
H.265码流分析软件的设计与实现
2018-04-10 08:04许雪娇江苏省广播电视集团有限公司
视听界(广播电视技术) 2018年2期
许雪娇 江苏省广播电视集团有限公司
1.前言
随着视频技术的不断发展,人们对视频图像质量的需求越来越高,数字视频传输对带宽和存储的要求越来越高。这不但提高了对信息的传送、传播和存储速度的要求,更是对视频图像压缩性能的考验。数字视频的核心编码标准在不断地更新,国外视频压缩编码的格式主要由二大组织制定。ITU-T视频编码专家组制定了H.26X,ISO/IEC运动图像专家组制定了MPEG-X。HEVC/H.265是由以上两大组织联合制定的新一代高效视频编码标准,内含先进的编码技术及并行处理能力,在相同编码质量条件下,比H.264/AVC能够节约近50%左右的码流利用率。
本文设计并完成了对H.265编码视频文件的深度分析。包括视频基本信息(图像长宽、采样方式、亮度和色度的采样深度、帧数、层级信息等)、每个NALU基本信息(位置、字节长度、NAL类型、SLICE类型)和RBSP内容的详细解析(H.265标准文档目前定义了41个nal_unit_type的类型,包括VPS、SPS、PPS、SEI、AUD 等)。
2.H.265码流分析
在H.265编码格式中,视频文件被分为一个个NAL,为复杂的视频数据增加友好的网络接口。视频压缩数据根据其内容特性被分成具有不同特性的NAL单元(NALU),并对NALU的内容特性进行标识,即所有的压缩视频数据都被封装到不同NALU的荷载部分。NALU除了承载VPS、SPS、PPS等信息,主要承载视频片(Slice)的压缩数据。每个NALU又分为NAL头和NAL荷载。

表1 H.265的NAL单元头结构
2.1 NAL头结构
H.265的NAL单元头(nal unit header)与H.264的单元头不同,H.264只有一个字节,而H.265的码流开头是00000001,后面跟两个字节的nal_unit_header,H.265的NAL单元头结构如表1所示。
NAL头由固定的4部分构成,分别是forbidden_zero_bit,nal_unit_type, nuh_layer_id 和 nuh_temporal_id_plus1,各自占用 1,6,6,3个比特。其中nal_unit_type占6个比特,意味着它的取值从0-63,每个编号代表不同的NALU类型,如32代表视频参数集VPS,35代表定界AUD。
2.2 NAL荷载
在H.265编码文件中,各个不同类型的NALU具有不同的NAL荷载,各NALU的类型由NAL头中的nal_unit_type决定。根据nal_unit_type的不同,可分为:VPS,SPS,PPS,SEI,AUD,EOS,EOB等。视频在编码过程中输出的包含不同内容的压缩数据比特流片段被称为SODB。事实上,SODB指的是RBSP中的有效成分,去掉了RBSP结尾中为了取整的数字零。RBSP中可以包含一个SS的压缩数据、VPS、SP、PPS以及补充增强信息等。
