
数据服务依赖图模型及自动组合方法研究
2018-03-27 03:41:04张元鸣叶成龙黄浪游陆佳炜
小型微型计算机系统 2018年3期
张元鸣,叶成龙,黄浪游,陆佳炜,徐 俊,肖 刚
1(浙江工业大学 计算机科学与技术学院,杭州 310023) 2(浙江工业大学 机械工程博士后流动站,杭州 310023)
1 引 言
随着服务计算技术的快速发展,不仅软件以服务的方式被发布在互联网上,称为Web服务,而且数据也以服务的方式发布在互联网上,称为数据服务(Data Service,DS)[1,2].数据服务通过一组数据资源访问接口,屏蔽了底层数据多源、异构等特征,为数据集成和数据共享提供了一种统一的数据模型.通过组合已发布的数据服务,可以有效满足跨域业务处理系统的处理需求和数据分析需求.
然而,如何快速自动组合数据服务并生成数据视图是数据服务需要解决的一个挑战性问题.与Web服务组合问题不同的是,数据服务间不存在接口依赖关系,不能根据接口关系生成数据视图,现有的数据服务组合方法与工具,如Aqualogic[3]、Damia[4]、Iviewer[5]等,为用户提供了可视化的方式来自定义数据服务组合,由用户根据需求手动地生成数据视图.然而,当数据服务的数量超过一定规模时,数据服务之间的关系也变得非常复杂,用户将难以高效地选择数据服务,这给组合出用户需要的数据视图带来很大挑战.
针对该问题,本文提出一种数据服务依赖图模型,并在该模型基础上实现了数据服务的自动组合.该方法根据内在的数据依赖关系,将数据服务组织为能够描述全局逻辑结构的数据服务依赖图,将数据组合问题建模为基于依赖图模型的数据服务搜索问题:以用户数据需求为输入,根据需求约束,在依赖图上搜索能够满足需求的数据服务依赖子图,然后执行组合后的复合数据服务生成可视化数据视图.
2 相关研究
BEA公司最早在2005年提出以服务的形式封装数据并提供各种数据服务给用户或系统[6],它以类似于Web服务的形式,将数据资源作为一种软件服务,通过其所提供的接口进行访问,并输出一个确定数据模式结果的数据集.数据服务为数据集成和共享提供了一种新的有效手段,是当前服务计算领域研究的一个热点.
在数据服务的封装、访问和应用方面,蔡海尼等[6]验证了数据服务不仅能够直接访问数据源,并且能通过标准的接口集成到SOA中,不需要依赖已有应用程序,能够访问跨平台的数据资源,弥补了传统SOA在数据访问中的缺陷与不足;Liu等[7]为现代企业信息系统设计了数据服务架构,用来解决数据的语义集成和数据服务的适应性,使各种企业信息系统能获取和共享数据;谢兴生等[8]提出了一种基于数据服务匹配的数据集成方法,该方法主要基于数据服务发布、注册和检索的方式,利用数据形式语义进行数据集成,并增强与语义Web和描述逻辑推理等智能技术的融合,具有良好的性能和可伸缩性;谢军等[9]提出一种基于虚拟视图的多源数据集成方法,该方法利用分类包装器对底层物理数据进行包装和转换,统一异构数据源访问接口,把底层的数据转换为统一的数据模型,有效地实现了多源异构数据的集成;王桂玲等[10]提出了基于云计算的流数据集成与服务,归纳了大规模流数据的集成与服务研究面临的挑战,探讨了云计算环境下求解相关问题的思路;Zorrilla M等[11]描述了基于SaaS的数据挖掘服务架构,它遵循面向服务的架构设计,可与其他数据挖掘算法和可视化工具非常容易地集成,为没有数据挖掘知识的用户提供服务.
在数据服务组合和数据视图生成方面,温彦等[5]提出了跨组织业务数据视图的动态生成方法iViewer,通过可视化和易用的数据服务组合操作来动态构建数据视图;Gu等[12]提出了服务数据链接模型,描述数据服务的输入和输出属性之间的数据映射,并实现了数据驱动在自动服务组合领域的应用;Amdouni等[13]提出了一种用于对不确定数据服务建模的概率方法,计算组合输出概率的组合代数,并提出了一种算法来找到组合的正确执行计划;Chen等[14]开发了一种名为HS3的新颖的分布式认证代码,针对多维数据的各种查询认证方案,确保集成数据的完整性和查询结果的正确性;Abdelhamid等[17]对非确定语义描述的数据服务组合问题进行了研究,通过“可能性”将非确定的语义描述进行了量化,并在组合过程中考虑可能的组合方案;Zhou等[18]提出了扩展的IOPE模型,能够基于本体描述语言OWL-S对数据服务进行语义描述和建模,为数据服务自动组合提供了语义信息.
