
基于半监督学习的安卓恶意软件检测及其恶意行为分析
2018-04-02 03:04:42杜炜李剑
信息安全研究 2018年3期
杜 炜 李 剑
(北京邮电大学计算机学院 北京 100876) (duwei0810@gmail.com)
权威市场研究机构Gartner于2017年5月发布了全球智能手机操作系统在2017年第1季度的分布报告[1].从分布报告中可以看出在智能手机的操作系统市场中,安卓智能操作系统比去年的市场份额增长了2%,在第1季度的市场份额已经高达86.1%,成为智能手机中主流的操作系统.而iOS智能操作系统的市场份额比去年的市场份额降低了0.9%,作为拥有第二大市场份额的智能操作系统,其在该季度的市场份额却只有13.7%,离Android智能操作系统的市场份额还有较大的差距.后面,包括Windows Phone在内的其他智能操作系统的市场份额总共为0.2%,占的市场份额很少.
随着安卓操作系统迅速成为市场占有率最高的智能操作系统,安卓软件的数量也迅速增长.最近1份报告显示[2],到2017年9月为止,在Google Play上的安卓软件数量已经达到330万个,并且除了Google Play,还有很多第三方应用商店也提供了安卓软件的下载.由于安卓系统的开放性、开源性及其相对简单的检查机制,使得安卓系统吸引了很多恶意软件开发者,因此安卓成为恶意软件进行恶意行为的一个主要平台.
安卓恶意软件的迅速增长已经对用户造成了很大的威胁,安卓恶意软件最常见的恶意行为主要有以下几种:通过假连接、假按钮和假提示来诱导用户下载恶意软件;通过向付费号码发送短信进行恶意扣费;偷盗敏感信息并发送到远程服务等等,这些恶意行为会直接或间接造成用户的经济损失或隐私泄露.并且自2012年以来,安卓恶意软件的数量从几十万跨越到几百万,这表明安卓恶意软件总体已经进入了平稳高发期,这就使得安卓恶意软件的检测成为一项迫在眉睫的工作.为了应对日益严重的安卓信息安全威胁,本文提出了一种基于半监督学习的安卓恶意软件检测及其恶意行为分析的研究方案,提高了恶意软件检测的精确率.
1 相关工作
目前,商业的杀毒产品通常都是采用传统的基于签名的检测技术,通常是从软件中提取二进制模式或者随机片段来创建恶意软件签名,将产生的恶意软件签名加入到创建的恶意代码库中,之后使用相同签名的任何应用程序都将被视为该恶意软件的一个样本.基于签名的恶意软件检测技术虽然检测速度快,只要是存入恶意代码库的恶意代码,都能够准确检测出来.但是这种检测方法对于事先未知的威胁是无法检测到的,因为不存在以前生成的签名,并且可以通过对安卓应用程序注入恶意代码来绕过签名验证机制,所以基于签名的检测技术并不具备很好的检测能力.
在过去几年中,国内外研究人员提出了一些处理日益严重的安卓恶意软件的分析方法和检测手段,按照方法可以将其分为静态分析和动态分析.
静态分析是一种通过分析代码段来检测恶意软件的分析技术,是在安卓软件不运行的状态下,将安卓APK进行反汇编处理以后对代码进行规则匹配及分析,这种情况下只会产生很小的开销.Liang等人[3]提出了一个基于权限组合的安卓恶意软件检测方案,开发了k-map工具来获得恶意软件经常请求的权限组合,并根据权限组合自动生成规则集来进行检测;Idrees等人[4]提出了一种通过分析安卓应用程序的权限和意图组合特征来检测恶意软件的方法,这种方法辅以机器学习算法进一步对应用程序进行分类;Wu等人[5]提出了DroidMat检测工具,从AndroidManifest.xml文件中提取权限信息、组件信息以及API信息作为安卓软件的特征,采用分类算法对待检测的软件进行分类,得到该软件是良性软件还是恶意软件;Sanz等人[6]提出了一个名为PUMA的安卓恶意软件检测方案,该方案基于权限信息对安卓软件进行分类.