在H.265编码视频的码流中,每一个NALU以0x000001作为起始码,以0x000000作为结束码。这就带来了一个问题,在NAL荷载中一旦出现上述的字节流,就会造成冲突,使一帧意外结束。为了解决这个问题,H.265编码规定将所有RBSP中非起始、结束码的,会产生冲突的比特流作如下处理:

其中,0x000002为预留码。需要注意的是,当RBSP数据的最后一个字节为0x00时,在数据结尾会加入0x03。
3.软件整体设计
本H.265码流分析软件流程框图见图1。根据文件编码格式判断文件类型,对于判断类型为H.265的视频文件,由帧头的起始码来决定如何将视频文件按帧分片,在一帧的数据中先读取该帧中nal_unit_type的值,根据取值判断该帧所属的类型。然后对提取出的帧数据进行处理,按照帧的类型分别将此帧中的各个语法元素提取并分类存储,包括在视频参数集(VPS)中提取档次和级别,在序列参数集(SPS)中提取图像格式,量化信息,在片段(SS)中提取帧类型等等,所有帧都依此进行处理并保存生成的语法元素树。

图1 H.265码流分析软件流程框图
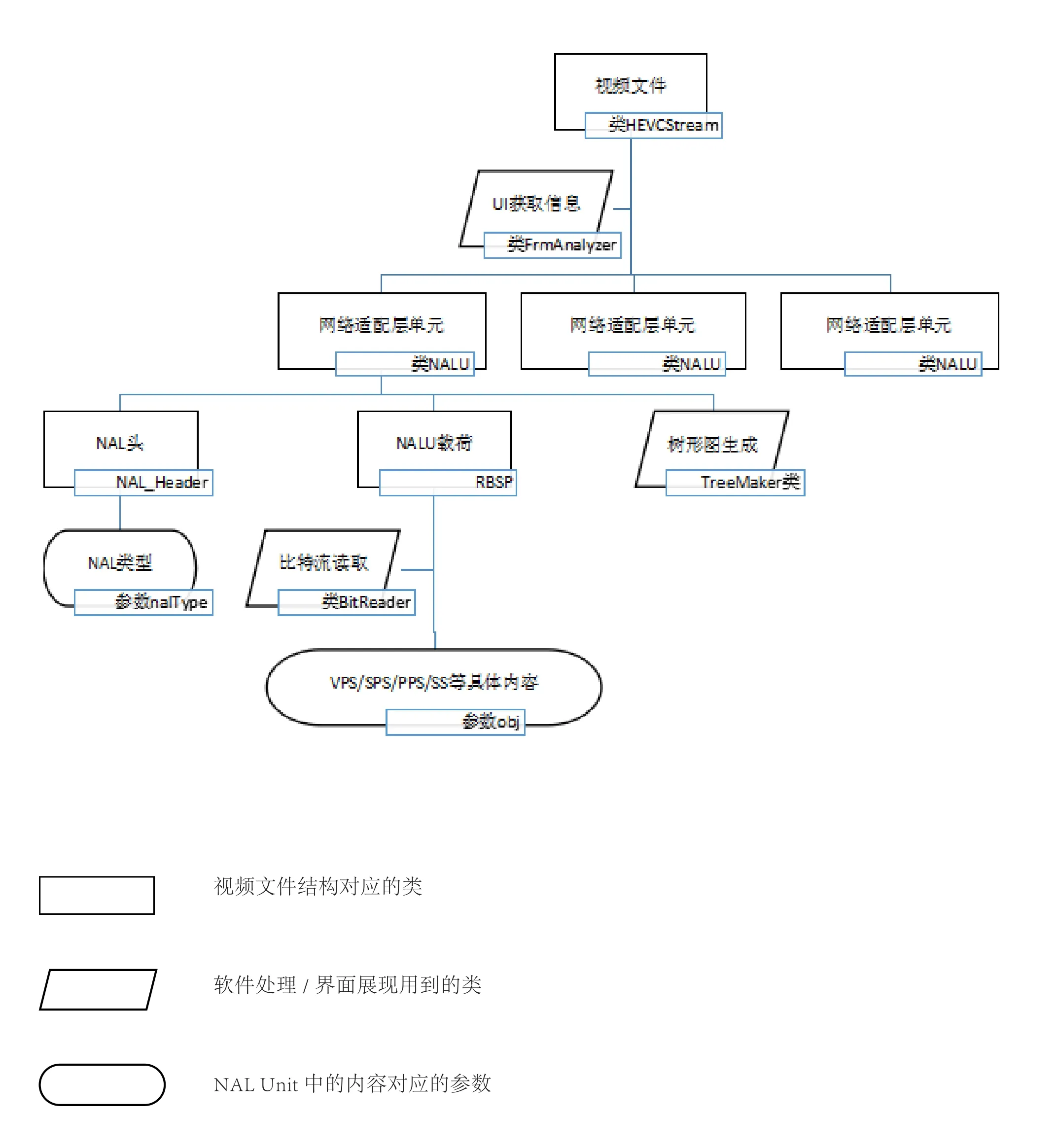
图2 视频文件结构和对应的程序框图
H.265视频文件结构和对应的程序如图2所示。H.265编码的视频码流将压缩视频数据封装成不同类型的NALU,即所有的压缩视频数据都被封装到不同NALU的荷载部分。在界面层获取码流信息时,先要将其分割成一个个NALU。对于每一个被分割的NALU而言,要分为三部分进行处理。首先是NAL头部分(NAL_Header),需要判断该NAL的类型,序号,参考帧等等。类型信息在每帧的nalType参数中。其次,要根据NAL头中判断出的类型,对NAL荷载进行处理,将RBPS数据读取进来以后,根据各自的编码特点,用类BitReader进行处理。最后,根据前两步处理好的数据,用TreeMaker类来生成每个NALU的树形图。
程序中依照实现的功能主要分为Stream处理,NalUnit处理,Bit处理和TreeNode生成这几大模块,程序模块划分如图3所示。Stream类负责初步处理一个视频文件,生成视频信息并扫描所有NALU信息。
首先对STREAM进行初始化,将文件所有内容读取至_byteFile字节数组内,提取读到的数据中第一个NAL的第一个字节,由前文的帧结构可以得知,每个NAL的第一个字节的第1-7个比特中含有该文件的类型信息,如果nalType属于在0和47之间的任意整数,则判断类型为H.265格式。判断完文件类型后返回,若文件类型错误,软件将给出WARNING警告。以上功能由JudgeVideoFile类实现。所有数据读入数组后,将获取所有NALU并生成NALU对象。具体流程是先将指针pos复位,用循环读取持续_byteFile,边读边判断每个NAL的起始字节,如果读到01则查看01与它之前是否满足0001或001,变量out用于返回这个NAL的起始字节数。以上功能由FindNextNal类实现。
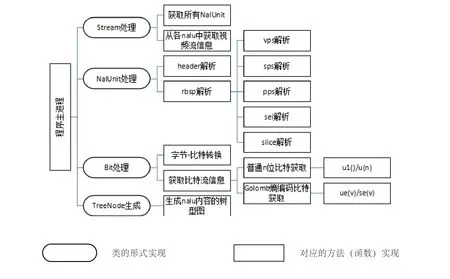
图3 程序模块划分
