
视觉感知启发的面向出舱活动的物体识别技术研究
2018-03-22 01:11:26张菊莉贺占庄周革强何双亮
载人航天 2018年1期
张菊莉,马 钟,贺占庄,周革强,何双亮
(1.西安微电子技术研究所,西安710065;2.中国航天员科研训练中心,北京100094)
1 引言
出舱活动(Extravehicular Activity,EVA)是一种由航天员着舱外服在远离地球大气层的舱外完成的活动[1]。它是载人航天三大关键技术之一,是载人航天工程在轨安装设备、检查和维修航天器的重要手段。
出舱活动通常意味着更具挑战、困难和危险的任务。因此提高出舱活动任务的工效,对出舱活动的成功执行,以及未来执行更复杂的出舱任务有着重要的意义。而影响出舱活动工效的一个重要因素是航天员出舱后能否快速地识别与定位要操作的物体。为提高出舱活动的工效,将能够自动识别舱外物体的智能化视觉感知系统集成到航天员的舱外航天服中,是未来智能化、信息化载人航天技术的一个趋势。而智能化、信息化的视觉感知系统如何进行舱外物体的识别也是一个极具挑战性的问题。
传统的物体识别方法首先对图像进行疑似物体区域的一般对象估计,然后根据估计结果进行相应的类别分类与识别。通常一般对象估计多采用滑动窗口等方法来提取相应的鲁棒性特征,该方法过程繁琐,计算量大。程明明等[2]提出对象估计领域的一种高效的检测方法,并被应用在相关领域中[3⁃4],且取得了较好的分类结果。 赵旦峰等[3]采用高斯差分方法对图像边缘特征进行增强,并级联Boost方法进行得分策略优化,取得了较好的分类结果,但其在一定程度上也增加了原方法的时间复杂度。 当前卷积神经网络方法 R⁃CNN[5]、FastR⁃CNN[6]和 Faster R⁃CNN[7]使用选择性搜索而非滑动窗口来提取图像特征。但即使在快速模式下,选择性搜索大约需要2 s来提取特征区域,时间上难以容忍。针对宇航员舱外活动的时间性要求,在对要识别区域的图像进行特征提取时,须选择耗时小、效率高的方法。
众所周知,人类视觉感知系统可以从复杂的背景中快速而准确地识别出物体种类及位置。在出舱活动时,复杂的太空环境,如强光照等都会增加物体识别的难度。因此,为排除复杂环境中的干扰,快速识别并定位物体,本文提出一种基于航天员视觉感知的物体识别方法。方法为加快识别速度,加入了航天员的视觉观察,即直接以宇航员的视觉注视点一定范围内的图像区域作为感兴趣区域,采用耗时小、效率高的二值化赋范梯度方法对感兴趣区域进行特征提取,然后由具有强大分类能力的深度卷积神经网络结合提取到的特征进行识别与精定位。
2 基于视觉感知启发的物体识别总体方案设计
为提高航天员出舱活动的工效及智能化、信息化水平,在航天员的头盔中集成眼动追踪设备、图像采集设备及综合信息推送显示设备等,算法的处理单元作为综合信息处理单元的一部分集成在航天服的中央处理单元中。头盔原型设计如图1所示。

