
基于专利数据的大数据技术发展研究
2018-03-29 04:34赵向阳王亮梁晨院
软件 2017年8期
赵向阳 王亮 梁晨院
摘要:全球范围内,运用大数据技术推动经济发展、完善社会治理、提升政府服务和监管能力正成为趋势。因此,对大数据技术进行梳理和分析有着十分重要的现实意义。而专利分析法作为一种常用的分析方法,通过对专利说明书、专利公报中大量零碎的专利信息进行分析、加工、组合,将这些专利信息转化为技术情报,为各方的相关决策提供参考。本文通过对大数据相关技术产业相关发明专利的申请情况、地区分布情况、申请人(权利人)分布情况等的分析,从数据层面清晰反映了大数据技术产业的创新能力、发展状况、发展阶段和发展趋势。
关键词:大数据;专利;技术路线
中图分类号:TP311.13 文献标识码:A DOI:10.3969/j.issn.l003_6970.2017.08.037
概述
大数据不是具体的方法,甚至不算具体的研究学科,而只是对某一类问题、或需处理的数据的描述。通俗地来说,大数据是指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合。根据Gartner公司的定义,大数据是大量、高速、及/或多变的信息资产,它需要新型的处理方式去促成更强的决策能力、洞察力与流程优化能力。而大数据的概念自诞生以来并非一成不变。大数据公认的特征3V是2001年由METAGROUP公司的分析员莱尼提出的,莱尼在一份报告中对大数据提出“3-D数据管理”的看法,即数据成长将朝3个方向发展,分别为数据即时处理的速度(Velocity)、数据格式的多样化(Variety)与数据量的规模(Volume),三者统称为“3V”0后来,随着时间的推移,人们对大数据有了更深入的看法,因此,对大数据的特征进行了相应的调整。2012年,包括IBM、国际调查机构Gartner、IDC等纷纷对大数据提出新的论述,将3V的概念扩展为4V,在原有的基础上增加了数据的真实性(Veracity)。此后,大数据的概念又在4V的基础上增加“Visualize”、“Value”、“Vast”
而扩展为6V甚至7V。随着大数据技术的发展,大数据技术越来越广泛的被应用于社会生活的方方面面,因而通过分析专利信息挖掘,从数据层面反应目前大数据技术和产业的发展状况和趋势具有重要的意义。
1 大数据技术专利分析
1.1 数据采集范围及相关说明
本文的外文数据检索于德温特数据库(DWPI数据库),中文专利数据检索于中国专利文献数据库(CPRSABS数据库),数据采集时间截至2015年12月。利用专业专利分析工具进行数据分析和数据深度挖掘。
同一项发明创造在多个国家申请专利而产生的一组内容相同或基本相同的文件出版物,称为一个专利族。从技术研发角度来看,属于同一专利族的多个专利申请可视为同一项技术。本文中,进行技术分析时对同族专利进行了合并统计,针对国家分布进行分析时各件专利进行了单独统计。
在进行专利申请数量统计时,对于数据库中以一族(这里的“族”指的是同族专利中的“族”)数据的形式出现的一系列专利文献,计算为“1项”。以“项”为单位进行的专利文献量的统计主要出现在外文数据的统计中。
