
Improved Pre fix Based Format-Preserving Encryption for Chinese Names
2018-04-04 08:21:07JunweiZouPengWangHongLuo
China Communications 2018年3期
Junwei Zou, Peng Wang, Hong Luo,*
1 School of Electronic Engineering, Beijing University of Posts and Telecommunications, Beijing 100876, China
2 Beijing Key Laboratory of Intelligent Telecommunications Software and Multimedia,Beijing University of Posts and Telecommunications, Beijing 100876, China
*The corresponding author, email: luoh@bupt.edu.cn
I. INTRODUCTION
In the era of big data, public participation in data analysis is becoming more common.However, digital information, for governments, businesses or individuals, usually contains some sensitive information. If people release the information directly, the privacy will be compromised. Therefore, in order to obtain greater value from the public participation, there is need to handle the sensitive data.Due to the change in cipher text type, format,length and other information, the traditional encryption method cannot store the data back to the database. To adapt to this change, the database structure must be changed correspondingly. Furthermore, data mining results through plaintext are different from the cipher text. For example, the encrypted name is a meaningless string. Thus, the original relationship between it and other data may not be available through data mining.
For the above problem, the ideal solution is to use Format- Preserving Encryption (FPE)[1]. FPE cannot change the format when encrypting a plaintext into a cipher text, which prevents sensitive information from being leaked. Meanwhile, this method preserves the attribute characteristics and data format of the original data, which keep mining results of plaintext consistent with that of the cipher text. Besides, the encrypted cipher text can be stored back to the database or used by the program without changing the database structure and application code.
In addition, in the era of big data, the amount of published data is extremely large.The types of data are also varied. For the massive data, it is necessary to achieve automated processing and reduce the impact of human intervention. In the massive data scenario,multi-type self-identified format preserving encryption system, based on massive data processing and data type diversity, can effectively achieve the data automatic identification and encryption operations. Moreover, the above system takes the data file as the operating unit. It combines with multiple types of data format-preserving encryption algorithm to achieve multi-type data encryption and decryption operations. This paper mainly focuses on the encryption problem of Chinese format data.
At present, there are many researches on the formatting methods of reserved format encryption for numbers, characters, and so on[1][2]. However, the Chinese data encryption research is still relatively little [3]. Chinese data is usually encrypted with Chinese code.Although this method can retain the Chinese data attributes, the encrypted Chinese is usually an uncommon word. This method does not meet the Chinese name naming habits, which reduced confidentiality. This paper focuses on the Chinese name reserved format encryption. First, according to the characteristics of Chinese name, we design retention format encryption model for Chinese name. Then, we combined with the model to design Chinese name retention format encryption process.Combined with adjustment factors and cyclic encryption algorithms, the Cycle-Prefix algorithm is proposed as the core algorithm for Chinese name reservation format encryption.Finally, the Chinese name reservation format encryption scheme is designed in detail and the security analysis is given.
II. RELATED WORK
Format-preserving encryption is an emerging branch of information security and privacy protection, and has received extensive attention and research since the 1980s. Researchers have published a large of preserve-formatting encryption results. It promotes the development of preserve-formatting encryption. The research of preserve-formatting encryption can be divided into three aspects: basic algorithm,encryption model and application scenario.
The basic algorithm mainly focuses on FPE in basic type. Baldridge et al. [4] proposed a method based on DES encryption string. The cipher text yϵcharsnis valid for each plain text xϵcharsn. This guarantees that plaintext and cipher text have the same format. For the specific field of the database encryption and decryption problem, Smith et al. [5] tried to find a way to preserve the data type after encryption(Data-type Preserving Encryption). This method uses the CFB mode to generate the offset vector and sums up plaintext index vector.Then, we transform it into a cipher text string.Black et al. [6] resolved the format-preserving encryption problem from the view of cryptography. He presented the core of the format preserving encryption algorithm and proposed three basic construction algorithms based on
This paper studies the format-preserving encryption of the Chinese name.integer set preserving scheme, which includes Prefix algorithm, Cycle-Walking algorithm and Generalized-Feistel algorithm. These three algorithms not only solve the problem of integer format preserving scheme encryption, but also become the basic algorithm of preserving the format encryption model.
On the basis of the basic construction method, the encryption model begins to solve the more complex format preserving encryption problem. Spies et al. [7] constructed pseudo-random functions [8] by truncating the base packet cryptography AES output. Then,he combined Feistel Networks to build FFSEM model for more efficient format preserving encryption. Besides, he used the theory of circular encryption to solve the problem of format-preserving encryption on any integer set. Taking into account the complexity of the message space, Bellare et al. [9] proposed a complete definition of the format-preserving encryption and cryptography security goals.Then, he proposed the RtE (Rank-then-Encipher) model, that is, the sorted encryption model. He pointed out that the ability to find efficient sorting algorithm is the core of model design. In the same year, Bellare et al. [10]proposed an improved FFX model for the FFSEM model in the round function, Feistel network. Moreover, they used Feistel and the adjustment factor [11] to solve the string type data format-preserving encryption problem.
The scene research is mainly based on the speci fic application of the requirements about the scene and the speci fic data format, to design a specific format-preserving encryption algorithm. Sttz et al. [12] studied the application of format preserving encryption in multimedia data. It is noted that JPEG2000 can be desensitized with reserved format encryption.Pauker et al. [13] implemented a data processing system based on a reserved format encryption engine, which uses the Fesitel network to construct block ciphers to handle format preserving format encryption problems.
However, these algorithms and models are reserved for a single basic data type and they do not consider the problem of massive data and data type diversi fication.
III. MULTI-TYPE SELF-IDENTIFIED FPE SYSTEM
Multi-type self-identi fied FPE system contains multiple FPE algorithms corresponding to different types of data. The data file is used as the data container to provide the source data required for the encryption. Then, the system parses the input data file and identi fies the data type. Moreover, the corresponding encryption-decryption algorithm is initialized for data encryption and decryption operations. Finally,the system completes the data boxing operation according to the file structure information.
3.1 System module
The system includes file operation module,data processing module and encryption-decryption module, as shown in figure 1.
The file operation module is responsible for automatically unboxing files according to file type, reading and parsing data files. After that, the data in file is separated from the file structure for the data processing module.Meanwhile, the module is also responsible for recording the structure of the data file being read. In this case, the data can be automatically boxed based on the file structure information after decryption. The file operation mod-ule is the interface module between the system and the data to be encrypted. The functional design of this module is related to user operability and user experience.
The data processing module is mainly responsible for identifying the type of data imported from the file operation module. Then,it validates the data and initializes the corresponding encryption algorithm based on the identified type. The data processing module belongs to the mid-tier module and has certain scalability. According to the specific requirements of the system, the data recognition algorithm can be added or deleted.