图1 航天员头盔原型Fig.1 Prototype of astronaut helmet
应用时,首先由头盔中的眼动追踪设备对航天员眼部活动进行扫描,获取目光注视点,由综合信息处理单元开启图像采集设备对注视时间超过100 ms的一定范围的区域进行图像采集,然后调用识别算法对采集到的图像进行识别。
识别算法首先对采集到的图像进行二值化赋范梯度特征提取,由于图像采集的角度及距离等因素,通常对于一个较大的物体,采集的图像往往不能完全覆盖物体的全部或者绝大部分,从而对物体识别的准确率存在一定的影响。因此在这里考虑选取比提取的特征区域大的图像区域输入到深度神经网络中进行分类识别与精定位,最后将识别结果推送到航天员头盔中的显示设备上。总体的识别方案流程如图2所示。
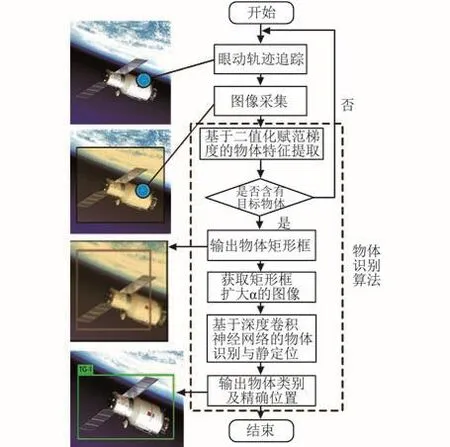
图2 基于视觉感知的物体识别算法流程Fig.2 Flowchart of object detection inspired by visu⁃al perception
2.1 基于二值化赋范梯度的物体特征提取
人类视觉感知系统只需对物体的整体轮廓进行判断,就可以分辨物体的类别。程明明等[2]分析发现,在一幅图像中,一般物体都会有定义完好的封闭轮廓,从而与背景区域相区别。受此启发,将图像缩小到一定大小,并计算图像的二值化赋范梯度,对梯度进行分析发现,图像中物体的赋范梯度幅度变化很小,而背景的变化幅度比较大,从而通过对抽象图的分析就可以判断出哪是物体。在设计算法时,将采集到的图像窗口重置为固定大小,并计算二值化赋范梯度,并将梯度幅值转化为64维的特征向量,利用64位数据类型存储,在一定程度上压缩了数据量,同时达到快速处理的目的。然后通过两次支持向量机(Support Vector Machine,SVM)训练赋范梯度特征,得到目标和背景的区分模型。第一次SVM训练获得整体的物体模型后,用匹配算法及非极大值抑制算法预测所有可能包含真实物体的候选窗口,再针对这些候选窗口进行第二次SVM训练,获得候选特征窗口的得分,选择得分最高的窗口作为物体特征窗口。每个窗口可通过一个训练好的线性模型w∈RR64获得得分,如式(1)、(2)所示:
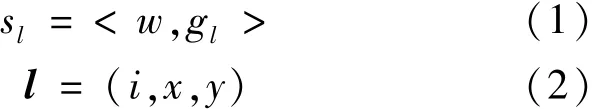
其中,sl代表窗口得分,gl代表赋范梯度特征,公式(1)表示窗口的得分可以通过训练好的线性模型w∈R R64与赋范梯度特征gl的向量内积获得,得分越高,越接近目标。公式(2)中l表示窗口坐标及其尺度,i表示尺度大小,(x,y)表示窗口位置。再运用非极大抑制方法,为每个尺度提供一些建议特征,过滤掉包含物体可能性很小的特征窗口,选取得分最高的窗口作为物体特征窗口。算法流程图如图3所示。
2.2 基于深度卷积神经网络的物体识别与精定位
近年来,深度卷积神经网络强大的特征提取能力[5⁃8]使得物体识别似乎变得更简单了。但神经网络计算量大、参数多等问题也导致要实现实时的物体识别并不容易。Redmon等[9]作者将物体识别问题看作回归问题,采用卷积神经网络直接进行特征提取、识别与定位,可实现快速的物体识别。

图3 基于二值化赋范梯度的物体特征提取流程Fig.3 Flowchart of object feature extractionbased on binarized normed gradient
受此启示,基于视觉感知的物体识别方法借鉴了其将识别问题当作回归问题的思想,直接将二值化赋范梯度提取的特征图输入到深度神经网络中,由其计算相应类别概率及位置的置信度。
识别时,卷积神经网络将输入图像缩放为418×418,并分割成3×3的网格,每个网格负责预测2个矩形框,每一个预测的矩形框包括5个预测值:x、y、w、h、confidence。 其中(x,y)表示框的中心坐标,w和h分别代表矩形框的宽和高。卷积神经网络提取到的特征区域与二值化赋范梯度提取的特征区域进行重叠率的比较,选择重叠率最大的区域作为识别出的物体的最终位置。
同时,每个网格还预测物体相对于所有类别的条件概率,即该网格包含某物体的可能性。算法选择概率值最大的类别作为物体的类别。

图4 基于深度卷积神经网络的物体识别与精定位Fig.4 Object detection and accurate location by deep CNN
算法的识别与精定位过程如图4所示。图中第四幅图中绿色有标签的矩形框为物体的最终位置,标签为类别名。
神经网络训练时采用的损失函数如式(3):

