
基于随机游走的电子商务退货风险预测研究
2018-03-22 01:02刘冠男马宝君
管理科学 2018年1期
刘冠男,张 亮,马宝君
1 北京航空航天大学 经济管理学院,北京 100191 2 北京邮电大学 经济管理学院,北京 100876
引言
近年来,网上购物因其具有方便快捷的属性,已经成为人们的一种生活方式,极大地推动了电子商务的发展。然而,电子商务的虚拟特性使顾客无法获得商品的现场体验,只能依赖于商品描述、照片等媒介,所以顾客对商品的认知容易产生偏差,导致实际产品与需求不一致。在这种情况下,顾客便可能产生退货行为。退货率过高会给制造商和零售商带来巨大的损失,例如零售商必须根据退回产品的情况进行库存调整,带来巨大的运输和返修等成本,制造商可能要调整其生产计划等。有数据表明,在美国,每年因为产品退货产生的成本损失达到上千亿美元[1]。据零售咨询公司统计,电商企业产品的平均退货率高达三分之一。因此,防范电子商务环境中的退货风险是电子商务企业需要高度重视的问题。
实际上,随着大数据分析在商务管理中的深入应用,大多数电子商务企业已经开始重视大数据对于管理的重要意义,并具备了较为成熟的客户关系管理系统、库存管理和销售管理系统,也因此积累了大量的销售、客户和退货记录等数据。但是对于电子商务环境下大规模退货行为模式的分析和研究仍然较缺乏,也难以为管理者提供有效的退货风险预警。
有鉴于此,本研究针对个体用户和产品在电子商务环境下的退货风险进行分析和建模。电子商务的退货环境中包含了用户和产品两种基本的实体类型,因而可以将退货记录构造为二部图,而二部图的结构及节点的排序可以通过定义实体间互相表示的随机游走来发现。基于此,本研究设计了关于用户和产品的随机游走过程,进而将用户和产品的退货风险进行迭代直至收敛。同时,考虑到影响退货的用户以及产品本身的各类因素,提出一种融合特征的退货风险预测方法,并采用真实数据进行实验,验证方法的有效性。
1 相关研究评述
1.1 退货的影响因素
目前针对退货的相关研究主要是从营销和运作管理的角度出发,分析影响退货的各类因素,并且探究不同退货政策对于运营管理的影响。在退货的影响因素研究方面,LI et al.[2]设计了不同的模型检验在线购物中退货政策、商品价格、商品质量对于消费者购买意愿和退货意愿的影响,发现这些要素的影响是相互作用和耦合的;WALSH et al.[3]运用风险理论,通过实验检验退款保证、产品评论和免费退货标签3种工具对用户退货行为的影响,发现退款保证的使用增加了产品的退货率,而产品评论与之相反,降低了产品的退货率,提供免费退货标签对退货行为没有产生显著影响。这些研究说明产品价格、产品质量等产品本身的属性在退货行为的预测中占据着重要的地位。孙永波等[4]通过实证分析研究用户的购买行为与退货行为之间的关联,发现有过退货经历的用户其后续的购买行为是可以被零售商善意“操控”的。这启发研究者可以从用户特质的角度去探讨对退货行为的预测。特别地,DE et al.[5]通过实证方法研究电商平台中信息技术的使用对退货的影响,包括图片、网站排版、文字描述等;FU et al.[6]认为退货的发生是由两种不一致导致的,顾客期望的商品属性与实际的商品属性之间不一致,实际的商品属性与顾客收到的商品属性之间不一致,在此基础上利用带有隐变量的概率矩阵分解预测了交易的退货概率。
在退货政策方面,PASTERNACK[7]研究定价策略和退货政策,提出一种对于短期寿命商品的层次定价模型;张霖霖等[8]将用户的退货行为引入到在线零售企业的单周期和多周期定价订货策略研究中,发现退货率与在线零售企业定价正相关,而与订货量和收益负相关。这些研究都只聚焦于产品价格对于退货的影响,没有很好地探讨其他属性对结果的影响。李勇建等[9]研究在产品需求和消费者产品估价均不确定的情况下,报童零售商的预售策略和无缺陷退货问题,发现最优的退货策略是部分退款退货策略,且最优退货价格为产品的残余价值。但却在模型中忽略了产品需求与产品本身特征和消费者类型之间的联系,类似的缺陷也存在于孙军等[10]的研究中。赵晓敏等[11]着重从产品生命周期的视角探讨不同的退货政策对企业供应链系统运作绩效的影响;MUKHOPADHYAY et al.[12]发现提供友好的退货政策能够增加收入,但同时也会由于高昂的退货和设计费用增加成本,并基于此提出一种优化退货政策的最大化模型;ANDERSON et al.[13]提出一个用来识别最优退货政策的结构化模型,使零售商可以在销售需求和退货成本之间进行取舍。与本研究不同的是,这些关于退货政策的研究都是从较为宏观的角度出发,在电子商务的环境下不容易进行个性化的应用和推广。更进一步地,卢美丽等[14]将退货视为一种促进销售的服务策略,讨论不同商品的服务敏感系数、销量退货率和退货量对于价格敏感系数和最优利润的影响;单汨源等[15]聚焦于退运险这一细分领域,通过构建数学模型分析不提供退运险服务、赠送退货运费险和消费者购买退货运费险3种退货策略下零售商的盈利能力,证明了赠送退货运费险这种策略的有效性。这些研究启发我们在对退货的预测研究中,零售商的服务水平和品牌效应等因素也应当融入到建模过程中。
