
基于模板匹配的车牌识别及图形用户交界面设计
2018-03-26 08:39郑大波
宿州学院学报 2018年12期
邵 毅,郑大波,温 艳,孙 恒
1.宿州学院机械与电子工程学院,宿州,234000;2.宿州学院煤矿与机械与电子工程中心,宿州,234000;3.上汽通用(沈阳)北盛汽车有限公司,沈阳,110000
车牌识别技术起源于20世纪80年代初期,图像模式识别和计算机视觉在其中起到至关重要的作用。随着计算机技术的迅速普及和进步,80年代中后期,车牌识别系统逐步投入市场并使用,但识别精度和速度都不理想。目前,发达国家的车牌识别系统已广泛用于市场,其中以色列和新加坡公司的车牌识别系统较为领先[1]。由于车牌设计的不同,不存在一种通用的车牌检测技术[2]。因中国车牌包括汉字,使得国外车牌识别系统不能直接用于国内车牌识别,需要中国自主研发。中国的车牌识别技术研究起步略晚于西方国家。目前国内技术领先的是中科院的“汉王眼”和香港的视觉科技公司[3]。但是,这些投入市场的车牌识别系统的使用都有一定的局限性,在车牌图像质量差、车牌倾斜、光照条件不理想等情况时,识别率会大幅度降低。
为了克服上述问题,本文对不同光照条件下获得的车牌图像进行了识别和分析。由于车牌涉及保密信息,暂时没有公开的大规模数据集可供使用和实验对比。本文先对车牌数据进行采集,统一处理为320×240分辨率的图片,建立测试用数据库。数据库分为两类:测试库1为光照条件较好,无阴影车牌;测试库2为光照条件较差,有阴影车牌。采用传统的模板匹配算法建立车牌识别系统,模板图片采用中值滤波算法进行平均处理,统一建立分辨率为20×40的识别模板库。为方便用户使用,利用Matlab建立了图形用户交互界面(GUI)。通过对测试库车牌实验,可以看到车牌成像质量对识别率有很大影响。因此在建立车牌识别系统时,适当角度的补光可有效提高识别的准确率[4]。
1 图像的预处理
由于车牌多是通过交通监控等条件获得,因周边交通环境、拍摄角度、光照和实时性要求等多种原因,得到的照片直接用于车牌的识别准确率难以得到保证。因此,预处理图像可以提高识别的准确性。
1.1 图像的灰度化
由相机拍摄的牌照通常是彩色图像,即RGB图像。为了提高车牌识别系统的速度、节省内存,先将RGB图像转换为灰度图[5]。红、蓝、绿三种基本颜色按不同的比例可以组成任意一种颜色,所以车牌照片的每一个颜色都可由不同比例的红、蓝、绿组成。灰度图像可以用数组I表示,数组I的数据类型一般有整数和双精度两种。通常0代表黑色,255代表白色。采用适合于人类视觉系统的转换方法,如公式(1)所示。
Y=a×R+b×G+c×B
(1)
其中,系数a,b,c要大于0,且a+b+c=1,Y表示灰度值,R、G、B分别表示红色、绿色和蓝色,a=0.299、b=0.584、c=0.117。图1显示了带有车牌照片的原始车牌图像,图2显示了在公式(1)的灰度处理之后车牌图像的灰度图像。

图1 车牌原图 图2 车牌灰度图
1.2 图像二值化
图像二值化不仅可以大大减少数据量,还可以突出图像的目标轮廓,有利于后续的图像定位和分割处理。在车牌图像的二值化处理中,被确定为目标区域的像素具有大于或等于阈值的灰度值,计算如公式(2)所示。经过测试,当阈值th=0.76时,效果较好,结果如图3所示。

(2)

图3 车牌的二值化图
1.3 图像的边缘检测
本文采用Roberts算子来进行边缘检测。采用该算子的计算量小,速度快,便于后续的实时处理,其模板如表1所示。若梯度幅度G(x,y)大于设定的阈值,则判断为边缘。G(x,y)计算式如公式(3)所示,此处阈值选择为0.15。