在数据服务视图更新及优化方面,张鹏等[15]提出了一种基于数据服务的嵌套视图动态更新方法,利用指针为嵌套视图中的元组建立嵌套任意层次的数据服务的引用,同时给出了一种记录数据服务更新的日志以及在该日志上的嵌套视图增量更新算法,提高了嵌套视图的数据新鲜度;此外,该课题组还对数据组合视图的优化更新方法进行了研究,通过数据缓存的方法减少数据视图更新的时间[16].
分析现有的关于数据服务组合的研究可知,还没有给出有效的数据服务自动组合方法.例如,文献[5]提出的基于嵌套视图的组合方法属于手动的组合方法,难以适应数据服务数量较大的情况;文献[12]提出的基于输入输出依赖关系的数据服务组合方法借鉴了传统的Web服务组合方法,无法利用数据服务自身的特征对组合进行建模;文献[17]给出了数据服务的语义描述方法,还没有具体的组合算法;文献[18]仅对数据服务的模糊语义进行了建模,也没有提出可行的自动组合方法.与以上这些方法相比,本文将数据服务组合问题建模为基于依赖图模型的数据服务搜索问题,实现了数据服务的自动组合:以用户数据需求为输入,根据需求约束,在依赖图上搜索能够满足需求的数据依赖子图,然后执行组合后的复合数据服务生成可视化数据视图,实现了数据服务的自动化组合和视图生成.
3 数据服务依赖图模型
本节先给出数据依赖、数据依赖图、原子数据服务的基本概念,并说明这些基本概念之间的关系.
3.1 基本概念
属性是客观事物特征或性质的抽象描述,数据则是属性的具体取值,而数据依赖则是客观事物属性间取值的约束关系.借鉴关系数据模型中的函数依赖和连接依赖的相关概念,对数据服务之间的关系进行建模.
定义1.(函数依赖)设X,Y是关系模式R(U)的两个属性集合,当R的任意关系的任意两个元组的X值相同时,则它们的Y值也相同,则称Y函数依赖于X,记为X→Y.
根据函数依赖的定义,可以推导出完全函数依赖、部分函数依赖、相互函数依赖,定义如下:
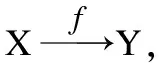
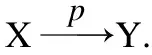
推论3.如果X→Y且Y→X,则X与Y之间为相互函数依赖,记为X↔Y.
表1 电梯企业信息系统数据集
Table 1 Data set of elevator enterprise information system

来源部门关系模式名称属性集设计部门电梯基本信息a;b;c;d;电梯客户信息e;f;g;h;电梯订单信息a;e;i;j;维修部门电梯基本信息k;l;m;n;电梯维修记录o;p;q;r;电梯维修信息k;o;s;t;数据项定义:(1) a:电梯编号;b:电梯名称;c:规格型号;d:安装位置;(2) e:客户编号;f:客户名称;g:客户地址;h:联系方式;(3) i:电梯价格;j:安装日期;(4) k:电梯标识;l:电梯名称;m:使用单位;n:安装位置;(5) o:维修标识;p:报修故障;q:报修时间;r:维修时间;(6) s:维修部件;t:维修价格
定义2.(连接依赖)设X是两个关系模式R1(U1)和R2(U2)的公共属性集,若X→U2,则称属性集U2连接依赖于X.
将连接依赖视为关系模式间特殊的函数依赖,这样函数依赖定义了关系模式内和关系模式间的数据依赖关系.任给关系模式集及在其上定义的属性集,通过属性集之间的函数依赖关系就可以建立属性之间的依赖图,简称为数据依赖图(Data dependence graph,DDG),定义如下:
定义3.(数据依赖图)将关系模式集的属性间的依赖关系描述为一个扩展的有向图,表示为一个二元组DDG=(U,E),其中U={a1,a2,…,an}是单个属性的集合;E={e1,e2,…,em}是属性间依赖关系的集合,如ei=X→aj表示属性aj完全依赖于属性集X,X⊆U.
依据上述定义中的完全依赖关系,可以推出属性间的部分依赖关系和相互依赖关系.例如,假设存在电梯企业的两个业务信息系统,它们包括的关系模式以及属性如表1所示.其中的属性a(电梯编号)和属性k(电梯标识)在两个信息系统中语义等价,相互依赖,为数据集成和共享提供了桥梁作用.
