
基于全卷积神经网络的人群计数
2018-03-29 03:36陈思秦
电子设计工程 2018年2期
陈思秦
(1.中国科学院上海微系统与信息技术研究所上海200050;2.上海科技大学上海201210;3.中国科学院大学北京100049)
人群计数,顾名思义就是从图像或者视频帧中获得其中总共的人头数目。而人群密度则是人群在一定时间一定空间内的分布情况。准确地估计人群数目和人群密度是衡量一个安防系统好坏的重要指标之一。准确地估计体育馆、地铁站、火车站等关公场所的人群数目可以有效得控制和管理人流量。而这种统计数据在公共安全和交通管制上有着极其重要的作用,可以预防踩踏等一些危险事故的发生。通过分析大型商场的人群密度分布,可以获得顾客的购买喜好和发掘潜在的商业价值。因此,人群计数在现实生活中,特别是在智能监控和安防领域有着广泛的应用价值和社会意义,这也使单张图像和监控视频中的人群计数问题在最近几年受到了越来越多的关注。
但是,在现实场景中,严重的遮挡、光照的变化、视角的扭曲、人群分布不均和复杂的场景背景等干扰因素使人群计数问题变得非常具有挑战性。目前还没有行之有效的人群计数算法可以应用于现实场景中,所以准确、鲁棒的人群计数算法也是计算机视觉领域重要的研究方向之一。
1 基于全卷积神经网络的人群计数
1.1 人群计数
人群计数一直以来都是学术界和工业界的研究热点之一。许多算法已经被提出尝试去解决人群计数问题。通过在视频序列的两个连续帧上扫描检测器来估计行人的数量[1-2]。这种基于检测的人群计数算法,人群是由可以被事先定义好的检测器检测出来的单个实体组成的。但是这种方法的一个缺点是,在人群十分密集或者严重遮挡的情况下,最后的估计准确率往往非常低。
在视频中的人群计数问题[3-4],一些工作已经提出对被跟踪的视觉特征进行轨迹聚类。例如,使用KLT跟踪器和聚类的并行版本,来估计移动的行人数目。概率地将已经跟踪到的图像特征分成若干个可以独立代表移动实体的群集。然而,这种基于跟踪的方法无法用来估计静止图像中的人群。
最广泛使用的人群计数方法是基于特征的回归[5-8]。这种方法的主要步骤是:先从背景中分割出人群,然后从分割出的人群中提取各种特征,如纹理特征,边缘计数或者人群区域面积,最后利用回归函数来估计人群数目。常用的回归模型有脊回归,高斯过程回归等。
还有一些工作专注于静止图像的人群计数。时增林[9]提出了空间金字塔池化网络来解决人群计数问题。Idrees[10]利用多个信息源来估计单张图像在极其密集情况下的人头数。Zhang[11]提出了一种基于卷积神经网络(CNN)的方法来计算不同场景的人群。通过使用类似的训练数据微调预训练网络来测试来自未看见的场景的图像,并在大多数现有数据集上获得了良好的性能。Zhang[12]提出了多列卷积神经网络(MCNN),不同列的卷积神经网络具有不同的感受野,从而能够对不同大小的人头进行响应,取得了现在最好的性能。
但是文献[11]和文献[12]都是使用浅层网络,并且只有2层的池化层,导致网络的感受野比较小,不利于网络对大的人头进行响应。另外,这两种方法在网络优化流程上比较繁琐,文献[11]使用交替优化人群数目和人群密度的网络,文献[12]需要先预训练每列网络,最后再整体微调。本文提出的全卷积神经网络,去掉传统卷积神经网络的全连接层,一方面使得网络的输入分辨率是任意的,另一方面减少了网络的参数。使用了3个池化层,增加了网络的感受野,从而对大人头的输入更加鲁棒。同时,模型优化流程简单,实现了真正意义上的端到端的学习。
1.2 基于密度图的人群计数
给定一张图像I,人群计数问题可以被定义为一个非线性映射F:I→N,N是输入图像I中总共的人头数。然而,对于深度学习来讲,直接从图像回归到一个数字是一个很难的任务。另外,这样做也没有考虑到人群在空间上的分布情况,而像这种分布信息是有助于我们对场景更好的理解。因此,受到Zhang[11]的启发,我们采用卷积神经网络去学习从图像到其密度图的映射,记为D。