式中:p1、p2是坐标预测,p3预测含有物体的矩形框的置信度,p4预测不含物体的矩形框的置信度,p5是类别预测,如式(4) ~(8):

上述公式中,S为网格数,B为每个网格要预测的矩形框数量,C为要预测的种类数,λcoord为坐标预测时的损失权值,λnoobj为没有物体时的损失权值,为第i个网络中的第j个矩形框不含物体的概率,用于判断第i个网络中的第j个矩形框是否负责预测这个物体,classes为全部可预测物体。
在损失函数中,当网格中有物体时,但分类预测错误时,则加大分类错误的损失。而当网格预测的矩形框与实际标注的矩形框重叠率越小,损失越大。在训练过程中,通过损失函数不断调整权重参数,最终学习到最适合本数据集的神经网络模型,以供在物体识别时使用。
3 实验验证
3.1 数据集建立
提出的识别算法中的二值化赋范梯度特征提取及深度卷积神经网络识别都需要预先在数据集上进行训练得到相应的模型,以在航天员出舱时实时地进行物体识别。为模拟航天员在舱外看到的部分物体,建立了包含7个类别的数据集,包括天宫一号、神舟八号载人飞船、国际空间站、Apol⁃lo三维模型图片等,原始图像共517幅,通过标注软件进行人工标注,标注信息包括物体类别和物体位置等,最后生成“.xml”格式的标注文件。由于有标注的数据较少,为了增强现有方法对目标旋转的鲁棒性,对数据进行了增殖。具体方法为:首先对原图水平镜像,得到一幅新图,然后对原图及新图分别进行3次旋转,每次旋转90°,共计得到7幅新图。整个处理方法的流程如图5所示。

图5 数据扩增方法Fig.5 Data augment
经数据扩增之后,原始数据集由517幅图像增加到4136幅,其中60%作为训练集,其余作为测试验证数据集。
3.2 模型训练
3.2.1 基于二值化赋范梯度算法的模型训练
训练时,利用一款针对SVM的开源的集成开发库LIBLINEAR库[10]来增强算法的处理速度。算法首先加载图像标注信息,然后再进行两个阶段的SVM的训练,训练过程如下:
首先,对每张训练图像进行不同的尺度变换,在每个尺度下计算梯度,根据预测得分机制,计算每个尺度下的二值化赋范梯度特征及得分,排序后利用非极大抑制方法消除掉最高分附近的得分值;然后,在原始图像上找到对应得分点对应的矩形框并保存;最后,将所有预测的矩形框与原始图像中所有有效正样本做重叠率比对,一旦有一个正样本框与该预测矩形框重叠率大于50%,则将该可能矩形框作为正样本,否则为负样本。在第二级训练时,针对每个尺度训练一次,训练结束后,生成新的权值模型供测试使用。
3.2.2 基于深度卷积神经网络的模型训练
基于深度卷积神经网络的模型训练采用Im⁃ageNet模型作为预训练模型以加快模型的收敛速度。训练样本同为上述样本。训练采用基于反向传播的随机梯度下降算法进行学习,训练迭代次数预设为100 000次,训练过程中可以随时停止,每1000次保存一次模型参数,学习率为0.000 05,动量为0.9。迭代次数大概为20 000次时,模型收敛,错误率在0.09。
3.3 原理验证平台搭建
为验证算法的识别效率,搭建硬件平台及实现测试软件对识别算法进行模拟验证。
为模拟捕获航天员眼动信息的场景,将TO⁃BII眼动仪连接在计算机USB端口采集人眼信息。首先由人眼注视计算机屏幕显示的图片,将目光停留时间大于100 ms时的区域视为感兴趣区域,然后测试软件以人眼注视点为中心选取一定范围的图像区域,由识别算法进行处理,最后输出识别结果。验证环境搭建如图6所示。

