
一种基于关联规则的中文变体词识别算法
2018-04-08 09:59:26赵俊杰
重庆理工大学学报(自然科学) 2018年3期
赵俊杰
(安徽财经大学 工商管理学院, 安徽 蚌埠 233030)
随着手机及互联网的高速发展和社交网络的兴起,经常会遇到如何正确识别变体词的问题[1]。例如,很多网民往往会采用不规范的汉字书写办法,使用字形相近的生僻字来代替原有的文字,或者针对某些敏感词采用加特殊符号的办法等[2]。这样做的目的或者是为了避开一些政治敏感词语[3],或者为躲避常规的过滤方法来发布广告以及反动、暴力或者色情等不良信息。这些变体词主要出现在短信、微博/博客、论坛、电子小说、电子邮件、微信以及各种即时通讯中[4]。
大量的广告与不良信息常常干扰到用户对互联网的正常使用,甚至会给用户带来损失。目前针对广告与不良信息主要采取关键词匹配的方法来进行识别和过滤,常见的关键词匹配方法是基于中文信息处理技术和多模式匹配技术,能够有效发现各种广告和不良信息,技术实现简单[5]。但因这些文本中存在的关键词中间夹杂字符、对关键词中的关键字使用形近字或拼音进行替换等变体特征,在实际应用中存在较高的误判率或漏判率,使得人工干预成本增加[6]。同时,需要不断增加新出现的各种特征进入关键词库,造成关键词库的极大冗余[7]。国内外一些专家学者针对中文变体词的识别技术和算法也进行了大量研究,例如:王宝勋等[8]提出一种适用于中文的基于无监督的变体词识别算法;汪霞等[9]针对特征词变异的中文垃圾邮件问题,提出了一种基于变体特征词匹配还原的新贝叶斯邮件过滤算法;温园旭等[10]提出的基于层次特征的变体短文本过滤算法;Sood等[11]在对不良文本及其变体信息进行检测的时候,采用机器学习的方法,通过采用bigram、词干等作为特征值来对文本信息做分类分析,以检测出变体词;Wang等[12]将中文微博变体词的发现与中文分词结合起来,提出二层阶乘条件随机场模型,并将两者结合起来,使得两者的性能都有所提高。Zhang 等[13]提出了一个端到端的无监督的方法,基于深度学习实现对变体词及其目标实体词的映射关系的发现。另外,部分防水墙过滤系统中对于网络灌水等恶意行为的监测,是将所有汉字转换成拼音形式,然后检索和过滤拼音关键字,但效果不理想。总体来说,关于中文变体词的识别技术研究还较少,目前对中文变体词仍缺少有效的解决方法。
本文研究中文变体词的识别技术和算法,对于垃圾邮件与短消息的过滤、不良信息的检索等都有着非常重要的作用。本文针对中文变体词的常见类型进行分析归纳,设计出一种基于关联规则的中文变体词识别算法,以提升识别效果。
1 中文变体词的分类及相关工作
1.1 中文变体词分类
通过对于中文变体词的收集和分析,中文变体词总体可以分为3种类型:
1) 汉字字形的变体,即使用繁体字、同音字或形近字替换部分或者全部目标词语,如“代开发票”替换为“代开发飘”等;
2) 汉字变换为字母,即使用英文单词、拼音或者拼音缩写替换目标词语,如“发票”替换为“fa piao”等;
3) 汉字词中包含特殊字符,即在中文词语中插入特殊字符或者使用特殊字符进行部分汉字替换,这里特殊字符包括字母或汉字的偏旁部首等形式。如“招聘淘宝刷钻”替换为“招*聘*淘*宝*刷*钻”等。
中文变体词的分类采用以上划分方式的主要目的是方便中文变体词识别算法的设计。另外,还有使用图形或图片替换中文目标词语的情况,需要图形识别等技术,这里不做讨论。
1.2 中文分词方法的改进
目前,常见的中文分词技术主要有基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法[14]。对于已经收录词库的词语分词结果误差较小,但对于一些新词或者变体词的分词效果不是很好。这里对于中文分词方法的改进主要是针对中文变体词的划分。
