
邻居、信息溢出与企业进口
2018-03-21 08:21吴小康
中南财经政法大学学报 2018年2期
吴小康 韩 剑
(1.南京大学 中美文化研究中心,江苏 南京 210093;2.南京大学 经济学院,江苏 南京 210093)
一、引言
近四十年来,得益于开放型经济和比较优势战略的支持,中国的出口飞速增长,为经济发展做出了巨大贡献,但由于经济结构和政策等原因,进口规模和增速始终慢于出口,造成顺差规模不断扩大,贸易争端频发。为了改善贸易环境,转变对外经济发展方式,近些年中国政府密集出台了一系列举措,将扩大进口上升到战略高度。2012 年、2014年和2015年国务院先后颁布《关于加强进口促进对外贸易平衡发展的指导意见》《关于加强进口的若干意见》《关于促进进出口稳定增长的若干意见》。2015年,习近平主席在博鳌论坛的开幕式主旨演讲中承诺,中国将在未来五年内进口超过10万亿美元。2018年11月中国将举办首届“中国国际进口博览会”。扩大进口战略不仅与中国当前的经济转型目标相契合,而且也有充分的理论依据。在微观层面, Kugler和Verhoogen、Goldberg等、钱学锋等都发现进口能促进企业生产率提高[1][2][3],张杰等、Feng等发现进口能使企业增加出口量[4][5],Amiti和Khandelwal、Fan等发现进口有助于出口质量提升[6][7],Chen等发现进口有利于研发和创新[8];在宏观层面,钱学锋等发现进口能改善贸易条件[9],Broda和Weinstein、陈勇兵等的研究表明进口的数量和种类增加能提升消费者福利[10][11]。这些研究对我们理解进口的经济效益有重要帮助,但鲜有文献进一步就企业如何增加进口展开研究。
针对如何扩大进口,国务院提出了许多建议,包括降低关税水平、加大金融支持、简化通关手续等。除了这些传统手段,国务院指出要“培育国家进口贸易促进创新示范区,充分发挥进口贸易集聚区对扩大进口的示范和带动作用,定期举办进口论坛,交流市场信息,加强进口政策宣传”。其中的关键词之一是“集聚”,但无论在学术还是实践中,集聚通常仅与企业出口或生产等行为相联系,还很少有学者对集聚与进口之间的关系进行严谨的论证。
事实上,与出口一样,在进口活动中,企业也面临着严重的信息壁垒。这些壁垒增加了企业的贸易成本,抑制了企业进口。在扩展边际上,即选择是否进口,进口哪一种产品,从哪个国家进口时,企业无法完全了解市场上是谁在销售其所需要的产品,哪一个供应商的价格最低品质最优。在集约边际上,即进口多少产品时,企业很难确定与其合作的供应商是否具有长期稳定的供给能力。对于进口中间产品的企业而言,如果供应商无法灵活及时地扩大供给,而企业在短期之内又无法找到其他供应商时,企业可能需要承担无法完成生产计划的风险。Rauch和Watson建立了一个搜寻模型来分析这个问题,他们发现企业与新供应商的初始订单规模随其搜寻替代供应商的难度增大而减小,随其生产能力的减小而减小[12]。由于语言、文化、制度等差异,信息壁垒对进口的负面影响可能比国内交易更大。本文的基本假设是,如果企业周围有从事过相似进口活动的邻居,这可能有助于减少企业的信息壁垒,增加企业进口的概率和数量。其一,同行的直接信息溢出。如果邻居能与企业分享其交易信息,特别是那些关于产品和供应商的专业知识,那么企业开始相似进口的概率及进口数量都会增加。其二,示范效应。即便同行无法直接向企业提供相关信息,其进口行为也能间接显示它们的偏好。在基本假设之外,本文进一步提出如下推断:第一,邻居的数量越多,信息溢出越强,企业进口概率越大,进口数量越多。第二,邻居的作用具有特定性。信息壁垒在产品和国家层面都存在,因此那些与企业从同一国家进口同一产品的邻居对企业的溢出作用最大。第三,邻居的作用具有地理限制,由于信息的传播存在成本,那些与企业在同一地区的邻居溢出作用最大。