以上研究一般仅从统计意义上分析影响退货的各类因素,无法针对特定用户对特定商品的退货倾向性进行分析。有鉴于此,本研究从更为微观和个性化的角度出发,挖掘用户在退货过程中的行为模式,进而预测用户对特定商品的退货风险,指导电子商务企业的运营管理实践。
1.2 二部图
现实世界中的许多行为活动都可以转换为二部图结构,如用户购买产品和用户评价等。因而,关于二部图的结构分析和模式发现等研究一直是热点问题。MOONESINGHE et al.[16]基于实体之间的相似性构造二部图,为每个实体分配异常得分,并假设与其他实体之间的关系较少的实体更有可能是异常点;BEUTEL et al.[17]对社交网络中的异常“点赞”行为进行研究,他们将用户与社交网络的页面根据“点赞”关系构造为二部图,并将疑似的非法“点赞”行为定义为一种基于时间的子图结构,从而将问题转化为在二部图中的结构搜索问题。这类异常检测的研究一定程度上证明了二部图的结构可以很有效地对退货这类数据进行建模。ZHU et al.[18]通过构建用户和产生内容的二部图,利用随机游走的方法研究社交网络中用户影响力的识别和度量;FOUSS et al.[19]将用户和产品构建成为二部图,并定义了在图结构上的马尔科夫链的随机游走过程,他们通过定义一些马尔科夫链上的基本度量,如第一次经过的时间、成本和平均的游走时间等,以度量不同节点之间的相似性,提供了一种利用随机游走方法对二部图中节点进行排序的基本思路。HE et al.[20]提出一套贝叶斯框架,可以基于图的链接结构和节点信息来研究二部图上的节点排序问题,他们通过引入查询向量来平滑二部图,在优化正则化函数的同时动态地更新各节点的得分,进而实现排序的目的。查询向量的引入能够很好地平滑异常点的影响,大幅提高算法的鲁棒性,具有很强的借鉴意义。蔡小雨等[21]提出一种采用群体信息的二部图链接预测方法,通过对二部图进行投影,抽取二部图中节点对的局部结构属性,并运用群体检测技术抽取节点对的群体属性,融合二者作为相似度的度量标准,有效地提高了二部图链接预测的准确率。在推荐领域,关雲菲[22]通过构建用户项目二部图,引入用户的点击、收藏、加入购物车和购买4种行为数据优化评分系统,实现了对传统的基于二部图的推荐算法的改进;黄熠姿等[23]根据用户的评论数以及与该用户对项目评分相同的评论数量定义该用户的专家信任度,根据传统的评分信息定义用户的偏好程度,提出融合专家信息的二部图推荐算法,实验结果表明该算法表现出了优良的性能。但这些工作的研究重点主要是对推荐算法本身的改进,没有聚焦于用户在电子商务环境中的退货行为模式的建模。
以上研究均说明,基于二部图研究具有较好的泛化能力,可以适应多种场景下针对不同实体之间交互关系的建模。因此,本研究以二部图结构组织用户的产品退货记录,进而对个体用户在电子商务中的退货行为进行预测分析。
1.3 基于随机游走的推荐算法
自从随机游走被提出,就一直受到研究者的青睐,现已被广泛应用于图像分割[24]、图挖掘[25-26]和文本挖掘[27]等领域。近年来研究者通过构建用户网络和产品网络,利用随机游走等模型,定义不同节点之间的相似性,从而设计推荐算法,以解决稀疏性和冷启动等传统推荐中常见的问题。PUCCI et al.[28]提出一种基于随机游走的评分算法ItemRank,可以根据潜在目标用户的偏好对产品进行得分排序,进而实现推荐的目的。但是该方法并没有考虑到与目标用户相似的其他用户的偏好,对偏好的建模不够完备。针对冷启动问题,SHANG et al.[29]提出一种基于马尔科夫随机游走的混合协同过滤模型,发现与传统的协同过滤模型相比,该算法能够更好地适应冷启动的情况;施海鹰[30]利用关联规则挖掘的特性,挖掘用户属性与项目之间的关联,为新用户构造初始的评分向量,弥补了传统推荐算法的不足。这类基于协同过滤的模型难以处理极端稀疏的数据,且对异常点十分敏感,不适合用来建模退货这类数据集。张光前等[31]尝试从消费心理学的角度解决冷启动问题,提出基于消费者购物记录分析其消费性格、基于消费者消费性格进行新商品推荐的方法,通过消费心理这一纽带建立起消费者与新商品之间的联系。但该方法在应用时需要收集较多的额外信息,在电子商务环境下难以有效实施。JAMALI et al.[32]认为,基于信任网络的推荐比传统的基于用户评分的推荐包含更多的信息,有利于解决冷启动和稀疏性问题,他们提出TrustWalker算法,即基于信任网络的随机游走,并在游走的过程中返回预测的用户产品评分;张萌等[33]在此基础上提出一种基于用户偏好的PtTrustWalker算法,该算法在TrustWalker的基础上通过细化信任度量,引入权威度等信息加强了信任网络,使推荐变得更有针对性和可解释性,并且一定程度上增强了模型的稳定性。