定义密度图是一个和原始输入图像相同大小的矩阵。理想情况下,密度图是:对于任意一个在密度图上的像素,如果对应于原始图像上相同位置的像素是属于某个人头区域,则该像素设置值为,Si是对应的人头所占的像素个数之和,否则为0。但是,在实际中,标注图像中所有人头的完整区域是很难的一件事情。因此,对于数据集人头的标注,一般是在人头的中心位置的那个像素设置值为1,其他的像素设置值为0。对于给定的人头中心像素点pi,一张包含N个人头的图像的密度图定义如下:
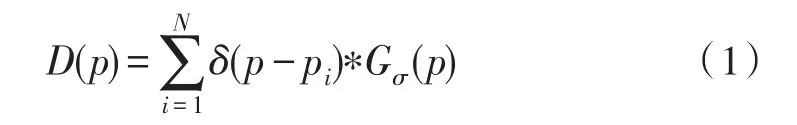
这里的Gσ(p)是一个二维的高斯卷积核,σ是其宽度参数,δ是冲激函数。原始图像和使用上述方法生成的密度图样例如图1和图2所示。

图1 原始图像

图2 生成的密度图
图2中的密度图已经灰度化,图中白色的区域代表像素值较大,即密度值较大的区域。
同时,通过这样高斯卷积生成的密度图之上的所有像素值之和还是和原始的标注图一致。因此,人群计数问题被转化为:先估计得到其对应的密度图,然后把获得的密度图上的每个像素的数值相加得到最终的人头数。
1.3 人群计数的全卷积神经网络模型
最近几年,卷积神经网络在大规模图像和视频识别上取得了最大的成功,这也源于两个重要的因素,大规模公开的数据集,比如ImageNet[13],和高性能的计算系统,像GPUs,大规模分布式集群。同时,卷积神经网络在其他计算机视觉任务、自然语言处理和语音识别等领域也展现出了强大的性能优势。卷积神经网络通过不断堆叠卷积层、池化层和非线性激活函数层,利用参数共享机制大大减少了模型的复杂度。它能够自动抽取不同层次的语义特征,去除了传统的人工设计特征,实现了端到端的训练。
但是经典的卷积神经网络由于有全连接层的存在,比如:经典的AlexNet[14]使用了5个卷积层和3个全连接层。全连接层的引入会导致模型的输入图像的尺寸是事先定义好的,而且模型的主要学习参数来自于全连接层。
Long[15]首先提出了基于全卷积神经网络(FCN)用于图像分割,将图像级别的分类进一步扩展到像素级别的分类。全卷积神经网络不再有全连接层,输入图像的大小可以是任意的,同时可以大大减少参数数量。
文中受到Long[15]工作的启发,将全卷积神经网络应用于人群计数问题,使用其来学习从图像到其密度图的非线性映射关系。具体的模型如图3所示。
人群计数的全卷积神经网络的模型一共有6个卷积层,表示为Conv1-Conv6。这里每个层右边的数字表示该层的输出通道数,箭头左边的数字为卷积核的大小。全卷积神经网络要学习的参数主要来自于每个卷积层的卷积核,这里采用小通道数,减少网络参数,降低模型复杂度。为了保证模型的非线性,每个卷积层之后都跟着一个非线性激活函数层,这里使用的是修正线性单元(Rectified linear units,ReLU),ReLU可以加速网络的收敛[14]。Conv1-Conv3之后都有一个核大小为2x2,步长为2的最大池化层(max pooling)。引入池化层有助于降低中间特征图的维度,节约计算资源。同时,有利于学习到更加鲁棒,具有判别性的特征表示。在模型的最后,采用1x1的卷积层,将之前的特征图映射到密度图。
为了进行有监督的训练,采用欧几里得距离来度量标注密度图和网络预测得到的密度图之间的距离。网络的损失函数定义如下:
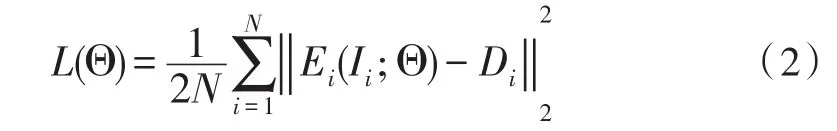
这里Θ是全卷积神经网络要学习的参数。Ii是在训练集上第i张训练图像,N是训练集的图像数目。Di是标注的密度图,Ei是全卷积神经网络预测得到的密度图。L(Θ)是计算标注的密度图和预测的密度图之间的欧几里得距离得到的损失。
在真实的场景中,人头的大小一般都很大,由于这些人靠近照相机,这就使得在设计网络的时候感受野不能太小。所以在这里使用了3个池化层。虽然池化层的增加会使最后的预测的密度图的分辨率降低,但是这样增加了网络的感受野,有利于网络对大的人头进行响应,学习到更加具有语义的特征表示。
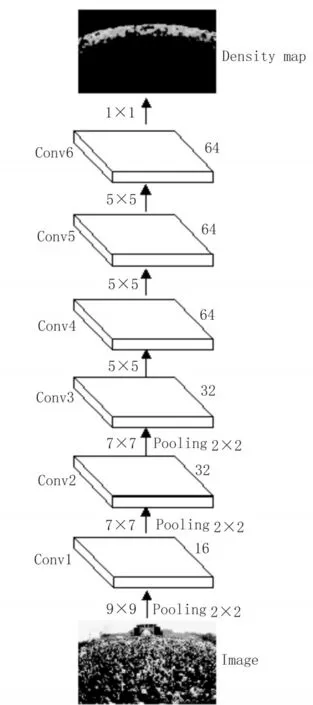
图3 人群计数模型
2 实 验
2.1 评价标准