大多数中文分词系统对于不能识别的词语或者字符都是单独分离出来进行分别标注,这样做的结果可能使得大多数中文变体词被分成多个单个的字符和汉字,例如原文:“本站诚征EMAIL广告代理,收费为每群发一次EMAIL广告100元。”被分解成“本站/诚/征/EMAIL/广/ #/告/ #/代/ #/理/,/收费/为/每/群/ #/发/ #/一次/ EMAIL/广/ #/告/ #/100/元/。/”。
本文对中文分词系统做部分改进,即对于不能识别的字符与前后的单个汉字合并,直至后面词语或符号等能够被单独识别和标注。这样设计的主要目的是尽可能地分出多字词和短语,方便中文变体词的识别。对ICTCLAS中文分词系统[7]进行改进,对于以上的例子,在改进后的ICTCLAS中文分词系统中分词的结果为“本站/诚/征/ EMAIL/广#告#代#理/,/收费/为/每/群#发#/一次/ EMAIL/广#告#/100/元/。/”。
1.3 中文变体词库及其关联词库的建立
对于中文变体词库的建立本文主要针对以上分类中的第1种和第2种类型,主要原因是第3种变体类型变化较多,如采用多种特殊字符进行替换等,不方便归纳和存储。中文变体词库包括3个表:中文变体原词表、字形变体表、字母变体表。其中:字形变体表主要收录变体原词的繁体字、常见同音字和形近字;字母变体表主要收录变体原词的英文单词、拼音或者拼音缩写。另外,为改善识别效果,还增加了1个关联词库。关联词库的建立原则是:首先对样本集的文本在分词后去除停用词,再筛选出与中文变体原词同时使用概率较大的词语集合,最后按照关联规则对每个中文变体词选定若干关联词语,形成关联词库。
中文变体原词表、字形变体表、字母变体表按编号建立关联,一一对应。关联词库与中文变体原词库中各表也按编号建立关联。这里共收集了477个变体原词(政治敏感词102个,广告词85个,反动和恐怖词93个,色情词71个,其他126个)和变体词以及关联词,分别存放在中文变体原词表、字形变体表、字母变体表以及关联词库中。
2 基于关联规则的中文变体词识别算法
2.1 算法优势与总体思路
对于中文变体字的识别目前采取的方法主要是基于多模式匹配技术和中文信息处理技术。多模式匹配技术即采用统计和规则的识别方法,这种方法主要依赖于匹配规则和变形词库。在实际运用中,一是精准的匹配规则较难确定,二是变形词库庞大,使得识别效果不理想。基于中文信息处理技术主要是对变体词在语义相似度上进行比较,在比较时一般是结合上下文或时空分布的相似性。但这种方法严重依赖变体词的若干个样本聚合上下文和时空信息,因此实际识别效果不稳定。
本文采取的算法是对以上两种方法的结合和改进:一是对模式匹配方法进行了改进,分类型进行匹配,提高了效率;二是采用关联词库辅助识别,相比结合上下文或时空信息进行语义相似度计算要简单易行,实际识别效果也较稳定。其主要思路是:先通过字符串匹配算法识别出初步目标,然后通过关联分析进一步识别判断,最后通过人工判定辅助最终识别出结果。对于识别出的结果可以补充和更新相应的变体词库和关联词库,具体识别过程如图1所示。
具体步骤为:
1) 将待查文本转换成文本格式,通过改进的分词系统进行分词;
2) 判断文本中每个词语或短语,是全部汉字、汉字与字符组合还是全部字母,然后分别结合对应变体词库,使用相应的识别算法进行识别;
3) 将初步识别结果进一步结合关联词库进行关联分析;
4) 对于关联分析的结果辅助于人工判定,最后给出最终识别结果;
5) 将识别结果补充和更新变体词库和关联词库。
识别算法在执行过程中首先判断目标类型,即扫描每个分词结果,判断是否全为汉字,若是则判断为第1种类型;否则再判断是否全为字母,若是,则为第2种类型;否则归为第3种类型。目标类型判断过程如图2所示。
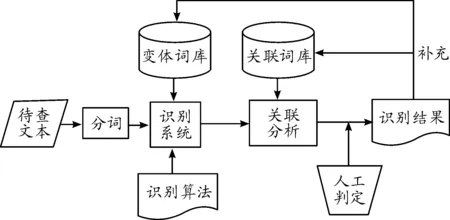
图1 基于关联规则的中文变体词识别算法
对于目标类型判断结果采取以下3种对应处理方法:
1) 全部汉字情况