与静态分析相反,动态分析是一种通过在真实环境中执行安卓软件来对恶意软件进行评估的检测技术,可以在安卓软件运行时动态监测行为,实时捕获敏感行为并进行分析.BlaäSing等人[7]提出了一个名为AASandbox的动态检测工具,在一个完全隔离的环境中执行安卓软件,通过分析执行期间获得的低级别交互日志来进行安卓恶意软件检测,这是一种较早使用动态分析方法来进行恶意软件检测的;Narudin等人[8]提出了一种利用机器学习方法评估各种网络流量特征的恶意软件检测的解决方案;Shabtai等人[9]提出了一个名为Andromaly的检测安卓恶意软件的框架,持续不断地监控从移动设备获得的各种特征和事件,然后应用机器学习将收集的数据分类为良性软件或恶意软件.尽管这些动态检测在识别恶意行为上相当有效,但需要花费大量的环境搭建成本和人力分析成本.此外,对于条件触发式的安卓恶意软件,动态分析也束手无策.
2 实验过程
2.1 数据集分析
本文从高校实验室、研究机构以及安全公司获得了48 143个安卓软件并作为数据集,随后使用VirusTotal[10]为每个安卓软件标注.因此我们统计了每个安卓软件是否属于恶意软件以及其恶意软件家族信息,得到了590种不同的恶意软件家族的信息.
我们根据这590种恶意软件家族出现的频率,列出其常见的20种恶意软件家族,如表1所示.尽管安卓恶意软件家族体现了安卓恶意软件的恶意行为,但是,不同的恶意软件家族很可能具有相似甚至完全相同的恶意行为,因此我们通过人工分析以及聚类等方法将具有相同恶意行为的恶意软件家族合并,并为每个安卓恶意软件产生最终恶意行为标签.但是,想得到590种恶意软件家族具体的恶意行为是需要花费巨大人力的,甚至是达不到的,因此,我们只针对表1中最常见的20种恶意软件家族进行分析.但是剩下未标注的数据并未因此丢弃,而是通过半监督学习的方式作用在模型上.

表1 最常见的20种恶意软件家族
2.2 特征提取
特征的提取也要分为静态分析和动态分析,静态分析主要从安卓软件的代码发掘与恶意行为相关的特征,称之为静态特征.而动态分析主要通过在真实环境(虚拟机)中执行安卓软件,同时动态监控其运行时的行为,抓取一些与恶意行为相关的动态特征.而本节我们同时提取了静态特征和动态特征作为训练的输入.
2.2.1静态特征提取
静态分析需要从代码中发掘,而我们的样本是编译后的二进制文件,因此,第1步是将安卓软件进行反编译.我们使用了工具APKTool.APKTool是一系列工具的集合,它的功能包括APK文件的解包和打包、AXML的编码与解码、资源文件的解包和打包、smali文件的汇编与反汇编、smali文件的调试等.经过APKTool工具进行反汇编后,每个APK文件会得到一个如图1所示的文件结构:

图1 反编译后的文件目录结构
从AndroidManifest文件中提取了142种权限特征和65种服务特征,从smali文件中提取了36种敏感API特征.
2.2.2动态特征提取
安卓软件样本的动态行为是使用DroidBox工具来进行监控的,DroidBox可以查找某些调试消息,收集与被监控的应用程序相关的任何信息并生成json格式的日志,该日志中包含了应用程序运行后发生的动态行为.它包含以下重要信息,来确定该安卓软件的危险性.
1) 网络通信数据;
2) 文件读写操作;
3) 网络通信,文件读写的信息泄露;
4) 权限漏洞;
5) SMS短信;
6) 调用Android API进行加密操作;
7) 拨打电话.
如上所述,我们使用这7种敏感的动态行为作为动态特征.
2.2.3编码
最后,本实验提取了142种权限、65种服务和36种敏感API以及7种敏感动态特征,共250种特征.而这250种特征均属于类别特征(categorical feature),即存在或不存在2种类别,而不是连续值.我们使用独热编码(one-hot encoding)将其编码为特征向量.独热编码又称一位有效编码,主要使用了N位0-1状态表示每个特征的N个取值.由于我们的特征均是二值特征,因此使用250维度的0-1向量即可将特征编码为特征向量,其中每一维度表示一种特征,1表示该特征存在,0表示不存在.
