
用于作战实验运用的时空逻辑推演方法*
2018-04-12 06:08张东俊王天忠
指挥控制与仿真 2018年2期
张东俊, 黎 潇, 吴 红, 王天忠
(解放军92337部队, 辽宁 大连 116023)
随着信息技术的飞速发展,战争的形态发生了巨大的变化,战争的复杂性、消耗性和风险性急剧增加,客观上需要更先进的方法和手段来研究战争[1]。钱学森曾说过“在模拟可控的作战条件下进行作战实验,能够对有关兵力与武器装备使用之间的复杂关系获得数量上的深刻理解”[2]。作战实验是用来探索作战的因果关系,揭示作战制胜机理,为装备研制、改进及作战运用提供支撑。作战实验运用领域是前沿交叉学科,其重难点问题是如何将作战问题转化为科学问题去表达和解析。
作战实验运用研究现状[3-7]:1)静态解析方法研究,如著名的兰彻斯特方程,可定量描述地面战斗的战斗过程, 分析双方损耗问题,然而它是一个确定解析过程,一旦初始条件确定,结果就基本确定,很难反应作战具体过程;2)仿真推演方法研究,如当下最热门的多Agent仿真等,都是基于装备性能指标进行推演,装备性能指标是静态的、孤立的,难以反映真实作战过程中装备能力的连续动态变化以及各能力之间的相互关联;3)行为控制研究,如CGF建模研究,都是对人的行为模型化,忽视了基于指挥操纵进程的装备作战能力的实时控制反映,不能定量反映装备探测、隐蔽、攻击等能力在人的实时指挥下优化控制以及最终对于作战行为的优化反馈;4)建模理论研究,如基于试验数据的建模等,都是试图通过模型来说明因果关系,然而建模的过程就是去粗取精、去伪存真的抽象描述过程,无法准确表达作战运用中许多复杂性、不确定等非逻辑问题。
因此,本文引入能量的观点,认为作战实验运用过程就是能量积蓄-感知-传递-转化的过程[8],是行为驱动下的综合战能在多维多域的全息动态表达,具有基于交战进程的强实时动态博弈特性,其随作战进程实时输入与响应的动态演化过程,客观表现为时空逻辑变化。因此我们应逐步从被动探究实验因果关系,转变为主动揭示实验过程的时空逻辑变化关系,即根据作战目标探究与作战对手、战场环境实时交互的一系列行为关系与战场态势。
因此,基于作战实验云所具备的高性能计算能力,借鉴AlphaGo的研究成果,本文提出了一种用于作战实验运用的时空逻辑推演方法。
1 基于战能势谱的时空逻辑推演方法
1.1 基本内涵
战场上所有行动就是构建我方杀伤链和解构对方杀伤链,杀伤链当前能量状态和未来期望能量状态之间的差距,称为当前战能。
势是运用军事力量所形成的力的积蓄或者释放状态。势能是一个相对值,因对手而存在。同一作战态势下,我方战能和敌方战能之比称为对抗势能,简称势能。
战能势谱是一种能量模型,通过当前和未来任务需求,将多影响因素约束的多领域系统的作战能量集成在一起,获取的任务各阶段的作战效能的中间态势量(相当于体系动量)。特定作战环境和对手下,战能势谱分量主要包括探测战能、隐蔽战能、攻击战能、防御战能和保障战能。