对于繁体字和同音字,首先检索变体词表中繁体字项和常见同音字项,如果有完全匹配项则标出,直接给出识别结果;否则将目标转换成拼音形式,然后与字体变体库中字母变体表的拼音项进行比较,如有相同则标出,没有匹配项则进入形近字识别。
对于形近字的识别,先检索字形变体词表,查看有无完全匹配项,如有则标出;没有则与变体词原表比较。如果有超过一半与原表中汉字相同,且字符数相等,则标出;否则,认为无匹配项。
2) 全部字母情况
由于变体词库中字母变体表中收录了变体词对应的拼音、拼音缩写和英文形式以及英文缩写形式,因此直接将目标与字母变体表中各项进行比较即可。如果有匹配项则标出;否则,认为是无匹配项。
3) 汉字与字符组合情况
由于这种类型变化较多,因此没有建立相应数据库表,在识别时,主要根据变体词原词表进行检索目标词语或短语,只要其中的汉字部分与变体词原表中的原词相应部分相同,则标出;否则,认为无匹配项。
2.2 关联规则设置与关联词库建立
设I={X,i1,i2,…,im}是项的集合,包括某一变体词及其所在语句中的去除停用词之外的词语集合。事物数据库D为变体词及所在的每条语句中去除停用词之外的词语集合,D={t1,t2,…,tn},ti(i=1,2,…,n)对应I上的一个子集,存放单条语句中的词语集。X⊂I,Y⊂I,X∩Y=∅,其中:X为变体词;Y为高频词集。这里高频词的选择设定为变体词所在语句范围内,是考虑到如果设定为全文范围,选择的高频词可能大多数与全文主题相关,但变体词不一定与全文主题相关,以此作为关联词的选择可能造成变体词的识别效果误差较大。对于其他变体词及其所在语句中的高频词可设定同样集合。关联规则X=>Y的支持度与置信度公式如下[15]:
Support(X=>Y)=P(X∪Y);
Confidence(X=>Y)=P(Y|X)=P(X∪Y)/P(X)
主要思路为:
1) 对样本中文本分词,去除停用词,人工抽取样本中包含有变体词的语句;
2) 对于每个变体词找出其所在语句中的前m个高频词;
3) 分别计算变体词与相应的这m个高频词在事物数据库D中同时出现的支持度与置信度;
4) 对于其他集合中每个变体词及其相应的高频词做同样计算;
5) 设置最小支持度和最小置信度值,以此对变体词的关联词语进行选择。
作为初步实验数据,抽取电子邮件2 500条,论坛发帖1 500条,电子小说600篇作为训练样本。通过统计分析发现:与变体词所在语句中同时使用概率较大的高频词基本集中在前7个高频词中,因此这里m值设为7。由于实验数据较少,这里只选取了在实验数据集出现的其中50个变体词。表1和表2是部分变体词的7个关联词语的支持度和置信度计算结果。

表1 部分变体词的主要关联词语的支持度计算结果 %

表2 部分变体词的主要关联词语的置信度计算结果 %
通过对计算结果进行统计发现:对于某一个变体词的每个关联词最小支持度和置信度,数值都较小;对于不同变体词的关联词,其支持度和置信度出现较大差别,最小支持度和置信度值较难设置,且依此选择的关联词比较分散,出现稀疏项目问题[16]。即:如果最小支持度太高,有些项目集中就不会生成包含稀疏项目的规则;如果最小支持度设置太低,就会生成太多的规则,而且其中很多规则都是不重要的[17]。解决稀疏项目的可行方法是将稀疏项目组合,并对这些组合重新生成关联规则,并按此关联规则重新选择关联词语集合,建立关联词库。
定义1支持度公式。设I={X,i1,i2,…,im}是项的集合,包括某一变体词及其所在语句中的去除停用词之外的词语集合。事物数据库D为变体词及所在的每条语句中去除停用词之外的词语集合,D={t1,t2,…,tn},ti(i=1,2,…,n)对应I上的一个子集,存放单条语句中的词语集。X⊂I,Y⊂I,X∩Y=∅。X为变体词,Y={i1,i2,…,ik},k=1,2,…,m,且规定当X出现时Y中的任意一项同时出现,则 Support(X=>Y)=P(X∪Y)就成立。
定义2置信度公式。X⊂I,Y⊂I,X∩Y=∅,X为变体词,Y={i1,i2,…,ik},k=1,2,…,m。当X出现时,Y中的任意一项同时出现,则Confidence(X=>Y)=P(Y|X)=P(X∪Y)/P(X) 成立。