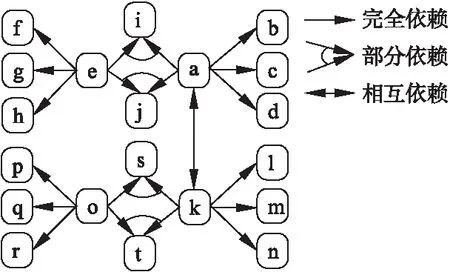
图1 属性间的数据依赖关系图Fig.1 Data dependency graph among attributes
3.2 原子数据服务
数据服务的粒度会对数据服务的可用性和可组合性产生直接影响:
1)如果数据服务粒度太小,则数据服务可能会失去语义信息.例如,若仅将表1中电梯的属性d作为一个数据服务,则对该数据服务的访问结果难以表明是属于哪台电梯的安装位置;
2)如果数据服务的粒度太大,则数据服务的组合将失去一定的灵活性,并造成一定的数据冗余.例如,若将关系“电梯基本信息”的所有属性作为一个数据服务,则对该数据服务访问的结果包括了较多的数据,降低组合的灵活性和引起较多的数据冗余.
为此,提出原子数据服务(Atomic data service,ADS)的概念,其定义如下:
定义4.(原子数据服务)将可独立访问且语义不可再分的数据服务称为原子数据服务,可以表示为一个八元组ADS=
· Id是ADS的唯一标识;
· Name是ADS的名称;
· Fields是ADS的属性列表;
· Description是ADS的语义描述;
· Input是ADS的输入,可以有多个;
· Output是ADS的输出,可以是一个关系;
· Operations是ADS可执行的操作;
· Publisher是ADS的发布者.
算法1给出了原子数据服务划分算法,输入是数据依赖图DDG,输出是原子数据服务的列表.该算法以DDG的任意结点v开始访问,按照广度优先策略查找结点v的任一邻接结点w,若结点w中存在结点v的前驱结点且存在多个前驱结点,则首先把v结点所有的前驱结点封装为一个ADS,其输入是v节点的属性,输出也是v节点的属性;再把所有的前驱结点与v结点封装为一个ADS,其输入是前驱结点的属性集或v结点的属性,而输出则是前驱结点的属性集和v结点的属性;若v结点的前驱结点唯一,则把前驱结点和v结点封装为ADS,其输入是前驱结点的属性集或v结点的属性,输出是前驱结点的属性集和v结点的属性;若v结点不存在前驱结点,则确定v结点为前驱结点,w结点为后继结点,把v结点和w结点依次封装为ADS,其输入是w结点的属性或v结点的属性,输出为w结点的属性和v结点的属性;若所有结点都被访问过,则划分结束,输出原子数据服务集合.
算法1.原子数据服务划分算法
Input:Data dependence graphDDG=
Output:A set of atomic data services.
1. Function ADSCreate(DDG
2. Dim i,w,n,loc As INTEGER;
3. n=G.NumberOfVertices(); //Take the number of nodes in the graph
4. Dim visited[] As bool; //Record whether the node has been visited
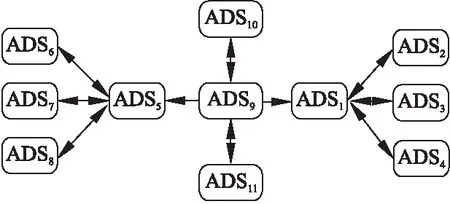
5. for(i=0;i 6. loc=G.getVertexPos(v); 7. G.getValue(loc);//Access the node,making the visited tag 8. Queue 9. while(!Q.IsEmpty){ 10. Q.DeQueue(loc); //Quit the node(loc)from the queue 11. w = G.getFirstNeighbor(loc); 12. While(w!=-1){ 13. if(visited[w] = = false){ 14. G.getValue(w); 15. visited[w]=true; 16. if(∃loc.П∈w){ // П means predecessor node 17. if(П.length()>=2){ 18. for(j=0;j<П.length();j++) 19. Encapsulated П as a data service, 20. input is {П},output is {П}; 21. Encapsulated {П,loc} as a data service, 22. input is {П} or {loc},output is {П,loc}; 23. }else if(П.length()<2){ 24. Encapsulated {П,loc} as a data service, 25. input is {П} or {loc},output is {П,loc}; 26. } 27. }else{ 28. for(j=0;j 29. Encapsulated {loc,w[j]} as a data service, 30. input is {loc} or {w[j]},output is {loc,w[j]}; 31. } 32. Q.EnQueue(w); 33. } 34. w = G.getNextNeighbor(loc,w); 35. } 36. delete [] visited; 37. } 38. }; 通过算法1对图1所示的数据依赖图进行原子数据服务划分,得到的原子数据服务如表2所示.根据定义4,原子数据服务可以表示为一个八元组,包括输入和输出,以ADS1和ADS2为例予以说明: 1)ADS1是仅包含一个属性的数据服务,该数据服务可以提供电梯编号信息,其输入和输出都是“电梯编号”. 2)ADS2是一个包括电梯编号和电梯名称的数据服务,该数据服务可以提供电梯编号和电梯名称信息,其输入是“电梯编号”或“电梯名称”,输出是“电梯编号”和“电梯名称”. 需要说明的是,ADS2不可以再细分为两个服务,因为在电梯名称可以重复的情况下,仅电梯名称(对应属性b)不能明确是哪台电梯,导致语义丢失,因此不可以独立封装为一个原子数据服务. 