
基于属性偏好自学习的推荐方法
2018-03-26 03:26:48,,,
浙江工业大学学报 2018年2期
,,,
(1.浙江工业大学 计算机科学与技术学院,浙江 杭州 310023;2.杭州市富阳中学,浙江 杭州 311400)
随着社会发展进步,人类已经步入了一个信息过载的时代.针对这个情况,推荐系统从海量数据中挖掘有用信息向用户推荐其感兴趣的商品.推荐系统的这种特性对电子商务网站具有显著作用[1].推荐所需的用户信息包括显式信息和隐式信息.显式信息包括用户对商品的评分、评价和投票信息,此类信息较为准确、难以收集.隐式信息包括用户点击历史、购买历史及收藏信息,该信息易收集、难以准确描述用户偏好(包含多种语义).随着研究的深入,社交信息被作为一种补充信息来优化推荐结果.社交网络富含多种用户关系,比如朋友关系、关注关系、社区关系及用户上下文数据(地点、心情等).属性信息也是一种补充信息,该信息对挖掘用户的潜在偏好上具有一定的作用.属性信息可分为用户、商品及标签属性信息.一般来说,用户信息包括用户年龄、性别、职业和所在地等.商品信息包括商品的分类、生产日期等.标签是一种特殊属性,它将用户和商品都关联起来.
在实际应用中,推荐系统存在数据稀疏性和冷启动问题.数据稀疏性是指用户对商品评分数量十分稀疏,比如Epinion数据集中有效评分仅占全部评分的0.05%[2].冷启动问题包括用户冷启动和商品冷启动问题.用户冷启动问题是指对于用户评分数量很少或没有而导致用户推荐结果不准确或难以推荐的问题.商品冷启动问题是指对于那些很少有人购买或没有人购买的商品推荐不准确或难以进行推荐的问题.笔者将首先介绍推荐系统的相关工作,然后介绍偏好自学习模型,包括建模方法、模型公式与推荐算法.接下来介绍实验的数据集、数据分布情况、实验设置、实验方案及结果.最后对工作进行总结并给出论文后续工作.
1 相关工作
推荐系统包含基于内容的过滤(Content-based filtering)和协同过滤(Collaborative filtering).基于内容的过滤在早期应用较广,现在主要用于新闻的个性化推荐.目前最为常用和成功的方法是协同过滤,其可分为基于邻域的推荐(Neighbor-based CF)和基于模型的推荐(Model-based CF)[3].其中基于邻域的推荐方法可分为基于用户的协同过滤(User-user collaborative filtering or userKNN)和基于商品的协同过滤(Item-item collaborative filtering or itemKNN).这两种方法都是在计算用户或商品的相似度基础上,选取相似度高于一定阈值的用户或商品进行推荐.基于模型的方法是从用户信息中学习相应的模型参数,然后根据模型进行推荐.该方法包括矩阵分解模型、聚类模型、贝叶斯模型和排序模型等.在相关论文中,PMF[4]构建了一个用户及商品概率模型,并通过梯度递减方法学习模型参数.BasicMF[5]类似于PMF,但其将评分矩阵分解为潜在用户特征和潜在商品特征的特征向量,然后使用用户和商品的潜在因子向量的乘积来表示预测评分.BaisedMF[6]在BasicMF的基础上引入了用户和商品的偏差值来提升推荐精度.SVD++[6]在BiasedMF的基础上引入了显式反馈和隐式反馈来提升预测精度.
在引入社交网络之后,推荐方法的预测精度也得到提升.社交网络可以分为基于信任机制和基于朋友机制的网络.信任机制网络是单向且不对称的,但朋友机制的网络是双向且对称的.目前大部分社交网络推荐模型都是在基于矩阵分解模型上的改进方法.在相关论文中,CircleCon[3]在不同社交圈下根据用户在圈内的评分数及用户之间的共同评分来计算用户之间的信任值.TrustMF[7]指出社交网络中的用户不仅受到其他用户的影响同时也影响其他用户这一前提,将社交信任信息划分为信任空间和受信空间.MFC[8]引入交叉社区的概念,用户特征向量应接近与其所在社区的特征向量或其所在社区内其他用户的特征向量.