在进行专利申请数量统计时,为了分析申请人在不同国家、地区或组织所提出的专利申请的分布情况,将同族专利申请分开进行统计,所得到的结果对应于申请的件数。1项专利申请可能对应于1件或多件专利申请。
1.2 技术分解
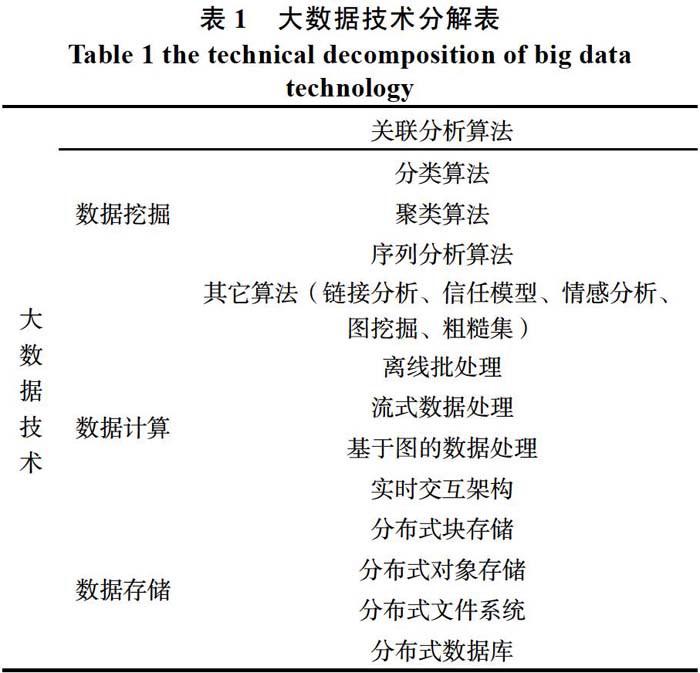
由于大数据涉及的技术种类较多,技术复杂多变,且在教科书以及专利分类体系中均没有现成的大数据的分类体系可供参考。因此,在综合考虑了现有的主流大数据平台架构以及数据处理的流程,對大数据技术进行如表1的技术分解。
1.3 大数据技术专利申请态势
基于上述的技术分解,采用CPRSABS和DWPI数据库进行检索,在上述两个数据库中共检索到专利32120项。
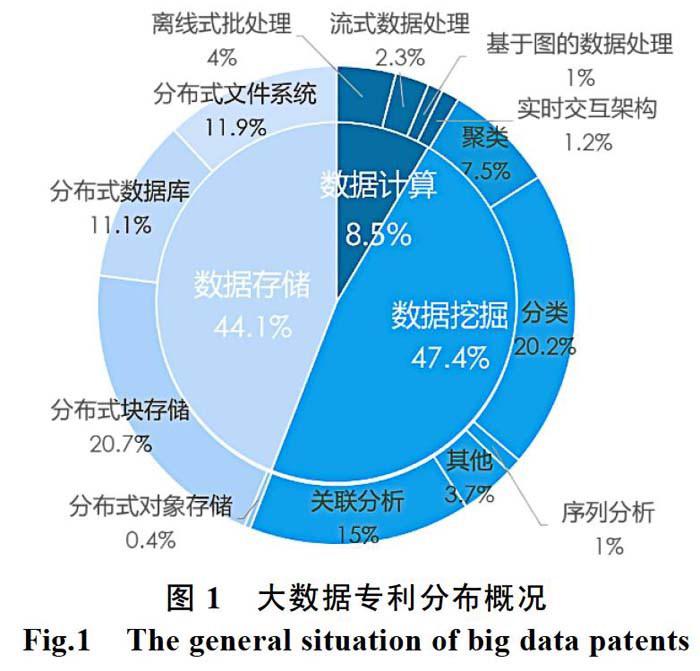
从图2可以看出,大数据领域的专利主要集中于数据挖掘以及数据存储,数据计算的相关专利较少,只占到总申请量的8.5%。数据挖掘专利中主要请集中于聚类算法、分类算法以及关联分析算法。数据存储专利主要集中于分布式块存储、分布式数据库以及分布式文件系统。
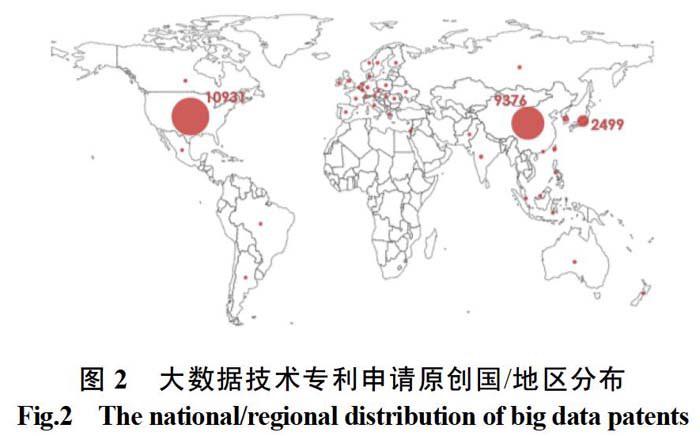
通过统计各项申请的优先权,大数据技术全球范围内专利申请的技术原创国分布如上图所示。优先权所属的国家/地区反映了申请人首次申请所属的国家/地区,折射了专利技术的起源,即专利技术的输出国家/地区,其数量也反映了相应国家/地区在相应领域的技术实力。从图2中可以看出,东亚地区、欧洲地区以及北美地区的主要国家均有申请,由此可见,大数据技术得到了众多科技发达国家的重视。同时,美国和中国的申请量最为庞大,远远多于其他国家,紧随中国及美国之后的是日本、欧洲国家以及韩国。
图3为主要五个国家/地区大数据专利申请的总体情况。横向比较,中国相关专利的年申请量已超过美国、日本、韩国以及欧洲,年申请量超过了1900项。同时,从申请人数量来看,自2000年以来,中国申请人的数量随着专利申请数量的增加增长明显,这显示出中国大数据市场参与者众多,竞争激烈,不断有新的申请人涌现。但是在申请人数量方面,中国与美国还有这较大差距,近两年申请人数量仅为美国的一半左右,这在一定程度上显示出,美国仍然是大数据技术创新的中心。日本与中国不同,虽然申请量也有较大增长,但是其申请人数量一直维持在400人左右,说明日本大数据市场成熟度较高,对大数据技术的投入持续而稳定。同时,可以看到,虽然在08年金融海啸中,各国经济均遭受重仓J,其中美国、日本和欧洲均出现负增长,但是各国在大数据领域投入并未受到影响,无论是申请量还是申请人数量都未降低。可见,大数据领域备受世界各国重视。从技术构成上看,主要五个国家/地区的专利申请主要集中于数据挖掘领域,中国、日本、欧洲、韩国有关数据挖掘的专利申请超过了总申请量的一半。美国以及欧洲在数据存储领域申请量占比较大,这是由于数据存储领域中的大公司绝大多数都是欧美公司,如:IBM、EMC、NETAPP等公司。而中国在数据计算领域的申请量占比较大,这与中国互联网公司的爆发息息相关,诸如阿里巴巴、腾讯等互联网公司对大数据计算技术投入较多。