表2 属性集划分得到的部分原子数据服务 IdNameFieldsDescriptionInputOutputOperations01ADS1{a}查询电梯编号电梯编号电梯编号get02ADS2{a,b}查询电梯编号和电梯名称电梯编号或电梯名称电梯编号和电梯名称get03ADS3{a,c}查询电梯编号和型号规格电梯编号或型号规格电梯编号和型号规格get04ADS4{a,d}查询电梯编号和额定人数电梯编号或额定人数电梯编号和额定人数get05ADS5{e}查询客户编号客户编号客户编号get06ADS6{e,f}查询客户编号和客户名称客户编号或客户名称客户编号和客户名称get07ADS7{e,g}查询客户编号和客户地址客户编号或客户地址客户编号和客户地址get08ADS8{e,h}查询客户编号和联系方式客户编号或联系方式客户编号和联系方式get09ADS9{a.e}查询电梯、客户编号电梯编号或客户编号电梯编号和客户编号get10ADS10{a,e,i}查询电梯、客户编号和电梯价格电梯、客户编号或电梯价格电梯、客户编号和电梯价格get11ADS11{a,e,j}查询电梯、客户编号和安装日期电梯、客户编号或安装日期电梯、客户编号和安装日期get 由于原子数据服务是通过封装关系模式的属性得到的,因此原有属性间的数据依赖关系可以直接转换为数据服务之间的依赖关系.根据属性间的完全函数依赖、部分函数依赖和相互函数依赖可以得到数据服务之间的以下三种依赖关系: 定义5.(顺序依赖)对于两个原子数据服务ADSi与ADSj,若ADSi的属性值确定,ADSj上的属性值也相应确定,即ADSi→ADSj,则称ADSi与ADSj之间为顺序依赖. 定义6.(合并依赖)对于原子数据服务ADS1,ADS2,…,ADSm以及ADSj,若 {ADS1∪ADS2∪ADS3∪…∪ADSm}→ADSj,则称为合并依赖. 定义7.(相互依赖)对于原子数据服务ADSi以及ADSj,若ADSi→ADSj且ADSj→ADSi,则称为ADSi与ADSj之间为相互依赖. 图2 原子数据服务间的基本依赖关系Fig.2 Basic dependency relationship among ADSs 这三种数据服务依赖关系如图2所示.根据以上定义,可以得到数据服务依赖的性质: 性质1.数据服务依赖具有传递性,即若ADSi→ADSj且ADSj→ADSk,则ADSi→ADSk. 证明:略. 性质2.数据服务依赖具有对称性,即若ADSi↔ADSj,则ADSi→ADSj且ADSj→ADSi. 证明:略. 根据数据服务依赖关系,可以得到数据服务依赖图(Data service dependence graph,DSDG),简称服务依赖图,定义如下: 定义8.(服务依赖图)将原子数据服务间的依赖关系描述为一个扩展的有向图,表示为一个二元组DSDG=(D,E),其中D={ADS1,ADS2,…,ADSn}是原子数据服务集合;E={e1,e2,…,em}是原子数据服务间依赖关系集合,如ei=A→ADSj表示原子数据服务ADSj依赖于原子数据服务集合A,A⊆D. 对于上述定义的数据服务依赖关系ei=A→ADSj, 1)若A仅包含一个原子数据服务,ei是顺序依赖关系; 2)若A至少包含两个原子数据服务,ei是合并依赖关系. 图3 数据服务依赖图Fig.3 Data service dependence graph 根据图1的数据依赖图得到原子数据服务依赖图,如图3所示,图中的原子数据服务对应表2中的原子数据服务. 构建服务依赖图的意义在于可以方便地根据数据服务之间的依赖关系组合成用户需要的复合数据服务,并进一步生成用户数据视图.例如,假设有一个数据需求是根据“客户名称”查询“规格型号”,则根据服务依赖图可以查询知道,相关的数据服务集包括{ADS6,ADS5,ADS9,ADS1,ADS3},这些数据服务之间的关系构成了一个子图,通过分析执行子图可以得到查询的结果. 本节给出一个数据服务自动组合算法,该算法基于服务依赖图模型,通过分析原子数据服务之间的依赖关系,搜索与数据需求相关的数据服务,构建复合数据服务,通过执行复合数据服务得到用户视图,对复合数据服务(Composite data service,CDS)的定义如下: 定义9.(复合数据服务)由若干原子数据服务组成且可被独立访问的数据服务称为复合数据服务,它可以表示为一个八元组CDS= · Id是CDS的唯一标识; · Name是CDS的名称; · Sub-DSDG是DSDG的子图; · Description是ADS的语义描述; · Input是CDS的输入,可以有多个; · Output是CDS的输出,可以是一个关系; · Operations是对ADS可执行的操作; · Publisher是ADS的发布者. 数据服务组合过程是在用户数据需求驱动下进行的,数据需求(Data Requirements,DR)的定义如下: 定义10.(数据需求)用户所需要的属性列表、约束条件以及执行的操作称为数据需求,可以表示为一个三元组DR= · Requires表示数据需求的属性列表; · Conditions={ · Operations={get,delete,update}表示需要执行的操作. 以查询客户名称为“杭州大厦”的电梯规格型号为例,其DR可以定义为: DR=<{客户名称,规格型号},{<客户名称,“杭州大厦”>}, 算法2给出了数据服务自动组合算法,该算法的输入是DSDG和DR,输出是复合数据服务.首先在DSDG上检索出包含Requires属性列表和Conditions属性列表的所有ADS;通过深度搜索策略寻求能够联通这些ADS的通路;如果存在多个通路,则表示存在多个组合方案;将包括ADS数量最少以及包括的属性个数最少的通路作为最终输出,得到最优的数据服务组合结果,该结果即是需要的CDS. 由于CDS包括的ADS数量和属性个数将影响CDS的执行性能,因此算法以此为标准对数据服务组合方案进行筛选,得到最优的数据服务组合结果.实际应用表明,该方法简单易用,实际应用中往往能得到最优的组合解.