消费者是否购买及评价好坏也受到商品的某些属性的影响[9].并且在获取难度上,属性信息获取相对于社交数据以及评分数据上更加容易,并且相较于隐式信息来说其含义更加明确.但上述文献忽略属性信息的存在.针对这个问题,胡新明[10]给出了三种方法(基于商品属性效用叠加推荐、基于神经网络属性推荐及基于属性的协同过滤推荐).基于商品属性效用叠加推荐使用TF-IDF[11]算法获得用户对每个商品属性值的偏好权重,然后将各个属性值的偏好叠加获得最终的预测评分.这种方法采用的用户属性值偏好是固定,而且没有考虑到属性之间的交互情况.基于神经网络属性推荐采用神经网络来拟合用户、商品属性值及评分值关系,这种方法计算复杂度高.基于属性的协同过滤推荐算法将属性关系加入到相似度计算过程中,这种方法在计算属性的相似度和评分的相似度之后会导致整体预测效果下降.郑麟等[12]在商品效用叠加推荐方法的基础,考虑到各属性之间相互作用关系,减少盲目交互带来的消极影响.该论文从用户、商品与属性类型三种方面分别与属性进行交互,使得属性用户偏好、商品关联与类型特征相适应,并使用局部采样的方法有效挖掘出有用特征.然而,上述的文献中用户对属性偏好都是固定的,并且没有从评分数据中挖掘用户更好的偏好信息.笔者算法在属性信息和评分数据上构建模型以自学习属性偏好.该方法相较于属性效用叠加推荐的固定属性权重考虑拥有相同属性用户的个体差异,较之于神经网络的属性模型在复杂度上简单,与属性协同过滤模型采用属性信息和评分信息计算相似度后再执行协同过滤,在运行时间上较快.笔者模型简单、训练速度较快,并在评分数据稀疏时能提升预测精度.
2 建模基本概念
2.1 基本术语
在相关理论中,用户信息中的评分数据是使用评分矩阵来描述.评分矩阵R∈Rn×m由n个用户和m个商品组成,其中元素ruj为用户u对商品j的评分,评分矩阵一般只有少量实际用户评分.
属性信息分为用户属性和商品属性,每个属性可能有一个或多个属性值,比如性别的属性值有男、女.用户对商品具有评分,属性值对商品也有相应的评分.该评分可以通过所有包含该属性值的用户对商品的平均评分来进行表示.
2.2 基本矩阵分解模型
基本矩阵分解方法BasicMF[5]将用户和商品的评分矩阵映射到由一群潜在因子组成的向量空间.用户和商品可以用该潜在空间中的潜在因子向量进行表示.该方法使用用户潜在因子和商品潜在因子向量的内积来表示用户对商品的预测评分.该模型[5]为
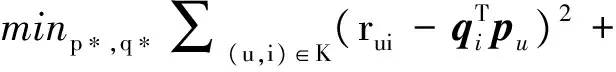
(1)
式中:K为训练集中rui已知的用户物品对(u,i)的集合;pu为用户u的潜在因子向量;qi为商品i的潜在因子向量;P和Q分别为用户和商品潜在因子矩阵;‖P‖2,‖Q‖2为Frobenius范式,其计算式为
(2)
λ(‖P‖2+‖Q‖2)部分用于避免过度拟合.该模型可设定相应的潜在因子数量后进行梯度递减迭代进行训练得到模型参数.
3 属性偏好自学习
首先对预测评分模型进行建模,然后给出模型的训练公式和算法流程.
3.1 预测评分模型
首先给出模型基本假设及属性评分计算方法,然后给出在各种属性信息(单属性值属性、多属性值属性及标签数据)下的预测评分公式.
3.1.1 模型假设
假设每个用户对商品的评分取决于其各个属性,并且每个用户可以对自己的属性中属性值表示相应的偏好程度(喜爱或厌恶).用户对物品的预测评分可以根据用户对自己属性下属性值的偏好程度和属性值对商品的平均评分的乘积得到.
该假设将用户属性看成一个个虚拟信任用户,然后使用用户对属性的信任程度(偏好)与信任用户(属性)对商品评分的乘积来预测用户对商品的评分,如图1所示.