战能环是对作战实验过程的一种高度抽象,能较清晰地描述整个作战实验全过程,即战能的“感知-积蓄-传递-转化”过程:感知,是运用传感器和网络感知战场环境能量,通过作战需求对感知能量进行控制;积蓄,是对感知的能量进行分析,标识关键能力,形成特定作战条件下的战能势谱;传递,是研判态势确定能量传递的方向和时机,以及重构各战能分量之间的适应性关系;转化,是评判在作战任务下战能转化的不同效果及其对整个作战任务的贡献度。
时空逻辑推演是作战实验中时空能量感知、积蓄、传递和转化的重要工具,输入是战能势谱(大小和方向),输出是战能分量之间的关系以及战能传递和转化等战场优化布势的综合效果。作战实验时空逻辑推演是在战能环的约束下,推演各个阶段的战能势谱模型,其中,重点是实现编成战能及其空间协同优化、指控战能及其时间协同优化,以及不同任务下的综合战能(时空可重构)。
1.2 时空逻辑推演基本框架
时空逻辑推演主要是基于高性能计算的作战实验智能指控方法,框架如图1所示。
1)作战任务时空分析
作战任务分析,就是从时间和空间两方面描述作战任务,从作战、指挥和操纵三个方面构建具有时序和层级关系的作战链路和指挥操纵链路,描述作战任务,确认任务要求。
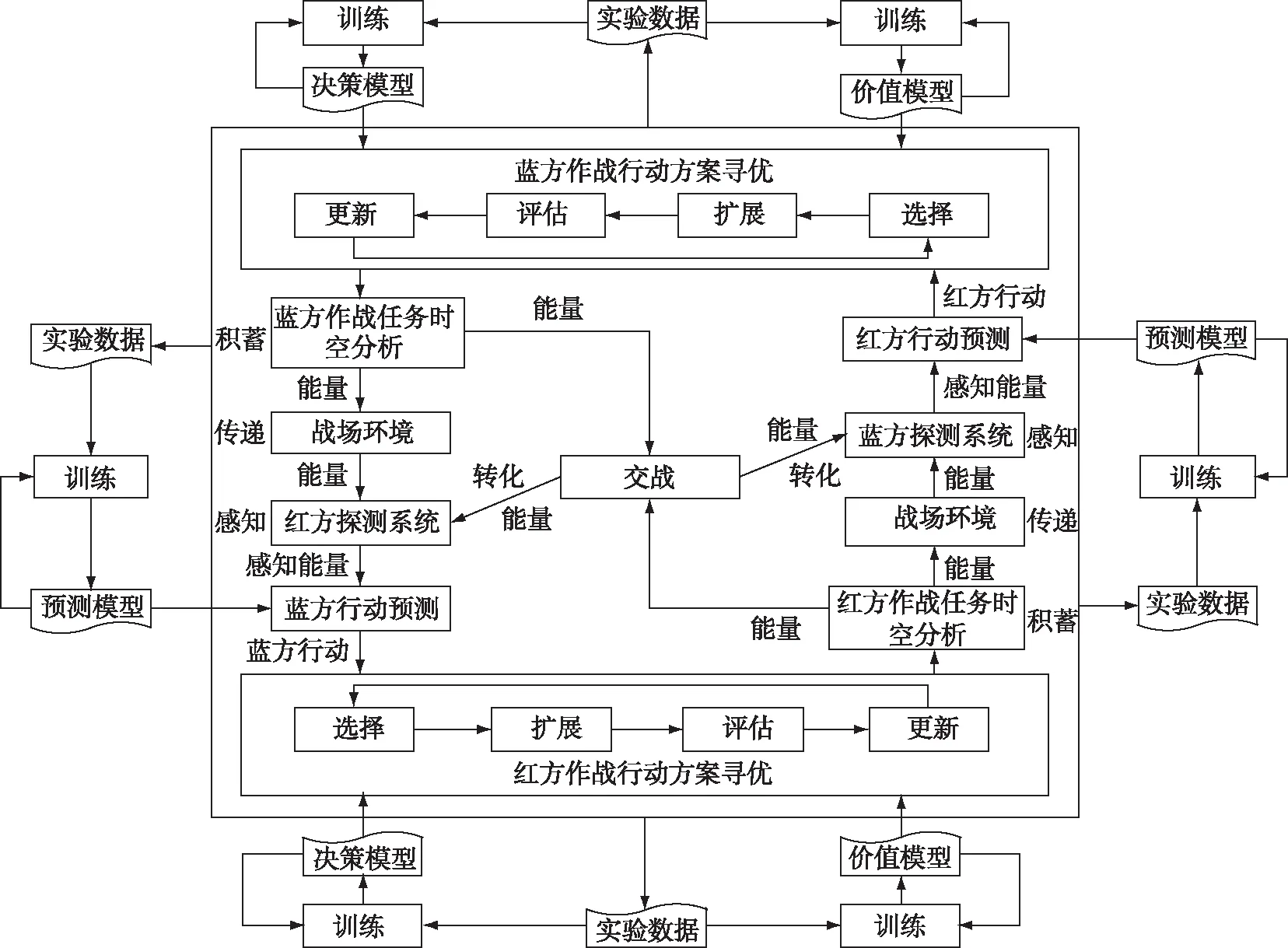
图1 时空逻辑推演框架
2)在预测模型构建方面,针对红蓝对抗过程中,传感器只能获取对方局部能量的情况,采用基于时空域卷积神经网络的预测模型,将感知能量和历史数据有机结合,准确把握对方当前作战行动能量,为己方下一步决策提供支持(战能预测)。
3)在决策、价值模型构建方面,为模拟作战过程中人类的指挥艺术,采用基于强化学习的决策模型和价值模型,其中价值模型主要模拟人的经验,以战场态势为输入,输出特定态势下的战能势谱(作战行动方案);决策模型模拟人对全局的把握,输入为战场态势和战能势谱,输出为作战任务达成度。
4)在作战行动方案寻优方面,针对方案生成和态势更新可并行计算量小于具有的高性能并行计算资源的情况,设计了并行蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)算法,充分利用了已有的计算资源,可快速开展作战行动方案寻优,从而提高了仿真推演速度。
2 时空逻辑推演关键算法描述
2.1 基于时空域卷积神经网络的预测模型
建模的基本思想是基于己方传感器获取的能量信息和空间信息以及对方真实的作战行动状态信息,采用改造后的卷积神经网络对预测模型pr进行训练。下面以红方作战行动预测模型为例,阐述预测模型的构建过程。
2.1.1模型输入
时空域卷积神经网络[4-5]的基本结构采用3个相邻的帧为输入,构建预测模型的输入层(Ph1、Ph2、Ph3),具体步骤如下:
