
基于matlab的文本处理系统的设计与实现
2018-03-29 04:34费扬杜庆治
软件 2017年8期
费扬 杜庆治

摘要:为了进行关键词的文本查重和文本检索,设计出基于matlab的文本处理系统。首先,研究文本处理系统的相关原理及技术;其次,设计系统的总体框架,细化功能;最后,采用matlab语言来设计系统,利用多个TXT文本构建语料数据库,设计出基于matlab的文本处理系统应用程序。测试表明:该系统能有效地实现文本查重和文本检索。
关键词:MATLAB;文本处理;文本查重;文本检索;TF-IDF
中图分类号:TP319 文献标识码:A DOI:10.3969/j.issn.1003-6970.2017.08.044
本文著录格式:费扬,杜庆治·基于madab的文本处理系统的设计与实现[几軟件,2017,38(8):226-229
引言
随着计算机及网络技术的不断发展,信息技术进入了高速发展时期,信息以电子文档形式呈现在大众面前越来越普遍,而电子文档中文本文档占据重要位置。要想实现在海量的文档中如何快速有效地进行文本信息的查重与检索,需设计出一个针对TXT文档格式的多文档的文本处理系统。信息检索的核心技术是全文检索技术,全文检索是以各种计算机数据诸如文字、声音、图像等为处理对象,提供按照数据资料的内容而不是外在特征来实现的信息检索手段。文本处理系统里的全文检索是现代信息检索技术的一个重要的分支,它极大地提高了从大量纷繁复杂的数据中查找特定信息的效率。文本处理系统能实现对指定目录下的目录或文件的遍历
和检索。完成多文档文本处理系统的设计与开发,为用户提供一个快捷、安全的信息检索渠道。利用matlab设计系统操作简单实用,比其他编程语言更加容易实现数据分析。
1 文本处理原理及相关技术
1.1 文本处理
文本处理系统主要包含文本查重和文本处理两个部分。文本查重顾名思义就是查找关键词在文本中的重复率。文本检索(Text Retrieval)是信息检索的一部分,是指根据文本内容,如关键字、语意等对文本集合进行检索、分类、过滤等。当知道某个关键词在文本中重复率较高时,可以从关键词可以粗略的判断出该文章的类型,对某关键词进行文本检索就可以知道关键词在语料库中所占权重,将包含关键字的文档挑出来作为检索结果呈现给用户[34]。
1.2 TF-IDF
TF-IDF(term frequency-inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF(Term Frequency,词频)是指某个关键词在特定文件中出现的频率。一般情况下,同一个关键词在长文件里会比短文件的词数要高,关键词却与文件大小无关,为了防止偏向长文件情况,需要对词数进行处理,词频就是对词数的归一化,[6_7]计算公式如式(1)所示。
关键词a在某特定文件中出现的次数 (n某特定文件里所有字词的数目IDF(Inverse Document Frequency,逆向文件频率)是一个词语普遍重要性的度量,打个比方说,如果包含某关键词的文档很少,IDF很大,则说明该关键词能很好地将该类文档区分开来,具有很好的类别区分能力。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到。计算公式如式(2)所示。
包含关键词a的文档数
2 系统的设计和实现
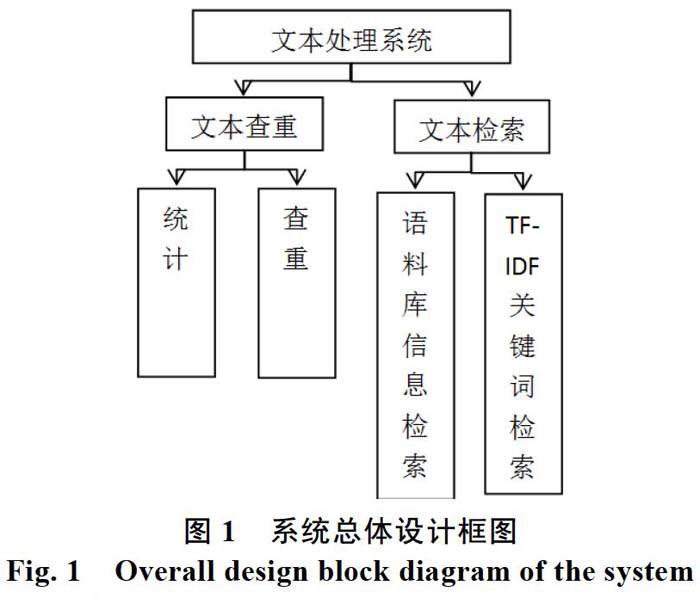
2.1 系统总体功能设计
本系统主要是利用matlab语言来编程实现,最后生成EXE(executable program,EXEFile)可执行程序更加方便使用。开发系统时充分考虑到系统的开发背景和系统目标等信息,使系统设计的更加合理。本系统为了更好地对文本文档进行关键词的查重和权重检索,将系统分为两个部分:一个是文本查重,一个是文本检索。系统的总体设计框图如图1所示。通过该应用程序能很好地实现信息检索,操作简单实用,而且可以在任意电脑运行。