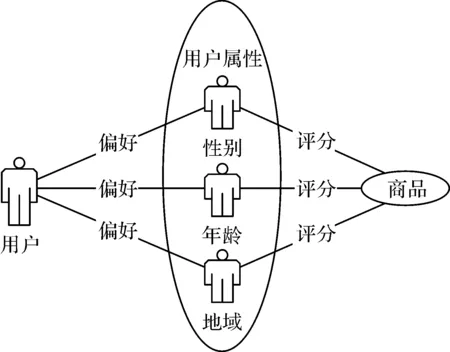
图1 用户预测评分组成Fig.1 Composition of user predict rating
3.1.2 属性值评分
传统方法使用平均评分来表示属性值对物品的真实评分.当平均评分的平均数量过少或没有时,传统方法就不能很好体现用户真实评分.为此,模型使用加权平均评分来表示属性值评分.其定义为
(3)
α=nyj/(nyj+w)
(4)
β=(1-α)nxj/(nxj+w)
(5)
γ=1-α-β
(6)
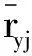
3.1.3 实例说明
针对上述模型假设,下面结合例子进行说明.
假设用户Mary的性别为女,职业为软件工程师,并且Mary的评分仅与性别和职业这两个属性有关,而且Mary对这两个属性的偏好程度分别为0.3,0.7.
假设女性用户会对商品j评分为3,工程师用户对商品j评分为4,则Mary对商品j的预测评分为
0.3×3+0.7×4=3.7.
3.1.4 单属性值属性
单属性值属性包含一个属性值,其预测评分较为简单.其定义如下:
假设用户属性数量为n′,用户属性偏好矩阵C∈Rn×n′,其中元素cuy∈[-1,1]表示用户u对属性x下的属性值y的偏好程度.当属性只有唯一属性值时,其预测评分表示为
(7)
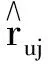
3.1.5 多属性值属性
多属性值属性包含多个属性值,对单属性值的预测评分公式进行扩展,其预测评分为
(8)
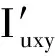
3.1.6 标签数据
标签数据是一种特殊属性,与传统的属性单向关联不同,标签数据是双向关联.标签数据是单属性值的一种特殊情况,其属性值和属性是相同.假设标签数量为k′,其预测评分为
(9)

3.2 训练模型
根据上述预测评分模型,本节提出了用户属性自学习模型UP和商品属性自学习模型IP模型.
这里首先定义模型训练所需损失函数的基本形式,然后对属性值评分进行改进,并在损失函数中加入相应正规化项以避免过度拟合,最后给出UP模型定义、算法流程.
3.2.1 损失函数
模型使用最小平方距离定义预测评分和实际评分的误差,并通过损失函数来学习用户属性偏好矩阵.定义损失函数为
(10)

3.2.2 正规化处理
通过正规化项来避免在模型过度拟合的情况.
首先,由于模型在训练中只对有购买过商品的用户的属性值偏好进行学习.故当用户购买历史中用户属性值所对应的商品数量过少时,用户对其属性值偏好程度占总偏好程度应该低.故正规项定义为
(11)
式中:λ为正规化基本常数;nyj为属性值所对应的商品j的次数;w为特定收缩常数.该式在属性值所对应的商品数量少时压制用户对属性值的偏好程度cuy上升.
此外,模型采用的是偏好程度与属性值评分的乘积来表示预测评分.因此模型在训练时需要保证一个隐式约束,使得用户对其所有属性下的属性值偏好的总和应在1的左右浮动,而不是远远超过或小于1.故第二个正规项为
(12)
3.2.3 用户属性偏好自学习模型(UP)
结合前面提出的属性偏好模型、属性值评分和正规化项,UP模型损失函数可定义为
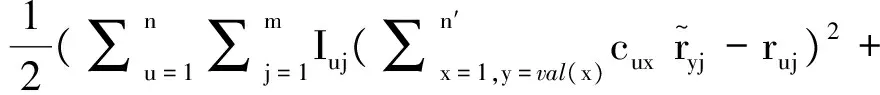
(13)
式中:正规化项Auy,Bu的定义见式(11,12),梯度递减模型的偏导为
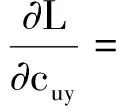
(14)
(15)
然后分别对cuy执行式(15)并且同时调整学习因子θ直至收敛.算法的伪代码描述如下:
输入 评分矩阵R,属性信息
输出 用户属性偏好矩阵C
1) Fori=1 to迭代次数
2)L=0
3) For(用户u,物品j)∈R
5) Foryin用户u的属性值集合
8) End
10)L=err×err
11) Foryin用户u的属性值集合
12)cux=cux-θ×(∂L/∂cux)
13)L=L+∑Auy+∑Bu
14) End
15) End
16)L=L×0.5
17) 动态调整θ以达到收敛
18) End
3.2.4 物品属性偏好自学习模型(IP)
通过转换角度,可假设物品购买用户而不是传统的用户购买物品,就可以得到物品属性优化模型.该模型实际上是用户对物品属性的偏好程度.其定义如下:
假设物品属性数量为m′,物品属性偏好矩阵为D∈Rm×m′,其元素djx为物品j对其物品属性x的信任程度.其评分预测为
(16)
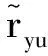
(17)

3.2.5 时间复杂度
在时间复杂度上,模型复杂度为O(nmkh),其中:h为模型中属性值的数量;k为潜在因子数量;n为用户数量;m为物品数量.其时间复杂度优于基于用户或物品相似度的UserKNN的O(m2n)及ItemKNN的O(n2m),接近与基本矩阵模型的迭代学习O(nmk).
