
基于深度学习的肺部肿瘤检测方法
2018-04-13 01:07陈强锐谢世朋
计算机技术与发展 2018年4期
陈强锐,谢世朋
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
计算机辅助诊断(CAD)[1]是指运用计算机技术分析计算影像、病理等数据,辅助发现病灶,从而提高诊断的准确率。现代计算机技术的快速发展对其起到了极大的推进作用。目前CAD技术已经广泛应用于各种疾病的诊疗过程中,被形象地称之为医生的“第三只眼”。肺癌检测是最常见的CAD技术应用之一。近年来国内肺癌发病率呈逐年上升趋势,年平均增长率为1.63%。而肺癌的发病率及死亡率已居所有恶性肿瘤之首。引入计算机辅助诊断技术对肺癌的早期发现与诊疗有着重要的积极作用,所以它在辅助医生诊疗肺癌领域有着巨大的发展前景。
对于肺癌检测的CAD技术关键在于肿瘤病灶的定位与分类。目前已经有许多传统机器学习的方法可以对肿瘤进行检测。文献[2]从灰度特征、纹理特征、形态特征等多个角度提取肺部CT图像的特征,并利用支持向量机[3](SVM)对肺部CT图像进行分类分析。文献[4]针对肺结节的形态、位置、纹理、灰度等17个特征,利用主成分分析(PCA)方法,对特征集进行优化选择和降维处理,最后利用基于SVM的分类器对样本进行分类检测。文献[5]开发了一种提取肺结节特征信息的转换器,并结合随机森林算法利用提取到的特征信息对模型进行训练和测试。这些方法较好地解决了分类问题,但实验结果也并非十分完美,仍有提升的空间,尤其在复杂的特征提取方法和结节的位置预测方面。
深度学习[6]的概念于2006年由Hinton等提出,作为机器学习的一个分支,由于其善于发现高维数据的复杂结构,使用泛化目标的学习过程可以自动学习好的特征,所以近年来发展十分迅速。深度学习算法模仿人脑的机制来解释并处理数据,在语音识别、图像识别、自然语言理解等领域取得了重大突破。卷积神经网络(CNN)则是深度学习在图像领域的一个重要应用,已成为众多科学领域的研究热点之一。卷积神经网络对图像的特征提取十分方便,只需设置合理的网络结构与网络参数,每对图像进行一次卷积操作就可以生成一个特征图。通过加深网络结构可以学习到图像更深层次的特征。相较于人工设计特征的方法,卷积神经网络的适用范围更广,对图像的特征提取更加深刻全面。国内知名学者也曾表明深度学习将取代人工特征加机器学习的方法而逐渐成为主流图像识别方法[7]。文中采用深度学习的方法,将卷积神经网络应用到肺部肿瘤图像的特征提取中,结合区域生成网络预测肺癌结节的位置,并通过实验验证该方法的有效性。