2.2 系统详细设计和实现
2.2.1 系统的主要功能
本系统主要包括两个部分:一个是文本查重,一个是文本检索。文本查重主要是用来统计关键词在文章中出现的重复率,文本检索主要是用来统计关键词在语料库中出现的情况及TF-IDF检索情况。
2.2.2 系统模块的设计
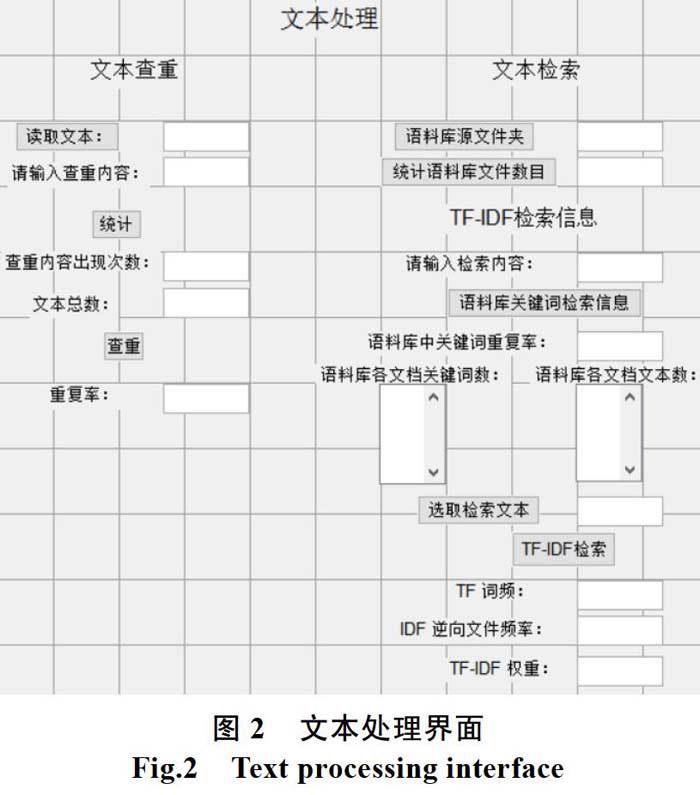
为了直观的看到文本查重和文本检索信息,将两个模块放在同一界面来进行设计,文本处理界面如图2所示。在设计系统时,除了要完全实现该系统的功肯巨外,要考虑到用户使用的便利性,将MATLAB程序输出成EXE应用程序,同时将运行环境嵌套到里面。软件的外观框架结构的设计是基础工作,组成模块是各具应用服务功能和结构特点的,兼容性和合理性是设计模块的基础理论依据。
2.2.3 系统功能的实现
由系统的设计可以知道,系统主要功能模块涉及两个部分:文本查重及文本检索。因各模块设计不同,需要根据相应原理来实现其功能。
(1)文本查重模块的实现文本查重首先需要读取所需查重的文本,然后设定需要查重的关键词,然后点击相应的功能按钮,进行文本关键词信息的统计和查重。文本查重模块利用静态文本来显示文字,这些文字主要用来提示使用者下面进行什么操作。利用可编辑文本、按钮来实现统计和查重等操作。文本信息统计主要是获取关键词在文本中出现的次数和整个文章的文本数。查重就是把关键词数与文章的文本总数相除。
文本查重模块主要利用uigetfile函数读取文本,其功能的代码如下所示:
文本查重模块主要利用strcmp函数来判断是否找到关键词,利用for循环来统计次数,实现统计功能的代码如下所示。
文本查重模块中重复率主要是计算关键词在文档出现的比率,其代码如下所示:set(handles.edit5,String,count/N)
(2)文本检索模块的实现文本检索主要采用的TF-IDF检索方法进行关键词权重检索,文本检索需要有相应的语料库做检索的依据,先统计语料库信息,如语料库文件夹名及文件夹里面的文档数,然后读取检索文本文档,输入关键词进行TF-IDF检索。文本检索模块利用列表框、按钮来实现数据的显示和读取,可编辑文本来显示读取数据的路径和检索内容,最后做TF-IDF检索分析。
统计语料库文档数主要是利用dir和length函数来实现,代码如下所示:
統计关键词在语料库中检索信息,实i其功能主要是利用fopen和fscanf读取文本,for循环来读取全部文本。在读取文本信息时,利用strcmp函数和for循环来统计关键词在各个文本中次数,利用length函数统计各个文本总数。实现其功能的代码如下:
文本处理系统文本检索采用的是TF-IDF检索,将上面公式(1-2)代码化,TF实现和上面查重类似这里不做介绍,主要介绍IDF的实现,IDF的计算需要调用前面关键词在语料库各个文本中检索信息,利用函数eq来判断文本是否包含关键词,没有将其剔除,利用for循环来实现统计包含关键词的文档数,其功能实现代码如下所示。
计算IDF,文档频率IDF=log(语料库的文档总数(包含该词的文档数+1))
2.3 数据库设计
文本处理系统里除了需要一些用于文本查重和检索的TXT文本外,还需要一个由多文本组成的语料库,实际上就是一个由多文本组成的文本数据库。语料库是语料库语言学研究的基础资源,也是经验主义语言研究方法的主要资源。应用于词典编纂,语言教学,传统语言研究,自然语言处理中基于统计或实例的研究等方面。为了便于MATLAB读取语料库,将语料库里面的文档按照1,2,3...来进行编号。MATLAB提供的系统函数fopen和fscanf函数可以读取TXT文本,利用for循环就能将语料库里全部文本读取介绍了文本处理相关原理及技术,设计与实现了基于matlab的文本处理系统。经过电脑测试表明,功能模块运行正常,基本满足功能需求。该系统在文本处理研究领域具有重要价值,给研究者带来巨大的方便,尤其是很容易帮研究者做TF-IDF检索。