在本算法中,当属性含有非常多的属性值时,这种情况导致相应的属性偏好矩阵C,D的维数过大.而且属性信息也存在着冷启动问题的问题.这些问题都会导致推荐精度不高且复杂度高.为此,筛选其中评分数量较多的属性值加入模型中以减少维数.
4 实 验
这里先介绍两大实验数据集,然后对数据集进行稀疏性分析,再给出实验方案,最后对笔者算法和其他算法的进行实验比较.
4.1 实验数据集
4.1.1 Yelp数据集
Yelp为美国商户点评网站,用户可以在Yelp上给商户评分、评论等.该数据集(Yelp第7轮数据集挑战)包含商户的所在地址、城市和分类,用户的评分数量、朋友信息及用户对商户的消费评分、评论等信息.该数据集(表1)包含36万用户和6万商户(剔除没有评分的商户)及152万评分信息(多次重复消费评分只选取其第一次评分).实验中所采用的属性信息为商户的分类(共781种)及城市信息(共372个).
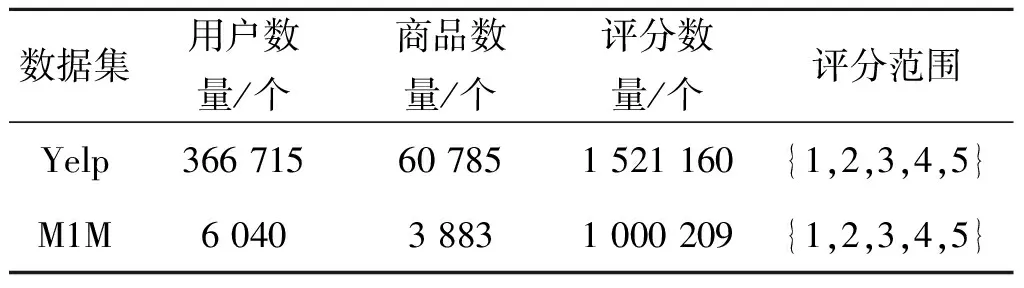
表1 实验数据集Table 1 The experiment dataset
4.1.2 MovieLens-1m数据集(M1M)
MovieLen数据集[13-15]为用户电影评价数据集,实验数据集(表1)包含了100万的匿名评分(五分制),其中有3 952部电影及6 040个用户.用户信息包含用户ID、性别、年龄、职业和邮政编号,电影属性包含电影ID、电影名和分类.其中年龄被分成小于18,18~24,25~34,35~44,45~49,50~55,56+这些分段,职业也有很多类型,电影的分类有动画片、儿童剧、喜剧、犯罪和纪录片等.
4.2 稀疏性分析
4.2.1 评分数据稀疏性分析
图2,3分别绘制出评分数量为0~50+的用户和物品评分数量的分布.出于显示效果的考虑,图2,3只给出在0~800+的用户数量和商品数量.其中Yelp中用户评分数量大部分(97%)小于20(存在用户冷启动问题),而M1M中用户评分数量都大于20(不存在物品冷启动问题).另外,Yelp中商品的评分数量大部分(75.8%)小于20(物品冷启动问题),而M1M中商品评分数量较多,评分数量小于20的物品数仅占17.9%.