The encryption-decryption module is mainly responsible for performing encryption and decryption operations on the classified data.The encryption-decryption algorithm involved in this module can be determined by the detailed analysis from the data processing module. Therefore, it also has the certain scalability as same as the data processing module. This module is the kernel module of the encryption-decryption, which directly affects the data format-preserving encryption. The algorithm selection is an important part of this module.
3.2 Multi-type self-identi fied FPE system process
The system uses the data file as the container.First, the input data file is parsed and the file structure is recorded. Then, the data types are identi fied for data screening. The type recognition algorithm is extensible and can be added or subtracted according to the actual situation.Moreover, type recognition should be filtered from fine screening to coarse screening. In the end, the unrecognized type is classi fied as the default type. It is necessary to check the validity of the data according to the identi fied type before the encryption-decryption operation. In consideration of the performance, it is not necessary to check the legitimacy of all data at once. Therefore, we can use the “lazy”thoughts to defer the legitimacy detection until the data format-preserving encryption. Finally,the initialized algorithm is used to perform format-preserving encryption for data. Also, a cipher file is generated based on the previously recorded file structure. The process is shown in figure 2. As can be seen from figure 2, the key part of the system lies in the identi fication and detection of multi-type data. On this basis,a FPE algorithm corresponding to data type is used for the encryption-decryption operation.
3.3 Data type in the system
Multi-type self-identified FPE system takes data file as the encryption-decryption unit.Data file usually contains multiple data in different types, including number, string, date type, ID number, phone numbers, and mailbox.
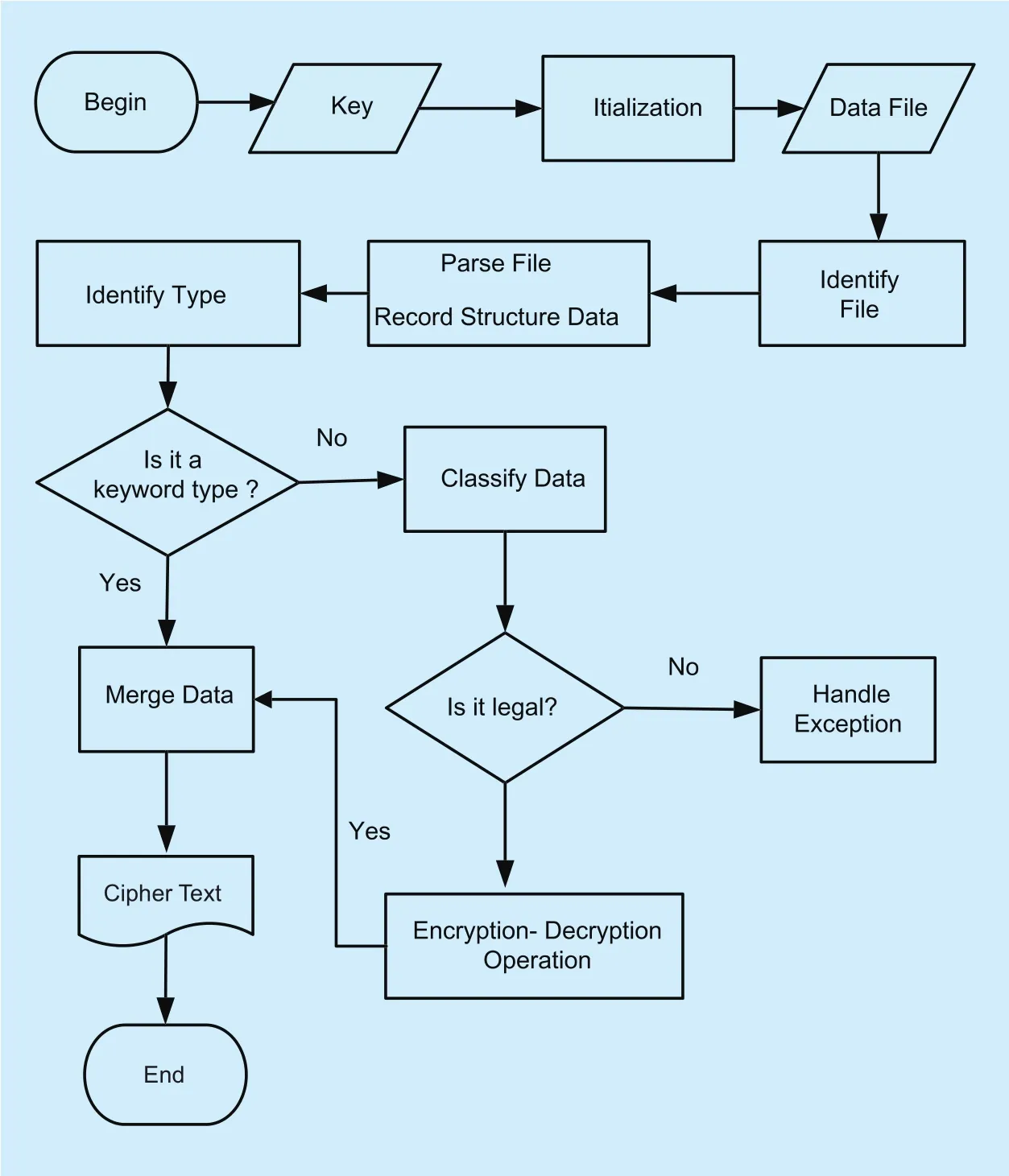
Fig. 2. Multi-type self-identi fied FPE system flow chart.
In these types, number and string belong to basic type, while date, identity card number,telephone number, mailbox and Chinese name can be classified as feature data. For FPE of number, an integer-type FPE algorithm [3] can be used. The string can be encrypted through the RtE model or the FFX model. For the feature data, the segmented encryption mode can be used to design the corresponding FPE algorithm according to the specific data construction rule.
At present, there is little research on the format-preserving encryption for Chinese and Chinese name. In various business operations of daily life, lots of Chinese data are produced.Chinese name is a class of representative user privacy data. Therefore, the research on Chinese name format-preserving encryption has certain signi ficance and application prospect.
IV. CHINESE NAME FORMATPRESERVING ENCRYPTION MODEL
4.1 Model introduction
In order to ensure that the cipher text still conforms to the naming convention of Chinese name after encryption, we first construct the Chinese name format-preserving encryption model, as shown in figure 3.
First, the model decomposes the name x into the last name x1and the given name x2.Then, the name field in the name library and the integer field form a bijection. Therefore,x1and x2are mapped to x1’ and x2’ in the integer field. Moreover, we use the Cycle-Prefix algorithm to encrypt x1’ and x2’ to y1’ and y2’.Finally, the map y1and y2in the name field are merged into cipher text y.