在专利流向方面,如图4所示,日本公司在美国布局的专利数目最多,紧随其后的是欧洲,而中国申请人在美国申请的大数据专利较少,中国绝大部分的申请人都是仅申请本国专利。这一方面说明中国申请人对本国市场的重视,另一方面说明中国申请人缺乏全球视野,忽视了对全球的专利布局,没有为日后进军全球市场做好充分准备。美国申请的大数据专利主要以欧洲作为目标国,优先对欧洲进行专利布局。在我国布局大数据专利最多的国家是美国,其次是日本,欧洲、韩国相关专利进入中国的较少。
大数据技术专利的主要申请人包括IBM、日立、微软、谷歌、NETAPP、华为等公司。其中,IBM公司的专利申请量最大,是本领域中最为重要的专利申请人。从图5可以看到,LBM的专利分布于大数据领域的各个方面,在所有的领域都有涉及,而分布式块存储以及分布式文件系统是IBM公司申请的重点。日立公司作为日本企业的代表,其在大数据领域的专利布局也很广泛,但相较于微软和谷歌这一类互联网公司,日立在数据计算领域较为薄弱,尤其是谷歌公司,其于2004年首次提出Map Reduce编程模型,开创了大数据计算的新局面。华为公司作为中国申请人的代表,其专利同样集中于分布式文件系统和分布式块存储,在数据挖掘方面申请较少,同时在申请总量上与国外公司还有较大差距。
1.4 大数据技术发展路线
大数据的存储架构可以分为三类,分别是分布式文件系统、分布式块存储与分布式对象存储。由于大数据的来源都为社交网络、电子商务等应用,而第三种架构容易造成大数据访问的瓶颈,因此,如两种作为主流存储,在市场中有很多产品,从最初谷歌开发的GFS[18]发展到HDFS以及后来的Lustre等。此外,为了适应大数据多元化的特点,数据库也从传统的关系型数据库转为N0SQL数据库,例如MongoDB、HBase和SequoiaDB,且NoSQL数据库已应用在诸多新兴互联网公司,其中包括国内的淘宝、百度、360等。
从1980年代的DAS与NAS发展到1990年代的SAN,分布式块存储在2009年迎来重大进展,其中包括著名的Sheepdog和Ceph存储系统。最初的分布式文件系统应用发生在上世纪80年代,极具代表性的NFS和AFS问世。90年代中后期,随着SAN的广泛普及,分布式文件系统进入飞速发展期,出现了多种体系结构,诸如GPFS与XNFS等。到2004年谷歌提出GFS并申请多篇重要专利(如US7065618B2[21]等),标志着新的时代开始,随后基于GFS的HDFS大范围被使用,直至今天仍然是最重要的存储系统。
NoSQL最早出现于1998年,是一个轻量、开源、不提供SQL功能的关系数据库。而在现如今的海量数据和多样化数据类型的环境下,关系型数据库不再是最佳的选择了。2009年再次提出的NoSQL概念,主要指非关系型、分布式、不提供ACID的数据库设计模式。NoSQL最初为NotSQL的缩写,如今已经演变为NotOnlySQL,强调键值和文档数据库的优点,而不是单纯的反对RDBMS(关系型数据库系统)。