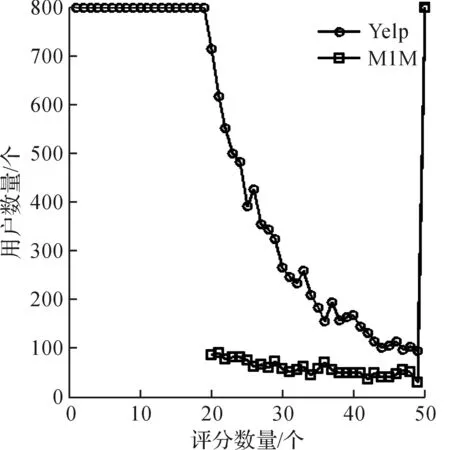
图2 用户评分数量稀疏性分析Fig.2 Sparse analysis of user rating number
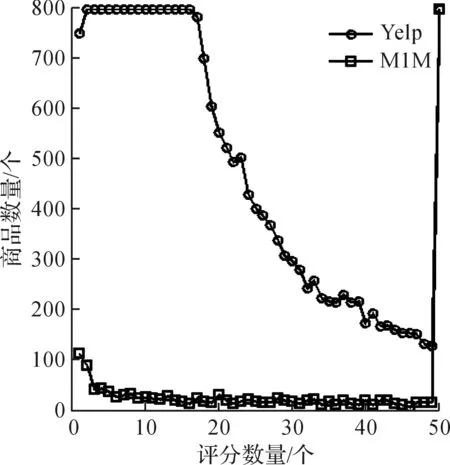
图3 商品评分数量稀疏性分析Fig.3 Sparse analysis of item ratings number
4.2.2 属性评分稀疏性分析
图4,5分别给出了Yelp和M1M中属性对(即属性值和商品或用户的二元组)评分数量分布的稀疏性分析.出于显示效果的考虑,图4,5只给出在0~800+的属性对数量.在图4中,Yelp商品属性中城市属性对评分数量小于10的占总的属性对数量的99.98%,分类信息占99.99%,两个属性评分分布非常稀疏.出于显示效果的考虑,图5将M1M中用户属性和商品属性合并在一起,其中性别、年龄、职业和地域为用户属性,分类是商品属性.在图5中,M1M中属性评分数量小于10的百分比分别为性别21.8%,年龄49.1%,职业68.7%,地域100%,分类60.0%.性别属性评分分布稀疏度低,年龄、职业和分类稀疏度较高,地域的稀疏度非常高.
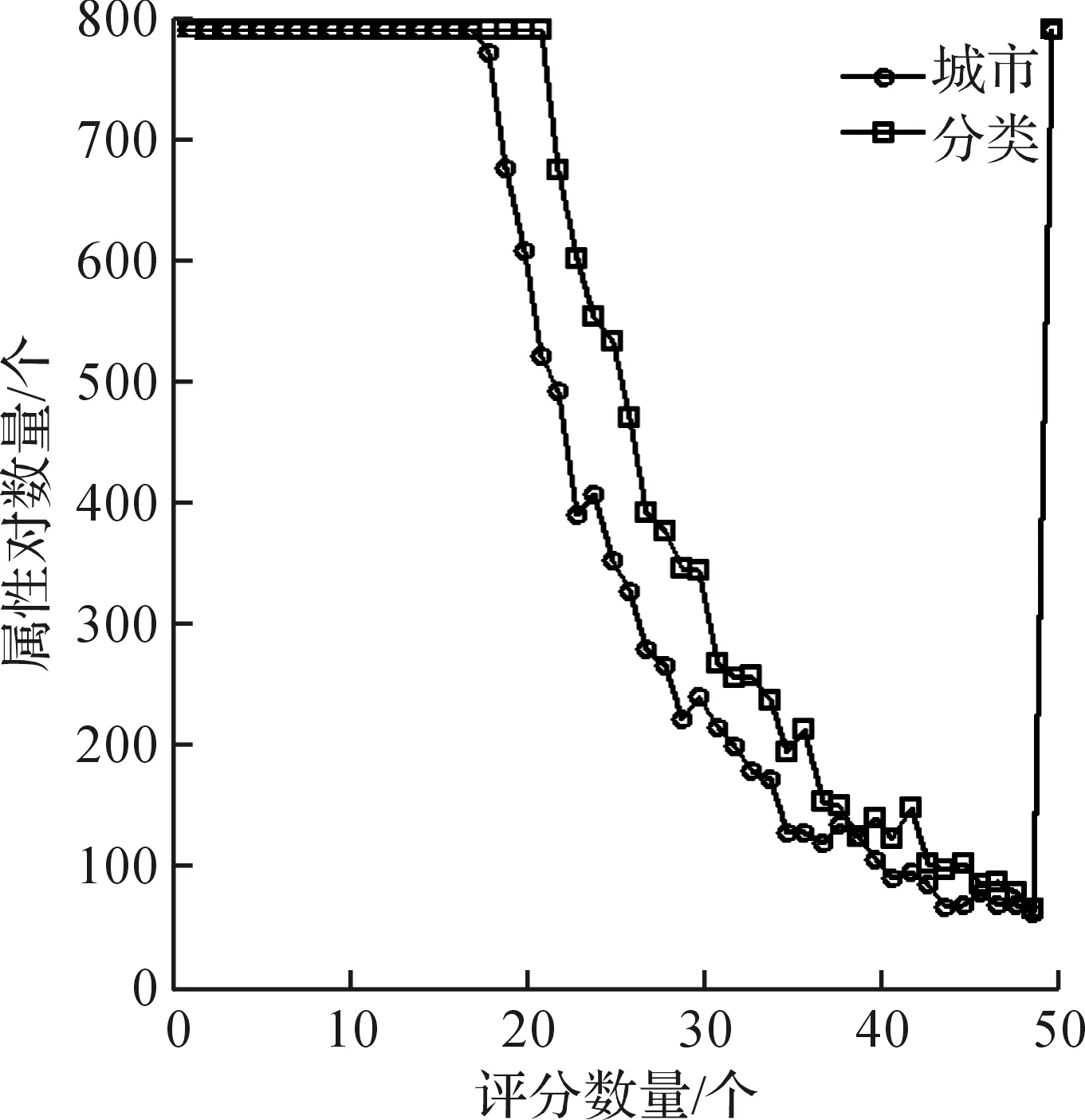