此外,以上算法假设DSDG的所有节点是联通的,如果不联通,则可以分别对DSDG的所有子图循环使用该算法,并输出每个子图的CDS. 设r为数据需求属性列表的个数,n为服务依赖图中的节点总数,e代表邻接表表示边的个数,则算法第1行到第6行的时间复杂度是O(n),第7行到第25行的时间复杂度是O(n+e),因此算法总的时间复杂度为O(n+e). 以查询客户名称为“杭州大厦”的电梯规格型号的数据需求为例予以说明:根据该算法首先检索包含“客户名称”和“规格型号”语义的原子数据服务,然后寻求能够联通这两个节点的通路,所有在该通路上的原子数据服务以及依赖边组成的子图即是满足该用户数据需求的“复合数据服务”.图3中ADS1,ADS3,ADS5,ADS6,ADS9的ADS原子数据服务就是组合后的复合数据服务. 算法2.数据服务自动组合算法 Input:DSDG,DR Output:CDS 1. Function CDSCreate(DSDG= 2. Dim i,n,w,loc As INTEGER; 3. n=G.NumberOfVertices(); //Take the number of nodes in the graph 4. Dim visited[] As bool; //Record whether the node has been visited 5. for(i=0;i 6. loc=G.getVertexPos(v); 7. getPaths(G,loc,visited[],DR){ 8. G.getValue(v); //Access the node,making the visited tag 9. stack.push(v); 10. w=G.getFirstNeighbor(v); //Find the first adjacent node of node v 11. while(w != -1){ 12. stack.push(w); 13. if(stack.contains(r)== true){ 14. Encapsulated v and visited[w] as a composite data service; 15. return true; 16. } 17. else if(visited[w] == false){ 18. getPaths(G,w,visited[],DR); //Recursive access if w has not been accessed 19. stack.pop(); 20. } 21. w = G.getNextNeighbor(v,w); //Take the next adjacent node after w of node v; 22. } 23. delete [] visited; 24. } 25. }; 根据数据服务组合的结果,执行CDS将能够生成数据视图,其定义如下: 定义11.(数据组合视图)执行复合数据服务后生成的结果称为数据组合视图,其形式上是一张二维表格. CDS包含了与数据需求相关的原子数据服务及其依赖关系,以查询操作为例,给出执行CDS的基本步骤: 第1步.分别执行CDS的所有ADS,并根据Conditions条件对ADS的执行结果进行筛选; 第2步.对具有服务依赖关系的ADS的结果执行连接操作; 第3步.根据DR中的Requires属性列表对连接的结果执行投影操作; 第4步.若存在多个CDS,则反复执行步骤1和步骤4,得到多个满足DR的数据子集; 第5步.对得到的多个数据子集执行并操作. 执行复合数据服务所涉及的操作包括选择、连接、并和投影,这些操作是关系数据模型中的基本操作,不作为本文论述的重点. 以图3中灰色原子数据服务组合成的复合数据服务为例说明执行的过程:首先,执行原子数据服务ADS6、ADS5、ADS9、ADS1、ADS3,根据Conditions条件<客户名称,“杭州大厦”>对ADS6的执行结果进行筛选;第二,对以上五个ADS的结果执行连接操作,得到一个结果集;第三,根据DR中的Requires对结果集执行投影操作;第四,由于只有一个复合数据服务,因此跳过;第五,输出执行的结果,该结果就是执行复合数据服务后得到的数据组合视图. 由于目前还没有公开的数据服务评价数据集,本文结合电梯企业各部门信息系统中的数据建立数据服务,涉及的数据类别包括电梯标准数据、电梯设计基本数据、电梯销售基本数据、电梯维护基本数据、电梯使用基本数据、电梯故障检测数据、电梯使用单位数据、电梯制造单位数据、电梯维保单位数据等. 图4 跨部门数据服务依赖图Fig.4 Data service dependency graph of inter-departments 根据文中提出的原子数据服务划分方法,得到原子数据服务集合,并根据原子数据服务之间的服务依赖关系,建立数据服务依赖网,如图4所示,图中每个节点代表一个原子数据服务,每条有向边代表原子数据服务之间的依赖关系,原子数据服务总数为810个,图中的不同颜色表示数据来自多个不同的部门,并通过公共的属性建立跨部门之间的数据联系. 由于数据服务的划分已结合实例进行了详细描述.为此, 本实验主要对数据服务组合算法的效率、 质量和成功率三个方面进行评价: 组合效率用来评估数据服务组合所花费的时间代价; 组合质量用来评价服务组合的结果是否为最优解; 组合准确性用来评价复合数据服务的执行结果能否满足数据需求. 表3 实验数据集 测试数据集类型DR.Requires属性个数DR.Conditions约束个数数据服务总数不同数据服务总数62100,200,400600,800不同属性列表2,4,6,8,102800不同约束个数61,2,4,6800 实验环境是在一台服务器上搭建完成的,CPU是Inter E5-2430,主频是2.20GHz,内存是4GB. 