谷歌首先开发出Bigtable,紧随其后的是Amazon的Dynamo、Facebook的Cassandra以及Microsoft的Azure等,各大厂商也纷纷申请了相应的重要专利(例如微软的压缩键值US8595268B2[22])。NoSQL目前发展为4类:Key-value、Document-Oriented,Column-Family与Graph-Oriented。随后开发商意识到,NoSQL不使用SQL是一个错误,由此便出现了所謂的NewSQL[23]数据库,主流的有VoltDB、NuoDB、Clustrix等。NewSQL是对各种新的可扩展/高性能的关系型数据库的简称,其不仅具有NoSQL对海量数据的存储管理能力,还保持了传统关系型数据库支持ACID和SQL等特性,EMC于2012年申请了无共享架构的专利US8386473B2。
在互联网和大数据应用的冲击下,数据库进入井喷式发展阶段,各式各样的产品迸发而出,局面由过去传统通用数据库(OldSQL)—统天下变成了OldSQL、NoSQL、NewSQL共同支撑多类应用的局面。
由于对于大数据分析实时性的要求逐渐提高,大数据计算架构从早期的离线批处理模式已发展到针对在线数据进行处理的流式数据处理模式以及基于内存计算的处理模式。离线批处理模式的典型代表是由Google公司在2004年提出的MapReduce编程模式(并申请相关专利US8126909B2、US7756919B2与US7650331B2等),主要适用于对静态数据进行批量处理。然而其在数据计算效率方面还需要进一步提升,同时其并不能满足对动态数据的处理。针对上述不足,大数据计算领域相继出现针对在线数据进行处理的流式数据处理模式和实时交互架构,以及针对采用图数据库进行存取的数据而设计的基于图数据的综合处理模式。
在实时性要求较高的应用场景,离线批量数据处理模式便存在诸多不足,由此出现了基于在线动态数据的流式数据处理架构和基于内存计算的处理模式。流式数据处理架构在无需先存储,可以直接进行数据计算,实时性要求很严格,但数据精确度要求稍微宽松的应用场景中具有明显优势,其主要用于对动态产生的数据进行实时计算并及时反馈结果,但往往不要求结果绝对精确。流式数据处理模式最具典型的代表为Twitter的Storm、Yahoo的S4系统与Linkedin的Kafka系统等。尤其是Storm流式计算(重要专利有动态修改数据流的US8286191B2、US8285780B2),在非专利文献库中对其研究和应用非常热门,这不仅和其系统本身相关,更和其开源相关,目前广泛引用于金融银行业、互联网、电子商务、物联网等领域。
基于图数据的处理一直都是计算机领域研究的重点,现今主要的图数据库有Neo4j、Infmite Graph与Trinity等,比较具有代表性的图数据处理系统包括Google的Pregel系统,Neo4j系统和微软的Trinity系统。