步骤1:设T1、T2、T3时刻红方通过传感器获取的蓝方能量信息(简称为感知能量),以及蓝方对红方的空间位置、姿态信息(简称为空间信息),分别为ERB(Ti)=[rbe1,…,rbemRBE](Ti)和SRB(Ti)=[rbs1,…,rbsmRBS](Ti),采用正向极差变换法对它们进行归一化处理,即
(1)
组合感知能量及空间信息,可知:
C(Ti)=[c1,…,cmRBE+mRBS](Ti)
其中,
cj={urbej(j=1,…,mRBE)urbsj-mRBE(j=mRBE+1,…,mRBE+mRBS)
步骤2:将C(Ti)进行两两组合,形成三幅二维图像Ph(1)、Ph(2)、Ph(3),其中各图像像素点值的计算方式如下:
2.1.2网络结构
针对Ph1、Ph2、Ph3采用不同的卷积层及相同的池化层进行处理,然后采用全连接层对结果进行综合[6-7]。
1)卷积层
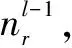
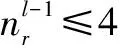
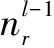
步骤3:卷积核的数量为16,每个卷积核依次与其中一半的特征图进行卷积,转步骤1。
步骤4:结束。
2)池化层
对于各个池化层,采用2×2求平均值进行下采样。
3)全连接层
全连接层为2个,神经元的个数取为蓝方作战行动状态变量水平数量之和,第1个全连接层的每个子全连接层采用全连接的方式,即:
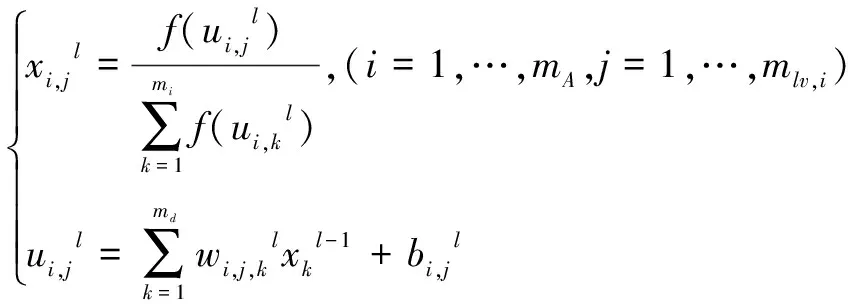
(2)
式中,mA表示蓝方作战行动状态变量数量,mlv,i表示第i个变量的水平数量,md,l-1表示xl-1的向量维数,激活函数f(·)使用sigmoid函数。
由于第一个全连接层的每个子连接层都能产生一个蓝方作战行动预测,第二个连接层采用局部连接的方式,即将各子层相应的部分进行连接:
4)训练算法
训练算法采用经典的反向传播算法[8-10],以优化卷积核参数k、全连接层的网络权重w和各层的偏置参数b等。
2.2 基于强化学习的价值模型(战能势谱)和决策模型
建模的基本思想是基于纯数字的闭环仿真对抗推演,人在回路中的半实物仿真对抗推演和将实验室搬到艇上的虚实结合的仿真对抗推演产生的训练样本,采用基本卷积神经网络对价值模型vθ、决策模型pσ进行训练[11-13]。
2.2.1价值、决策模型输入
战场态势主要由四部分组成:红方战能、蓝方战能、战场环境、空间信息。不同的参数具有不同的量纲与取值,为了统一量纲,便于数值分析,引入极差变换法进行归一化处理:对作战能力起抑制作用的战能分量采用反向极差变换法,其他采用正向极差变换法。正向极差变换方法如下所示:
反向极差变换方法如下所示:
yi,j的范围在0-1之间,yi,j各值的分布仍与相应原X值的分布相同。
1)价值模型输入层
设归一化的红方战能为RE=[rei,…,remR],蓝方战能为BE=[bei,…,bemB],战场环境为Env=[envi,…,envmE],空间信息S=[si,…,smS]。基于红蓝双方的能态是影响作战进程的主要因素,构建形如二维图像的输入层X=[xi,j]mR×mB,其中每个像素点的值为:
xi,j=f1(rei,bej,Env,S),(i=1,…,mRE;j=1,…,mBE)
(3)
式中,f1表示单层神经网络,采用求积的方式计算输出层:
为缩减深度学习中的参数数量,基于专家知识分析rei、bej、Env、S的关系,当rei、bej无对抗关系时,则xi,j为0,例如红蓝双方的攻击能力;当envk、sl与rei、bej的对抗关系无关时,将相应的权重置于0。
2)决策模型输入层
决策模型的输入层Y=[yi,j]mRE×mBE构建如价值模型,其中不同之处在于每个像素点值的求解上,设归一化的作战行动为A=[a1,…,amA],则:
yi,j=f2(rei,bej,A,Env,S),(i=1,…,mR;j=1,…,mB)
(4)
式中,f2表示单层神经网络,采用求积的方式计算输出层:
当rei、bej无对抗关系时,则yi,j为0;当envk、sl、an与rei、bej的对抗关系无关时,将相应的权重置于0。
2.2.2决策、价值模型结构
模型结构采用标准的卷积神经网络,主要有输入层、卷积层、池化层和全连接层组成,其中卷积层、池化层成对出现。
1)卷积层
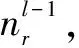
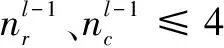
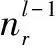
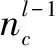
步骤4:卷积核的数量为16,每个卷积核依次与其中一半的特征图进行卷积,转步骤1。
步骤5:结束。
2)池化层
对于每个池化层,采用2×2求平均值进行下采样。
3)全连接层
决策、价值模型的全连接层都为1个,神经元的个数分别取为红方作战行动状态变量水平数量之和,红方作战目标达成状态变量水平数量之和,即:
(5)
式中,m表示红方作战行动状态变量数量或红方作战目标达成状态变量数量,mlv,i表示第i个变量的水平数量,md,l-1表示xl-1的向量维数,激活函数f(·)使用sigmoid函数。
4)训练算法
训练算法采用经典的反向传播算法,以优化卷积核参数k、全连接层的网络权重w和各层的偏置参数b等。
2.2.3强化学习的基本流程
强化学习的主要过程如图2所示,其中vθ为价值模型,pσ、pσi、pρ表示决策模型。
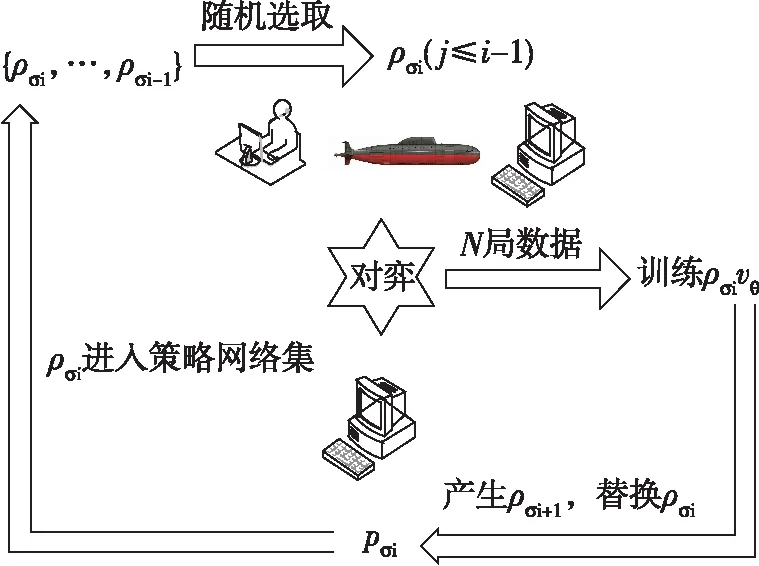