从原子数据服务的总数、数据需求的属性个数和数据需求的约束条件个数对组合算法进行评价,包括三组测试数据:测试数据集1保持属性个数和约束个数不变,数据服务总数分别设置为100、200、400、600、800;测试数据集2保持约束个数不变,数据服务总数不变,属性个数分别设置为2,4,6,8,10;测试数据集3保持属性个数和数据服务总数不变,约束个数分别设置为1,2,4,6.以上所涉及到的属性都可以在数据服务中进行成功匹配.每次测试均按照随机方式给出属性个数、约束个数,并选取10次测试结果的平均值作为实验结果. 本文的数据服务组合算法是根据数据需求的Requires和Conditions,基于服务依赖图搜索最优的复合数据服务.图5(a)给出了不同数据服务总数下的复合数据服务的组合时间; 图5(b)给出了不同属性列表情况下复合数据服务的组合时间.从图中可以看出,随着Requires和数据服务的增加, 复合数据服务的组合时间也在不断增加.这是因为Requires影响数到涉及的原子数据服务的数量;而数据服务总数影响到据服务的组合范围;此外,实验还表明数据需求的Conditions也影响着服务组合的时间,但其影响与Requires类似,Conditions中的条件越多,涉及到的原子数据服务数量也越多.当数据服务为800时,不同属性列表的平均搜索时间为128ms. 图5 不同条件下数据服务组合的效率Fig.5 Composition efficiency with different conditions 组合质量是指组合得到的复合数据服务所包含的原子数据服务的数量以及属性的个数.实验结果表明,每组数据需求通过组合算法可以得到多个组合方案,但它们的原子数据服务数和属性个数可能不同.由于组合算法以复合数据服务包括的原子数据服务数量和属性个数作为评价标准,复合数据服务中包括的原子数据服务及其属性列表的数量越少,组合方案越好.因此,通过运行本文算法得到的组合结果即是最优组合解,实验统计结果如表4 所示.对组合结果分析发现,当原子数据服务数量为800、属性列表数量为4时,存在两个包含数据服务数量相同的组合方案6(10)和6(11),其中括号前面的数值表示原子数据服务的数量,括号中的数值表示属性的个数;此外,实验还表明随着数据需求中包含的属性列表数量的增大,组合结果逐步趋向唯一解. 表4 组合质量的统计结果 原子数据服务数量属性列表数量不同的CDS包括的原子数据服务的数量最优CDS包括的原子数据服务数量80022、4、6、6、8、10280046(10)、6(11)、8、106(10)80066、8、10680088、108800101010 实验只考虑数据需求所包含的属性列表能够在原子服务中查找到的情况,对于无法查找到相应原子数据服务的情况,则表明无法通过服务组合满足数据需求,被直接忽略.通过执行复合服务生成数据视图,仔细分析后发现:数据视图中包含的属性列表与数据需求中包含的属性列表相匹配,而且执行的数据结果满足数据需求的约束条件,这表明通过执行复合数据服务得到的数据视图能够准确地满足数据需求,成功率为100%. 为了根据已封装的数据服务自动组合出能够满足用户数据需求的复合数据服务,本文提出了一种基于依赖图模型的数据服务自动组合方法.该方法将具有跨域异构特征属性集封装为不可再分的原子数据服务,并根据原子数据服务之间的数据依赖关系建立数据服务依赖图,由此将数据组合问题建模为基于依赖图模型的搜索问题,得到最优的复合数据服务,通过执行复合数据服务生成数据视图.实验结果表明,该方法具有较高的组合效率,得到的复合数据服务包含的原子数据服务数量最少,能够准确满足用户的数据需求. [1] Carey M J,Onose N,Petropoulos M.Data services[J].Communications of the ACM,2012,55(6):86-97. [2] Carey M.Declarative data services:this is your data on SOA[C].Proceedings of the IEEE International Conference on Service-Oriented Computing and Applications(SOCA),IEEE,2007:4-4. [3] Carey M J.Data delivery in a service-oriented world:the BEA aqua logic data services platform[C].Proceedings of the ACM SIGMOD International Conference on Management of Data,Chicago,Illinois,Usa,June.DBLP,2006:695-705. [4] Altinel M,Brown P,Cline S,et al.Damia:a data mashup fabric for intranet applications[C].Proceedings of the International Conference on Very Large Data Bases(VLDB),University of Vienna,Austria,September,2007:1370-1373. [5] Wen Yan,Liu Chen,Han Yan-bo.iViewer:service-based view construction method for just-in-time sharing business data across organizations[J].Journal of Frontiers of Computer Science & Technology,2012,6(3):221-236. [6] Carey M,Reveliotis P,Thatte S,et al.Data service modeling in the aqualogic data services platform[C].Proceedings of the IEEE