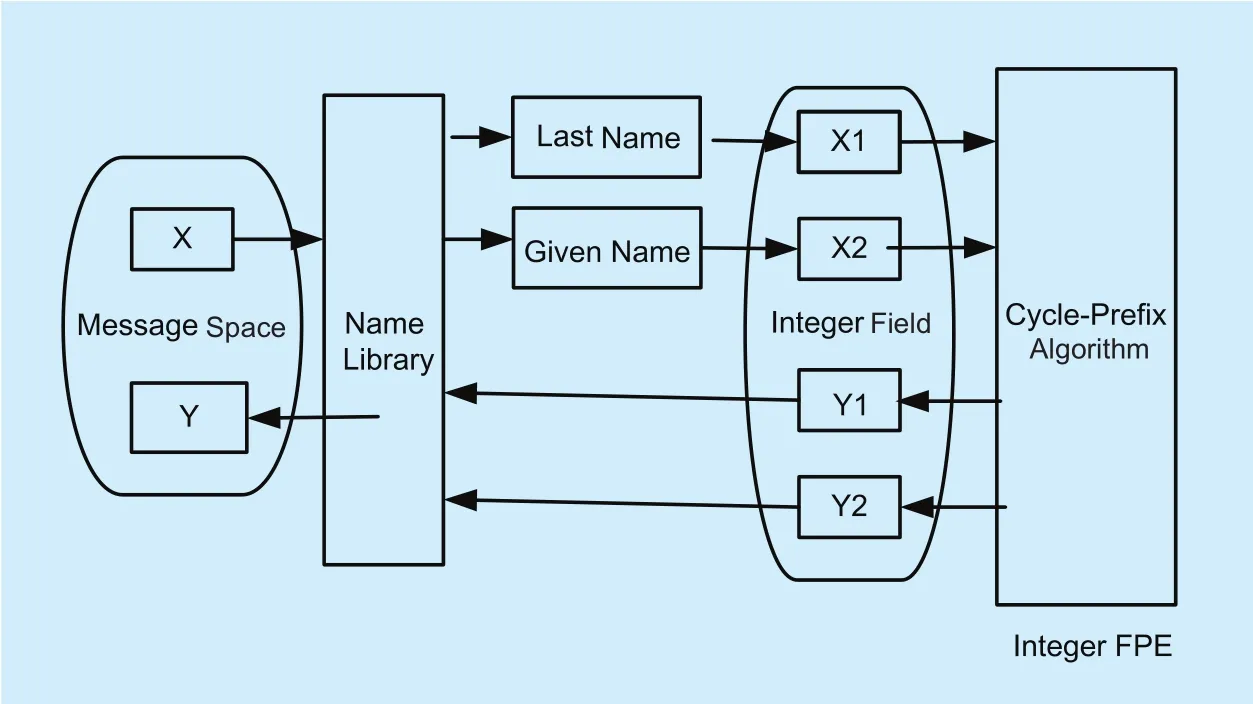
Fig. 3. Chinese name format-preserving encryption model.
4.2 Model sections description
4.2.1 Message space
Message space M refers to all the names which conform to the naming convention of Chinese name. Given P is the plain space, C is the cipher text space and M is the message space,then P, C and M meet the following rule:
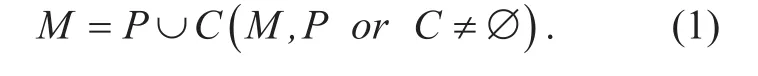
4.2.2 Name library
The name library N is the speci fic realization and existence form of the message space. Generally, the name library can limit the encrypted name within a reasonable range effectively. In addition, the name library is also used for the extraction of the last name and given name as well as the establishment of the bijection between the name field and the integer field. The name library N can be divided into last name library L and given name library F. According to the meticulous degree of encryption-decryption operation, the last name library L can also be divided into common surname library FL and uncommon surname library NFL.
4.2.3 Name field and integer field
The name field Snis the embodiment of content in the name library, while the integer field Znis the embodiment of name library size and content order. For a defined name library, its name field and integer field are unique. Meanwhile, there is a bijection between the name field and the integer field, that is:
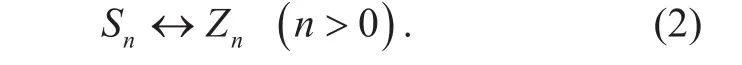
4.2.4 Cycle-Pre fix algorithm
The main idea of traditional Pre fix is rank and permutation [6]. If the message space is M ={1, 2, ..., n−1}, n < 106, we use the block cipher E to encrypt M to get the tuple A = (E(0),E(1), ..., E(n−1)). Then, we obtain the tuple B= {r0, r1, ..., rn-1} after sorting the tuple A in a selected sort way, so A and B form a permutation table. To encrypt m (m ∈ M), we only need to return the element rmwhose subscript is m in B.
As this model uses the name library to limit the message space, and the size of each library is about 103, the Pre fix algorithm can complete the encryption and decryption operations efficiently and accurately. However, if we only use the Pre fix algorithm alone, the same plaintexts will get the same ciphertexts after encryption. Moreover, Pre fix algorithm depends on the key too much, which makes the less security of this algorithm. In order to solve the above problems, we improve the traditional Pre fix algorithm and propose the Cycle-Pre fix algorithm in this paper.
Definition 1: The Cycle-Prefix algorithm can be described in the following Eq. 3.
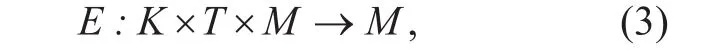
where K refers to the key space and T refers to the adjustment factor space [14]. In this model, the improvement of Pre fix algorithm mainly focuses on proposing the safety adjustment factor tsizeand the difference adjustment factor tlen, which can control the number of rounds about encryption and decryption.
4.2.5 Adjustment factor
The adjustment factor is the crucial part of the Cycle-Prefix algorithm, and two adjustment factors are added to the algorithm to increase the security. Two adjustment factors will be described below.
(1) security adjustment factor tsize
The security factor tsizeenhances the security of the FPE algorithm by controlling the number of rounds of the name encryption-decryption algorithm [6]. It can protect the user’s privacy from being leaked under the condition of the key being lost or leaked. When encrypting and decrypting, the user needs to provide a digit which has a length of six to ten. The above digit is used as the seed to generate the adjustment factor tsize.
The generation formula of security adjustment factor tsizeis as follows:
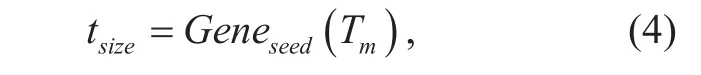
where Gene is the random and Tmis the adjustment factor space.
The security adjustment factor space Tmdetermines the number of round about the name encryption. The size of Tmis generally controlled between 10 and 50. Speci fically, too small Tmwill reduce the security of algorithm due to the limitation of cycle number, while too large Tmmay affect the efficiency of the algorithm and cause the unnecessary waste of computing resources.