这类方法一般仅使用二部图本身的信息,缺乏利用丰富的先验信息提高算法性能的机制。MO et al.[34]将随机游走方法引入到基于事件的社交网络的推荐中,通过构建异构图来表示社交网络中不同类型的实体之间的交互作用,并提出一种重启动的反向随机游走方法,以获得每个用户的评分列表。类似的,曹云忠等[35]将社交网络中用户间的交互行为引入信任的计算,通过基于信任的随机游走模型实现了微博粉丝的精准推荐。与之类似,在退货二部图中,用户间通过产品而产生的交互行为也需要被引入到偏好的计算中。张怡文等[36]采用共同项目和用户打分项目数量的共同性质体现用户兴趣度,提出一种基于用户兴趣度的二部图随机游走方法;李镇东等[37]在传统的二部图推荐算法的基础上,提出一种以单调饱和函数为权重,利用目标用户和其他项目共同评分个数相对用户总数均值的正切值作为相似性度量的推荐算法。这类研究大多只从用户角度出发,没有将产品一侧的相似度融入到模型之中。杨华等[38]将推荐网络的拓扑结构从二部图延伸到更一般的网络,根据商品、品牌、店铺及其关联关系构建混合图,通过重启动的随机游走算法确定节点间的转移概率,实现商品推荐,证明了随机游走方法在图排序问题上良好的泛化能力。
上述研究仅针对用户的购买记录进行建模,并未考虑用户特征和产品本身的特征。而对于退货问题来说,需要同时考虑与购买和退货相关的行为,融合影响退货的用户特征和产品特征,从而提升模型的预测精度。
2 基于二部图的退货风险模型
退货是用户的一项综合决策过程,与产品的购买过程类似,在一定程度上反映了用户对于产品的偏好特征和个性化的退货行为模式,同时也涉及到用户和产品等不同实体。不同的用户对于不同类型商品评价的侧重点不同,对应的退货行为也存在特定的模式,因此需要针对用户购买和退货的行为数据进行深度挖掘,进而对用户在购买各类产品时发生退货的风险进行预测。对于具体的目标用户来说,退货风险即为针对不同产品的退货倾向。
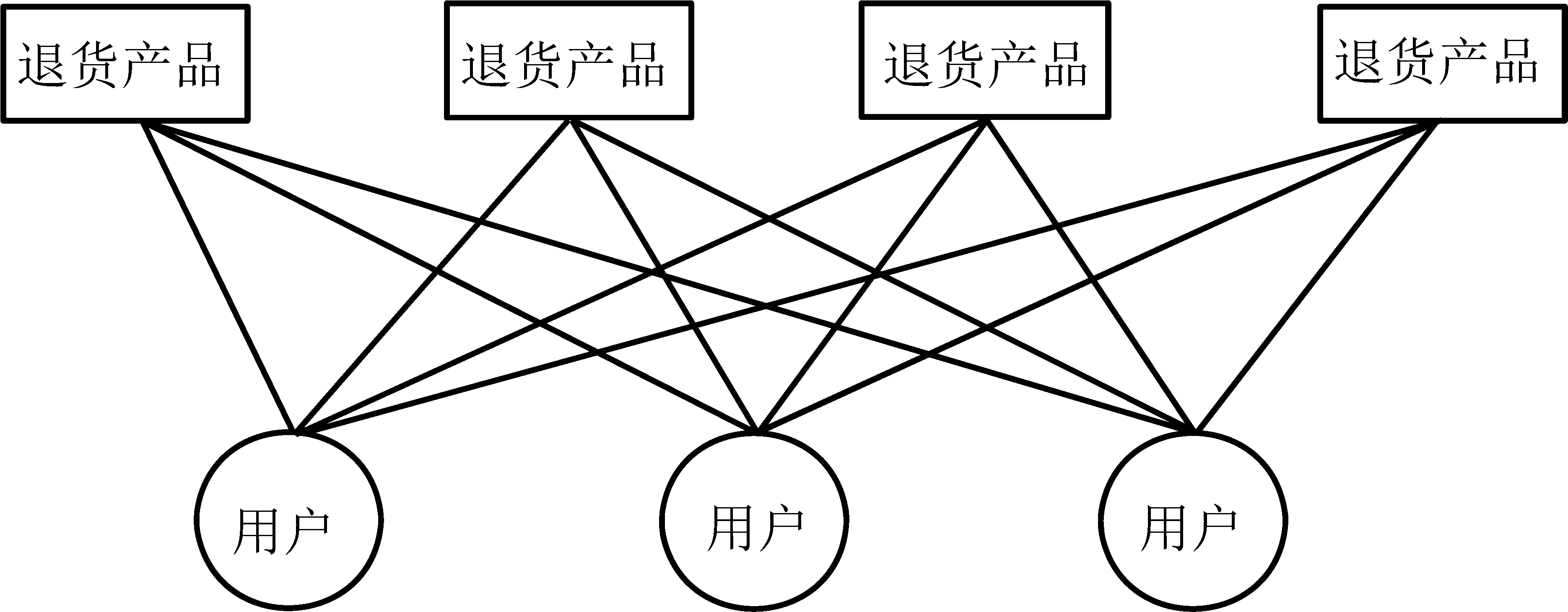
图1 退货二部图结构示例Figure 1 Example for Product Return Bipartite Network
2.1 退货二部图与随机游走
如前所述,二部图能够有效地表征不同类型实体间的交互活动。实际上,电子商务中的退货场景中所包含的用户和产品符合二部图刻画不同实体类型间交互行为的结构。令由“用户-产品”的退货记录构成的退货二部图为G,G=(U∪I,E),U为电子商务平台中的用户集合,I为平台上的产品集合,E为该二部图的边集。二部图中的边由历史退货记录集合T生成,形如(uj,ik,wjk)∈E,uj为用户,uj∈U,1≤j≤|U|;ik为产品,ik∈I,1≤k≤|I|;wjk为uj用户对ik产品的退货次数。对二部图中的每一个用户节点和每一个产品节点而言,度是图上的重要属性,因此可以引入两个由权重矩阵W生成的对角矩阵DU和DI。
基于如上定义的退货二部图,可以根据二部图的结构特征对图中的节点按照一定的规则进行排序。因此,对于退货风险的预测问题可以转换为基于二部图的结构发现问题。具体而言,对于特定用户的退货风险的预测问题可以定义为:给定目标用户节点uj,根据该节点在二部图中与不同产品的连接以及与其他用户节点的相似性,得到该用户对于不同产品的潜在风险退货列表。
随机游走提供了一种根据二部图中节点间的相关性进行排序的方法,其基本思想是根据特定的概率游走规则,在不同类型的节点间进行转移,直至收敛,能够在一定程度上减小稀疏性的影响。因此,在对用户和产品的退货风险进行建模时,本研究构建二部图,并通过随机游走模型实现对用户和产品的循环表示。具体而言,对应于本研究所关注的退货二部图,可以将用户到产品的一条退货记录边作为一条随机游走的路径,而在退货网络中的随机游走则可以视作是退货风险在用户与用户之间、产品与产品之间的传递。其中相似的用户具有相似的退货行为,而相似的产品也会被相似的用户退货。图1为一个退货二部图结构的示意图,直接反映用户与产品退货关系的结构特点。
于是,令uj用户为待预测的目标用户,由退货二部图可以得到其对应的产品集合为I(uj),I(uj)={ik},(uj,ik)∈T。显然,I(uj)中的产品与目标用户具有较强的相关性。因此,基于随机游走的基本思想,退过I(uj)中产品的up用户则与目标用户具有较强的相似性。与此同时,up用户所退的产品集合I(up)也与目标用户产生了相关性,循环迭代,则可以生成与目标用户最相似的用户节点集以及最相关的产品节点集。上述过程可形式化地描述为以下两个迭代规则,即

(1)
(2)
其中,ruj为uj用户的退货风险,可以用其对应的退货产品和退货次数表示;rik为ik产品的退货风险,可以用退过该产品的用户和退货次数表示。但是,根据ZHOU et al.[39-40]的研究,上述形式的迭代规则不容易平稳地收敛,很容易受到异常点和参数设置的影响,所以需要进行形式上的正则化处理。因此,本研究使用对于图的对称正则方法进行平滑处理,正则化后的迭代规则为