Stream处理的流程方法如图4所示。ScanNalu()函数主要负责扫描_byteFile并分析其中所有NAL。首先定义新指针pos,将其指向第一个NAL的起始位置。如果指针位置为负数,则返回false,找不到NAL。用循环搜索下一个NAL,每搜索到一个新的NAL,就新建一个NALU对象,将指针数组指向该NAL的开头位置,用读出的下一个NAL的开头位置减去这一个NALU的开始位置,计算出这个NALU的长度。记录下长度及NAL的内容传递给NAL对象的_byteNALU变量,将此NAL加入_lstNALU中,最后指针指向下一个NAL,循环直到处理完成所有的码流。当所有NAL都读取完毕后,此时可以将stream信息生成文字内容以备输出界面调用。
Nalu处理(NALU类)包括NAL Header解析和rbsp解析两部分功能,其中rbsp解析功能根据header中的type类型,调用不同的模块进行解析(VPS,SPS,PPS,SEI,SS等)。
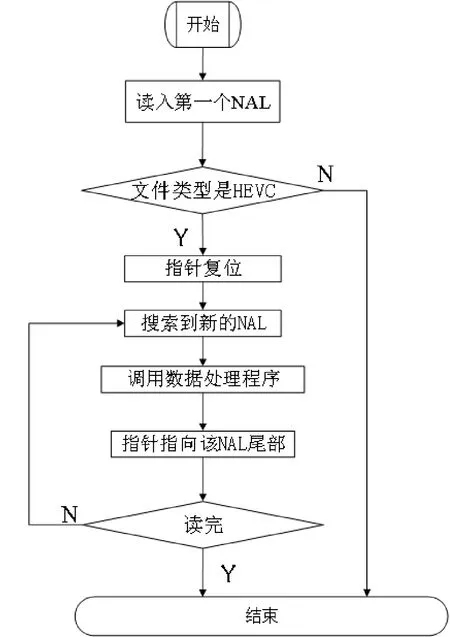
图4 Stream处理流程图
在对NALU解析时,要先进行准备工作,首先对NALU类进行定义。在每个NALU类中含有基础信息包括序号,长度,偏移,文本说明,start code的长度;码流信息包括存放NAL的字节数组,RBSP字节数组;文本格式的NAL字节显示等等。
将NALU进行初始化,新建一个BitReader的对象_bitNALU,将NAL的字节数组传入,指针指向第一个比特,为防止显示界面杂乱,如果此NALU超过5000字节,则只需将前5000字节放在待显示的位置,接着处理NAL头的数据,此处调用BitStream中已经编写好的函数即可。为了避免帧中的数据和起始码形成冲突,每个NAL中的RBSP都做了预处理,在读取数据中的语法元素时,需要先将其恢复。
上述处理方法在NaluToRbsp程序段中有所体现,从byteNALU的起始位之后开始检测,count用来记录0x00连续出现的个数,每当读取到0x03则判断,不允许出现00000102这样的组合,且03之后的一位不应该大于03。如果判断出冲突则将其记录并更改,否则跳过这个0x03位。这样,在将NALU转换成RBSP的同时也检测出了这些“竞争机制”并进行还原,以方便接下来的操作。
对nalType进行判断,调用BitStream中对应的解析方法处理数据。此处以VPS为例,如果CASE语句判断出该NAL的NAL_UNIT_TYPE为32,对应的类型就是视频参数集VPS,程序转到处理VPS的函数处继续运行。
具体类型读取方法,以读取一个普通的SLICE为例,参考H.265标准文件《T-REC-H.265-201504-I!!PDF-E》中第7.3.6.1 节General slice segment header syntax中对码流格式的定义,图5说明了读取数据的流程。