采用平均绝对误差(MAE)和平均均方根误差(MSE)来评价算法的性能。MAE和MSE定义如下:
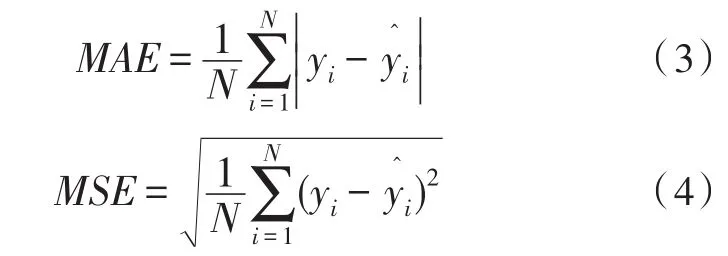
这里N是测试集的图像数目,yi和分别表示对于第i张测试图像,标注图的人头数和预测得到的人头数。MAE衡量人群计数算法的准确率,而MSE来刻画算法的鲁棒性。
2.2 实验环境和设置
所提出的全卷积神经网络的实现和它的训练测试是基于Caffe深度学习框架。
在生成标注密度图的时候,设置二维高斯卷积核的宽度参数为4。为了防止网络过拟合,在训练集上进行了数据增加操作。具体来说,从原始图像的不同区域裁剪出9个四分之一大小的图像块。因为网络使用了3个核大小为2×2,步长为2的最大池化层,这样使得最后输出的密度图的大小是原始的八分之一,所以在网络计算损失的时候,使用的标注密度图也是原始大小的八分之一。
在训练阶段,设置网络初始的学习率为0.000 1,当训练的损失不再下降的时候,学习率减少10倍。使用的网络优化算法是带冲量的批处理随机梯度下降法(SGD with momentum),设置批处理大小为32,冲量为0.9。为了减少模型过拟合,使用0.000 5的权重衰减。
在测试阶段,使用全尺寸的图像作为输入,在网络输出的密度图上进行求和操作获得最终的人群数目估计。
2.3 实验结果与分析
采用UCF_CC_50数据集来评价所提出算法的性能,同时对比现在最好的一些算法。
UCF_CC_50数据集是第一个非常密集的人群数据集,由Idrees[10]所提出的,数据集是由作者在互联网上收集而来。数据集只有50张图像,单张图像的人头数从94到4543不等,作者一共标注了64K个人头。所以这是一个非常有挑战性的数据集。实验采用和Idrees[10]一样的设置,因为该数据集没有提供标准的测试数据,所以实验进行5折的交叉验证。
实验结果如表1所示。

表1 实验结果
表1展示了文中所提出的全卷积神经网络和其他几种现存最好方法的性能对比。文献[16]采用在随机选取的图像块上提取密集的尺度不变特征变换(SIFT)特征。文献[10]使用多种不同来源的特征来估计人群。文献[11]提出了一种浅层的卷积神经网络来同时获得一张图像的人群数目和人群密度。文献[12]使用多列卷积神经网络来适应不同大小的人头。本文提出的方法取得了最好的MAE效果,在MSE上和其他方法几乎一样。
重点比较文献[16],文献[11]和文献[12]。因为UCF_CC_50数据集训练样本只有50张图像,训练样本很少,导致本文提出的全卷积深度网络容易过拟合,所以导致在MSE上比不过文献[16]。与文献[11]对比,本文的网络的深度更深,感受野更大,对人头更大的图像更加鲁棒。在训练阶段不用像文献[11]那样交替优化人群数目和人群密度的网络。而相较于文献[12],网络的参数数量比较少,同时不用像它那样先分别预训练每列网络,最后再微调整个网络,使得整个训练流程变得复杂。本文的方法优化简单,训练方便快速。
3 结 论
本文提出了一种基于全卷积神经网络的人群计数算法。模型是一种全卷积的神经网络,所以不受输入图像的大小影响。同时,网络的参数很少,降低了模型的复杂度,减少过拟合现象。采用3个池化层,大大增加了网络的感受野,从而使网络能够对大面积的人头响应。通过网络先预测得到人群密度图,然后进一步获得人群数目,既能获得人群的在空间中分布情况,同时也使最终获得的人群数目更加准确。在UCF_CC_50标准数据集上充分的实验和对比,验证了所提出的全卷积神经网络对于人群计数的高准确率和有效性。
[1]Lin Z,Davis LS.Shape-based human detection and segmentation via hierarchical part-template matching [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32(4):604-618.