图6 验证平台Fig.6 Verification platform
图6 中,由眼动仪获取人眼信息,蓝色圆型区域代表人眼的注视点,红色和绿色有标签的矩形框分别表示注视点移动到不同对象上时的物体识别结果,不同颜色的矩形框代表不同的物体类别。
3.4 软件实现与识别结果
算法为模拟航天员出舱活动中视觉运动,采用眼动仪追踪人眼的眼动轨迹。眼动仪放置在计算机屏幕下方能够采集到眼动数据的位置,并进行固定。实验时人眼注视计算机屏幕,眼动仪进行眼动扫描,软件选取目光停留时间100 ms以上的一定范围的图像输入到识别算法中进行识别。识别算法首先将采样的人眼感兴趣区域图片进行二值化赋范梯度的特征提取,以判断人眼注视点为背景还是物体。有物体时,提取物体的矩形框,输入到卷积神经网络中进行分类识别与精定位。验证软件实现的流程如图7所示。
在对眼睛注视点进行选取及物体特征区域的预测之后,如果有物体则确定物体的矩形框,选取比物体框扩大α(扩大因子,0<α<1)的图片作为深度卷积神经网络物体识别算法的输入。算法将整幅图像直接输入到卷积神经网络中,进行识别与精定位。图8为基于视觉感知的物体识别算法输出结果。

图7 软件流程Fig.7 Flowchart of software

图8 物体识别输出结果Fig.8 Output of the object detection
图8 中的每一幅图中不同颜色的矩形框代表不同的物体种类,每一个矩形框左上角的字符代表物体所属的类别名称。
软件在实现时,只显示人眼的感兴趣区域图片,然后输出最终的识别结果,如果未识别到感兴趣区域的物体时,只显示感兴趣区域的图片。图8为识别到物体及精定位的最终结果。
3.5 实验结果评估与分析
3.5.1 评估准则
评估识别算法的类别准确性有四个标准[11]:召回率(Recall)、准确率(Precision)、平均准确率(Average Precision,AP)和均值准确率(Mean Av⁃erage Precision,mAP)。
而评估位置的准确性,则通过矩形框A与标注矩形框B之间的IoU(Intersection of Union)重叠率来计算。算法的实时性,则通过每秒处理帧数(FPS)来评估。
在面向出舱活动的物体识别算法中,主要评估了算法的IOU、召回率和平均准确率及时间。以下将自建数据集简称为EVA数据集。
3.5.2 实验结果与分析
表1是算法验证得到的IoU和召回率,表2为验证得到的mAP,表3是本文算法与目前主要卷积神经网络方法的mAP与处理时间的对比,验证样本集有1655幅图片。
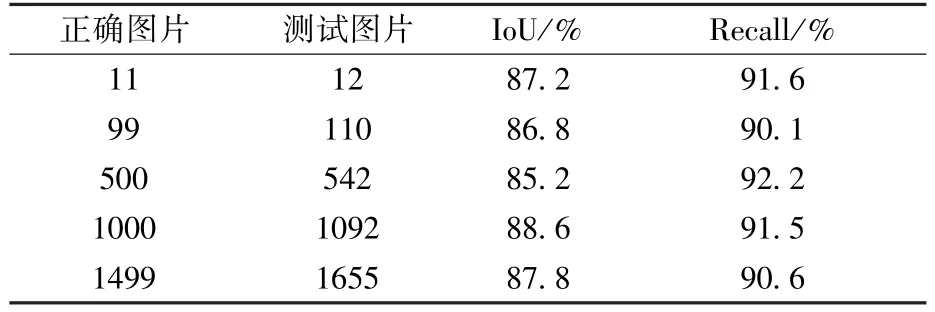
表1 IoU和召回率Table 1 IoU and recall rate

