为小波局部谱的能量,而SE为它的香农熵.实验结果如表1所示:


表1 母小波性能
表1中,DB表示Daubechies小波,SYM表示Symlet小波,而后面的数字代表了该小波的消失距.小波谱的能量越大说明小波分析捕获重要信息的能力越强,而香农熵越小则小波分析的稳定性越好.也就是说ESER越高则小波性能就越好.表1中,DB4和SYM6得到的ESER最大.因此,这2个小波的性能就最好.但是,DB4(实小波)处理实信号时比SYM6(复小波)计算简单.因此,本文只使用DB4.
3.3 准确率
本实验将测试识别模型的准确率.为了比较,另外3种模型即MFCC-GMM[12],WMFCC-GMM[3],S-SVM[8]被引入到实验中.384个说话人的语音被用作训练语音和测试语音.对于每个说话人,5个语音作为训练语音,而剩下的5个语音作为测试语音.实验结果如表2所示:

表2 4种模型的准确率
从表2可以看出,WMFCC-GMM模型的识别率要高于MFCC-GMM.这是因为,WMFCC中使用了小波分析对信号帧进行谱分析,而在MFCC中谱分析由傅里叶变换实现.和傅里叶变换相比,小波分析的可变窗口可以更准确地分析非平稳信号,这就使得WMFCC有效提高了准确率.还可看出基于超级向量模型(后2种模型)的准确率比基于短向量模型(前2种模型)的准确率高.这是因为超级向量考虑到了背景信息而短向量并没有考虑到这一点.最后,WS-SVM的准确率高于S-SVM,这表明小波分析可以有效提高模型识别性能.
3.4 抗噪性能
本实验用于测试上述4个模型的抗噪性能.为了获得噪音语音样本,向上述384个说话人语音中加入高斯白噪音.高斯白噪音序列由MATLAB高斯白噪音函数产生,其中s表示噪音强度.实验用到信噪比(SNR)分别为40 dB,30 dB,20 dB 3种噪音语音.实验结果如图5所示:

图5 4种模型的抗噪能力
如图5所示,所有模型随着噪音强度的增加(SNR减小),其准确率都在下降.但是,当SNR下滑至30 dB时,2种非小波模型(实线表示)的准确率下滑超过12%,而小波模型(虚线表示)准确率下滑不到8%.更有甚者,在SNR>30 dB时,S-SVM的准确率低于WMFCC-GMM的准确率.这说明了基于小波的模型的抗噪性能明显好于非小波模型.这是因为小波在对信号进行谱分析时,它将信号分解到多个局部频带中.这些局部频带有效地限制了噪音的传播范围,而使得特征向量在整体上不受噪音污染.
4 总 结
本文提出了一种基于小波分析和超级向量的说话人识别模型(WS-SVM).实验表明该模型在干净语音和噪音语音中都可以取得较高的识别性能.这是因为,小波分析获得的局部谱有效阻止了噪音的传播,而超级向量中包含的背景信息有效提高了特征向量表征说话人的能力.超级向量是一种用时间复杂度换取识别性能的技术.在未来的研究中,我们将重点放在如何降低超级向量算法的计算时间代价上.
[1]Almaadeed N,Ggoun A,Amira A.Speaker identification using multimodal neural network and wavelet ananlysis[J].Biomtrics,2014,4(1):2047-4938
[2]Lalitha S,Mudupu A,Nandyala B V,et al.Speech emotion recognition using DWT[C]//Proc of Int Conf on Computational Intelligence&Computing Research.Piscataway,NJ:IEEE,2016:1-4
[3]Adam T B,Salam M S,Gunawan T S.Wavelet based cepstral coefficients for neural network speech recognition[C]//Proc of IEEE Int Conf on Signal and Image Processing Application.Piscataway,NJ:IEEE,2013:447-451
[4]Verma G K,Tiwary U S.Text independent speaker identification using wavelet transform[C]//Proc of IEEE Int Conf on Conputer and Communication Technology.Piscataway,NJ:IEEE,2010:130-134
[5]Zhao X L,Wu Z.Speech signal feature extraction based on wavelet transform[C]//Proc of IEEE Int Conf on Intelligent Computation and Bio-Medical Instrumentation.Piscataway,NJ:IEEE,2011:14-17
[6]Srivastava S,Bhardwaj S,Bhandari A.Wavelet packet based Mel frequency cepstral features for text independent speaker identification[J].Interalligent System and Computing,2013,182:237-247
[7]Lei Lei,She Kun.Speaker recognition using wavelet cepstral coefficient,i-vector and cosine distance scoring and its application for forensics[J/OL].2016[2018-03-15].http://www.hindawi.com/journals/jece/2016/4908412
[8]Campbell W M,Reynolds D A.Support vector machines using gmm supervectors for speaker verification[J].Signal Processing Letters,2006,13(5):308-311
[9]Chauhan F M,Desai N P.Mel frequency cepstral cofficients based on speaker identification in noisy environment using wiener filter[C]//Proc of the 2014 Int Green Computing Connunication and Electrical Engineering.Piscataway,NJ:IEEE,2014:1- 5
[10]Reynolds D,Rose R.Robust text-independent speaker identification using gaussian mixture speaker models[J].IEEE Trans on Speech and Audio Processing,1995,3(1):72-83
[11]Biswas A,Sahu P K,Bhowmick A,et al.Feature extraction technique using erb wavelet sub-band periodic and aperiodic decomposition for timit phoneme recognition[J].International Jounrnal of Speech Technology,2014,17(4):389-399
[12]Martinez J,Perez H,Escamilla E,et al.Speaker recognition using Mel frequency cepstral coefficients and vector quantization techniques[C]//Proc of the 22nd Int Conf on Electrical Communications and Computers.Piscataway,NJ:IEEE,2009:248-251
猜你喜欢
中国特种设备安全(2022年3期)2022-07-08
科技风(2021年19期)2021-09-07
小学科学(学生版)(2020年10期)2020-10-28
电子制作(2019年13期)2020-01-14
疯狂英语·新悦读(2019年10期)2019-12-13
铁道学报(2018年5期)2018-06-21
制造技术与机床(2017年10期)2017-11-28
小火炬·阅读作文(2017年8期)2017-09-26
Coco薇(2017年9期)2017-09-07
火控雷达技术(2016年1期)2016-02-06