(3)
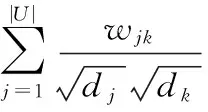
(4)
其中,dj为二部图中uj用户的度,dk为二部图中ik产品的度。
本研究涉及的变量及其含义见表1。
2.2 融合退货特征的二部图排序模型
2.2.1 影响退货的特征分析
本研究针对用户和产品的各类特征进行观测。在淘宝网中,平台根据用户的购买记录对用户的信用水平进行评分。图2给出不同信用评分用户的退货率分布,其中高退货率的用户主要集中在低信用评分区段,当信用评分超过2 000时,退货率基本稳定在0附近,总体呈现出负相关的趋势。由此可见,用户的信用评分与退货有很强的相关性。不同信用评分区段的用户具有不同的退货特征,信用评分较低的用户退货倾向更明显。

表1 变量及其含义Table 1 Variable and Definition
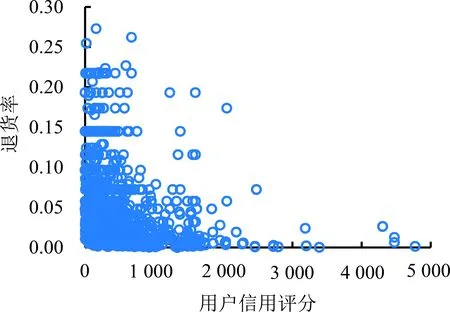
图2 不同信用评分用户的退货率分布Figure 2 Product Return Rate Distributionfor Users with Different Credit Scores
图3给出不同价格的产品呈现出的不同的退货特征。由图3可知,随着产品价格的升高,产品的退货率也逐渐升高,呈现出正相关的特征。一般来说,对于价格较为便宜的产品,用户的期望相对较低,退货风险较小;而对于价格较高的产品,用户要求较高,发生退货的风险也更高。因此,产品价格可以作为预测退货风险的一大特征。
图4给出产品运费的支付方与退货频次分布之间的关系。由图4可知,当运费支付方为用户时退货风险更高。因此,产品包邮与否也可以作为测量退货风险的特征。
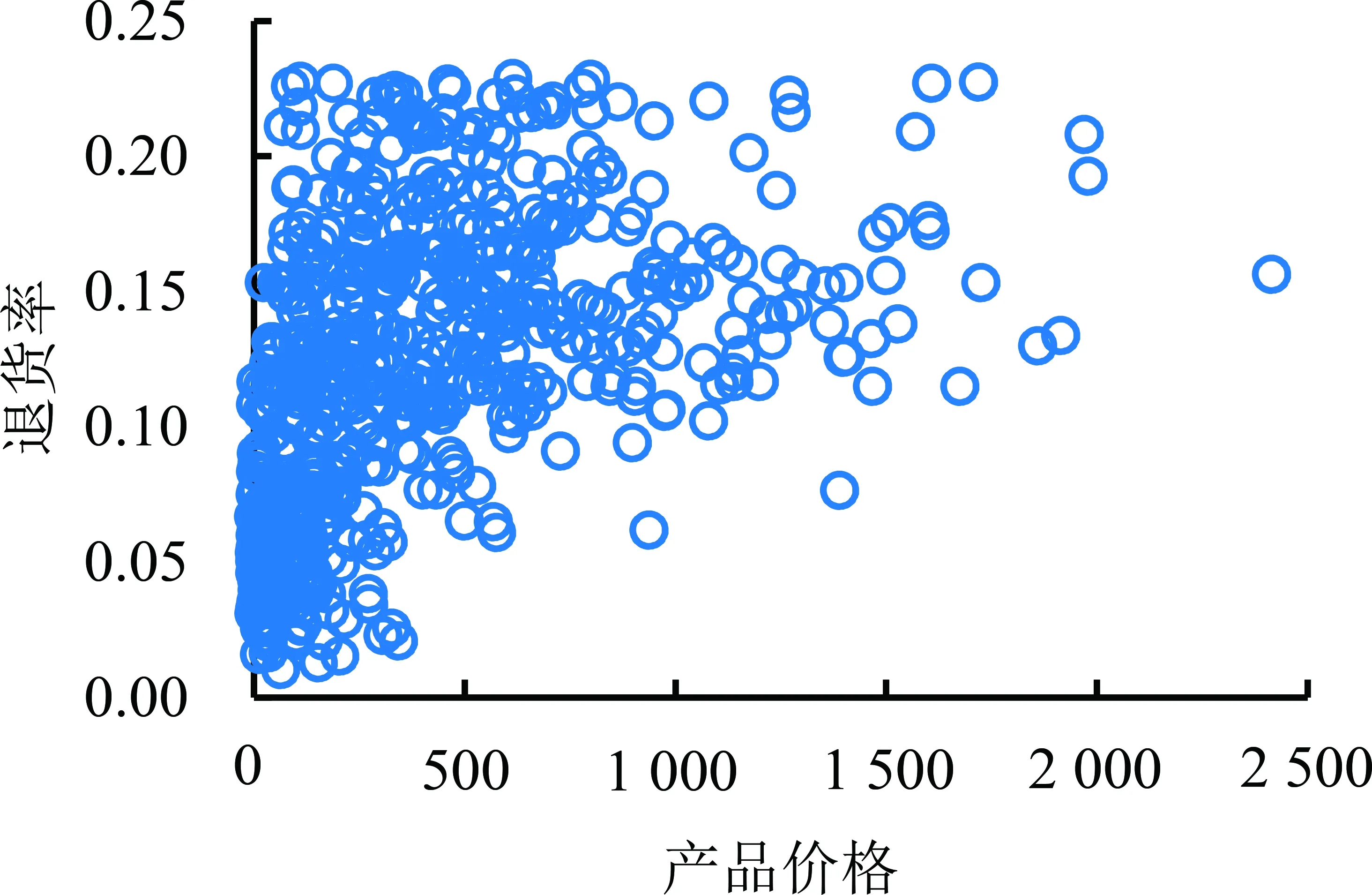
图3 不同价格产品的退货率分布Figure 3 Product Return RateDistribution with Different Price
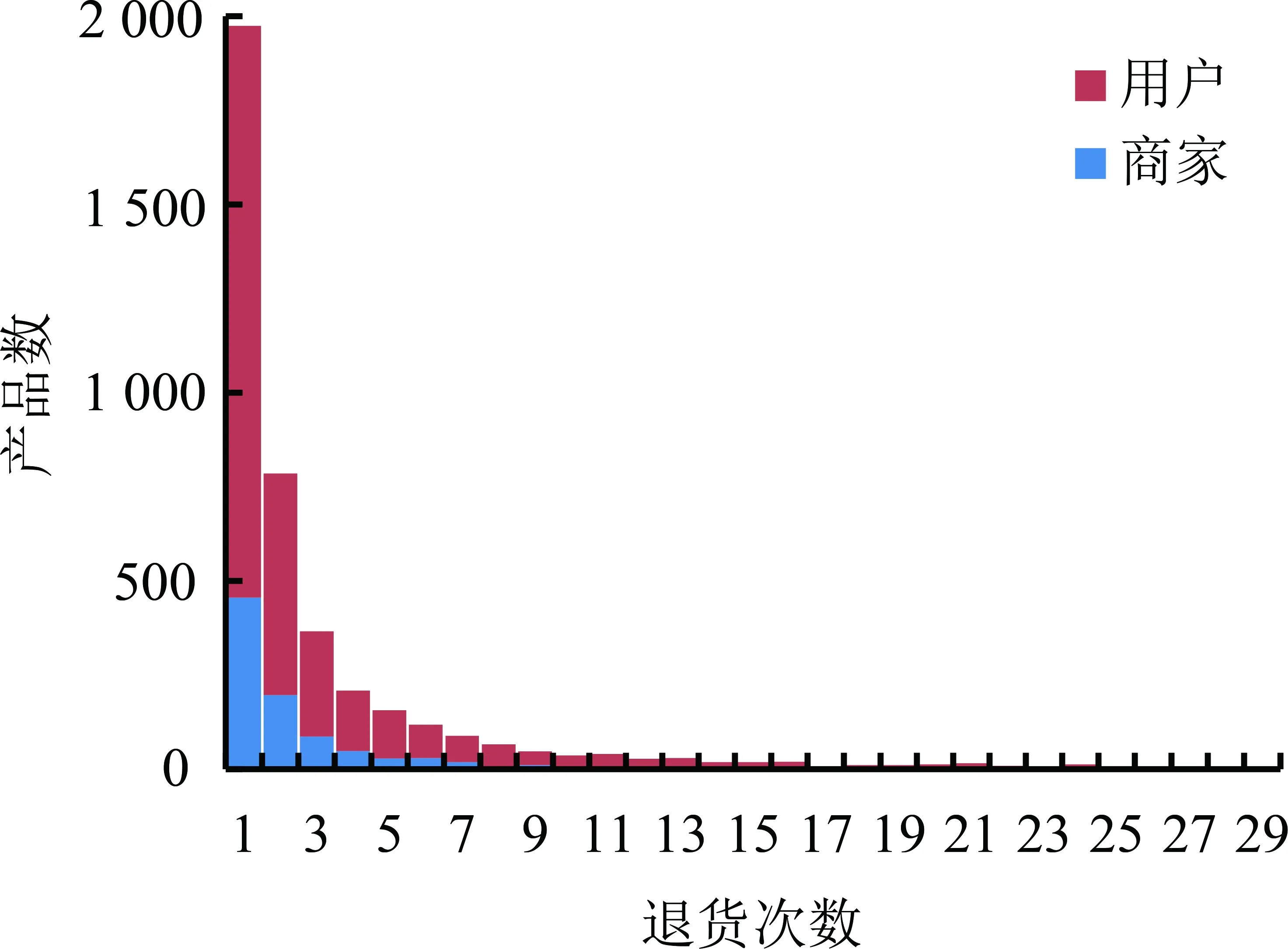
图4 不同产品运费支付方的退货频次分布Figure 4 Product Return Frequency DistributionWhen Shipping Rate Paid by Different Parties
此外,在电子商务环境中,用户只能通过产品的简介和描述来判定产品的质量,其中是否拥有质保证书是一项重要的指标,图5给出是否拥有质保证书的产品被退货的频次分布。由图5可知,无质保证书的产品被退货的风险高于有质保证书的产品。可能无质保证书的产品总体上质量较差,也可能因为用户对无质保证书的产品持负面态度。因此,有无质保证书也可以作为影响退货的重要特征融入到退货风险的预测模型中。
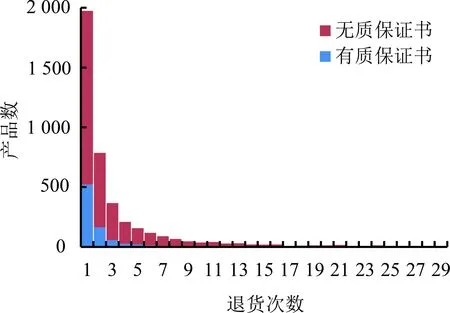
图5 产品是否拥有质保证书的退货频次分布Figure 5 Product Return Frequency Distributionover Whether Product Has Warranty
2.2.2 退货特征相似性度量
随机游走测量用户与产品之间的相关性,表示退货风险在二部图中传递。因此,为了将上述相关特征融入到随机游走过程中,需要度量用户与产品在不同特征间的相似性,并将相似性作为随机游走的先验信息,指导游走过程。
(1)用户静态相似性的度量
根据图2可知,不同信用评分的用户具有不同的退货行为特征,可以很好地用来量化用户的静态相似性。对于任意的目标用户uj,任取用户集合U中的一个元素记为ul,设计如下的相似性函数计算该用户与目标用户之间的相似度,即
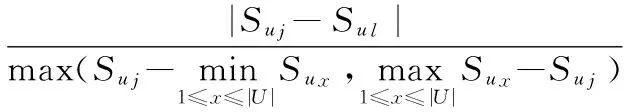
(5)
其中,SU(uj,ul)为基于用户的相似性度量函数,Suj为uj用户的信用评分,Sul为ul用户的信用评分,Sux为除uj和ul用户外其他任一用户的信用评分。当ul用户是目标用户时,SU(uj,ul)的取值为0;当ul用户不是目标用户,但与目标用户信用评分差距最大时,SU(uj,ul)的取值为1。且SU(uj,ul)在0~1之间具有良好的线性变化性质。
(2)产品相似性的度量
根据之前的观测,产品的相关特征属性主要包括价格、产品包邮与否和是否有质保证书3项,价格是连续性变量,其他两项是[0,1]变量。为了消除量纲的影响,先对价格属性进行归一化处理,归一化函数为
(6)
其中,ik为目标产品,ip为产品集合I中的任意一个元素,Pik为ik产品的价格,Pip为ip产品的价格,Piy为除ik和ip产品外其他任一产品的价格。
令ik产品经过归一化后的特征属性向量为Fik,ip产品经过归一化后的特征属性向量为Fip,采用调整的相关系数作为产品之间相似性的度量函数,记为SI(ik,ip),即
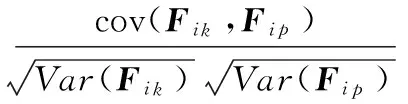
(7)