1 肿瘤检测
肿瘤检测的流程如图1所示。首先让整幅图像经过卷积神经网络进行特征提取,然后针对获得的特征图像生成肿瘤位置建议框,最后对各个建议框包围的图像进行分类并微调建议框的位置。

图1 肺部肿瘤检测流程
1.1 特征提取
对于图像的特征提取方法有很多,它们大多依赖于人工的设计。例如算法HOG[8]和SIFT[9]。但是SIFT和HOG受限于图像中梯度的方向直方图[10],并不具备普适性。
1998年,LeCun提出的卷积神经网络是第一个真正多层结构学习算法[11],并成功地将其应用到手写数字识别中,标志着卷积神经网络对图像特征提取的第一次成功应用。由于当时的硬件计算条件不足以支撑更深层次的网络,只适合做小图片的识别,因此对于大规模数据识别效果不佳。直至2012年ImageNet图像分类竞赛中,AlexNet凭借Top-5错误率低于上一年十个百分点的优秀成绩,使得CNN受到了研究者们的重视[12]。
卷积神经网络的再次流行主要得益于非线性激活函数Relu和防止过拟合方法Dropout的提出,当然还有大数据训练以及GPU并行计算的发展。文中使用的特征提取网络是基于Zeiler和Fergus提出的ZF[13]网络。
网络结构如图2所示。
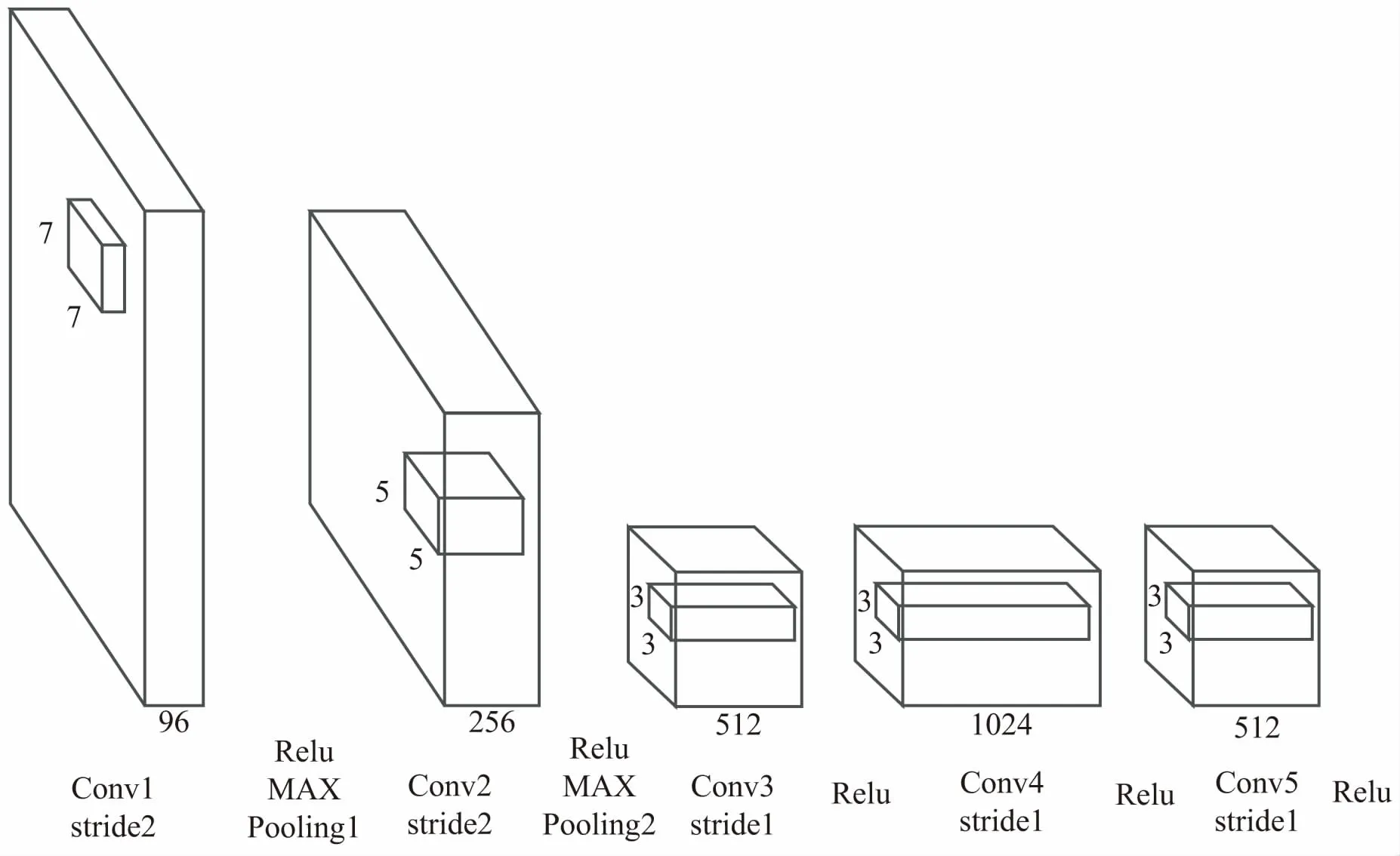
图2 特征提取网络结构
网络总共含有5层可共享特征的卷积层,每一卷积层都应用了一个Relu激活函数。卷积层第一层与第二层的卷积核大小分别为7*7和5*5,卷积步长为2。卷积层后三层的卷积核大小为3*3,卷积步长为1。卷积层的第一层与第二层之后分别设置了一个最大值池化层。这种网络结构保证了神经网络既能充分学习到图像特征,又能够防止过拟合。
1.2 区域建议网络
传统生成区域建议框的方法如selective search[14],是将输入图像分割成许多相邻的小区域,计算相邻区域的相似度且合并相似度最高的相邻区域然后重复迭代,并融合各种多样化策略。虽然这种方法相较之前exhaustive search[15]方法提升很大,但是其不能通过GPU加速导致耗时很大。或者是像YOLO[16]中将原始图片分成S*S个网格,将生成建议框看成单一的回归问题,虽然解决了耗时问题,但是这种方法对于处在网格边缘或者尺寸较小的肿瘤,生成的建议框效果较差。