表2 各类别mAP和平均mAPTable 2 mAP of each class and average mAP
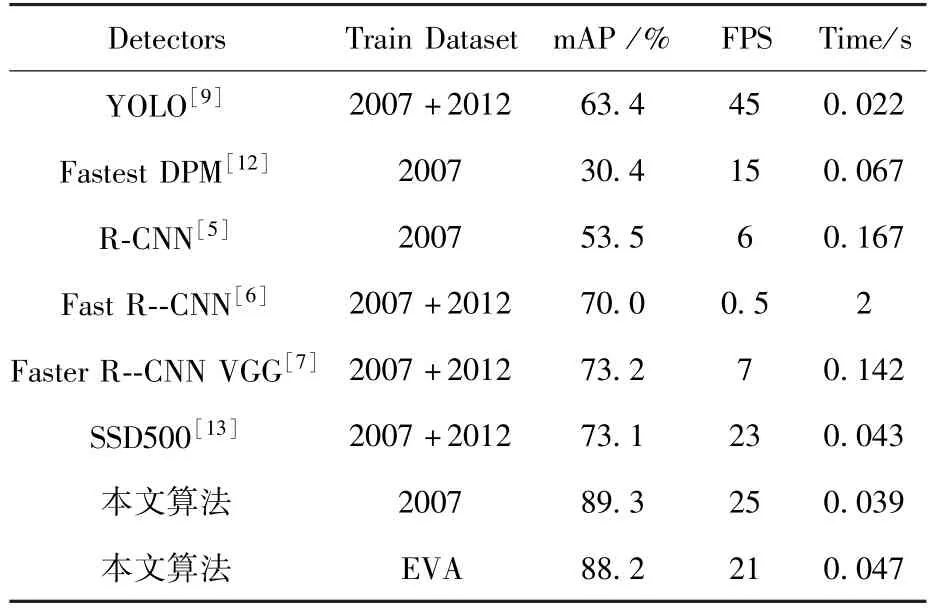
表3 算法与目前主要算法的比较Table 3 Comparison of the algorithm with other main algorithms
从表1和表2中可看出,算法的平均IoU值为87.1%,而召回率则为91.2%,mAP为88.2%。算法在每幅图像平均耗时约0.047 s,可以达到实时识别的结果。表3中,算法的mAP在VOC2007及在EVA数据集上的测试结果表明,该算法比当前主要的基于卷积神经网络的识别算法的mAP还要高一些,分析主要原因在于:一方面算法中加入了人眼对感兴趣区域的选取;另一方面,卷积神经网络直接对二值化赋范梯度算法提取的特征区域进行识别与精定位,因此识别时,输入的图像中已经确定有物体,且特征区域已经被提取,卷积神经网络只需要在此基础上进行分类和定位即可,置信度提高,从而最终的识别准确率也有明显的提高。
在对采集到的图像进行了二值化赋范梯度的特征提取之后,将特征区域回归到原图像中,并在原图中选取比特征区域面积大α的区域,α分别选取5%、10%、15%、20%、25%、30%,观察其对最终检测准确率的影响。影响曲线如图9所示。