(3)退货特征的随机游走
在测量退货特征相似性的基础上,可将其作为算法的先验信息融入到随机游走中。具体而言,通过SU(uj,ul)函数计算所有用户与目标用户uj的相似性,可以生成用户的先验信息u0,从而将用户特征融合到用户端退货风险的测量中,即
u0={SU(uj,ul)} 1≤l≤|U|
(8)
产品在退货特征上的相似性也可以作为产品端游走过程的先验信息,以此改进(2)式中对于产品退货风险的测量。同时,由于退货风险预测的目标是寻找目标用户最可能退货的产品列表,所以产品的先验信息还应包含产品与目标用户之间的相关性,这里采用退货次数占比作为相关性的度量,记为r(uj,ik),即
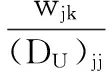
(9)
其中,(DU)jj为uj用户的总退货次数。但是,用户的退货记录矩阵是较为稀疏的矩阵,即目标用户对很多产品的退货次数可能为0,难以进行有效的区分。因此,本研究在产品特征相似性的基础上,引入基于产品特征相似性的平均退货次数占比,记为C(uj,ik),即
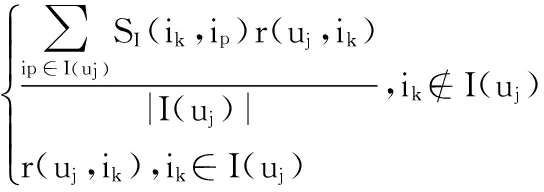
I(uj)={ip},(uj,ip)∈T
(10)
根据(10)式可以测量uj目标用户与所有产品之间的相关性,进而生成产品的先验信息i0,从而将产品特征融合到产品端退货风险的测量中,即
i0={C(uj,ik)}, 1≤k≤|I|
(11)
进一步地,引入超参数α和β对原有的随机游走过程和退货特征的相似性进行线性组合,得到融合的迭代规则。
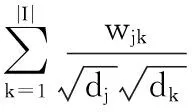
(12)
(13)
其中,α和β为超参数,α表示产品先验信息的重要性,β表示用户先验信息的重要性。上述规则可以使用向量形式更为简洁地表达为
(14)
(15)
其中,u为按与目标用户相似性排序的用户向量,i为按退货风险排序的产品向量。
上述迭代规则是基于二部图的退货风险预测模型的核心,根据迭代规则可以设计如算法1(ReRank)所示的退货风险预测方法。具体而言,输入目标用户、权重矩阵、超参数α和β,经过多次的迭代直至收敛,最终输出u和i,其中排名前N的产品集合R(uj)作为预测的退货风险列表。

算法1 基于二部图的退货风险预测模型(ReRank)
3 实验
3.1 实验设计
本研究从淘宝网的在线商家中获取交易数据,淘宝网是阿里巴巴旗下的电子商务B2C购物网站,是目前中国最大的电子商务平台之一。该在线商家主要经营护肤产品,包括面霜、面膜、香水等。该数据集包含用户记录、产品记录和2013年全年的退货记录。为了更好地发现用户退货的潜在行为模式,本研究对发生频繁退货的用户进行采样,保留退货次数超过2的用户及其退货记录。并抽取用户的信用评分作为用户特征,以产品价格、运费支付方和证书状态作为产品特征。抽样后形成的新数据集的统计数据见表2。
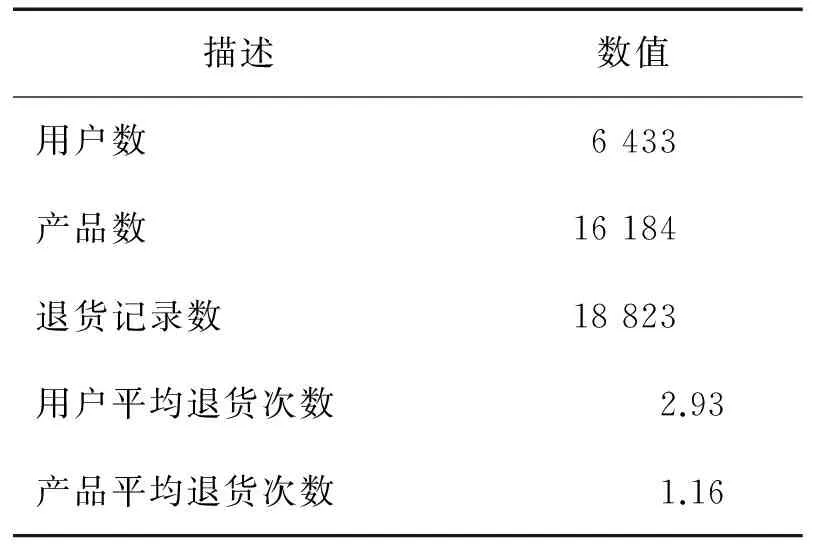
表2 数据集描述Table 2 Description for Dataset
将退货记录划分为5份,取其中的4份划入训练集,其余的划入测试集。对于无法等分的部分,向上取整划入训练集中。在此基础上进行实验。
3.2 实验比较方法和评价指标
3.2.1 实验比较方法
为了验证本研究提出的算法ReRank的实际预测效果,选取一些常用的推荐方法作为基准比较方法。
(1)基于产品的协同过滤(ItemCF)
基于产品的协同过滤的基本思想是向用户推荐与他们之前偏好的产品相似的产品。该算法认为,A产品与B产品具有很强的相似性是因为偏好A产品的用户也更倾向于偏好B产品。记A产品的退货向量为VA,B产品的退货向量为VB,采用余弦夹角计算二者之间的相似度可以得到产品的相似度矩阵。对于目标用户,利用产品相似度对用户偏好程度进行加权平均,经排序后可输出推荐列表R(uj)。
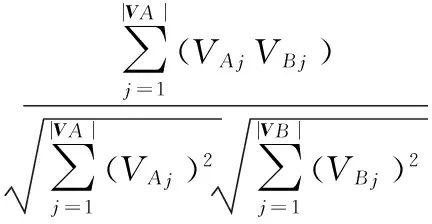
(16)
其中,VAj为退货向量VA的第j个分量的值,VBj为退货向量VB的第j个分量的值。
(2)基于用户的协同过滤(UserCF)
基于用户的协同过滤的基本思想是向用户推荐与其相似的用户所偏好的产品。该算法认为,C用户与D用户很相似是因为二者偏好同样的产品。记C用户的退货向量为VC,D用户的退货向量为VD,采用余弦夹角计算二者之间的相似度可以得到用户之间的相似度矩阵。对于目标用户,利用用户相似度对产品偏好程度进行加权平均,经排序后可输出推荐列表R(uj)。
(17)
其中,VCj为退货向量VC的第j个分量的值,VDj为退货向量VD的第j个分量的值。
(3)奇异值分解(SVD)
奇异值分解是一种矩阵分解的方法,它可以将推荐问题映射到一个隐含空间进行求解。对于本研究关注的退货问题,给定退货矩阵W,wjk为矩阵中任意元素。SVD假设用户和产品都可以被映射到一个低维度的隐含空间,而退货矩阵可以分解为用户对各个隐含因子的偏好程度L以及产品包含各个隐含因子的程度M。典型的奇异值分解公式为