基于内存计算的Spark是在HadoopMapReduce的基础上实现,其不再需要读写HDFS,能更好的适用于数据挖掘和机器学习等迭代算法。Spark于2009年诞生,2013年进入高速发展期,随后便成为了Apache的顶级项目,且相应的申请了关于缓存优化的专利CN103631730A。由于支持多种数据源,并具有更多种性能优化技术,到了2015年Spark在国内IT行业变得愈发火爆,大量的公司开始重点部署或者使用Spark来替代MapReduce、Hive、Storm等传统的大数据计算框架。
由于传统的机器学习模型几乎无法支持大规模的数据集,而大多数数据挖掘应用需要实时性,比如:突发事件监测、輿情管理等,因此,对于数据挖掘技术主要面临计算量和精度上的两个问题。关于计算量的问题,可以采用分布式的方式加速运算,在精度上,可以用数据挖掘算法人手,在数据采集时通过采样减少数据规模,在数据模型中采用近似求解方式或采用简单的模型减少计算复杂度,或是通过分布式的架构并行计算。此外,为了在减少复杂度时保证结果准确度,也可以采用多个简单模型进行组合。如图8所示,不管是在分类、聚类、关联分析、时间序列分析、或者其他数据挖掘算法中,传统的算法出现时间较早,但是并不适用于大数据的特点。因此,需要从算法的时间复杂度和计算效率等方面对传统的数据挖掘算法进行改进,如1995年前提出的ID3、C4.5、CART等决策数算法在进行计算时需要多次扫描和排序,效率低,而1996年IBM提出的SLIQ和SPINT算法针对该缺点进行了改进,减少了时间复杂度。总而言之,对于大数据的挖掘算法,需要改进后,方可有实用性,比较成功的案例如:腾讯公司的Peacock改进了LDA模型,以适应百万级别的主题。改进的方式有:基于更复杂的模型、模型的组合以及混合模型。其实,在大数据分析时,由于数据的混杂性和模型,无法完全解决“测不准的问题”,因此,数据挖掘的模型必须具有在线学习和流式学习的能力,一边使用就模型,一遍纳入新的数据进行增量训练,快速更新模型以适应新环境。必须指出的是,大数据不仅有规模的特点,还有多源化的特点,因此,在数据特征不多的前提下往往传统的简单的模型也非常有效,比如常见的流感预测或票房预测,简单的线性回归模型就可以应对的很好。
2 结论
中国在大数据领域起步较晚,但是随着我国互联网、物联网技术的飞速发展,积累丰富的线上和线下数据资源,自2000年以来,在该领域的专利申请数量和专利申请人数量都出现了爆发式的增长,但是在专利申请质量上还有待提尚。从技术构成来看,中国专利申请主要集中于数据挖掘领域,其申请量占到总申请量的接近50%,在申请量最多的数据挖掘领域,排名靠前的申请人多为高校和研究院,这与国外申请人主要集中于企业形成了鲜明的对比,说明我国在该领域的技术大多还处于实验室阶段,急需将这些技术产业化,形成市场化的产品。在大数据存储领域,申请量排名靠前的申请人以企业为主,但是,应该看到,在该领域无论是从专利申请数量还是从专利申请数量上来看,中国的申请人还是远远落后于诸如IBM、EMC、日立这样的国际巨头。
猜你喜欢
水运工程(2022年7期)2022-07-29
传感器世界(2019年4期)2019-06-26
化学分析计量(2013年1期)2013-03-11
轴承(2010年2期)2010-04-04