图9 α对mAP的影响Fig.9 The influence of α on mAP
从图中可以看出,扩大因子α在一定范围内可以提高mAP。当α取5%时,由于其扩大非常小,对准确率的影响也很有限,而当扩大至10%时,其有比较明显的准确率提升,但是随着面积的扩大,准确率并不再明显上升。分析原因在于提取特征时,已经基本获取了所采集图像中物体区域,扩大到一定程度时,物体的信息并不会被增强,因而也并不会因为扩大而提升准确率,反而会因为扩大太多,提供了太多干扰信息,造成准确率的下降。
表3展示了本文算法在EVA数据上的静态图片平均识别时间为0.047 s。应用时,总耗时应包括:眼动信息采集时间、图像采集时间、在线识别耗时等。在本模拟实验中,眼动信息采集时间包括:眼动仪获取眼动轨迹信息、选择注视点信息。根据眼动仪手册,眼动仪获取眼动信息的时间大约40 ms,注视时间为100 ms,选择注视点时间约为50 ms,因此眼动信息采集信息大约为190 ms。根据相机的性能,采集时间不等,普通相机大约一帧图像30 ms,加上在线识别耗时大约为47 ms以上,因此总体理论时间大约为267 ms。而在模拟实验中,因采用静态图片,即获取眼动信息后,直接采集注视点图片,测试的总体耗时为300 ms。在实用性和准确率方面,基本可以满足工程应用需求。
4 结论
本文针对航天员出舱活动所面对的特殊环境,提出了一种基于视觉感知启发的物体识别方法。方法以人眼注视点区域作为感兴趣区域输入到识别算法中进行处理,将人的视觉选择性与主动性特性引入算法,提高了算法的识别效率。实验结果证明该方法可以实时而准确地进行舱外物体的识别。但是方法仍然存在一些局限性,需要在后续工作中改进。
在验证方法的准确性时,仅使用眼动仪和通用计算机来测试原理,测试图像只是一些关于航天器和航天员的静态自然图片,实验条件与真实航天服及应用环境差异较大。同时,由于该方法采用卷积神经网络来进行最终的识别与定位,而卷积神经网络需要大量存储空间且计算复杂度很高,因此在模拟验证时用到了GPU来加速神经网络的处理。在实际的航天服中,高存储和复杂计算都较难实现。
针对神经网络模型大、参数多,可通过二值化方法实现CNN模型压缩,降低存储要求和计算复杂度,最终将其整合到航天员的舱外服中。同时,需要设计人机交互软件来显示识别信息及其他信息,并推送到综合信息显示系统中进行显示。更重要的是,针对真实太空环境中的强光照、颜色及纹理的巨大变化,为进一步提高算法的鲁棒性,考虑先对采集图像进行物体边界增强,再采用二值化赋范梯度提取特征,以进一步适应EVA的真实环境。
(
)
[1] Freni P,Botta E M,Randazzo L,et al.Innovative Hand Ex⁃oskeleton Design for Extravehicular Activities in Space[M].Berlin: Springer International Publishing, 2014: 3⁃4.
[2] Cheng M M,Zhang Z,Lin W Y,et al.BING:Binarized normed gradients for objectness estimation at 300fps[C]//IEEE Conference on Computer Vision and Pattern Recogni⁃tion, Columbus, 2014:3286⁃3293.
[3] Zhao D,Hu Y,Gan Z,et al.A novel improved binarized normed gradients based objectness measure through the multi⁃feature learning[C] //International Conference on Image and Graphics, Tianjin, 2015:307⁃320.
[ 4 ] Li X, Hao J, Qin H, et al.Real⁃time fish localization with binarized normed gradients[C] //Oceans, IEEE, Shanghai,2016:1⁃5.
[5 ] Girshick R,Donahue J,Darrell T,et al.Rich feature hierar⁃chies for accurate object detection and semantic segmentation[C] //IEEE Conference on Computer Vision and Pattern Rec⁃ognition, Columbus,2014: 580⁃587.
[ 6 ] Girshick, Ross B.Fast R⁃CNN[C] //IEEE international con⁃ference on computer vision (ICCV), Santiago, 2015:1440⁃1448.
[7] Ren S, Girshick R, Girshick R, et al.Faster R⁃CNN: To⁃wards real⁃time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis& Machine Intel⁃ligence, 2017, 39(6): 1137⁃1149.
[8] Matthew D,Zeiler,Rob Fergus.Visualizing and understand⁃ing convolutional networks[C]//European Conference on Computer Vision, Zurich, 2014: 818⁃833.
[9 ] Redmon J, Divvala S, Girshick R, et al.You only look once: Unified, real⁃time object detection[C] //Proceedings of the IEEE Conference on Computer Vision and Pattern Rec⁃ognition, 2016: 779⁃788.
[10] Fan R E, Chang K W, Hsieh C J, et al.LIBLINEAR: a li⁃brary for large linear classification[J].Journal of Machine Learning Research, 2008, 9(8): 1871⁃1874.
[11] Mao H, Yao S, Tang T, et al.Towards real⁃time object de⁃tection on embedded systems[J].IEEE Transactions on E⁃merging Topics in Computing, 2016, pp(99): 1.
[12] Yan J, Lei Z, Wen L, et al.The fastest deformable part mod⁃el for object detection[C]//Computer Vision and Pattern Recognition, Columbus, 2014:2497⁃2504.
[13] Liu W,Anguelov D,Erhan D,et al.Ssd:Single shot multi⁃box detector[C] //European Conference on Computer Vision,Amsterdam, 2016: 21⁃37.
猜你喜欢
军事文摘(2023年4期)2023-03-22 08:44:26
军事文摘(2022年8期)2022-05-25 13:29:16
数学物理学报(2021年6期)2021-12-21 06:24:38
应用数学(2020年2期)2020-06-24 06:02:50
小哥白尼(趣味科学)(2019年10期)2020-01-18 09:16:14
军事文摘(2019年18期)2019-09-25 08:08:58
沈阳理工大学学报(2019年4期)2019-09-13 01:02:40
科学与技术(2019年3期)2019-03-05 21:24:32
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
电脑知识与技术(2014年9期)2014-05-30 10:48:04