W=LΣMT
(18)
其中,Σ为分解后的中间矩阵。
(4)非负矩阵分解(NMF)
与SVD方法类似,NMF也是将消费者对于产品的评分矩阵分解为消费者与产品的隐含矩阵。NMF要求输入矩阵元素非负,目标是最小化消费者对于产品的评分矩阵与多个隐含矩阵乘积之间的距离。
3.2.2 评价指标
(1)准确率(Precision)
准确率是反映预测精度的单值指标,表示预测的退货风险列表中实际发生退货的产品数在预测列表中所占的比例。因此对于uj用户,退货风险预测得到的产品集合为R(uj),R(uj)中实际发生退货的产品集合为hits(uj),对应的准确率为
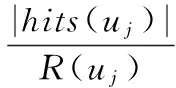
(19)
(2)召回率(Recall)
召回率是指预测的退货风险列表中实际发生退货的产品数在用户实际发生退货的产品数中所占的比例。对于uj用户,其实际发生退货的产品集合记为I(uj),R(uj)中实际发生退货的产品集合为hits(uj)。
(20)
(3)nDcg
该指标用来测量算法能否将实际发生的退货产品置于预测风险列表的顶端,该指标值越大,说明得到的预测精度越高。对于uj用户,退货风险预测得到的产品集合为R(uj),长度为N。计算Dcg的公式为
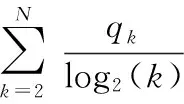
(21)
其中,当排序列表中的第k件产品在交易记录中被实际购买时,qk=1;反之,qk=0。为了得到nDcg,需要对Dcg进行标准化,即
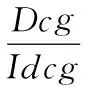
(22)
其中,Idcg为在最理想的排序情形时Dcg的取值,即最大化的取值。当有多个目标用户时,计算不同用户nDcg的均值即可。
3.3 退货风险预测实验结果
3.3.1 算法收敛性分析
基于随机游走算法的特点,在实验中首先利用用户和产品的退货风险向量平均值的变化率对算法的收敛进行分析。取α=0.5,β=0.8,根据(14)式和(15)式计算迭代后得到的退货风险向量u和i,同时计算与上次迭代得到的向量的平均值的变化率。收敛性分析见图6,随着迭代次数的增加,用户和产品退货向量的变化率都在同时减小,当迭代次数大于10时,u和i平均值的变化率同时趋近于0,算法趋于收敛。
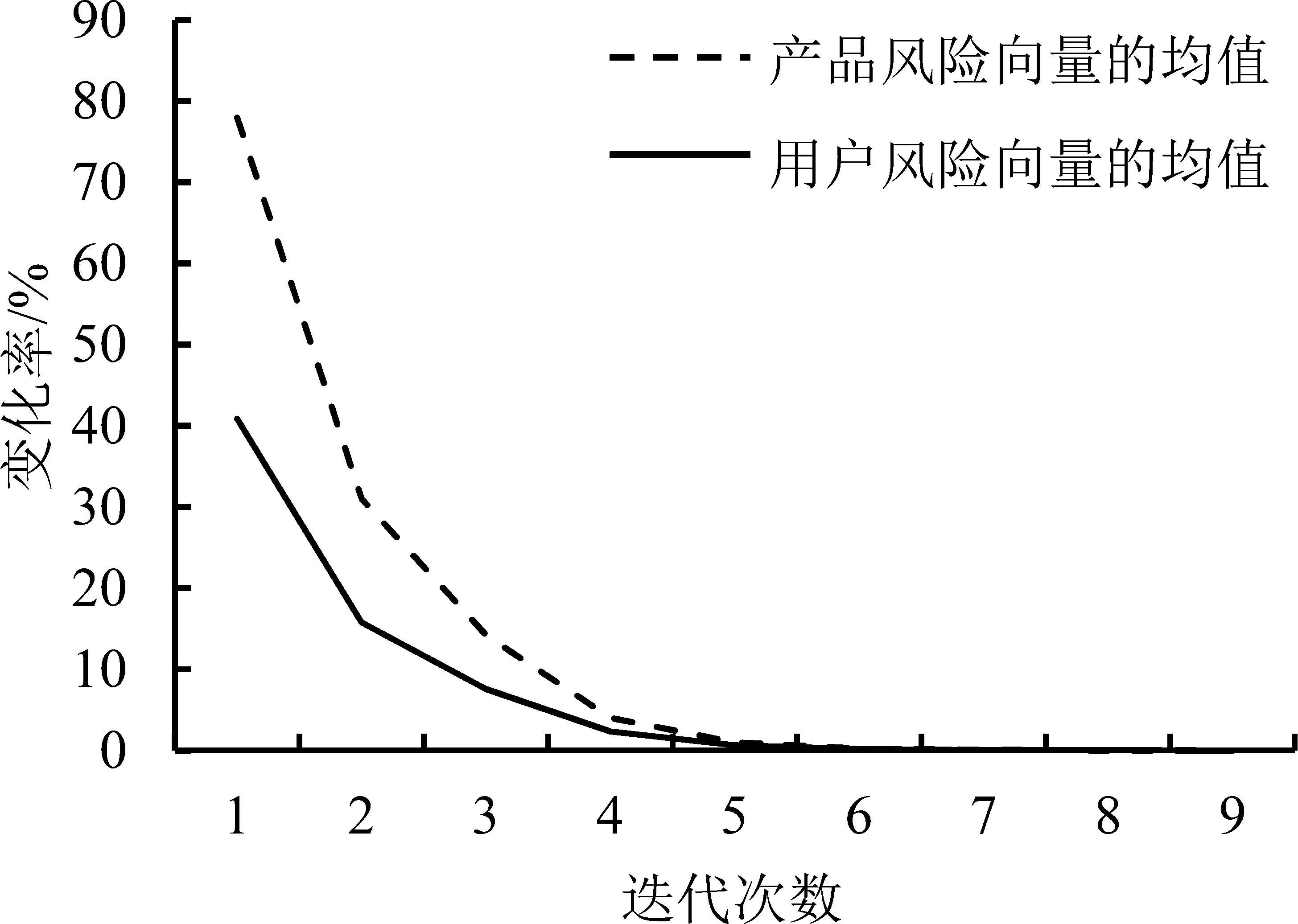
图6 算法的收敛性分析结果Figure 6 Convergence Analysis Resultsfor the Algorithm
3.3.2 参数敏感性分析
本研究提出的ReRank算法中包含α和β两个超参数,分别用来衡量产品先验信息和用户先验信息的重要性,可以根据实际的使用情况自由设置。不同的参数设置可以导致不同的推荐结果,因此在本实验中着重分析模型对超参数的敏感性。
取β=0.8并保持不变,分析α对模型性能的影响,见图7。由图7可知,分别在列表长度为5、10和15的情形下进行参数分析,随着α值的增大,模型的召回率呈现不断下降的趋势,准确率先升后降。当α=1,即无任何产品先验信息时,与包含一定的先验信息时相比,模型的准确率和召回率都有明显的下降,可见先验信息对于模型性能的重要影响。
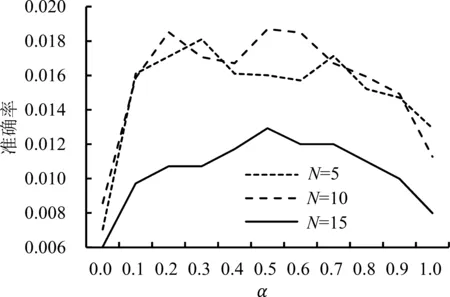
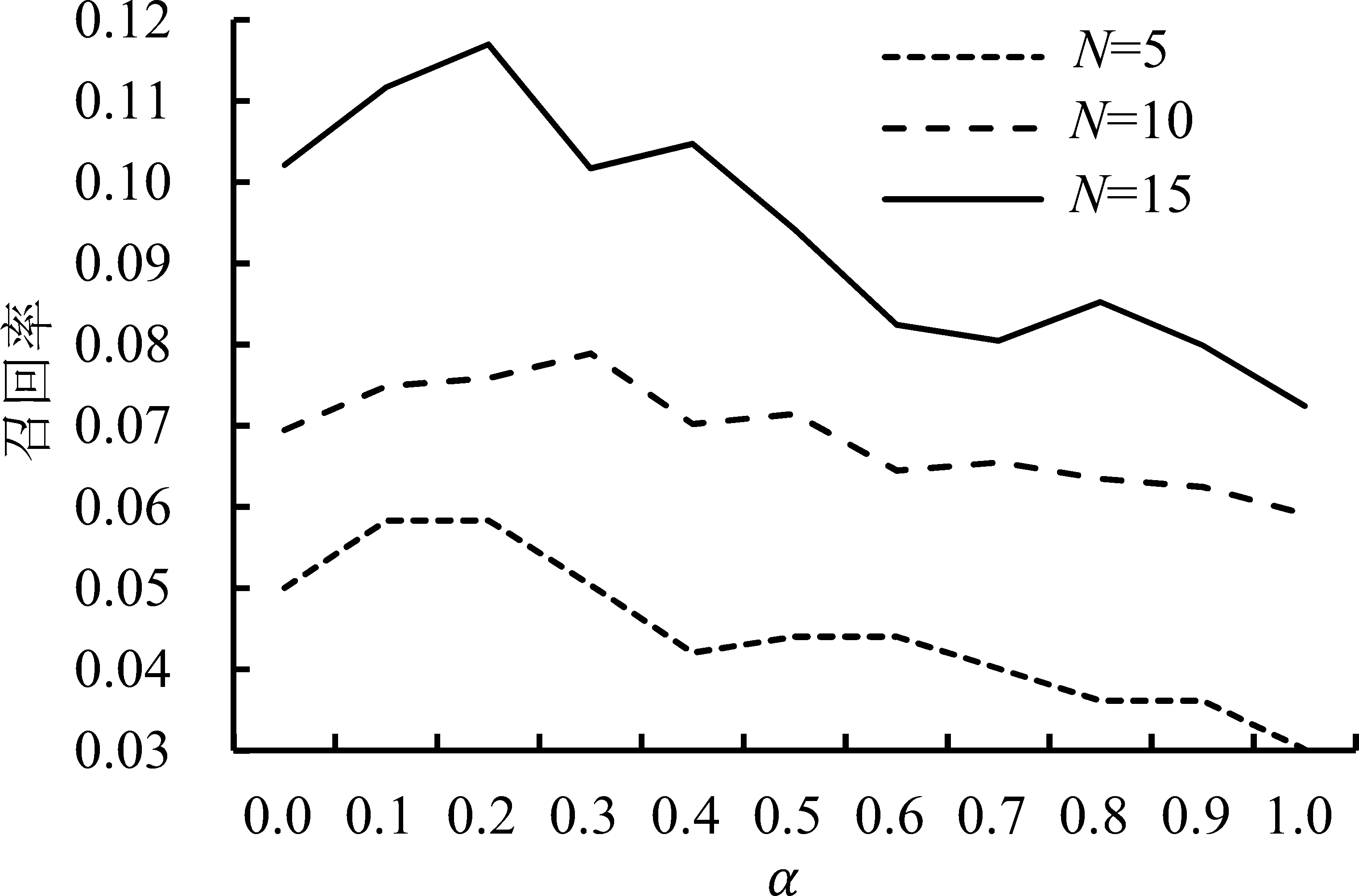
(a)准确率(b)召回率图7 α的敏感性分析Figure 7 Sensitivity Analysis Results for the α
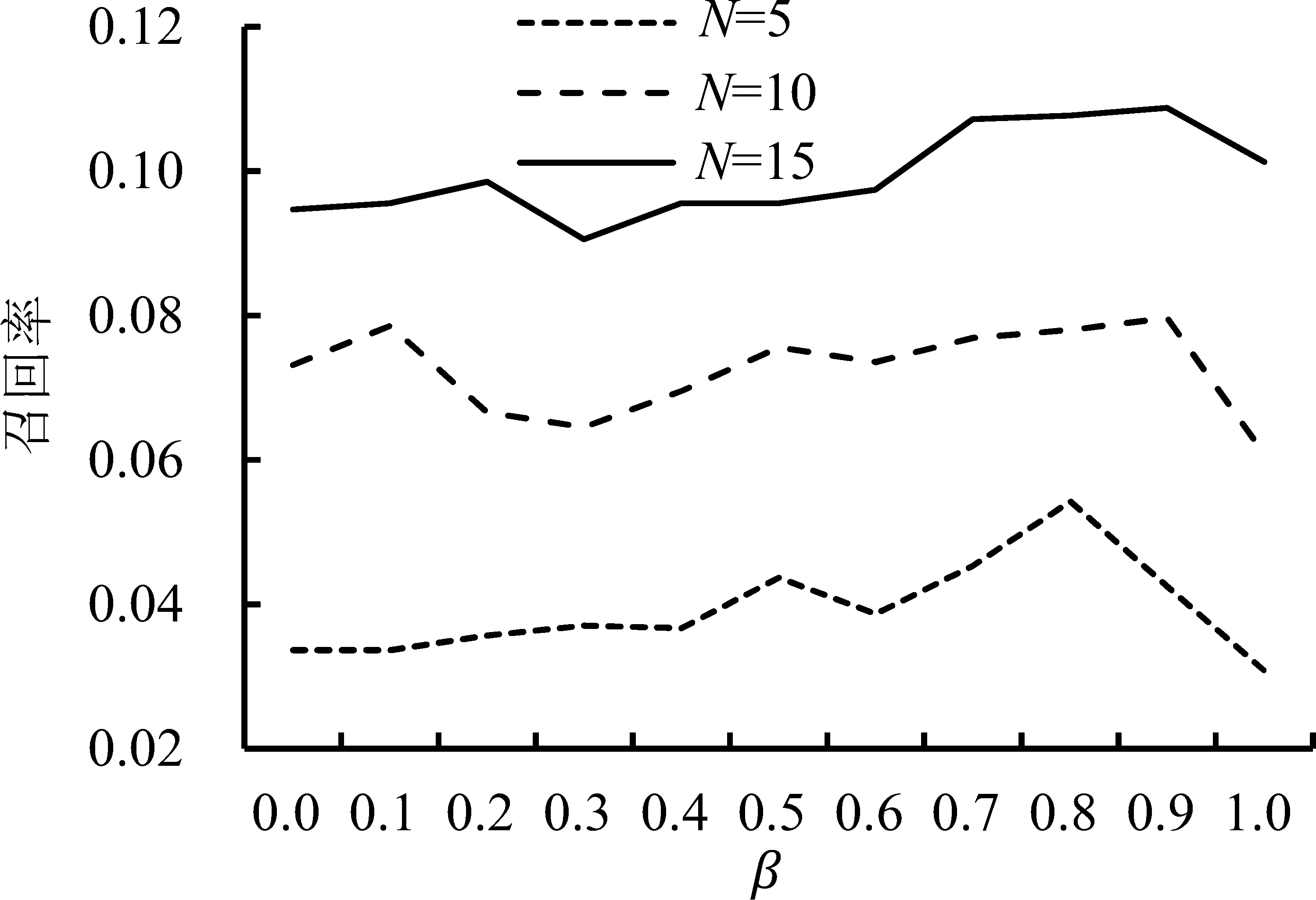
取α=0.5,分析β对模型性能的影响,见图8。由图8可知,在退货预测列表长度分别为5、10和15时,随着β值的不断增加,模型的召回率总体呈上升的趋势,准确率总体呈下降的趋势。同样的,当β=1,即无任何用户先验信息时,与包含一定的先验信息时相比,模型的准确率和召回率也都有明显的下降。另外,准确率和召回率曲线的变化幅度都很小,说明在该数据集上ReRank算法对β不敏感。
3.3.3 算法性能分析
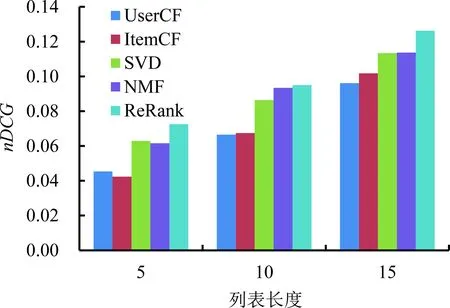
进一步地,设定最优参数(α=0.5,β=0.8),对所有用户的退货风险进行预测,即根据用户对于产品的退货风险预测用户的退货列表。将预测结果与UserCF、ItemCF、SVD和NMF等算法进行对比,分析结果见图9。整体上看,本研究提出的算法在所有指标上均表现得最好,当列表长度为15时,与NMF相比,ReRank的准确率提高了16%,召回率提高了17%,nDcg提高了11%。另外,基于产品的协同过滤表现出较差的性能,可能是因为在该数据集中产品的退货记录较为分散,所以基于产品的相似度计算区分度不高。
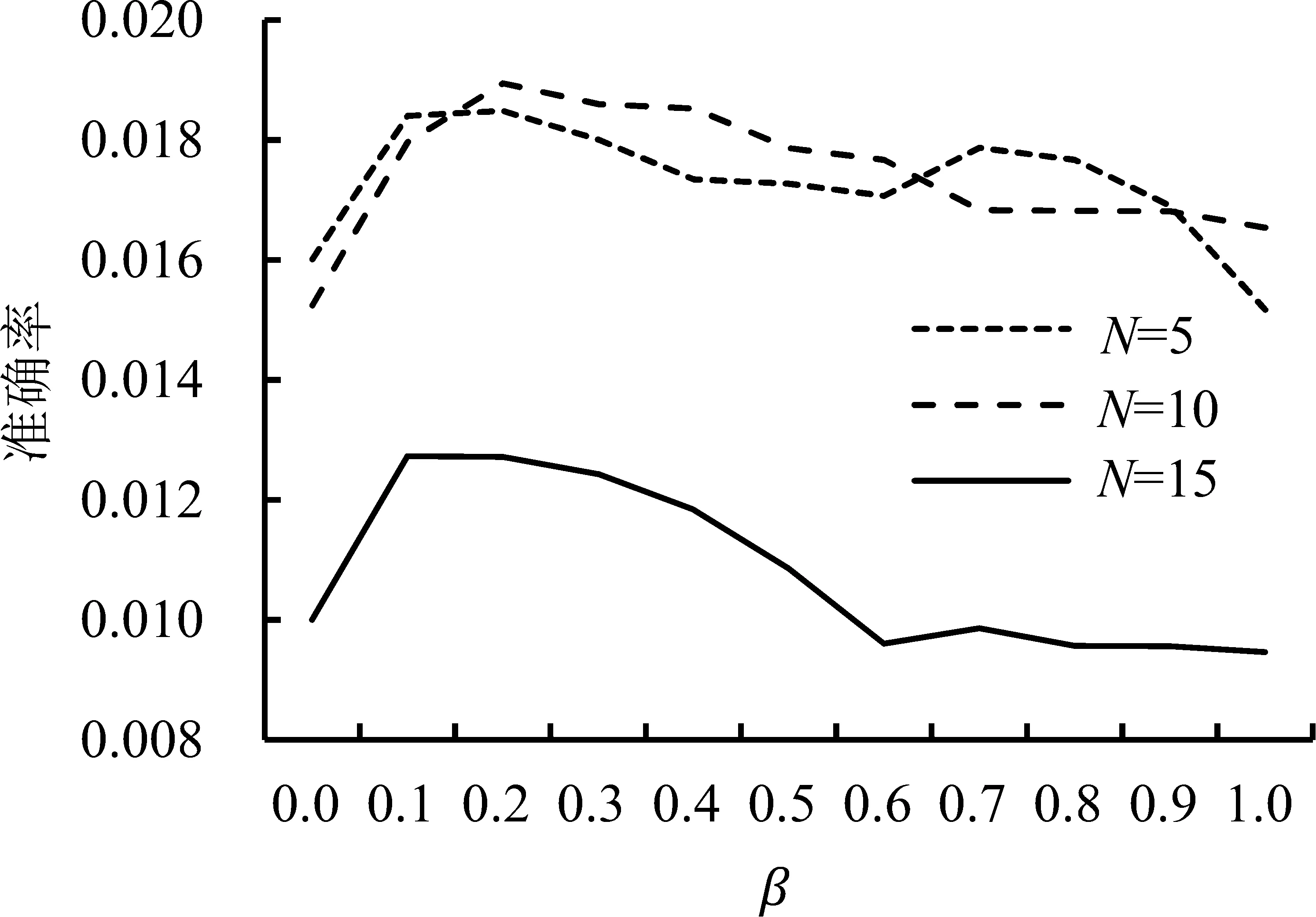