(2) difference adjustment factor tlen
In the case of the same key and tsize, we will obtain the same ciphertexts after encrypting the same plaintexts, for example, all the surnames ”“Wang” are encrypted to the same “Liu”. In this case, it may leak some information such as the plaintext length or the location, which can be used by the attacker to attack the password. In order to increase the confusion and the crack difficulty of ciphertext, and reduce the correlation between the plaintext and the ciphertext, this model proposes the adjustment factor tlen. tlenis generated based on the length of the name to be encrypted and the seed. tlencan make the encryption result of the same plaintext show difference,by adjusting the number of round about surname encryption.
The generation formula of difference adjustment factor tlenis shown as follows:
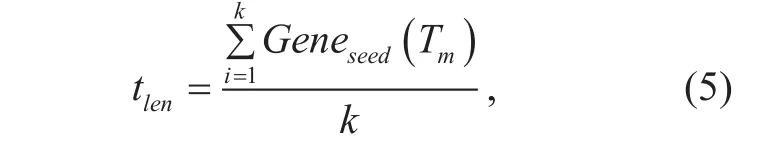
where k is the length of name.
V. CHINESE NAME FPE PROCESS
In order to ensure that the encrypted Chinese name still falls within the legitimate message space, we use the name library to limit the message space of the plaintext and the ciphertext. In addition, for the encryption of the last name and the given name, we can adopt the idea of “encoding-then-encryption” to switch it to the question of integer set FPE. For enhancing the security of the encryption algorithm, we improve the Pre fix algorithm. Speci fically, we design the Cycle-Pre fix algorithm by adding the adjustment factor.
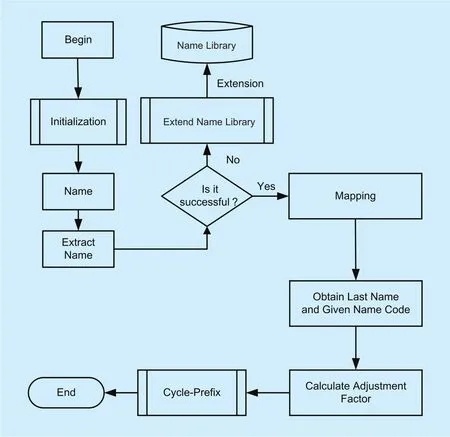
Fig. 4. Flow chart of format-preserving encryption-decryption for the Chinese name.
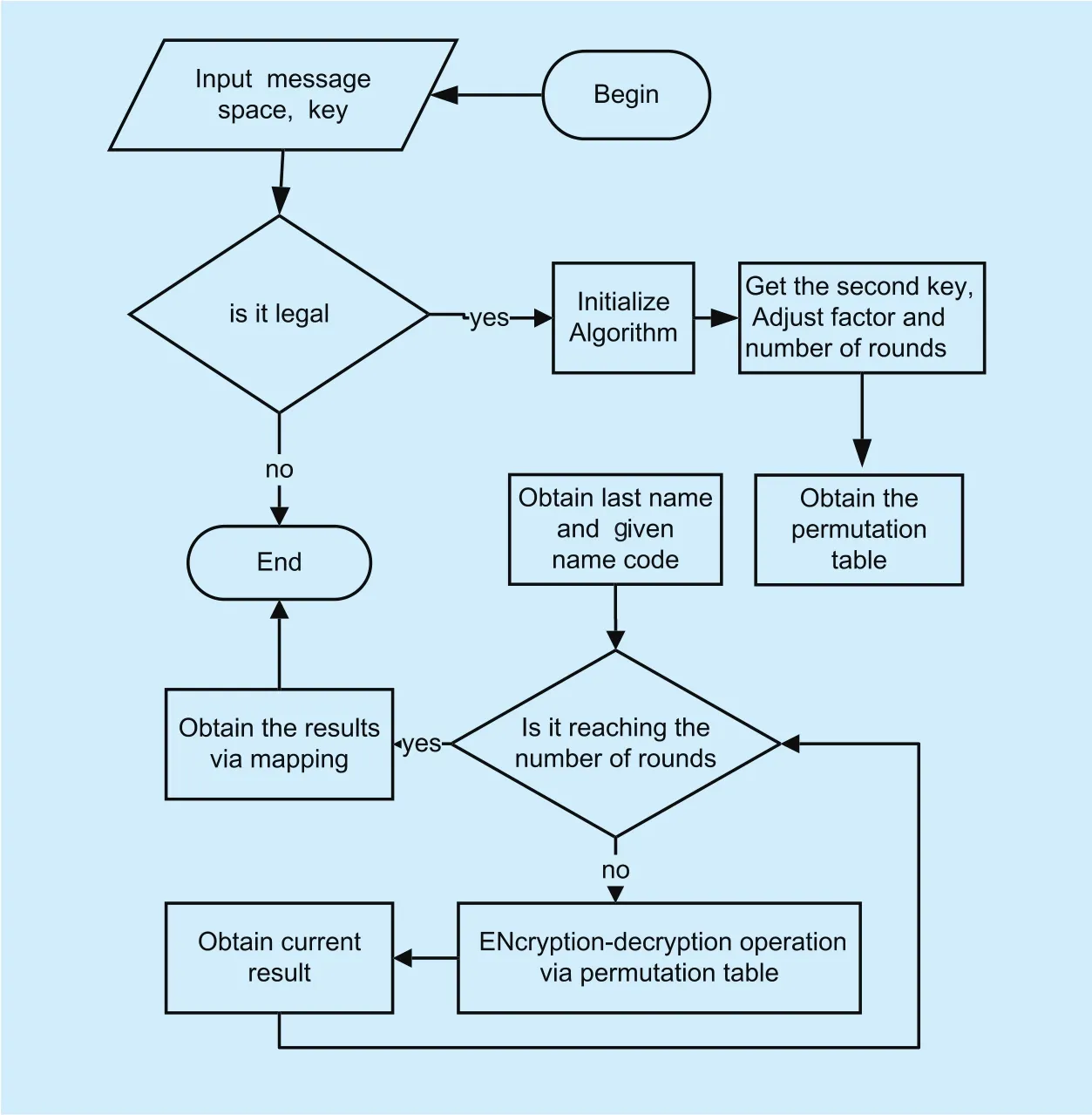
Fig. 5. Cycle-Pre fix algorithm flow chart.
According to the Chinese name FPE model in figure 1, we refine each part of the model to design the process of format-preserving encryption-decryption for the Chinese name,which is shown in figure 4.
It can be seen from the flow chart in figure 4, the algorithm would firstly perform the initialization according to the key, such as initializing the parameters, reading the name library, and generating the permutation table of last surname and given name. Then the name is passed into the name extraction algorithm,which will automatically try to distinguish the last name from the given name and further extract them. If the extraction fails, the name library extension algorithm will be triggered to extend and maintain the name library. Once the last name and given name are extracted successfully, we can build the mapping relationship to obtain the last name code and given name code At last, we calculate the adjustment factor and use the Cycle-Prefix algorithm to encrypt the code of last name and given name.