2.3 恶意行为标注
对安卓恶意软件检测的研究已经日益成熟,但是在之前的研究中绝大部分只是将安卓软件识别为恶意软件或者是良性软件2种,而在本文的研究中,不仅只想将安卓恶意软件识别出来,并且想对安卓恶意软件的恶意行为进行分析.安卓恶意软件家族信息可以反映出安卓软件的恶意行为,首先通过工具可以得到每一个恶意软件样本的恶意软件家族信息,然后通过对获得的恶意软件家族进行人工分析和聚类分析,得到了不同的恶意软件行为,对恶意软件样本进行标注.
2.3.1人工分析
首先,对表1中的20种恶意软件家族进行人工分析,可以发现明显有几个恶意软件家族是完全一样的.例如,“Android.Trojan.FakeInst”和“Trojan:AndroidFakeInst”,“Adware:AndroidAdWo”和“Android.Adware.Adwo”,这2对恶意软件家族明显存在着相同的恶意软件行为.继续分析其他的恶意软件家族,最终总结出了3种恶意行为,即SMSSend,Adware和PrivacySteal.3种恶意行为的解释如下.
SMSSend:发送SMS消息或打电话给付费号码.
Adware:为用户提供广告内容.
PrivacySteal:从设备中窃取机密信息.
2.3.2聚类分析
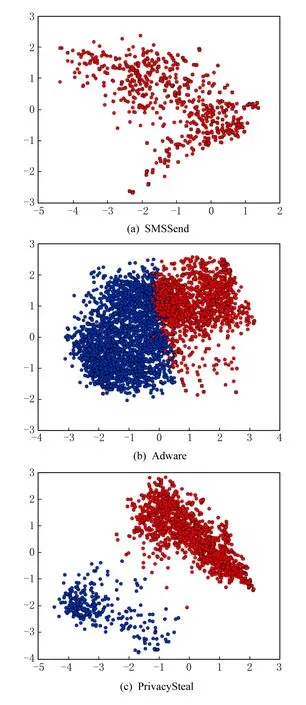
图2 聚类结果示意图
对于安卓恶意软件来说,只将它们分为2.3.1节所列出的3种恶意软件行为太笼统,例如Privacy-Steal,信息窃取可能是盗取安卓设备的设置信息,也可能是盗取用户的地理位置.所以需要对2.3.1节得到的3种恶意行为进行细化,得到更准确的恶意行为分类,但是已经无法从恶意软件家族中获取更多信息.显然,聚类算法[11]很适合用来分析这类问题,通过聚类我们可以分析不同恶意家族的相似程度.对人工分析得到的3个主要类别进行k-means聚类,步骤如下:
1) 首先,构造样本的特征向量,我们使用python-scikit-learn中的k-means训练聚类模型,选择2个或者3个聚类簇.
2) 其次,调整聚类簇的个数k,使得目标函数最大.
3) 最后,使用PCA进行降维处理成2维数据,调用Matplotlib绘图显示聚类结果.
从图2的3个分图分析可知,图2(a)中SMSSend类别没有明显的聚类特性,而图2(b)中Adware类别可以聚类为2个类别,分别命名为Adware.A和Adware.B.同理图2(c)中PrivacySteal也可以聚类为2个类别,分别命名为PrivacySteal.A和PrivacySteal.B.而最终我们将每个类别对应在恶意家族中.