(a)准确率(b)召回率图8 β的敏感性分析Figure 8 Sensitivity Analysis Results for the β
3.3.4 退货特征的预测能力分析
为了进一步分析融合到随机游走过程的各个退货特征对于退货风险的预测能力,分别在初始的随机游走模型中加入各个特征,得到各自的预测精度,见表3。在模型中加入所有特征后,各项预测指标均
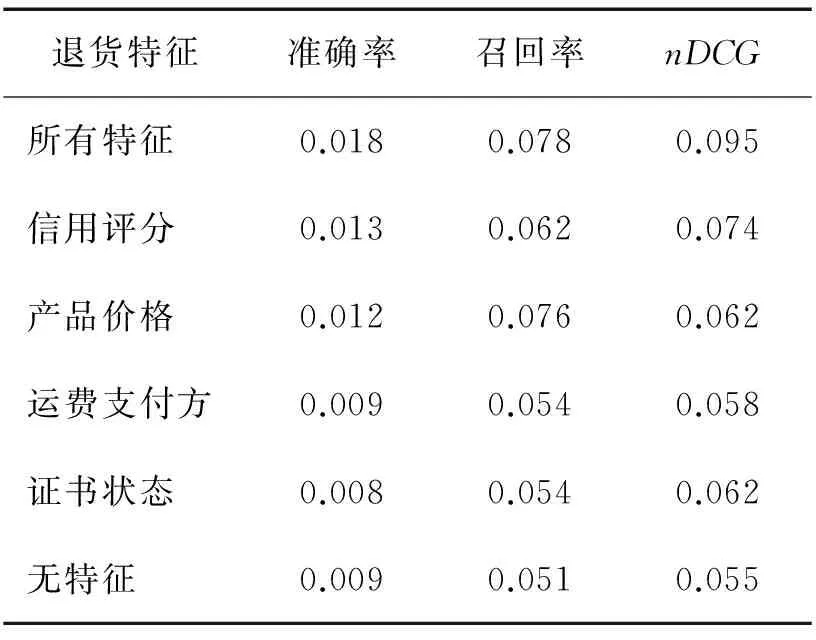
表3 不同退货特征的预测能力Table 3 Predictive Powerfor Different Product Return Feature
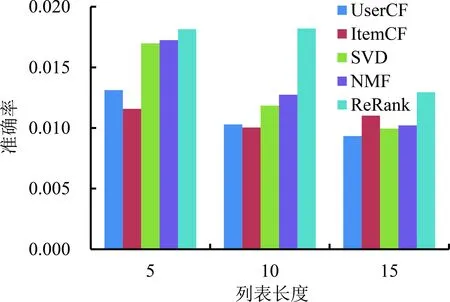
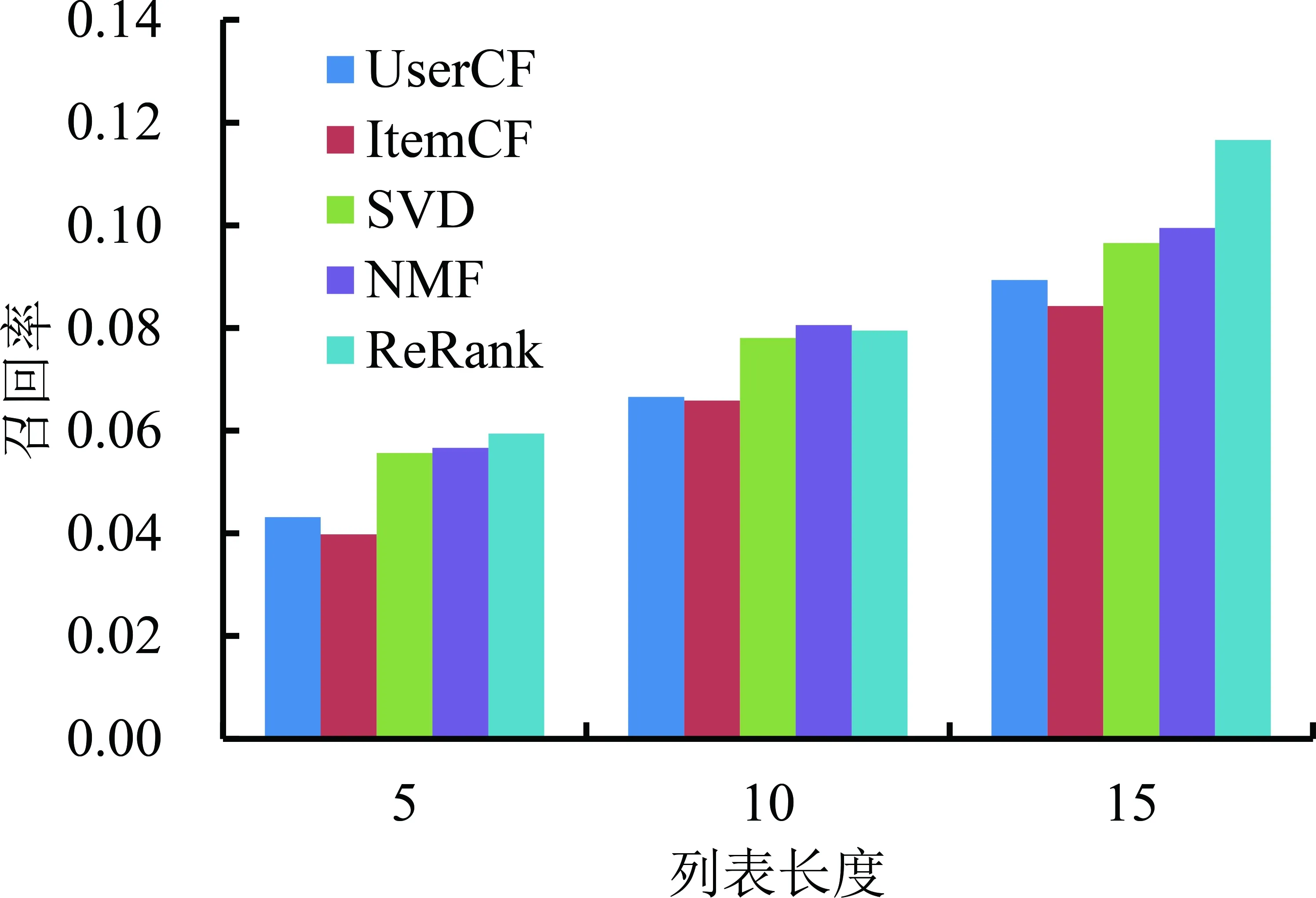
(a)准确率(b)召回率(c) nDCG图9 不同算法的性能比较结果Figure 9 Results for ComparingPerformance for Different Algorithms
达到最高,而不加入任何退货特征的模型整体表现最差。单独加入用户的信用评分或产品价格均从较大程度上提升了算法的精度,并且偏重不同的精度指标,信用评分有效提升了准确率,产品价格提升了召回率。运费支付方式和质保证书也从一定程度上改进了算法的预测精度,但精度的提升幅度有限。分析结果再次表明,融合了退货特征的随机游走模型能对退货风险进行更细致的建模。
实际上,本研究提出的ReRank算法对于不同类型的退货特征有较好的可扩展性,各类特征均可以根据相似性的测量融入到随机游走的先验信息中。
4 结论
4.1 研究结果
本研究聚焦于电子商务环境下的退货问题,针对电子商务企业的交易、用户和退货数据,提出一种分析和预测用户对于特定产品退货风险的方法。①退货行为中包含的用户和产品两种实体类型,通过引入二部图结构来组织历史退货记录,将问题形式化为二部图上的节点排序问题。②设计退货风险的随机游走过程,实现用户与产品退货风险的互相表示。基于实际退货数据的观测,发掘影响退货的各类特征属性,并将其转化为先验信息引入模型,有效引导退货风险在用户与产品间的游走过程。③通过在真实数据集上的实验表明,本研究提出的模型比其他方法具有更高的性能,并且相关退货特征的引入可以提升退货风险的预测精度。本研究主要适用于退货率较高且退货难度较低的电子商务环境。
4.2 理论和实践意义
本研究的意义包含两个方面。①提供了一种识别潜在高退货风险的用户和高风险产品的方法,对于电子商务企业的运营管理决策具有较强的实践意义。相关企业可以利用本研究提出的分析和预测方法对相关的用户购买各类产品时进行风险判断,有针对性地加强客户关系管理。同时可以加强对高退货风险产品的管理和规划,如采用加强包装、改善产品质量等方式,以规避退货风险。②本研究针对电子商务退货数据,创新性地将二部图随机游走模型应用到退货风险管理中,为电子商务领域相关研究提供一种新的视角,具有一定的理论意义。
4.3 研究的局限和不足
①受数据本身的限制,本研究采用的退货特征相对有限,因此仅针对部分用户和产品的相关特征进行融合。但实际上仍存在大量影响退货的因素,如产品的选择过程、产品退货的难易程度等,可以更有效地识别退货风险。虽然本算法对各类特征具有较强的可扩展性,但仍无法全面验证和分析退货特征对于风险的预测能力。②本研究仅针对截面时间上的退货数据进行分析,但实际上用户的退货行为和产品的被退货模式可能随时间发生变化,因此未来研究需对模型进行动态性的扩展。③后续研究可以结合一些行为学研究范式,补充个体用户对于电子商务环境下退货的主观认知,从而更好地揭示退货的管理意义。
[1]ANDERSON E T,HANSEN K,SIMESTER D.The option value of returns:theory and empirical evidence.MarketingScience,2009,28(3):405 - 423.
[2]LI Y,XU L,LI D.Examining relationships between the return policy,product quality,and pricing strategy in online direct selling.InternationalJournalofProductionEconomics,2013,144(2):451 - 460.
[3]WALSH G,MÖHRING M.Effectiveness of product return-prevention instruments:empirical evidence.ElectronicMarkets,2017,27(4):341 - 350.
[4]孙永波,李霞.网购退货后续购买行为的实证研究.企业经济,2017,36(2):149 - 155.