由于不同变体词的关联词语的支持度数值差别较大,因此对于每个变体词的关联词分别单独计算其支持度。由于篇幅有限,表3和表4只给出k取1~7时部分变体词的支持度和置信度计算结果。

表3 k取不同值时支持度计算结果 %
表3、4中:当k=1时,值为第一个高频词支持度值;当k=2时,值为前两个高频词组合,以此类推。由表3和表4中数据可以看出:随着k值增大,其支持度和置信度值也随之增大,但在实际识别中误差也会增大。这里对于k的取值,如果统一设定一个固定值,由于有的变体词的关联词比较集中,有的变体词的关联词比较分散,导致误判率较高。因此,这里根据最小关联度值和最小置信度值作为k取值的依据,即确定关联词集合中词语的个数。通过对初步实验数据的综合分析,将最小支持度的值设定为15%,最小置信度值设定为40%,此时k的取值比较合理。每个变体词在此最小支持度和最小置信度下分别取对应的k值,当两个k取值不统一时,以最小的k值为最终值。统计表明,大多数k的取值主要集中在2~5之间,少数k值为1和6。考虑到计算误差和样本较少,在实际执行过程中对k值进行微调,即:当k<2时,k=2;当k>5时,k=5。这样设计的目的在于:如只取一个关键词和超过5个关键词,可能造成关键词过于集中和过于分散。
3 实验及结果分析
3.1 实验语料的选取及准备工作
本文收集了477个变体词样本作为实验数据,其语料来源为网上收集的包含变体词的电子邮件、论坛和电子小说。其中,电子邮件5 000条,论坛发帖3 500条,电子小说1 300篇。这些实验语料中的变型词主要涉及广告、不良信息和政治敏感词语等。在实验前期,抽取电子邮件2 500条、论坛发帖1 500条、电子小说600篇作为训练样本,剩下的作为测试样本。由于收集的变体词样本只涉及到部分变体类型,因此在测试样本中人工增加了一些变体词实例,尽可能覆盖各种变体类型,以便检验整体的识别效果。
对训练样本进行分词,去除停用词。针对训练样本中的变体词进行统计和归纳,分别建立中文变体词库。其中,中文变体词库包括中文变体原词表、字形变体表、字母变体表。对于每个变体词先找出其所在语句中的前7个高频词,然后根据最小支持度值和最小置信度值为每个变体词建立关联词集,从而形成关联词库。
3.2 实验过程
首先对于测试样本进行初步识别,未使用关联规则,3种变体词类型的识别效果如表5、6所示。
进而对测试样本做基于关联规则的变体词识别整体测试,对比初步识别结果和基于关联规则的识别结果,如表7所示。

表5 测试样本各类型识别效果 %

表6 测试样本平均识别效果 %
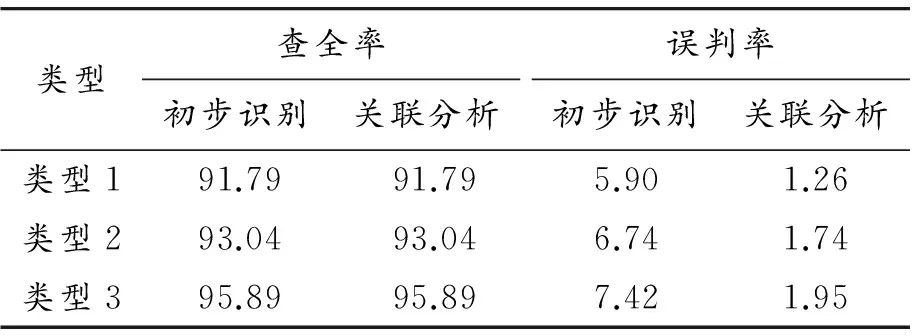
表7 测试样本识别效果对比 %
3.3 实验结果分析
通过对改进后的分词结果进行初步字符匹配识别,可以初步识别出绝大多数疑似变体词的目标。对于不同类型采取不同的字符匹配的方法,使得平均查全率超过93%,其中对于繁体字、拼音替代、英文替代以及插入字符等类型识别效果较好,误判率较低,对于同音字、形近字和字符替代类型误判率稍高。分析其原因为:每个变体词的不同同音字和形近字较多,不能全部收录;字符替换的形式也是各种各样,尤其是变体词中大部分汉字被替换成符号的情况,容易造成误判。
对于初步识别的结果通过进一步借助关联词库分析识别,对于误判率有显著改变,尤其是同音词和字符替换类型,使得变体词识别的平均误判率下降到2%以内。
4 结束语
在现实生活中,大量的广告和不良信息为了规避常规方法的检测和过滤,常常以不规整、不正常的形式出现,即采用变体的形式使传统方法无法正确检测和过滤。但是这部分包含变体词的文本却仍能够达到发布广告、不良信息的目的。本文通过对改进后的分词结果进行初步字符匹配识别,可以初步识别出绝大多数疑似变体词的目标。对于不同类型采取不同的字符匹配方法,使得平均查全率超过90%,接着对于初步识别的结果进一步借助关联词库分析识别,可显著减少误判率,尤其是对同音词和字符替换类型,使得变体词识别的平均误判率下降到2%以内。但对于文本行列变换,图形替代等变体形式如何识别未在算法中考虑,这部分内容将在后续研究中进行。