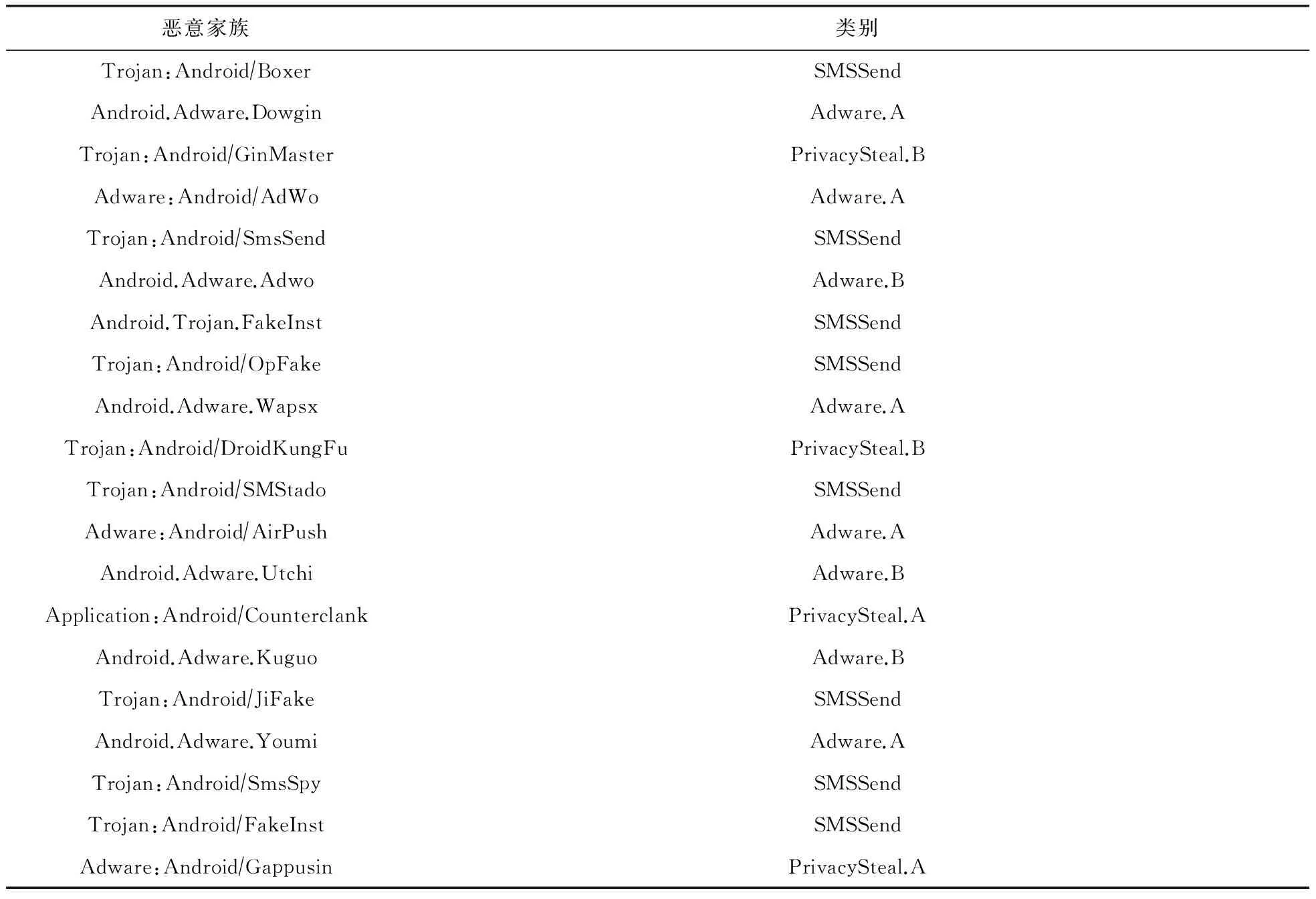
表2 5种恶意行为
最终,经过人工分析和聚类分析2个过程,将安卓恶意软件家族归并为了5种恶意行为,如表2所示,分别为SMSSend,Adware.A,Adware.B,PrivacySteal.A和PrivacySteal.B,再加上良性的安卓软件,故本实验共标注了6个类别.
2.4 算法实现
由于有大量人力无法标注的样本,因此本文提出的Co-RFGBDT算法是一种使用协同训练技术的半监督模型,同时属于混合了随机森林以及梯度提升决策树(gradient boosting decison tree, GBDT)两者优点的一种集成训练模型.
2.4.1半监督学习
监督学习的监督是指给定的训练数据具有标注的标签,一般用于分类或者回归.反之,无监督学习是给定的数据没有标注,一般用来作聚类(例如k-means等)或者生成模型(例如自动编码器、GAN等).而半监督学习主要是如我们的场景一样,人工标注的代价巨大且耗时,而且专业知识也影响着标注的准确率,但是不标注也就没有目标,而仅仅使用已标注的少量数据进行训练得到的模型泛化能力不够.因此,半监督学习就是研究如何在标注少量样本时,利用已标注样本和大量的未标注样本进行充分学习的方法.