VI. DESIDN OF CYCLE-PREFIX ALGORITHM
As this model uses the name library to limit the message space, and the size of each library is about 103, the Pre fix algorithm can complete the encryption and decryption operations efficiently and accurately. However, if we only use the Pre fix algorithm alone, the same plaintexts will get the same ciphertexts after encryption. Moreover, Pre fix algorithm depends on the key too much, which makes the less security of this algorithm. In order to solve the above problems, we improve the traditional Pre fix algorithm and propose the Cycle-Pre fix algorithm in this paper.
On the basis of the traditional Prefix algorithm, combined with the idea of circular encryption, we add two adjustment factors to control the round of encryption, which increases the security of algorithm under the premise of retaining the efficiency of encryption. The algorithm flow chart is shown as follows:
It can be seen from figure 5, we firstly verify the legitimacy of the input data. This verification can filter the illegal data to reduce the unnecessary operations, and avoid the interference with the algorithm. After that, it needs to perform the initialization, read the data from the name library and set the basic construction method of encryption. The secondary key, provided by the user, is used as the random seed to generate the adjustment factor. The above adjustment factor is used to generate the round of encryption about given name. Then, on the basis of adjustment factor and given name length, we generate the round of encryption about last name. Moreover, we use the pattern of “encoding-then-encryption” to perform the encryption operation on the last name and given name based on the given rounds. Finally, according to the mapping relationship, we obtain the corresponding cipher text and splice them into the final result.
Based on the adjustment factor, Cycle-Prefix generates the random seed as a secondary key of encryption, which can control the generation of the round times about the encryption-decryption operation on last name and given name. Thus, even if the encryption key is lost, we can guarantee the security of the encryption algorithm. In addition, the algorithm adds the security adjustment factor and the difference adjustment factor. In this case, the security of the algorithm can be enhanced by controlling the round times of each part about the Chinese name FPE.
VII. STRATEGY OF THE CHINESE NAME FPE
The strategy of the Chinese name format-preserving encryption contains five basic algorithms: Init, Extract, Enc, Dec, and Extend.Among them, the initialization algorithm Init is used to initialize the parameter and data required during the encryption-decryption operation. Combined with the name library,name extraction algorithm Extract automatically identify and extract the last name and given name. If the extraction fails, it means that the last name or given name does not exist in the name database. In this case, we need to call the name library maintenance algorithm to expand the name library. The name library maintenance algorithm Extend is used to extend the name library, so that it can meet the current requirements of encryption-decryption operation. The encryption algorithm Enc encrypts the input code of last name and given name, while the decryption algorithm Dec decrypts the input code of last name and given name. The flow chart of the Chinese name format-preserving encryption is shown in figure 6. Next, we will focus on the initialization algorithm, encryption algorithm, and name library maintenance algorithm.
7.1 Initialization algorithm

Algorithm 1: The initialization algorithm init Input: The key, the seed, and the rank rule λ.Output: tsize and the permutation table Table.1. Use the traditional block cipher and key to encrypt the name domain Sn.2. Rank Sn, according to λ to generate the permutation table Table.3. while times > 0 do 4. tsize = Genesize(seed)5. end while
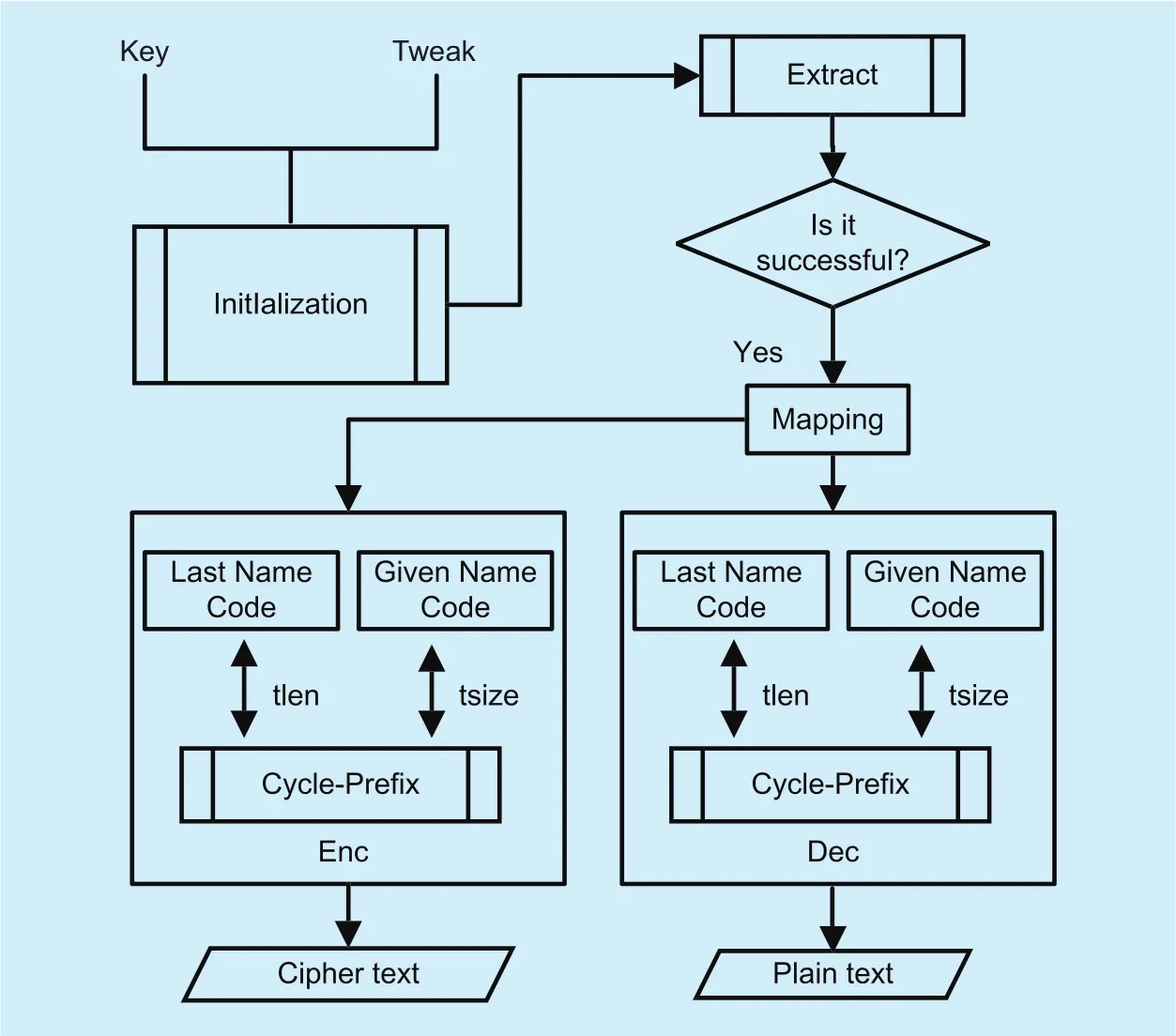
Fig. 6. Chinese name format-preserving encryption scheme.