图4 Yelp属性对评分数量稀疏性分析Fig.4 Sparse analysis of yelp attributes pairs
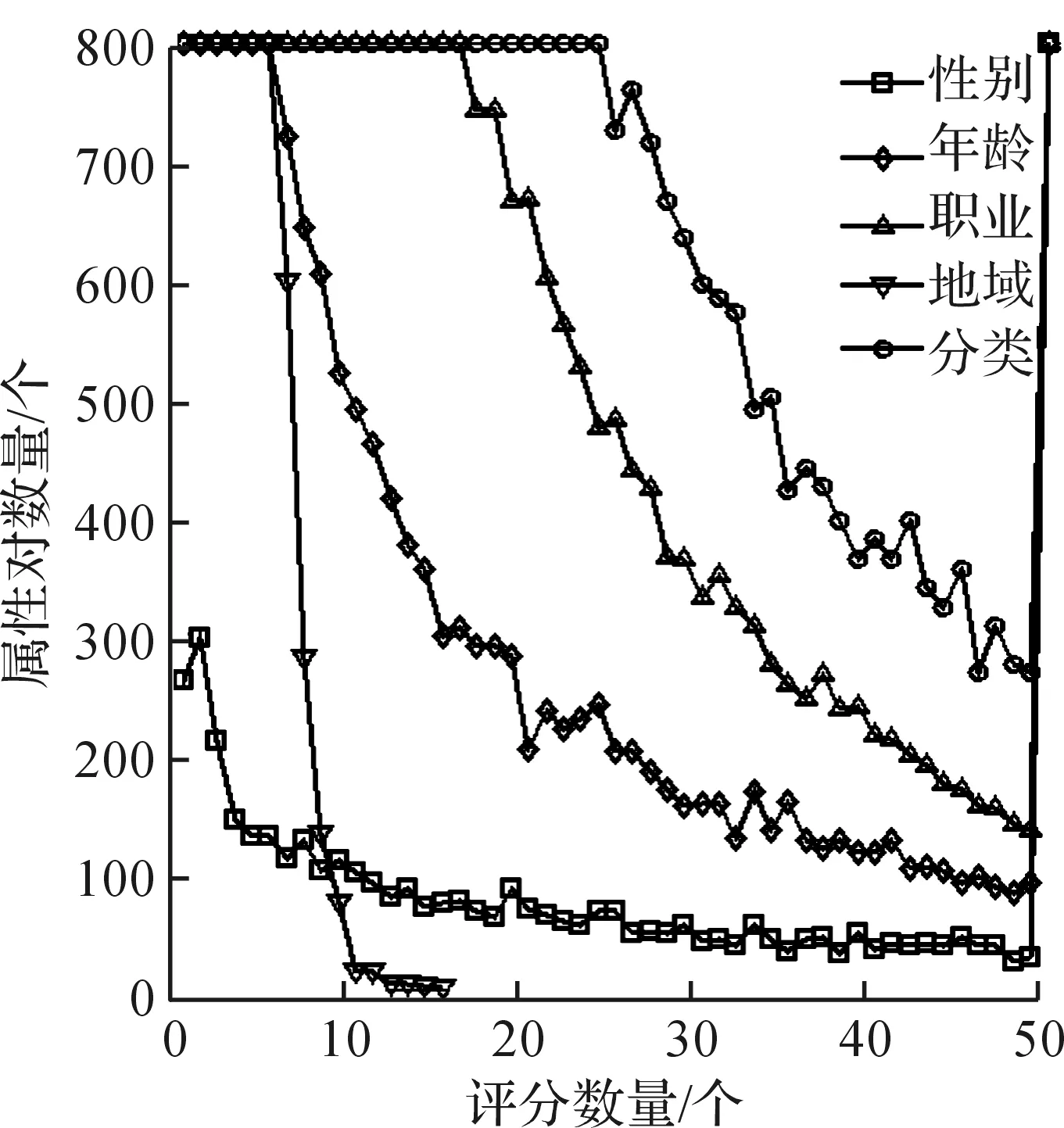
图5 M1M属性对评分数量稀疏性分析Fig.5 Sparse analysis of M1M attributes pairs
4.3 实验方案
实验使用MAE和RMSE来评估预测精度.MAE和RMSE分别通过预测评分和实际评分的误差的绝对值、平方值来表示预测精度.其计算式定义为
(18)
(19)
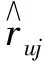
4.4 实验验证
首先将数据集按4︰1随机划分训练集和测试集.在训练集上进行模型训练,在测试集上进行模型测试.记录模型算法的5次运行(训练+测试)得到MAE和RMSE,使用预测指标平均值来表示实验结果.模型的训练迭代次数为200次,学习系数θ初始值为0.01,潜在因子数量都设为10.
4.4.1 Yelp数据集
在Yelp数据集中,固定参数λα=0.3,λb=1.0,w=20,分别对城市、分类及城市+分类执行IP模型(表2).分类的属性值共781个,城市属性值共371个.在两者属性评分分布稀疏性相差不大(图4)时,分类的属性值较多,故其预测效果好于城市属性的效果.当结合两者属性时,IP模型取得了更好的RMSE.

表2 Yelp属性IP模型结果Table 2 The RMSE result of yelp attributes
4.4.2 M1M数据集
在M1M数据集中,固定参数λa=0.05,λb=0.001,w=10,对用户属性执行UP模型,对商品属性执行IP模型(表3).

表3 M1M属性UP模型RMSE结果Table 3 The RMSE result of M1M user attributes
用户属性的属性值数量分别为性别2个、年龄7个、职业21个和地域3 403个.性别的属性值评分分布相较于其他属性更加稠密(图5),但其属性值数量少,所以预测精度与属性年龄、职业相差不大.对于地域属性,其属性值数量为3 403,数量最大,但其属性评分分布稀疏性非常高(图5),所以其RMSE最低.当结合所有用户属性进行训练的预测精度为0.917,其预测精度偏向与用户属性中较优预测精度,且不受预测精度低的地域属性影响.
4.4.3 算法比较
表4为BasicMF,ItemKNN,UserKNN与笔者的UP,IP的配置参数列表.表5为预测精度比较结果.