读取一个新的SS时,首先要将指针POS复位,指向第0个比特位。首先根据H.265编码定义表判断第一个语法元素有没有前置判断因素,是否由于前面的FLAG标识而导致这个元素不存在,如果该元素存在,就根据编码方法选择读取方式。如果是固定比特位,就调用BitReader中的函数ReadU1()或者ReadU3()等等;如果是不固定比特位数,则分为两种情况,无符号零阶熵编码调用BitReader中的函数ReadUE(),有符号零阶熵编码调用BitReader中的函数ReadSE()。该语法元素读取完毕,指针POS移动至该语法元素末尾,如果指针已经移动到整个片段SS的末尾,即将整个片段SS读取完毕,如果是,则整个流程结束,如果没有读取完毕,则继续循环读取下一个语法元素,直到读取完毕为止。
在读取过程中,需要注意片段中slice_type表达的片段的类型,slice_type类型对照如表2所示。
由于H.265提升了编码的效率,同样的信息可以引用前面已经表述的内容,不用重复编码,所以,大多数帧都有对前面帧的引用。在分析当前SS的程序中,要注意SS引用PPS的ID号和从PPS可找到引用的SPS的ID号。在编码中引用的内容被省略了,但是,程序在翻译编码时要将其翻译出来。
BitReader类中包括字节流-比特流转换模块和比特流信息读取模块两部分功能。这个类更多的是提供辅助性的功能,实现了byte字节数组转为bit数组的方法,将所有码流由十六进制转换为二进制数据,为其他部分的读取数据提供方便。
同时,由于在H.265视频编码的规则中,每个语法元素并不是以字节为单位进行表达,而是以非整数字节的零散比特位为单位。所以,在BitReader类中,还提供了一些以比特为单位读取数据的函数,如ReadU()/ReadU1()/ReadUE()/ReadSE()等方法调用。在H.265视频编码的规则中,使用了一些不定比特数的语法元素,它们被称为零阶指数哥伦布编码,读取这类语法元素时,必须根据编码特点,单独用函数读取。
在H.265视频编码标准中,由于语法元素是层层归属的,在表现形式上,比起常规的表格或是图片,更倾向于展现语法元素的归属关系。而树形结构是典型的层次的嵌套结构,一个树形结构的外层和内层有相似的结构,在编码中更是能以递归的形式展现,所以本软件采用了树型结构来表达语法元素的归属关系。

图5 读取数据流程图

表2 slice_type类型对照表
TreeMaker类包括了一个公有方法MakeTree()和多个nodeMaker模块,可根据传入的NALU对象来生成对应的TreeView节点用以直接在界面中显示。在TreeMaker类中,只要将tree调用,即可实现软件右下角的展现每帧的语法元素的功能。
最后在用户界面中,主要实现了将H.265视频文件读入,显示NAL列表的信息,以十六进制显示原始码流,显示STREAM流基本信息和以树形结构图显示任一NAL的语法元素分布这5种功能。软件编辑界面示意图如图6所示。