Algorithm 2: Encryption algorithm enc Input: The name to be encrypted name, tsize, the name library N Output: The ciphertext name name’1. for name ∈ N do 2. (lastName, lastCode, givenName, givenCode)= Extract(name)3. end for 4. while length(givenName) > 0 do 5. tlen + = Genelen(seed)/length(givenName)6. end while 7. while tlen > 0 do 8. lastName’ = Table(lastCode)8. end while 9. while tsize > 0 do 8. givenName’ = Table(givenCode)10. end while 11. name’= lastName’+ givenName’12. return name’
The initialization algorithm Init mainly completes the initialization of the encryption key and the adjustment factor tsize, as well as generates the permutation table Table according to the name library.
The detailed procedures are shown by algorithm 1.
where times refers to the times of circular generation about tsize, and Gene(seed) refers to the random generation algorithm of the adjustment factor.
7.2 The encryption algorithm
The core of the encryption-decryption algorithm is the Cycle-Prefix algorithm. In addition, the Extract algorithm needs to be called to extract the last name and given name before encryption and decryption.
The detailed procedures are shown by algorithm 2.
Speci fically, the encryption algorithm firstly traverses the name library. Then, the last name lastName and given name givenName are extracted from name with the extraction algorithm Extract. The last name code lastCode and given name code givenCode on the integer field are subsequently determined. Based on the givenName, we generate tlenfor the current last name encryption. Then, for lastCode, we perform tlencyclic permutation encryption
to get the encrypted last name lastName’.Moreover, for givenCode, we perform tsizecyclic encryption to get the encrypted given name givenName’. Lastly, we merge the encrypted last name and given name to return name’.
Similar to the encryption algorithm, the decryption algorithm is the inverse of the encryption algorithm. Speci fically, the encryption process maps the plaintext column to the ciphertext column from the permutation table.Different from the encryption algorithm, the decryption process maps the ciphertext column to the plaintext column from the permutation table.
7.3 Maintenance algorithm for name library
In the process of encryption and decryption,we may encounter the last name or given name that is not contained in the name library.Thus, we need to design the name library maintenance algorithm to improve the encryption strategy of the Chinese name format-preserving encryption. The detailed procedures are shown by algorithm 3.
The algorithm first tries to extract the input name, and, in the last name library, uses the idea of longest matching substring to find the most appropriate last name. When the last name extraction algorithm returns NULL, it is necessary to guess the last name. When the length of name is 2 or 3, we divide equally the names into the last name and given name.When the length is 4, considering that there are fewer compound last name and most of the complex compound last names have been included in the last name library, we take the first word as the last name by default. Speci fically, substring(s, j, k) means that we intercept the substring whose subscript are from j to k in the string S. After guessing the last name,it needs to add the last name to the last name library. When confirming the last name, we literally search for the remaining part of name in the given name library to determine whether they exist or not. If they exist, it means the given name has been determined. In this case,we return the determined last name and given name. Otherwise, the word needs to be added to the given name library.
7.4 Security analysis for algorithm
7.4.1 The security analysis about algorithm The cryptography scheme is generally based on the underlying basic module, so the security of the scheme can also be normalized to the security of the basic module [15]. The Chinese name format-preserving encryption is a symmetric cryptography, so all the security objectives of the symmetric cryptography are applicable to it. The format-preserving encryption is essentially a pseudo-random permutation in the speci fied message space, so its security target is PRP security [15]. Based on Cycle-Prefix, the FPE algorithm in this paper has been proved to be PRP security in the existing research [16]. Beyond that it has the security of the traditional FPE algorithm,for the case that the same encrypted plaintext obtains the same ciphertext due to the same key, cycle-Pre fix uses the adjustment factor to deal with the ciphertext. Therefore, the same encrypted last name obtains the different ciphertext, which increases the attack dif ficulty for the cracker.
7.4.2 Security analysis after introducing the name library
The name database is essentially a means of restraining the scope of the message space. After the introduction of the name database, the security target of FPE is still the pseudo-random permutation security in the message space.
Therefore, the introduction of the name database does not reduce the security of the encryption algorithm. In addition, with respect to the common Chinese FPE for coding operation, there is a lot of flexibility in the name database. The encryption result is dependent on the content order of the name database, and the encryption result is different in different order, which also increases the difficulty of cracking.

?
VIII. EXPERIMENT AND ANALYSIS
In this experiment, our experimental scheme is performing the format-preserving encryption on the Chinese name.
The Chinese name is the experimental object. The program is implemented in Java language. The system environment is Windows7 and the version of JDK is 1.7. The underlying encryption algorithm adopts the AES algorithm. The length of key is 128 bits, and the key is obtained by the MD5. The experiments firstly verify the expansion of the name database and give the performance about the encryption and decryption on the same last name. Then, we compare the algorithm proposed in this paper with the traditional Pre fix algorithm on the efficiency and effect of encryption-decryption operation.

Fig. 7. Name library extension.

Fig. 8. Chinese name encryption and decryption.
8.1 Veri fication of feasibility
In the process of encryption and decryption, if the last name or given name does not exist in the name library, the system will call the name library maintenance algorithm to add the new last name or given name into the name library.As shown in figure 7, the system find the new last name “Pang” and new given name “Juan”,so the system add them into the name library.If the new last name or given name appears many times, such as “Pang Yuyang” and “Pang Juan” shown in figure 7, the system will automatically filter them to avoid the repeated addition.
As shown in figure 8, the system can guarantee the ciphertext accords with the naming habits of Chinese name after encrypting them.In addition, the system deals with the name which has the same last name but different length, so that the ciphertext of encrypted last name is different. For example, the “Pang Yuyang” and “Pang Juan” were encrypted into“Year River” and “Cen dance” respectively, as shown in the figure below.
8.2 Comparison between Cycle-Pre fix algorithm and traditional Pre fix algorithm
In this paper, we firstly propose a format-preserving encryption algorithm for the Chinese name. As illustrated in figure 9, set tsizeand tlenin Cycle-Pre fix as 1, then the efficiency of combining the name database is higher than the traditional Prefix algorithm. However,at this time, the ciphertexts are same after encrypting the same plaintexts. Meanwhile,they all have high dependence on the key. If tsizeand tlenare less than 50, the efficiency of Cycle-Pre fix algorithm is still higher than the traditional Pre fix algorithm, and Cycle-Pre fix algorithm greatly improves the usability of the encrypted name. That is to say, the ciphertext of the same plaintext is different, which improves the security of the algorithm. When tsizeand tlenare equal to or greater than 50, the efficiency of the algorithm will be reduced. In this paper, we use the random generation algorithm to limit tsizeand tlenat about 40, so that the encryption algorithm can not only achieve the high efficiency but also provide the good security.