SUN Yongbo,LI Xia.An empirical study on the follow-up purchases of online shopping returns.EnterpriseEconomy,2017,36(2):149 - 155.(in Chinese)
[5]DE P,HU Y J,RAHMAN M S.Product-oriented web technologies and product returns: an exploratory study.InformationSystemResearch,2013,24(4):998 - 1010.
[6]FU Y,LIU G,PAPADIMITRIOU S,et al.Fused latent models for assessing product return propensity in online commerce.DecisionSupportSystems,2016,91:77 - 88.
[7]PASTERNACK B A.Optimal pricing and return policies for perishable commodities.MarketingScience,2008,27(1):133 - 140.
[8]张霖霖,姚忠.考虑顾客退货时在线企业的定价与订货策略.管理科学学报,2013,16(6):10 - 21.
ZHANG Linlin,YAO Zhong.Pricing and order decisions with customer returns in online retailing.JournalofManagementSciencesinChina,2013,16(6):10 - 21.(in Chinese)
[9]李勇建,许磊,杨晓丽.产品预售、退货策略和消费者无缺陷退货行为.南开管理评论,2012,15(5):105 - 113.
LI Yongjian,XU Lei,YANG Xiaoli.Advance selling,return policy and false failure return for a newsvendor retailer.NankaiBusinessReview,2012,15(5):105 - 113.(in Chinese)
[10] 孙军,徐路恒,刘宇.退货问题下的在线零售商最优采购量研究.管理科学,2014,27(6):114 - 120.
SUN Jun,XU Luheng,LIU Yu.Optimal purchase quantity of on-line retailers under returns issue.JournalofManagementScience,2014,27(6):114 - 120.(in Chinese)
[11] 赵晓敏,高方方,林英晖.基于顾客退货的闭环供应链运作绩效研究.管理科学,2015,28(1):66 - 82.
ZHAO Xiaomin,GAO Fangfang,LIN Yinghui.Research on operational performance of a closed-loop supply chain with customer returns.JournalofManagementScience,2015,28(1):66 - 82.(in Chinese)
[12] MUKHOPADHYAY S K,SETOPUTRO R.Optimal return policy and modular design for build-to-order products.JournalofOperationsManagement,2005,23(5):496 - 506.
[13] ANDERSON E T,HANSEN K,SIMESTER D.The option value of returns:theory and empirical evidence.MarketingScience,2009,28(3):405 - 423.
[14] 卢美丽,叶作亮,王芳.考虑退货的在线零售价格和服务水平决策.系统工程,2017,35(1):102 - 109.
LU Meili,YE Zuoliang,WANG Fang.Online retail prices and service level decision considering returns.SystemsEngineering,2017,35(1):102 - 109.(in Chinese)
[15] 单汨源,江黄山,刘小红.在线零售商盈利能力及其退货策略研究.华东经济管理,2016,30(11):123 - 128.
SHAN Miyuan,JIANG Huangshan,LIU Xiaohong.Research on profitability and return policy of online retailers.EastChinaEconomicManagement,2016,30(11):123 - 128.(in Chinese)
[16] MOONESINGHE H D K,TAN P N.OutRank:a graph-based outlier detection framework using random walk.InternationalJournalonArtificialIntelligenceTools,2008,17(1):19 - 36.
[17] BEUTEL A,XU W H,CURUSWAMI V,et al.CopyCatch:stopping group attacks by spotting lockstep behavior in social networks∥Proceedingsofthe22ndInternationalConferenceonWorldWideWeb.Brazil,2013:119 - 130.
[18] ZHU Z,SU J,KONG L.Measuring influence in online social network based on the user-content bipartite graph.ComputersinHumanBehavior,2015,52:184 - 189.
[19] FOUSS F,PIROTTE A,RENDERS J M,et al.Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation.IEEETransactionsonKnowledgeandDataEngineering,2007,19(3):355 - 369.
[20] HE X,GAO M,KAN M Y,et al.BiRank:towards ranking on bipartite graphs.IEEETransactionsonKnowledgeandDataEngineering,2017,29(1):57 - 71.
[21] 蔡小雨,陈可佳,安琛.采用群体信息的二部图链接预测方法.计算机工程,2016,42(10):187 - 191.
CAI Xiaoyu,CHEN Kejia,AN Chen.Bipartite graph link prediction method using community information.ComputerEngineering,2016,42(10):187 - 191.(in Chinese)
[22] 关雲菲.改进的基于二部图网络结构的推荐算法.信息技术,2015(9):196 - 199.
GUAN Yunfei.Improved recommendation algorithm based on bipartite networks.InformationTechnology,2015(9):196 - 199.(in Chinese)
[23] 黄熠姿,杨金鑫,孙维.基于改进二部图与专家信任的混合推荐算法.价值工程,2017,36(19):160 - 164.
HUANG Yizi,YANG Jinxin,SUN Wei.Research of hybrid recommendation algorithm based on improved bipartite network and expert trust.ValueEngineering,2017,36(19):160 - 164. (in Chinese)
[24] 田东平.融合PLSA和随机游走模型的自动图像标注.小型微型计算机系统,2017,38(8):1899 - 1905.
TIAN Dongping.Integrating PLSA and random walk model for automatic image annotation.JournalofChineseComputerSystems,2017,38(8):1899 - 1905.(in Chinese)
[25] LIU X,CHEUNG G,WU X,et al.Random walk graph laplacian-based smoothness prior for soft decoding of JPEG images.IEEETransactionsonImageProcessing,2017,26(2):509 - 524.
[26] SHEN R,CHENG I,SHI J,et al.Generalized random walks for fusion of multi-exposure images.IEEETransactionsonImageProcessing,2011,20(12):3634 - 3646.
[27] 李鹏,王斌,石志伟,等.Tag-TextRank:一种基于Tag的网页关键词抽取方法.计算机研究与发展,2012,49(11):2344 - 2351.
LI Peng,WANG Bin,SHI Zhiwei,et al.Tag-TextRank:a webpage keyword extraction method based on Tags.JournalofComputerResearch&Development,2012,49(11):2344 - 2351.(in Chinese)
[28] PUCCI A,GORI M,MAGGINI M.A random-walk based scoring algorithm applied to recommender engines∥AdvancesinWebMiningandWebUsageAnalysis,2007,4811:127 - 146.
[29] SHANG S,KULKARNI S R,CUFF P W,et al.A randomwalk based model incorporating social information for recommendations∥2012IEEEInternationalWorkshoponMachineLearningforSignalProcessing.Santander,Spain,2012:1 - 6.
[30] 施海鹰.基于关联规则挖掘的分类随机游走算法.计算机技术与发展,2017,27(9):7 - 11.
SHI Haiying.Random-walk classification algorithm with association rules mining.ComputerTechnologyandDevelopment,2017,27(9):7 - 11.(in Chinese)
[31] 张光前,白雪.基于消费性格的新商品推荐方法.管理科学,2015,28(2):60 - 68.
ZHANG Guangqian,BAI Xue.Method of new commodities recommendation based on consuming personalities.JournalofManagementScience,2015,28(2):60 - 68.(in Chinese)
[32] JAMALI M,ESTER M.TrustWalker:a random walk model for combining trust-based and item-based recommendation∥Proceedingsofthe15thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.Paris,France,2009:397 - 406.
[33] 张萌,南志红.基于用户偏好的信任网络随机游走推荐模型.计算机应用,2016,36(12):3363 - 3368.
ZHANG Meng,NAN Zhihong.Trust network random walk model based on user preferences.JournalofComputerApplications,2016,36(12):3363 - 3368.(in Chinese)
[34] MO Y,LI B,WANG B,et al.Event recommendation in social networks based on reverse random walk and participant scale control.FutureGenerationComputerSystems,2017,79(1):383 - 395.
[35] 曹云忠,邵培基,李良强.基于信任随机游走模型的微博粉丝推荐.系统管理学报,2017,26(1):117 - 123,132.
CAO Yunzhong,SHAO Peiji,LI Liangqiang.Microblogging fans recommendation based on trust random walk model.JournalofSystems&Management,2017,26(1):117 - 123,132.(in Chinese)
[36] 张怡文,王冉,程家兴.基于用户兴趣度的改进二部图随机游走推荐方法.计算机应用与软件,2015,32(6):76 - 79.
ZHANG Yiwen,WANG Ran,CHENG Jiaxing.Improved recommendation algorithm of bipartite graph random walk based on user interest degree.ComputerApplicationsandSoftware,2015,32(6):76 - 79.(in Chinese)
[37] 李镇东,罗琦,施力力.基于增加相似度系数的加权二部图推荐算法.计算机科学,2016,43(7):259 - 264.
LI Zhendong,LUO Qi,SHI Lili.Weighted bipartite network recommendation algorithm based on increasing similarity coefficient.ComputerScience,2016,43(7):259 - 264.(in Chinese)
[38] 杨华,周琪云,汤青,等.混合图随机游走算法的商品推荐.小型微型计算机系统,2016,37(11):2433 - 2436.
YANG Hua,ZHOU Qiyun,TANG Qing,et al.Hybrid graph random walk algorithm for commodity recommendation.JournalofChineseComputerSystems,2016,37(11):2433 - 2436.(in Chinese)
[39] ZHOU D,HUANG J,SCHÖLKOPF B.Learning from labeled and unlabeled data on a directed graph∥Proceedingsofthe22ndInternationalConferenceonMachineLearning.Bonn,Germany,2005:1036 - 1043.
[40] ZHOU D,SCHÖLKOPF B.Regularization on discrete spaces∥KROPATSCH W,SABLATNIG R,HANBURY A.PatternRecognition:27thAnnualMeetingoftheGermanAssociationforPatternRecognition.Vienna,AustriaBerlin Heidelberg,2005:361 - 368.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
小学生学习指导(低年级)(2021年12期)2021-12-31
阅读与作文(英语初中版)(2019年8期)2019-08-27
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
中学生数理化·高一版(2017年1期)2017-04-25