参考文献:
[1]罗刚,张子宪.自然语言处理原理与技术实现[M].北京:电子工业出版社,2016.
[2]陈鄞.自然语言处理基本理论和方法[M].哈尔滨:哈尔滨工业大学出版社,2013.
[3]谢邦昌,朱建平,李毅.文本挖掘技术及其应用[M].厦门:厦门大学出版社,2016.
[4]朱俭.文本情感分析关键技术研究[M],北京:中国社会科学出版社,2015.
[5]范黎林,王晓东.一种用于垃圾邮件过滤的中文关键词匹配算法[J].河南科技大学学报,2006,27(5):35-37.
[6]丛健.不良信息过滤技术研究[D].北京:北京邮电大学,2012.
[7]周天绮.网络安全中的信息过滤综述[J].微处理机,2011.32(5):30-34.
[8]王宝勋,王晓龙,刘秉权,等.一种基于无监督学习的词变体识别方法[J].中文信息学报,2008,22(3):32-36.
[9]汪霞,郑宁.基于中文变形词匹配的贝叶斯邮件过滤模型[J].计算机应用与软件,2010.27(1):105-107,130.
[10] 温园旭.变体短文本过滤算法研究[D].北京:北京邮电大学,2012.
[11] SOOD S O,ANTIN J,CHURCHILL E.Using Crowdsourcing to Improve Profanity Detection[J].Aaai Spring Symposium,2012,33:69-74.
[12] WANG A,KAN M Y.Mining Informal Language from Chinese Microtext:Joint Word Recognition and Segmentation[C]//Meeting of the Association for Computational Linguistics.2013:731-741.
[13] ZHANG B,HUANG H,PAN X,et al.Context-aware Entity Morph Decoding[C]//Meeting of the Association for Computational Linguistics and the,International Joint Conference on Natural Language Processing.2015:586-595.
[14] 黄昌宁,赵海.中文分词十年回顾[J].中文信息学报,2007,1(3):8-19.
[15] 李爱国.数据挖掘原理、算法及应用[M].西安:西安电子科技大学出版社,2012.
[16] XINDONG W,VIPIN K.数据挖掘十大算法[M].北京:清华大学出版社,2013.
[17] MARGARETH D,邓纳姆,郭崇慧,等.数据挖掘教程[M].北京:清华大学出版社,2005.
猜你喜欢
小学生学习指导(低年级)(2023年10期)2023-10-28 06:34:40
疯狂英语·新阅版(2022年7期)2022-07-07 14:46:57
疯狂英语·新悦读(2022年7期)2022-07-06 13:36:40
小康(2022年7期)2022-03-10 11:15:54
小康(2022年7期)2022-03-10 11:15:54
小康(2021年7期)2021-03-15 05:29:03
小康(2021年7期)2021-03-15 05:29:03
作文周刊·小学四年级版(2017年35期)2017-10-18 14:44:45
英语知识(2016年1期)2016-11-11 07:07:54
电脑迷(2014年14期)2014-04-29 00:44:03