在程序运行和软件进行交互的过程中,为了完成用户发出的指令,常常不可避免地需要从一个线程中调用另一个线程,而这种操作在C#中是绝不允许的,因为C#的编程逻辑认为这样操作会出现循环调用,一旦程序的逻辑出现问题,就将陷入死循环。所以,软件采用了一种特殊的逻辑。以TreeView界面的更新为例,当软件操作触发了TreeView的调用时,首先判断这是否为界面线程的调用,当一个控件的InvokeRequired属性值为真时,说明有一个创建它以外的线程想访问,如果判断为真的话,就新开辟一个线程,再调用一次TreeView的更新函数,这时,由于之前已经开辟过一个新的线程,不会产生冲突,所以程序会转到TreeView真正的更新程序上运行。程序实现的方法如图7所示。

图6 软件编辑界面示意图
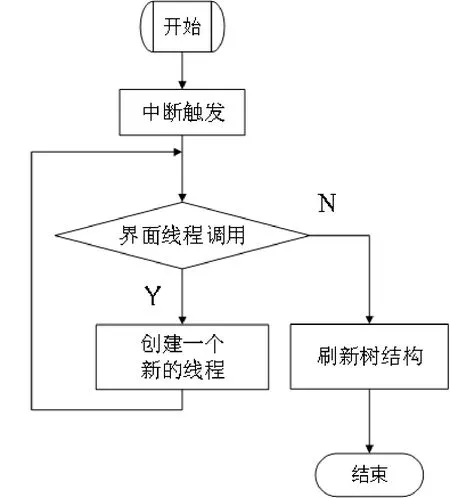
图7 调用新界面线程
其他更新界面进行显示的程序中,使用的方法是类似的,这里不做赘述。
4.软件的调试和分析
软件完成后,用20多个不同大小的文件对软件进行了测试,文件格式有hm10,h265和bin两种,都是官方指定的H.265格式文件。文件大小从十几K到几兆不等。
在测试到suzie_qcif.h265文件,点选第4帧NAL_UNIT_PREFIX_SEI,生成该帧语法元素树状图时,程序没有响应。推测该处程序陷入死循环中,在TreeMakeer.cs的C#程序段中,找到了出错的程序。在程序进行到制作SEI的树状图时,转到了函数MakeSEINode中,首先添加了sei_payload这个语法元素,对payloadType进行判断,不同的payloadType值会添加不同的数节点。但针对出错的这个视频文件来说,第四帧中的payloadType取值为5。原程序中只是在树中添加了user_data_unregistered()节点,将程序扩充并修改后,添加了2个三层的子节点,使得树状图中此节点可以被展开,从而消除错误。
最后经核对,修改过错误的本软件和商业化的H.265分析软件Elecard HEVC Analyzer得出的结论完全相同,所以,本软件均成功通过样例测试。
5.结束语
本文提供了H.265编码方式的详细分析和基本设计思路。根据本文提供的思路和方法,可以完成一个清晰简洁的H.265分析软件,得到视频文件的帧基本信息、语法元素信息和STREAM流信息,并将帧的树状结构图与原码流信息进行对比查看,为研究H.265编码方法提供了方便。
参考文献:
[1]万帅,杨付正.新一代高效视频编码 H.265/HEVC:原理、标准与实现[M].北京:电子工业出版社.2014:22-94,230-237,269-291.
[2]H.265标准文档《T-REC-H.265-201504-I!!PDF-E》
猜你喜欢
信息通信技术与政策(2022年10期)2022-11-09
视听(2021年8期)2021-08-12
电脑报(2021年23期)2021-07-23
商品与质量(2019年34期)2019-11-29
测控技术(2018年5期)2018-12-09
信息安全研究(2016年4期)2016-12-01
电子技术与软件工程(2014年20期)2014-11-19
电视技术(2014年19期)2014-03-11
卫星电视与宽带多媒体(2013年15期)2013-10-21
无线电工程(2013年1期)2013-09-19