[2]Idrees H,Soomro K,Shah,M.Detecting humans in dense crowds using locally-consistent scale prior and global occlusion reasoning[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(10):1986-1998.
[3]韩廷卯.一种基于独立运动的人群计数方法[J].电子设计工程,2012,20(20):55-57.
[4]姬丽娜,陈庆奎,陈圆金,等.基于GPU的视频流人群实时计数[J].计算机应用,2017,37(1):145-152.
[5]梁荣华,刘向东,马祥音,等.基于SURF的高密度人群计数方法[J].计算机辅助设计与图形学学报,2012,24(12):1568-1575.
[6]周成博,陶青川.基于景区场景下的人群计数[J].现代计算机,2016(5):52-57.
[7]覃勋辉,王修飞,周曦,等.多种人群密度场景下的人群计数[J].中国图象图形学报,2013,18(4):392-398.
[8]丁艺,陈树越,刘金星,等.基于归一化目标像素的人群密度估计方法[J].计算机应用与软件,2016,33(4):212-214.
[9]时增林,叶阳东,吴云鹏,等.基于序的空间金字塔池化网络的人群计数方法[J].自动化学报,2016,42(6):866-874.
[10]Idrees H,Saleemi I,Seibert C,et al.Multisource multi-scale counting in extremely dense crowd images[C]//CVPR.2013:2547-2554.
[11]Zhang C,Li H,Wang X,et al.Cross-scene crowd counting via deep convolutional neural networks[C]//CVPR.2015:833-841.
[12]Zhang Y,Zhou D,Chen S,et al.Single-image crowd counting via multi-column convolutional neural network[C]//CVPR.2016:589-597.
[13]Olga R,Jia D,Hao S,et al.ImageNet large scale visual recognition challenge[J]. International Journal of Computer Vision,2015,115(3):211-252.
[14]Krizhevsky A,Sutskever I,Hinton GE.Imagenet classification with deep convolutional neural networks[C]//NIPS.2012:1097-1105.
[15]Long J,Shelhamer E,Darrell T.Fully convolutional networks for semantic segmentation[C]//CVPR.2015:3431-3440.
[16]Lempitsky V,Zisserman A.Learning to count objects in images[C]//NIPS.2010:1324-1332.
猜你喜欢
数学小灵通(1-2年级)(2021年11期)2021-12-02
北京航空航天大学学报(2021年9期)2021-11-02
今日农业(2020年19期)2020-12-14
中等数学(2020年8期)2020-11-26
小学生学习指导(低年级)(2020年4期)2020-06-02
电子制作(2019年11期)2019-07-04
知识窗(2019年4期)2019-04-26
北京航空航天大学学报(2018年1期)2018-04-20
百花洲(2018年1期)2018-02-07
数学小灵通·3-4年级(2017年11期)2017-11-29