Congress on Services(SERVICES),2008:78-80. [7] Liu X,Hu C,Li Y,et al.The advanced data service architecture for modern enterprise information system[C].Proceedings of the International Conference on Information Science and Applications(ICISA),IEEE,2014:1-4. [8] Xie Xing-sheng,Zhuang Zhen-quan.Study of data integration method based on data service matching [J].Journal of University of Science & Technology of China,2009,39(5):504-509. [9] Xie Jun,Xiao Lu.Research on data integration based on virtual view and its application[J].Engineering Journal of Wuhan University,2014,47(2):281-285. [10] Wang Gui-ling,Han Yan-bo,Zhang Zhong-mei,et al.Cloud-based integration and service of streaming data[J].Chinese Journal of Computers,2017,40(1):107-125. [11] Zorrilla M,Garc,A-Saiz D.A service oriented architecture to provide data mining services for non-expert data miners [J].Decision Support Systems(DSS),2013,55(1):399-411. [12] Gu Z,Xu B,Li J.Service data correlation modeling and its application in data-driven service composition[J].IEEE Transactions on Services Computing(TSC),2010,3(4):279-291. [13] Amdouni S,Barhamgi M,Benslimane D,et al.Handling uncertainty in data services composition[C].IEEE International Conference on Services Computing(SCC),IEEE,2014:653-660. [14] Chen Q,Hu H,Xu J.Authenticated online data integration services[C].Proceedings of the ACM SIGMOD International Conference,ACM,2015:167-181. [15] Zhang Peng,Han Yan-bo,Wang Gui-ling.Implementing dynamic nested view update based on data service [J].Chinese Journal of Computers,2013,36(2):226-237. [16] Zhang Peng,Wang Gui-ling,Ji Guang,et al.Optimization update for data composition view based on data service[J].Chinese Journal of Computers,2011,34(12):2344-2354. [17] Abdelhamid M,Mahmoud B,Sidi-Mohamed B,et al.Composing data services with uncertain semantics[C].IEEE Transactions on Knowledge and Data Engineering(TKDE),2015,27(4):936-949. [18] Zhou L,Chen H,Zhang Y,et al.A semantic mapping system for bridging the gap between relational database and semantic Web[C].Proceedings of the AAAI Spring Symposium on Semantic Scientific Knowledge Integration,2008:122-126. 附中文参考文献: [5] 温 彦,刘 晨,韩燕波.iViewer:利用数据服务即时生成跨域数据视图[J].计算机科学与探索,2012,6(3):221-236. [8] 谢兴生,庄镇泉.一种基于数据服务匹配的数据集成方法研究[J].中国科学技术大学学报,2009,39(5):504-509. [9] 谢 军,肖 路.基于虚拟视图的数据集成方法研究及其应用[J].武汉大学学报工学版,2014,47(2):281-285. [10] 王桂玲,韩燕波,张仲妹,等.基于云计算的流数据集成与服务[J].计算机学报,2017,40(1):107-125. [15] 张 鹏,韩燕波,王桂玲.基于数据服务的嵌套视图动态更新方法[J].计算机学报,2013,36(2):226-237. [16] 张 鹏,王桂玲,季 光,等.基于数据服务的数据组合视图的优化更新[J].计算机学报,2011,34(12):2344-2354.