图2 强化学习基本流程图
步骤1:取pσ为第一代版本pσ1,让装配有pσ1的实验平台与装配有pσ1的实验平台、人机结合的实验平台、实际平台对弈N局,产生出N局新的对弈数据,用新的对弈数据训练pσ1产生第二代版本pσ2、vθ。
步骤2:让装配有pσ2的实验平台与装配有pσ1的实验平台、人机结合的实验平台、实际平台对弈N局,用新的对弈数据训练pσ2产生第三代版本pσ3、vθ。
步骤3:对于第i代版本,随机选取前面的版本进行对弈,如此迭代训练M次后得到第M代版本pσm=pρ,这就产生了增强学习的策略网络pρ、价值网络vθ。
2.3 面向行动方案寻优的并行蒙特卡洛树搜索算法
基本操作如图3所示,主要通过选择、扩展、评估、更新的循环迭代,让好的方案自动涌现出来,其中U表示决策模型的值,Q表示蒙特卡洛树搜索的值,f(x)、s(x)、o(x)表示最优值、次优值和其他值,pσ表示选择概率,m(x)表示求取在值,v(x)为价值[11]。

图3 并行蒙特卡洛树搜索算法
步骤1:选择
对于计算资源,采用二进制编码形式,编码位数为nb,计算方式如下:
选择操作进行nb次,对于每个计算资源,从低位向高位分别表示第1次至第nb次选择。当位值为0时,表示选择当前最优的行动;当位值为1时,表示选择当前次优的行动。
选择判据:
at=U(st,a)+Q(st,a)
(6)
式中,U(st,a)为来自决策模型的值,Q(st,a)为来自蒙特卡洛树搜索的值。
步骤2:扩展
从nb+1步开始,依据决策模型pρ向前推进L步。
步骤3:评估
对于选择操作涉及的节点i,其估值采用如下方法进行计算:
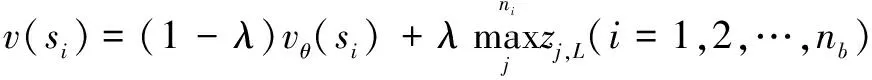
(7)
式中,ni为节点i在本次操作中的所有分支数量;vθ(Si)为采用价值模型对态势Si的估值,zj,L采用价值模型对态势sj,nb+L的估值;λ为常数,在AlphaGo中,实验检验发现取值0.5时效果最好。
步骤4:更新
U(s,a)采用下式进行更新
(8)
式中,N(s,a)表示蒙特卡洛仿真搜索分支(s,a)的次数;P(s,a)=pρ(s,a)表示在当前态势下,通过决策模型产生的每个分支上的先验知识。
Q(s,a)采用下式进行更新
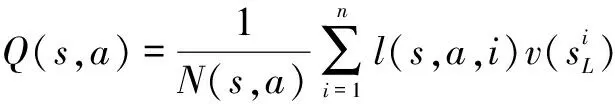
(9)
式中,l(s,a,i)为布尔函数,用来将遍历到的分支选择出来:如果第i次模拟遍历到(s,a)分支则函数值为1,否则函数值为0。
3 基于时空逻辑推演潜艇红蓝对抗实验案例分析
由于潜潜攻防问题作战过程过于复杂,这里只给出局部问题的推演简例。
3.1 基本想定
A艇与B艇为自由对抗态势,海区水深XX米,XX底,0-X1米为均匀层,X1米以下为负梯度,初始态势为A艇位于A1点,深度a1米,航向b1,速度v1节;B艇位于B1点,深度a2米,航向b2,速度v2节,两艇初距y1cab。