上述两种方法的输入都是原始图像,并未充分利用CNN输出的特征提取后的图像。文中使用的区域建议网络是RPN,结构如图3所示。其输入是CNN网络输出的特征图像。该方法在特征图像上设计了一个滑动窗口,在每一个窗口的中心生成3种不同大小、3种不同宽纵比,总计9个固定的建议框。同时将每一个滑动窗口映射成为一个256维的向量,该向量输出给两个同级的全连接层cls layer与reg layer,分别用作建议框的回归和分类。
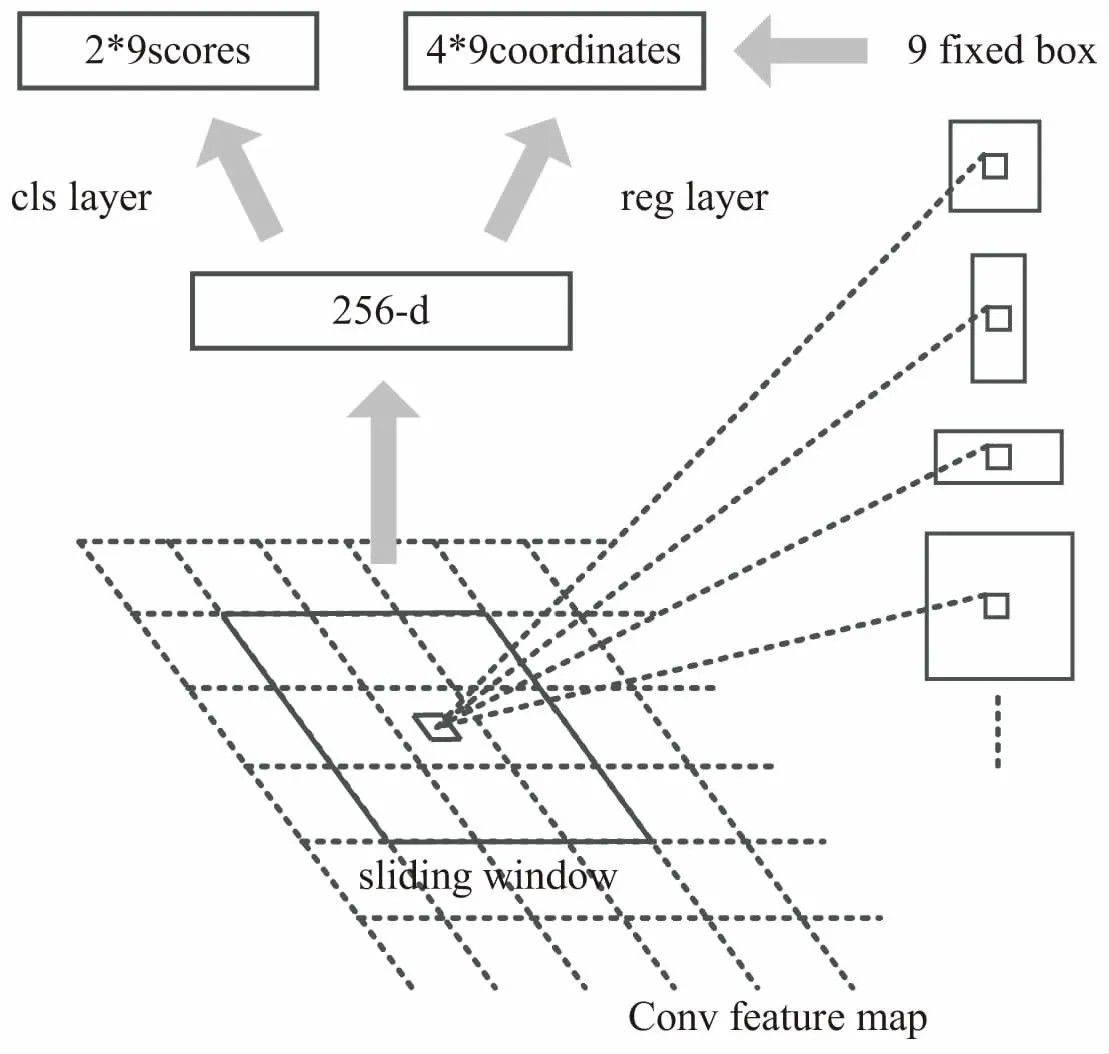
图3 区域建议网络
文中方法利用目标区域与ground-truth面积的交并比(IOU)对建议框进行筛选,IOU定义为:
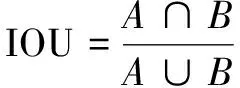
(1)
其中,A与B分别表示不同区域的面积。
选用IOU大于0.7的建议框作为目标建议框,将IOU小于0.3的建议框记为背景样本,弃用其余以及跨越图像边界的建议框。每张图片最后至多生成300个建议框,并利用其对应的向量对建议框内容进行分类且微调其位置。
2 实 验
2.1 损失函数及训练
实验采用的数据集来自于NLST以及Kaggle。从不同肺癌患者的CT中挑选出451张切片,并将DICOM文件格式转换成512*512像素的JPG图像。随机挑选出361幅图像并对这些图像中肺癌特征区域进行标注,作为训练集,剩余的90幅图像则作为测试集。文中采用的检测框架为Faster RCNN[17],对每幅图像的损失函数定义为:
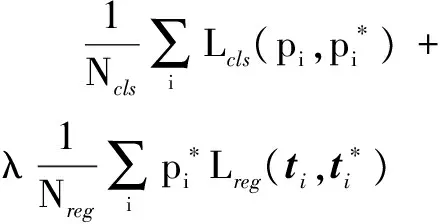
(2)

分类损失函数Lcls定义为:
(3)
建议框回归损失函数Lreg定义为:
(4)
其中,R是鲁棒的损失函数smoothL1[18]定义为:
(5)
网络训练时损失函数超参数λ设置为10,卷积神经网络的基础学习速率设置为0.001,权重衰减设置为0.000 5,在配置为Intel Core i7-2600 3.4 GHz处理器,4 G内存,8 G显存,显卡为GTX1070的服务器上训练总时长约4个小时。
2.2 实验结果分析
经过实验,测试集共90幅CT图像成功检测出86幅,其中典型的检测效果如图4所示。
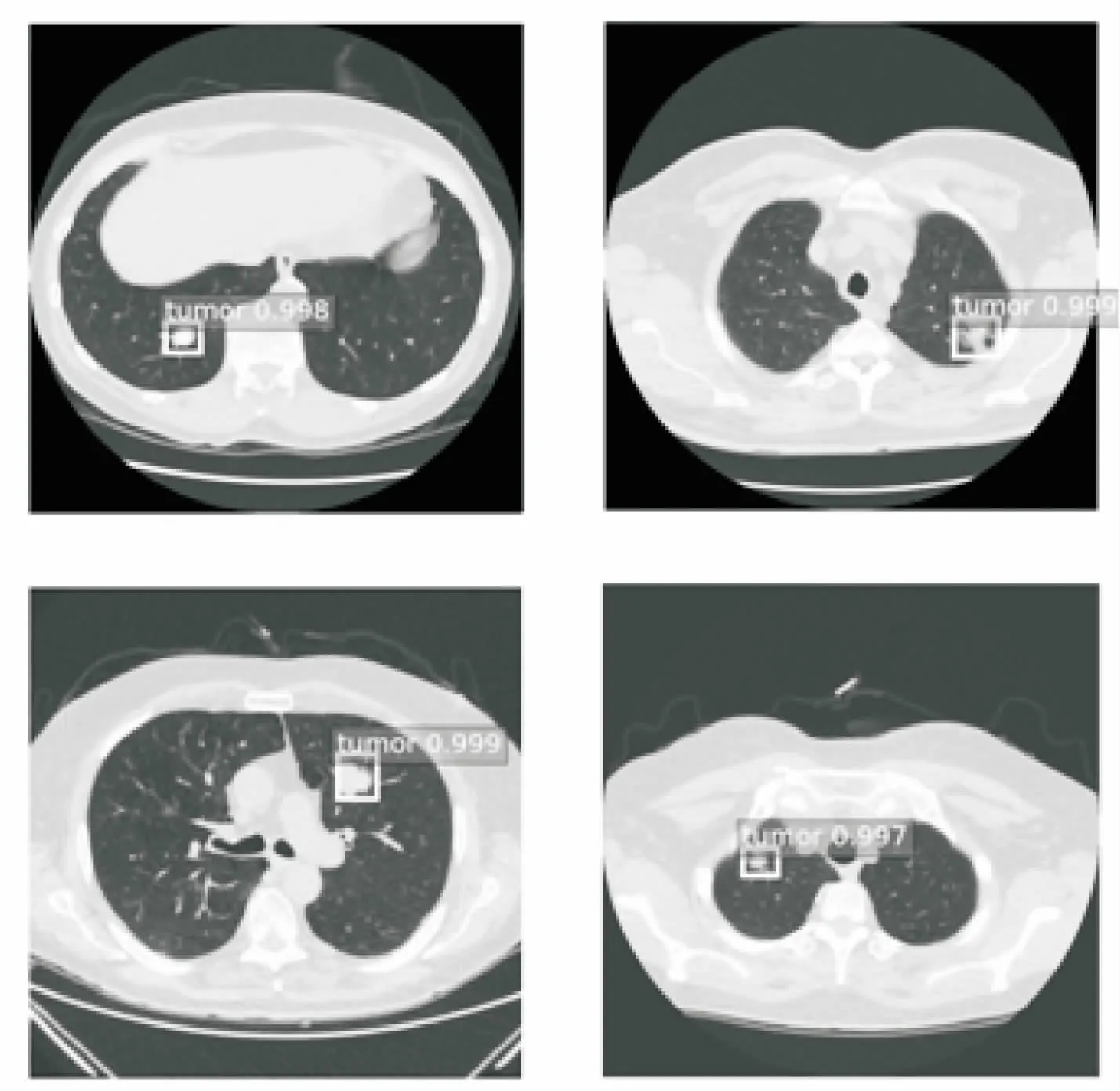