在Yelp数据集上,BasicMF,ItemKNN,UserKNN的表现低于笔者算法的预测精度(表5),这是由于Yelp中评分数据较为稀疏.笔者算法利用属性信息在评分数据稀疏下结合属性信息对预测精度进行了提升.在M1M数据集中,评分数据稠密,BasicMF,ItemKNN,UserKNN的预测精度较高,笔者的预测精度较为接近UserKNN的预测效果.
表6为M1M数据集下各算法的运行一次的训练、测试时间(迭代次数为100)比较.算法运行所在的测试机的运行环境为Window7 64位,内存4 G,CPU为Intel Core i3,jdk8,eclipse 4.5.2.
笔者的算法在运行时间(训练时间+测试时间,其比较见表4)上优于UserKNN,ItemKNN,并接近与BasicMF的运行时间,与算法复杂度分析相符,如表5所示.

表4 算法参数设定Table 4 Algorithm parameters setting

表5 算法预测精度RMSE比较Table 5 Comparison of algorithm predictive precision

表6 算法运行时间比较Table 6 Comparison of algorithm running time s
5 结 论
笔者算法结合UserKNN,ItemKNN,BasicMF优点,具有可解释性且模型训练速度较快,并在评分稀疏时较UserKNN,ItemKNN,BasicMF预测精度高.笔者算法类似于基于内容的推荐方法,但笔者算法从属性信息和评分数据中自学习属性偏好,而不需像基于内容推荐方法那样人工调整偏好.属性信息的获取上较之其他信息更加容易.由于属性优化的好坏取决于属性的属性值数量和属性评分分布稀疏程度,后续将研究如何对相关属性进行聚类以减轻属性值评分的稀疏性情况.
[1] RICCI F, ROKACH L, SHAPIRA B, et al.Recommend system handbook[M]. New York:Springer US,2011:4-7.
[2] GUO G, ZHANG J, YORKE-SMITH N. TrustSVD: collaborative filtering with both the explicit and implicit influence of user trust and of item ratings[C]//Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence. Austin Texas: AAAI,2015:123-129.
[3] YANG X, GUO Y, LIU Y, et al. A survey of collaborative filtering based social recommender systems[J]. Computer communications,2013,41(5):1-10.
[4] SALAKHUTDINOV R, MNIH A. Probabilistic Matrix Factorization[C]//Advances in Neural Information Processing Systems. Vancouver: NIPS,2007:1257-1264.
[5] KOREN Y, BELL R, VOLINSKY C. Matrix factorization techniques for recommender systems[J]. Computer,2009(8):30-37.
[6] KOREN Y. Factorization meets the neighborhood: a multifaceted collaborative filtering model[C]//Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining. Las Vegas: ACM,2008:426-434.
[7] YANG B, LEI Y, LIU D, et al. Social collaborative filtering by trust[C]//Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence. Washington: AAAI,2013:2747-2753.
[8] LI H, WU D, TANG W, et al. Overlapping community regularization for rating prediction in social recommender systems[C]//Proceedings of the 9th ACM Conference on Recommender Systems. Vienna:ACM,2015:27-34.
[9] 陆奇斌,赵平,王高,等.消费者满意度测量中的光环效应[J].心理学报,2005,37(4):524-534.
[10] 胡新明.基于商品属性的电子商务推荐系统研究[D].武汉:华中科技大学,2012.
[11] 刘端阳,王良芳.基于语义词典和词汇链的关键词提取算法[J].浙江工业大学学报,2013,41(5):545-551.
[12] 郑麟,朱福喜,姚杏.基于属性提升与局部采样的推荐评分预测[J].计算机学报,2016,39(8):1501-1514.
[13] HARPER F M, KONSTAN J A. The movielens datasets: history and context[C]//The Problem of the Southern Sudan. Oxford: Oxford University Press,1963:1068-1074.
[14] 孟利民,赵维,应颂翔.评分预测问题中个性化推荐模型的研究[J].浙江工业大学学报,2016,44(2):119-123.
[15] 龙胜春,傅佳琪,尧丽君.改进型k-means算法在肠癌病理图像分割中的应用[J].浙江工业大学学报,2014,42(5):581-585.
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:42
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
现代防御技术(2016年1期)2016-06-01 12:13:27
小猕猴智力画刊(2016年6期)2016-05-14 21:40:48