2.4.2随机森林和GBDT优劣分析
若将模型的预测值作为随机变量,那么广义的偏差表示该随机变量的均值距离真实值的差异,而方差表示该预测值随机变量的离散程度.若模型的偏差较大意味着预测不准确,若模型的方差较大意味着由于输入变化导致预测的不稳定,一般方差大意味着模型可能存在过拟合.随机森林是一个优化方差,但没有优化偏差的模型,而GBDT是一个优化偏差,但没有优化方差的模型.
对于随机森林,每个模型预测值使用随机变量Xm表示,由于每个训练单元均使用几乎同样的模型,而且随机抽样的样本也存在相似性,我们假设每个训练单元具有相同的均值和方差,分别用μ和σ2表示.于是总模型的均值为
从上式可以看出,随机森林集成后模型的均值和单个模型的均值并不能显著降低模型预测值随机变量的均值,也就不会改变模型预测的偏差.
而如果假设每个训练单元是独立的,那么总模型的方差为
但随机森林每个训练单元是不可能独立的,我们观察另一个极端,即若每个训练单元都是完全相同的,那么总模型的方差为
而对于GBDT,其每棵树的生成依赖于之前训练的决策树,训练单元之间是强相关的,因此其并没有显著降低模型的方差,从而可能出现过拟合.而由于GBDT每次迭代均在最小化损失函数,因此其偏差自然会下降.
而针对GBDT和随机森林的优缺点,结合了随机森林以及梯度提升决策树的优点,本文提出一种名为Co-RFGBDT的半监督学习方法,用于安卓恶意软件检测以及其恶意行为的分析.
2.4.3Co-RFGBDT算法
在安卓恶意行为分析场景中大量标注样本是不现实的,因此本文提出了一种半监督学习算法Co-RFGBDT.我们借鉴了Co-Forest的思想,但区别为Co-Forest使用决策树当作训练单元,而Co-RFGBDT则将一个完整GBDT模型作为训练单元.并且,为了保证不同模型之间的独立性,GBDT的树的深度以及树的个数并不固定,而是服从均匀分布,我们称之为随机GBDT.因此,与传统的随机森林相比,每个训练单元降低了预测的偏差,而所有训练单元用Bagging集成后可以降低预测的方差.除此以外,另一个区别在于输出,输出引入了拒绝机制,即若预测的数据的最多数投票的数量小于置信度阈值时,那么将拒绝预测的输入,在本文具体的场景中,其表示识别到了未知的恶意行为.
我们给出Co-RFGBDT算法的完整描述:假设H*表示所有GBDT模型的集合,共有N个,第i个GBDT模型用hi∈H*表示,Hi表示H*中除了hi之外的所有模型的集合,称之为伴随集合.使用L表示已经标注的数据集合,使用U表示未标注的数据集合.

算法1. Co-RFGBDT.
输入:已标注数据集合L、未标注数据集合U、置信度阈值θ、GBDT模型的数量N.
过程:
1) 训练N个GBDT模型,每个模型的树的深度服从均匀分布U(a1,b1),每个模型的树的个数服从均匀分布U(a2,b2),并且每个模型的训练样本使用Bagging方式从L中放回随机抽样共|L|次.