Combined with the name database, Cycle-Prefix algorithm encrypts the Chinese name. The vast majority of ciphertexts are consistent with the naming convention of the Chinese name. As illustrated in figure 10, the available proportion of encrypted name can reach to 95%. However, only less than 5% of the ciphertext, which is encrypted with the traditional Pre fix algorithm, can be used.
IX. CONCLUSIONS AND FUTURE WORK
In this paper, we study the format-preserving encryption of the Chinese name. In view of the shortcomings about the traditional Chinese FPE method, we propose the scheme of extending the name database and the Cycle-Prefix algorithm. The encrypted name is still in accordance with the Chinese name naming rule. At the same time, this algorithm processes the encryption result of the same last name,which enhances the security and dynamics of the algorithm. In the future, we will study the efficiency of the algorithm as well as the compatibility for various names.
ACKNOWLEDGEMENT
This work is supported by the National Natural Science Foundation of China under Grant (No. 61772085), (No. 61672109), (No.1472024) and. (No. 61532012).
[1] K. Mallaiah, S. Ramachandram, and S. Gorantala, “Performance analysis of format preserving encryption ( fips pubs 74-8) over block ciphers for numeric data,” in 2013 4th International Conference on Computer and Communication Technology (ICCCT), 2013, pp. 193–198.
[2] Z. Liu, C. Jia, J. Li, and X. Cheng, “Format-preserving encryption for datetime,” in 2010 IEEE International Conference on Intelligent Computing and Intelligent Systems (ICIS), 2010, pp.201–205.
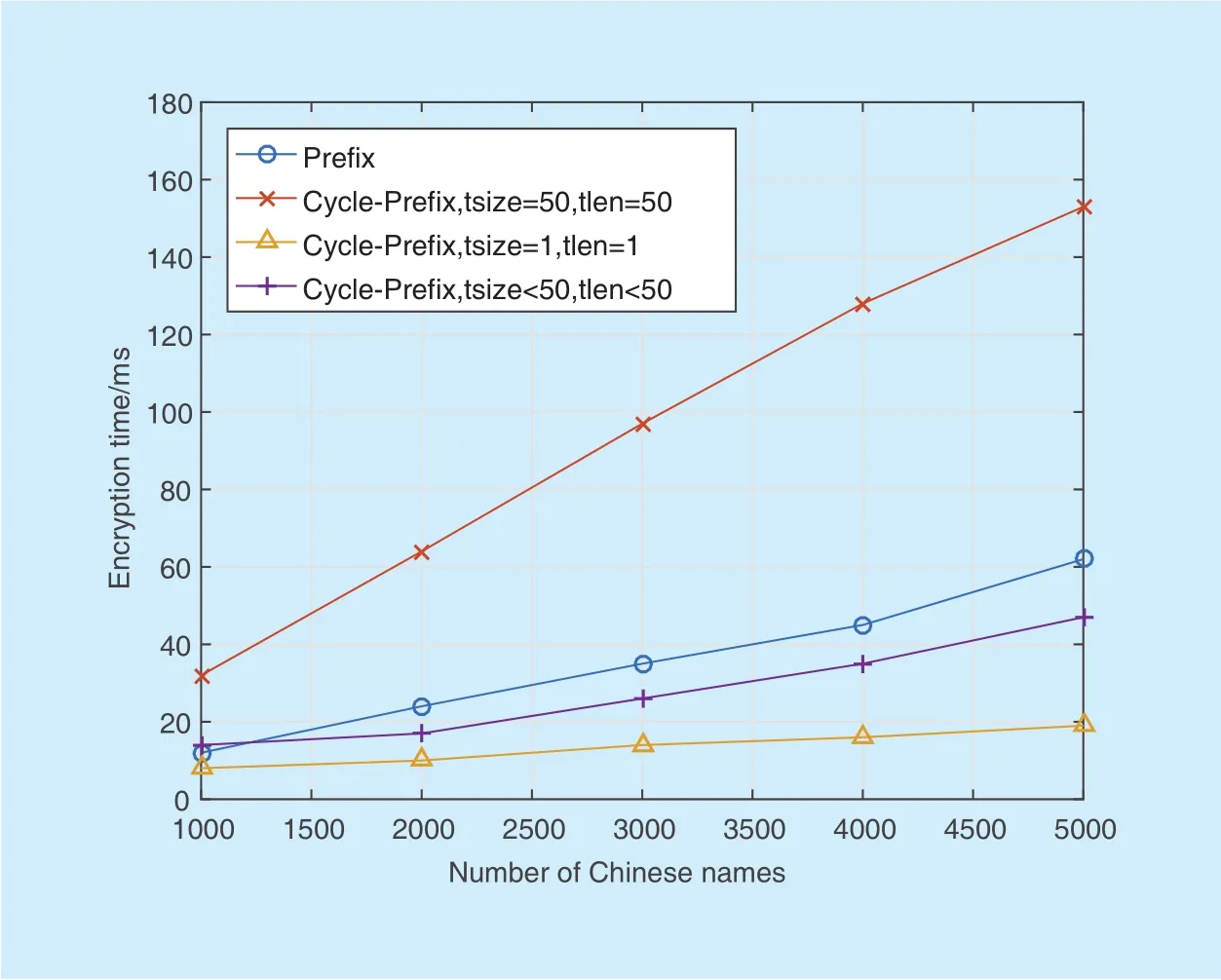
Fig. 9. Efficiency comparison of two algorithms.