表1 Roberts算子模板
Gx=1×f(x,y)+0×f(x+1,y)+0×f(x,y+1)+(-1)×f(x+1,y+1)
=f(x,y)-f(x+1,y+1)Gy
=0×f(x,y)+1×f(x+1,y)+(-1)×f(x,y+1)+0×f(x+1,y+1)
=f(x+1,y)-f(x,y+1)G(x,y)
=|Gx|+|Gy|
(3)
其中,f(x,y)是图像空间(x,y)处的灰度值,G(x,y)是f(x,y)的梯度幅度。图4是边缘检测后的结果。

图4 车牌的边缘检测图
2 车牌识别系统的设计
2.1 车牌定位
车牌定位采用颜色特征提取,一般的车牌区域都具有很明显的特点,中国的车牌以蓝底白字居多。传统的方法一般根据车牌的色彩特征,彩色像素点统计的方法分割出合理的车牌区域。假设经相机采集包含车牌的RGB图像,水平方向记为y,垂直方向记为x。首先,确定车牌各分量分别对应的颜色范围。其次,计算水平方向上对应的像素数量和车牌的合理面积。然后,计算分割的水平方向区域中垂直方向上该颜色范围内的像素数量,并为定位设置合理的阈值。最后,根据对应方向的范围确定车牌区域。但是这种方法的准确率较低,本文采用文献[6]提出的颜色特征提取及二值化归类方法进行算法改进,计算方法如公式(4)所示。图5为定位后的车牌。
其中的蓝色特征可用式(4)表示:
(4)
其中,t1(x,y)=B(x,y)-G(x,y),t2(x,y)=B(x,y)-R(x,y)

图5 车牌定位图
2.2 车牌字符识别
在字符识别前,先对车牌字符分割。字符分割采用阈值分割,主要包含两个步骤[7]。
(1)确定所需要进行分割的阈值。
(2)将阈值与每个点的灰度值对照,以达到分割目的。
将分割后的图像进行归一化处理,可以有效地将字符图像的大小进行缩放以得到大小一致的字符图像,便于后续的字符识别。
模板匹配一般是数字图像处理中最常使用的识别方法之一,先建立模板库,再将字符输入到模板中寻找与之最佳匹配的模板字符。
模板图像大小为20×40,模板库由数字0-9,32个省份的简称汉字和大写英文字母(其中O一般不用作车牌字母)三部分组成。模板的部分图像如图6所示。

图6 模板库部分图片
根据已经条件建立模板库T(i,j),然后将要识别的f(i,j)与T(i,j)对应的特征量进行比对,按公式(5)计算归一化的互相关量Ck。其中Ck最大的即为对应类别。

(5)

2.3 GUI设计
GUI设计采用Matlab的guide作为工具,GUI共包含14个用来显示图像的axes控件,3个用来控制各个步骤的pushbutton控件。界面可以完成输入图像、图像处理、退出系统功能。GUI运行界面如图7所示。

图7 车牌识别GUI界面
3 结果及分析
实验测试图像选取自拍摄的600幅图像,20个车牌,每个车牌30幅图像。分为光照条件好无阴影和光照条件差有阴影两大类,分别建库:样本库1和样本库2。对样本库车牌分别进行评价,记录不同样本库的车牌识别正确率。测试结果如表2所示,由表2可得:在光照无阴影的条件下300幅图像可识别272幅,而有阴影的图像只能识别190幅。