2) Fori=1 toM:
ei,0=0.5
Wi,0=0
t=0
3) Loop until 所有GBDT模型均不再更改
t=t+1
Fori=1 toN:
ei,t=EstimateError(Hi,L)
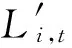
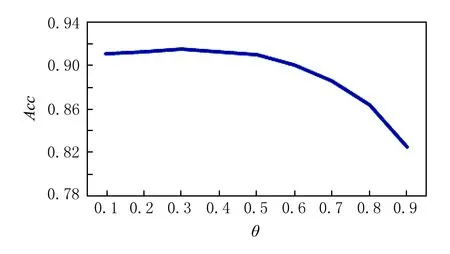
Ifei,t-1 IfConfidence(Hi,xu)>θ Wi,t=Wi,t+Confidence(Hi,xu) Fori=1 toN: Ifei,tWi,t 输出: Ifvotemax≥θelse reject 在最终输出模型中,其中Ihi(x)=y(i)表示模型hi(x)=y的指示函数,votemax表示所有模型中最多数投票的个数,若该个数小于置信度θ,那么则拒绝分类,回到安卓恶意行为分析的场景中.由于我们只标注了部分恶意行为,但是安卓恶意软件的恶意行为层出不穷.因此,采用这种方式,当一次预测中votemax≤θ时,我们认为该安卓软件的恶意行为是未知的. 我们使用多分类的精确率(precision)和召回率(recall)作为评价指标.首先,我们先使用混淆矩阵(confusion matrix)表示多分类模型的预测结果,如表3所示: 表3 混淆矩阵 如表3所示,混淆矩阵的每一行表示实际类别的个数,而每一列表示该类别的预测的个数,那么对于第i个类别,其精确率和召回率为 但由于类别有6个,指标太多会影响模型的比较,因此,我们使用整体指标准确率(accuracy)表示模型整体的优劣,准确率表示分类器所有被正确分类的样本与总样本数的比例,本文使用符号Acc表示. 3.2.1基准实验结果分析 本文将随机森林、GBDT以及Co-Forest这3种基准实验参数调至最优,然后进行对比分析,如表4所示: 表4 2个基准实验和2个比较实验以及Co-RFGBDT的比较 由表4可以看出,随机森林在大多类别上的精确率要比GBDT高,而GBDT在大多类别的召回率较高,但总体来看效果相当. 而对于Co-Forest和Co-RFGBDT算法,均符合我们的预期.当使用了半监督学习后,使用了更多未标注的恶意家族样本参与到训练,学习到了更广泛数据的分布,可以得到更好的效果. 对于本文中提出的Co-RFGBDT算法,由于其针对Co-Forest作了改进,使用了GBDT代替决策树作为训练单元,在一定程度上避免了偏差出现的可能性,而且通过Bagging以及每个GBDT分类器的生成随机性,保证了不同分类器的差异,从而足够降低了方差.其总体Acc相对于基准算法提升了0.015,获得了最优的效果. 但是从表4可以看出,由于Co-RFGBDT使用了机器学习中拒绝分类的方式(根据置信度阈值θ),以当前参数0.3为例,若某预测样本通过分类器获得的最多投票比例不超过0.3,那么我们认为该样本的恶意行为是未知的.但设置一个完美的θ是很难的,从Co-RFGBDT的结果也可以看出,精确率相对较高,但是召回率相对较低.接下来我们详细分析参数θ对于精确率和召回率的影响. 3.2.2置信度θ结果分析 Co-RFGBDT分类的效果与很多参数相关,其中置信度阈值θ是一个比较重要的参数.θ不仅控制了未标注样本的召回阈值,还控制着确定恶意行为是否属于未知恶意行为.从理论上来讲,θ值设置得越高那么预测的置信度就越高,精确率就会越高,但相应的召回率就会降低.我们将设置θ从0.1到0.9,间隔为0.1. 如图3所示,随着θ从0缓慢的增加,Acc会跟着缓慢的上升,但当θ>0.6以后,Acc会因为召回率的急剧下降而下降.因此最终我们选择θ=0.3作为最终的置信度阈值参数.而此时Acc值为0.915 609. 图3 Acc折线图 在本文中,提取了安卓软件的权限、服务和敏感API这3种静态特征,并提取了7种动态特征弥补了只使用静态特征不充分的问题.在静态特征中,主要通过反编译安卓软件,并从中提取特征.而动态特征则是使用DroidBox工具提取了安卓软件运行时的json日志,从中获得了动态行为特征.对安卓恶意软件的恶意行为分析是通过多分类来完成的,首先通过VirusTotal工具获得了每个安卓恶意样本的恶意软件家族信息,然后通过对这些恶意软件家族进行人工分析和聚类分析,将恶意行为分为5类,并对恶意样本进行标注.使用半监督学习方法Co-RFGBDT将少量的已标注样本和大量的未标注样本进行机器学习训练,并进行实验评估,并与随机森林、GBDT以及Co-Forest作了对比,并分析结果出现的原因.最终证明了本文提出的安卓恶意检测及其恶意行为分析方案具有较高的准确率和召回率,而且证明了本文提出的Co-RFGBDT半监督学习算法在一些场景下具有更好的性能. [1]Egham U K. Gartner says worldwide sales of smartphones grew 9 percent in first quarter of 2017[OL]. [2018-01-05]. https:www.gartner.comnewsroomid3725117 [2]Google Play. Number of available applications in the Google Play Store from December 2009 to September 2017 [OL]. [2018-01-05]. https:www.statista.comstatistics266210number-of-available-applications-in-the-google-play-store [3]Liang S, Du X. Permission-combination-based scheme for android