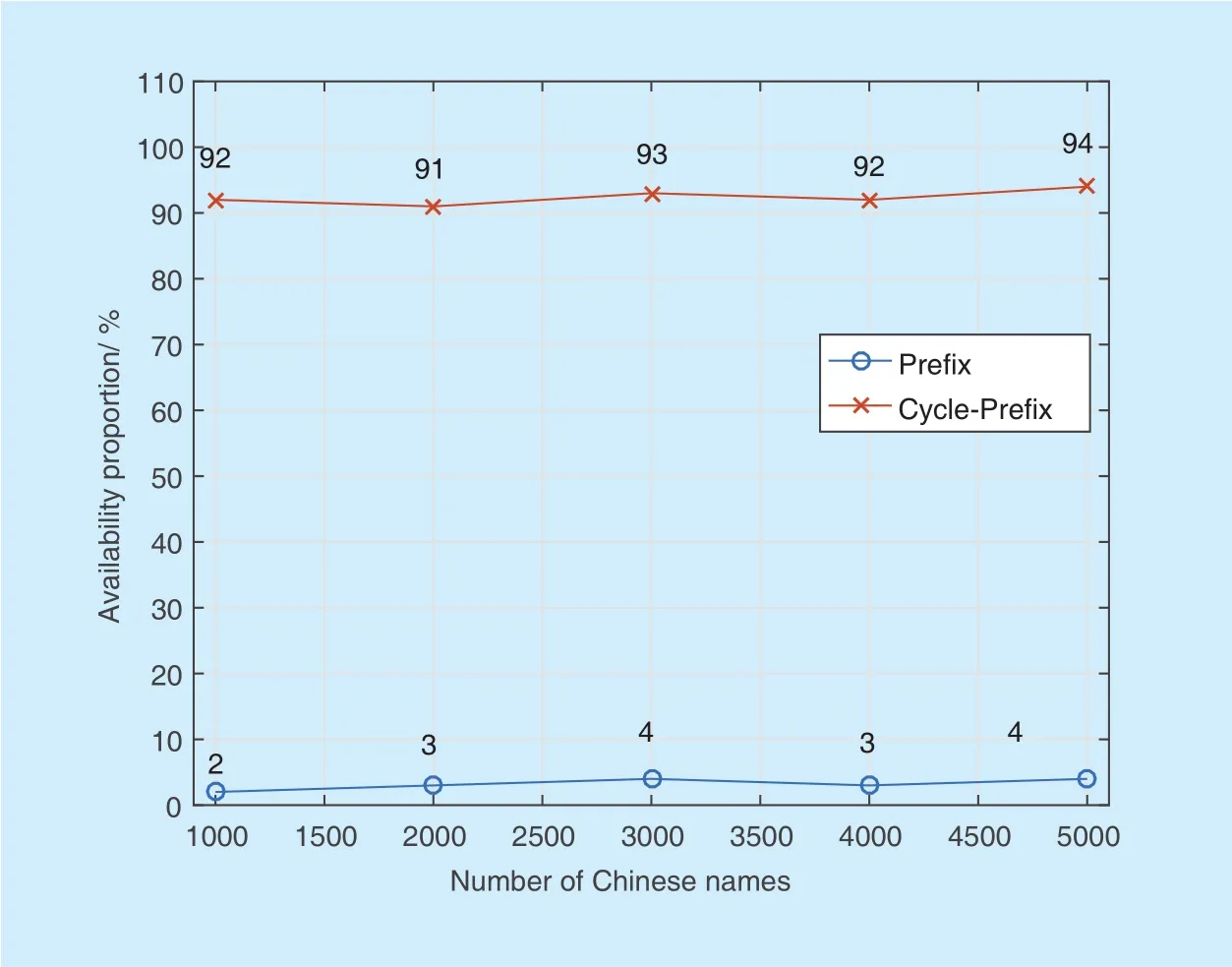
Fig. 10. Available proportion of encrypted name in two algorithms.
[3] Z. Liu, C. Jia, and J. Li, “Research on the format-preserving encryption techniques,” Journal of Software, vol. 23, no. 1, 2012, pp. 152–170.
[4] M. Baldridge and E. Ambler, “Guidelines for implementing and usingthe nbs data encryption standard,” Guidelines for Implementing and Using the Nbs Data Encryption Standard, 1995.
[5] M. Brightwell and H. Smith, “Using datatype-preserving encryption to enhance data warehouse security,” in the 20th National Infor-mation Systems Security Conference, 1997, pp.142–148.
[6] J. Black and P. Rogaway, “Ciphers with arbitrary finite domains,” Topics in Cryptology ł CT-RSA 2002, vol. 2271, no. 2001, 2002, pp. 114–130.
[7] T. Spies, “Feistel finite set encryption mode,” in http://csrc.nist.gov/groups/ST/toolkit/BCM/documents/proposedmodes/ffsem/ffsemspec. pdf,2008, pp. 1–10.
[8] M. Luby and C. Rackoff, “How to construct pseudo-random permutations from pseudo-random functions,” Siam Journal on Computing, vol. 17, no. 2, 1988, pp. 373–386.
[9] M. Bellare, T. Ristenpart, P. Rogaway, and T. Stegers, “Formatpreserving encryption,” Selected Areas in Cryptography, vol. 45, no. 5, 2009, pp.295–312.
[10] M. Bellare and P. Rogaway, “The ffx mode of operation for formatpreserving encryption,”Unpublished Nist Proposal, vol. 136, no. 9, 2010,pp.1–18.
[11] M. Liskov, R. Rivest, and D. Wagner, “Tweakable block ciphers,”Advances in Cryptology ł CRYPTO 2002, vol. 24, no. 3, 2002, pp. 31–46.
[12] T. Tz and A. Uhl, “Efficient format-compliant encryption of regular languages: block-based cycle-walking,” in 11th IFIP TC 6/TC 11 international conference on Communications and Multimedia Security, 2010, pp. 81–92.
[13] M. Pauker, T. Spies, and L. Martin, “Data processing systems with format-preserving encryption and decryption engines,” in US: US 7864952 B2., 2011.
[14] P. Rogaway, “A synopsis of format-preserving encryption,” in https://www.voltage.com/resource/independent-technical-assessment-of-voltage-format-preserving-encryption/,2010, pp. 1–18.
[15] Z. Liu, C. Jia, and J. Li, “Research on the format-preserving encryption modes,” JOURNAL ON COMMUNICATIONS, vol. 32, no. 6, 2011, pp.184–190.
[16] E. Brier, T. Peyrin, and J. Stern, “Bps:a format-preserving encryption proposal,” in http://csrc.nist.gov/groups/ST/toolkit /BCM/documents/proposedmodes/bps/bpsspec.pdf, 2010, pp. 1–11.
Biographies

Junwei Zou,lecturer of the School of Electronic Engineering, Beijing University of Posts and Telecommunications,China. His research interests include smart card technology,security technology and Internet of Things.


Hong Luo,is a professor of the School of Computer Science,Beijing University of Posts and Telecommunications, China.She is also a research member of the Beijing Key Lab of Intelligent Telecommunication Software and Multimedia.Her research interests include Internet of Things, smart environments, data service and communication software.

- China Communications的其它文章
- Stochastic Dynamic Modeling of Rain Attenuation: A Survey
- Heuristic Solutions of Virtual Network Embedding: A Survey
- A Survey on Smart Collaborative Identi fier Networks
- Service Function Chain in Small Satellite-Based Software De fined Satellite Networks
- Coordinated Resource Allocation for Satellite-Terrestrial Coexistence Based on Radio Maps
- A Novel Roll Compensation Method for Two-Axis Transportable Satellite Antennas