表2 不同测试库的测试结果
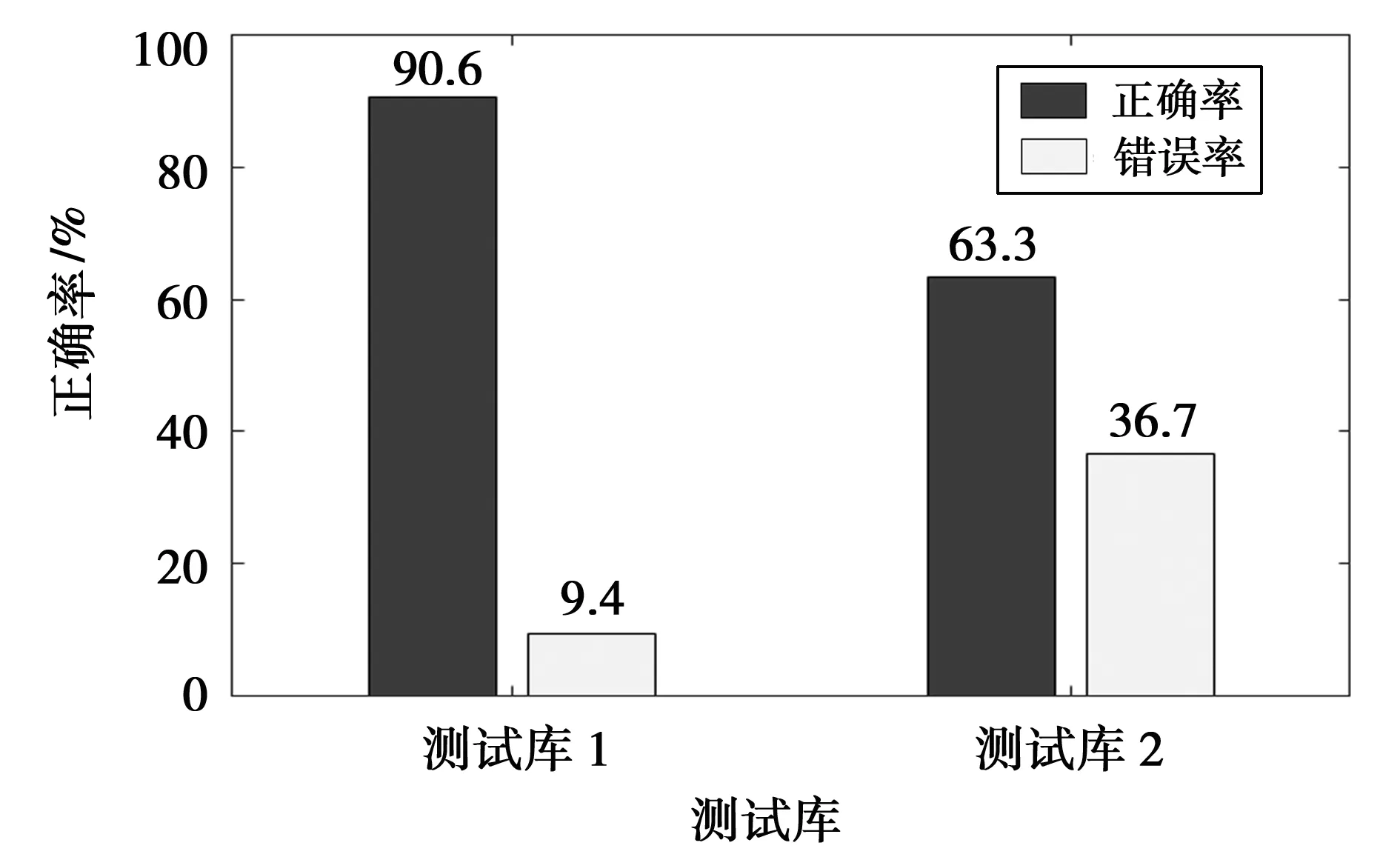
图8 测试库1和测试库2的识别率
由测试结果可见,当光照条件较好且无阴影的条件下,车牌的识别率较高,可达90.6%;当光照条件差有阴影时识别率迅速下降至63.3%。
综合分析可见,车牌识别在光照充足且无阴影的条件下,可达到较高的识别率,而对于有阴影的条件,则识别效果不理想。由于目前无公开的车牌数据库,此次所用的测试数据库车牌数量较小,车牌地点采集地点主要在安徽,皖开头的车牌较多,测试数据的多样性还有待进一步完善。
4 结 语
要实现智能交通,车牌识别是其中重要一环,本文车牌识别的具体实现方法进行了研究,设计了车牌识别系统。针对缺少公开的车牌数据库问题,进行了车牌图像的采集,建立了数据库。采用Matlab软件进行了图形用户交互界面设计。实验结果表明,此车牌识别系统在光照条件较好的情况下,可以较好地实现车牌识别,GUI界面使用方便、操作简单。但是,本文算法及系统是在实验室条件下,对采集的高质量图像进行识别,对于恶劣条件下车牌识别还需要进一步对算法进行改进。另外,还应采集更多的车牌制作模板,以增加模板的多样性来进一步提高识别的正确率。
猜你喜欢
文苑(2020年11期)2020-11-19
计算机工程(2020年3期)2020-03-19
中国诗歌(2019年6期)2019-11-15
电子制作(2019年12期)2019-07-16
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
小猕猴智力画刊(2017年5期)2017-05-25
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
电子制作(2017年22期)2017-02-02
中国交通信息化(2016年2期)2016-06-06