Table 2 Some atomic data services obtained from data sets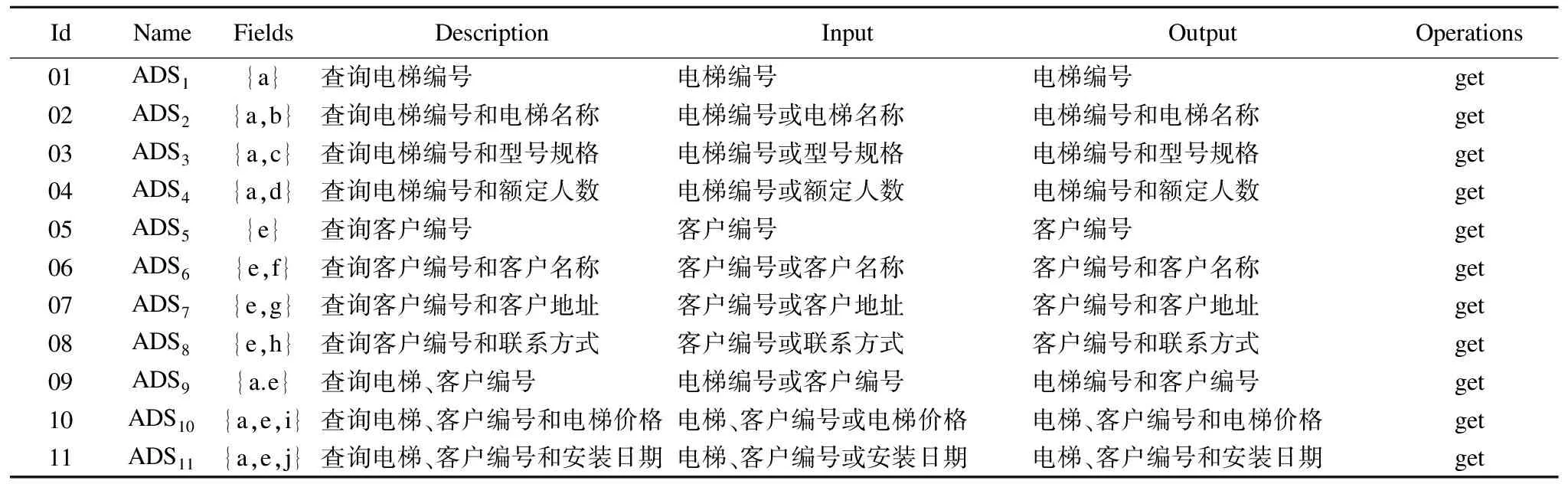
4 数据服务自动组合
4.1 数据服务依赖图模型

4.2 数据服务自动组合算法
4.3 数据组合视图生成
5 实验分析与评价

Table 3 Experimental data set
5.1 组合效率

5.2 组合质量
Table 4 Experimental results of composition quality
5.3 组合准确性
6 结束语
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:04:12数学物理学报(2018年1期)2018-03-26 08:16:42中学生数理化·中考版(2017年6期)2017-11-09 02:46:46非公有制企业党建(2017年10期)2017-11-03 02:26:27现代兵器(2017年4期)2017-06-02 15:59:24现代兵器(2017年4期)2017-06-02 15:58:14中国商论(2016年34期)2017-01-15 14:24:18电子科技大学学报(2016年2期)2016-08-31 02:50:00电信科学(2014年2期)2014-02-28 06:16:26电子设计工程(2014年12期)2014-02-27 11:58:23