3.2 作战任务分析
3.2.1链路构建
构建具有时序和层级关系的作战链路,如图4。
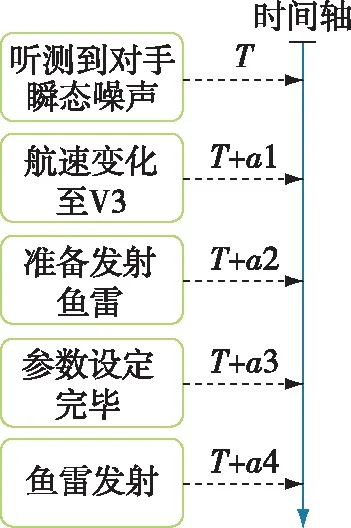
图4 作战任务时间描述模型
3.2.2基于感知信息的战能预测分析
依据前文方法,先根据以往演习试验数据,进行基于卷积神经网络的数据处理,本文的训练次数是2000次,再基于获取对抗过程中感知信息,初步预测下一步各项战能的变化,以听测到潜艇瞬态噪声链路行为为例,如图5-图7所示。

图5 初始状态A艇各战能状态

图6 听测到瞬态噪声后A艇战能状态

图7 预测B艇此时战能状态
同时,采用BP神经网络、SVM算法进行对比分析,预测准确率如表1所示。
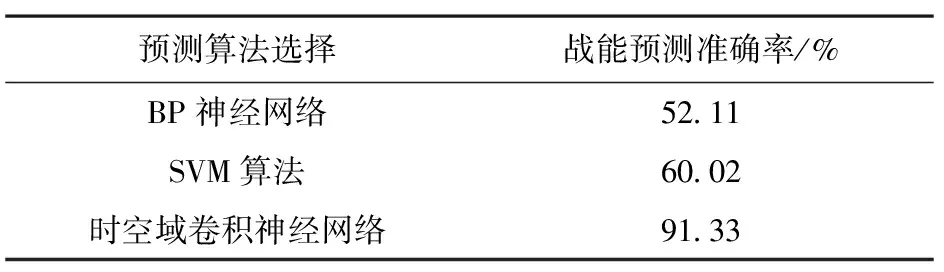
表1 4种战能预测模型的准确率对比
3.2.3战能势谱与决策网络
针对B艇战能随时间变化构建战能势谱。其中,针对B艇经航a转到主航b转过程中探测能、隐蔽能随时间变化如图8所示。同理可得相同时间A艇战能势谱。
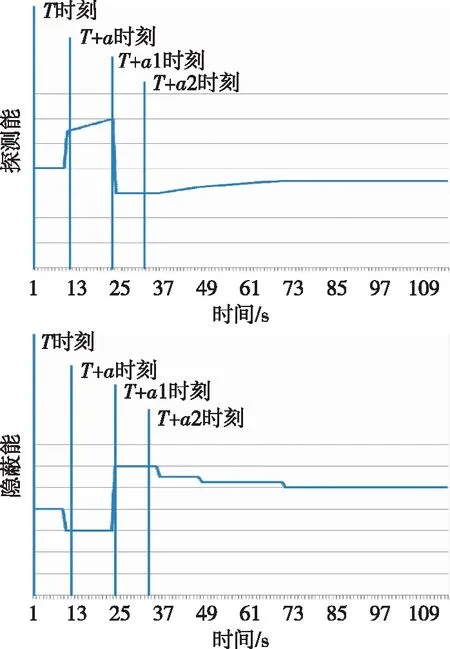
图8 经航a到主航b过程中探测能和隐蔽能随时间变化图
根据AB艇的战能势谱,分别输入A艇和B艇战能以及两方的空间关系,就可得A艇的作战决策和效能。如表2所示为红方小舷角远距离发现目标的决策网络实例。

表2 红方小舷角远距离发现目标时决策网络
3.3 分析与结论
综合以上分析,通过基于时空域卷积神经网络的预测模型,可以在感知能量的基础上,预测对手下一步能量变化,这里用到基于时空域的卷积神经网络可以较大幅度地提高战能预测准确度,达到91.33%;在作战任务时间描述模型的基础上,以探测能和隐蔽能为例构建了战能势谱,从图中可以看出,探测战能和隐蔽战能是两个相互影响的战能分量,随着作战进程的推进,探测能增加的同时,隐蔽能会相应减小,而后保持稳定。基于战能势谱输入当前战场空间关系,得出的作战行动和效果与实际保持一致。
4 结束语
将时空逻辑推演方法用于作战实验,用来主动揭示实验过程的时空逻辑关系,实现了将人类指挥与计算机智能进行交互、分析、比较、处理和印证的智能指控,将人类指控与战争统计、军事常识与装备性能、仿真模拟与外场试验等数据充分融合,精细化了系统数据,改进了实验方法,增强了作战实验的科学性和可信度,对全面提升作战实验运用方法的客观性具有很强的现实意义。
参考文献:
[1]陈建华,等.舰艇战法实验与分析[M].北京:国防工业出版社,2010.
[2]钱学森,等.论系统工程[M].长沙:湖南科学技术出版社,1982.
[3]曹裕华,刘淑丽. 装备作战试验与鉴定概念内涵及关键问题研究[J]. 装备学院学报,2013,24(4):123-125.