图4 检测结果
由图4可见,肺部肿瘤可以被文中方法准确定位,并且具有较好的检测效果。
文中准确率定义为:
(6)
其中,j为测试图像的索引号;Idet为检测结果标记,检测成功为1,检测失败为0;Pr(j)为预测概率;N=90为参与检测的图像总数。
利用相同的数据集在YOLO_V2框架上进行了重复实验,并将两次的实验结果进行了对比,结果如表1所示。
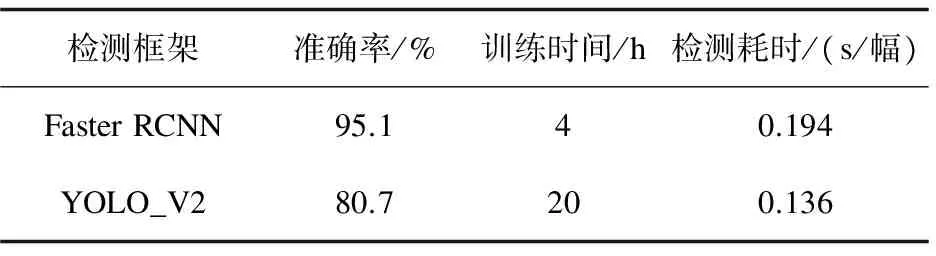
表1 不同框架检测结果对比
由表1可以看出,文中方法的检测效果更佳,准确率高达95.1%且高于YOLO_V2约15个百分点,并且训练时间也大大缩短。虽然每幅图像的检测用时略高于YOLO_V2,但是综合考虑各方面因素,文中方法对于肺部肿瘤的检测有着更好的性能。
将文中方法的检测结果与利用传统机器学习方法的检测结果进行了对比,结果如表2所示。

表2 不同方法检测结果对比
由表2可以看出,文中方法的检测准确率可达95.1%,相较于其他检测方法,具有更高的准确率,其准确率提升约6个百分点。由于文中方法可以对肿瘤图像自动地进行特征提取,并且深层次的网络结构可以提取到更好的特征,所以检测效果明显有所提高。并且该方法还可以准确定位出肿瘤的具体位置,相较其他方法具有一定的优势。
3 结束语
提出了基于深度学习的肺部肿瘤的检测方法,通过卷积神经网络对CT图像进行特征提取,最终定位出图像中肿瘤的位置。该方法在NLST以及Kaggle数据集上取得了较好的实验效果,对于肿瘤检测领域具有一定的积极意义。然而,该方法只考虑到肿瘤图像的二维特征,若能够对肿瘤进行三维特征提取,其检测效果则会更好。接下来的工作将向此方面发展。
参考文献:
[1] 舒荣宝,王成林.电子计算机辅助诊断(CAD)的原理及临床应用[J].中国CT和MRI杂志,2004,2(2):55-56.
[2] 马杨林.基于SVM的肺部CT图像特征提取及分类研究[D].成都:西华大学,2012.
[3] SCHÖLKOPF B,SMOLA A.Learning with kernels:support vector machines,regularization,optimization,and beyond[J].IEEE Transactions on Neural Networks,2005,16(3):781.