mobile malware detection[C]Proc of 2014 IEEE Int Conf on Communications (ICC). Piscataway, NJ: IEEE, 2014: 2301-2306 [4]Idrees F, Rajarajan M. Investigating the android intents and permissions for malware detection[C]Proc of the 10th Int Conf on Wireless and Mobile Computing, Networking and Communications (WiMob). Piscataway, NJ: IEEE, 2014: 354-358 [5]Wu D J, Mao C H, Wei T E, et al. Droidmat: Android malware detection through manifest and API calls tracing[C]Proc of the 7th Asia Joint Conf on Information Security (Asia JCIS). Piscataway, NJ: IEEE, 2012: 62-69 [6]Sanz B, Santos I, Laorden C, et al. Puma: Permission usage to detect malware in android[C]Proc of Int Joint Conf CISIS’12-ICEUTE’12-SOCO’12 Special Sessions. Berlin: Springer, 2013: 289-298 [7]BlaäSing T, Batyuk L, Schmidt A D, et al. An Android application sandbox system for suspicious software detection[C]Proc of Int Conf on Malicious and Unwanted Software. Piscataway, NJ: IEEE, 2010: 55-62 [8]Narudin F A, Feizollah A, Anuar N B, et al. Evaluation of machine learning classifiers for mobile malware detection[J]. Soft Computing, 2014, 20(1): 1-15 [9]Shabtai A, Kanonov U, Elovici Y, et al. “Andromaly”: A behavioral malware detection framework for android devices[J]. Journal of Intelligent Information Systems, 2012, 38(1): 161-190 [10]Total V. VirusTotal-Free online virus, malware and URL scanner[OL]. [2018-01-05]. https:www. virustotal. comen [11]Amorim R C, Mirkin B. Minkowski metric, feature weighting and anomalous cluster initialisation in K-means clustering[J]. Pattern Recognition, 2012, 45 (3): 1061-1075 杜炜 硕士研究生,主要研究方向为信息安全、机器学习. duwei0810@gmail.com 李剑 博士,教授,博士生导师,主要研究方向为智能网络安全、量子密码学. lijian@bupt.edu.cn
3 实验结果及分析
3.1 评价标注


3.2 结果对比

4 总 结

 猜你喜欢
小哥白尼(军事科学)(2019年9期)2019-12-21 02:09:34少年文艺·开心阅读作文(2019年8期)2019-09-12 03:22:24电影(2019年3期)2019-04-04 11:57:18阅读(低年级)(2018年11期)2018-05-14 09:37:53电子测试(2017年15期)2017-12-18 07:19:27少儿科学周刊·少年版(2017年3期)2017-06-29 14:01:15信息安全研究(2016年4期)2016-12-01 06:06:58智能系统学报(2015年4期)2015-12-27 09:38:39电子设计工程(2015年6期)2015-02-27 12:04:53中国教育网络(2014年10期)2014-03-18 01:27:31
猜你喜欢
小哥白尼(军事科学)(2019年9期)2019-12-21 02:09:34少年文艺·开心阅读作文(2019年8期)2019-09-12 03:22:24电影(2019年3期)2019-04-04 11:57:18阅读(低年级)(2018年11期)2018-05-14 09:37:53电子测试(2017年15期)2017-12-18 07:19:27少儿科学周刊·少年版(2017年3期)2017-06-29 14:01:15信息安全研究(2016年4期)2016-12-01 06:06:58智能系统学报(2015年4期)2015-12-27 09:38:39电子设计工程(2015年6期)2015-02-27 12:04:53中国教育网络(2014年10期)2014-03-18 01:27:31