[4]李博,谭志强,贾宁宁. 装备作战试验关键问题研究[J]. 国防科技, 2014,35(4): 76-79.
[5]罗小明,池建军,周跃. 装备作战试验概念设计框架[J]. 装甲兵工程学院学报,2012,26(4):5-10.
[6]张德群,李剑雄. 作战实验在“网络中心战”研究中的运用[J]. 情报指挥控制系统与仿真技术,2004,26(6): 8-11.
[7]卜先锦,张德群. 作战实验学教程[M].北京:军事科学出版社,2013.
[8]李俊,范怡, 刘泽勋. 美军谋求制能权,确保“焦特”优势[J]. 中国航空报,2017.
[9]杨格兰,邓晓军,刘琮. 基于深度时空域卷积神经网络的表情识别模型[J].中南大学学报,2016,47(7):2311-2319.
[10] 王伟凝, 王励,赵明权,等.基于并行深度卷积神经网络的图像美感分类[J].自动化学报,2016,42(6):904-913.
[11] 常亮,邓小明, 周明全,等. 图像理解中的卷积神经网络[J].自动化学报,2016,42(9):1300-1312.
[12] 王忠民,曹洪江,范琳.一种基于卷积神经网络深度学习的人体行为识别方法[J].计算机科学,2016,43(2):56-58.
[13] 布威廉奇. 卷积神经网络的注解, 麻省理工学院CBCL技术报告,坎布里奇,马萨诸塞州,2006.
[14] 李宏东, 姚天翔. 模式分类[M]. 北京:机械工业出版社, 2003.
[15] 柯圣财,赵永威,李弼程,等. 基于卷积神经网络和监督核哈希的图像检索方法[J].电子学报,2017,45(1):157-163.
[16] 陶九阳, 吴琳,胡晓峰. AlphaGo 技术原理分析及人工智能军事应用展望[J].指挥与控制学报,2016,2(2):114-120.
[17] 金欣. “深绿” 及AlphaGo 对指挥与控制智能化的启示[J].指挥与控制学报,2016,2(3):202-207.
[18] 刘知青, 吴修竹. 解读AlphaGo背后的人工智能技术[J]. 控制理论与应用,2016,33(12):1685-1687.
猜你喜欢
四川党的建设(2022年8期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
小学生学习指导(低年级)(2020年11期)2020-12-14
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
作文大王·低年级(2018年10期)2018-12-06
北京航空航天大学学报(2018年1期)2018-04-20
小猕猴智力画刊(2016年5期)2016-05-14
棋艺(2014年4期)2014-09-17
棋艺(2014年3期)2014-05-29