[4] 张 婧.基于SVM的肺结节自动识别方法研究[D].广州:华南理工大学,2011.
[5] KOUZANI A Z,LEE S L A,HU E J.Lung nodules detection by ensemble classification[C]//IEEE international conference on systems,man and cybernetics.[s.l.]:IEEE,2008:324-329.
[6] LECUN Y,BENGIO Y,HINTON G.Deep learning[J].Nature,2015,521(7553):436-444.
[7] 余 凯,贾 磊,陈雨强,等.深度学习的昨天、今天和明天[J].计算机研究与发展,2013,50(9):1799-1804.
[8] LOWE D G.Distinctive image features from scale-invariant keypoints[J].International Journal of Computer Vision,2004,60(2):91-110.
[9] DALAL N,TRIGGS B.Histograms of oriented gradients for human detection[C]//IEEE computer society conference on computer vision & pattern recognition.Washington DC,USA:IEEE Computer Society,2005:886-893.
[10] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//IEEE conference on computer vision and pattern recognition.Washington DC,USA:IEEE Computer Society,2014:580-587.
[11] 孙志军,薛 磊,许阳明,等.深度学习研究综述[J].计算机应用研究,2012,29(8):2806-2810.
[12] 李彦冬,郝宗波,雷 航.卷积神经网络研究综述[J].计算机应用,2016,36(9):2508-2515.
[13] ZEILER M D,FERGUS R.Visualizing and understanding convolutional networks[J].Lecture Notes in Computer Science,2013,8689:818-833.
[14] UIJLINGS J R,SANDE K E,GEVERS T,et al.Selective search for object recognition[J].International Journal of Computer Vision,2013,104(2):154-171.
[15] HARZALLAH H,JURIE F,SCHMID C.Combining efficient object localization and image classification[C]//International conference on computer vision.[s.l.]:[s.n.],2010:237-244.
[16] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once:unified,real-time object detection[C]//IEEE conference on computer vision and pattern recognition.Washington DC,USA:IEEE Computer Society,2016:779-788.
[17] REN S,HE K,GIRSHICK R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(6):1137-1149.
[18] GIRSHICK R.Fast R-CNN[C]//International conference on computer vision.[s.l.]:[s.n.],2015:1440-1448.
猜你喜欢
中国药学药品知识仓库(2022年1期)2022-03-23
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
昆明医科大学学报(2021年4期)2021-07-23
天津医科大学学报(2021年2期)2021-03-29
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
雷达学报(2018年5期)2018-12-05