本文结合2000~2006年的中国海关数据库和工业企业数据库,验证了以上假设。本文的发现主要有:第一,控制企业生产率、规模、企业出口、进口来源国总供给等因素后,邻居越多,企业开始进口的概率越高。并且,加入企业—产品—国家、企业—产品—年份、企业—国家—年份和产品—国家—年份固定效应后,邻居对企业开始进口的影响仍稳健。第二,邻居数量对企业进口概率的提升在经济上也是重要的。邻居数量翻倍,企业开始进口的概率提高14%,相当于使开始进口的无条件概率提高了55%。第三,邻居数量对企业进口的影响存在产品和国家层面的特定性。与企业从同一国家进口同一产品的邻居对企业进口概率的提升作用最大,其他类型的邻居,包括与企业从同一国家进口(不论进口何种产品)的邻居,与企业进口同一产品(不论从哪一国家进口)的邻居,与企业处于同一城市而不论是否从相同国家进口相同产品的邻居,对企业进口概率的提升作用都明显更小。第四,邻居对企业进口概率的影响呈现空间递减的特征。同一城市的邻居对企业进口概率的影响大于同一省份或全国范围的邻居对企业进口概率的影响。第五,邻居对企业进口规模也有显著正向影响。
宽泛地讲,本文是建立在国际贸易中有关信息成本的研究基础上的。这类研究旨在厘清信息成本影响国际贸易的机制和程度,并进一步发掘与信息成本相关的因素。例如,Rauch和Trindade、Bastos和Silva发现移民网络存在信息共享[13][14],Freund和Weinhold发现互联网的普及能减少企业信息获取成本[15],Chaney的研究表明企业会使用其现有的交易网络来寻找新的交易对象[16]。具体而言,本文主要关注的是集聚如何减少信息成本进而影响国际贸易,代表性文献包括Koenig等、Fernandes和Tang、 Hu和Tan等[17][18][19]。这些研究使用不同的数据考察了集聚对出口的影响,但总体而言,随着变量可观测程度的提高,支持集聚减少信息成本促进出口的证据越来越多。但关于出口的结论并不一定适用于进口,原因是:第一,与出口市场相比,在进口市场上,对产品交易信息的需求更少,供给更多,进口商找到供应商可能比出口商找到客户更容易。第二,作为买方,进口商比出口商对产品的了解更少。第三,出口商集聚会竞争生产资源,但进口商集聚的竞争效应可能相对更小。
与本文最相关的是Bisztray等关于邻居对匈牙利企业进口的影响[20]。相对于本文,他们的优势是能够观察到企业的详细地址,从而可以识别同一楼栋或同一街道的邻居对企业进口的影响,而本文最多只能将邻居定义为与企业位于同一城市的其他企业;他们的缺陷是无法观察到企业进口的产品种类,只能识别企业的主营产业,而本文的数据记录了企业进口的产品种类。考虑到信息溢出作用的地理和产品特定性,Bisztray等与本文都存在一定不足。
本文的边际贡献包括:第一,本文研究了邻居对中国企业进口的影响,扩展了Hu和Tan关于邻居对中国企业出口影响的研究[19]。本文的研究表明,在国际市场中,进口企业与出口企业一样面临着信息壁垒,因此邻居的信息溢出有利于企业进口。第二,本文充分利用了数据的细分性,证明信息成本在产品和国家层面都有很强的特定性,为揭示信息成本的特征提供了更多依据。本文的政策价值是为政府通过培育进口集聚区以及举办进口信息交流论坛等措施扩大进口提供了实证依据。
二、数据和变量
本文使用两个数据库:2000~2006年的中国海关数据库和工业企业数据库。海关数据库记录了中国企业的进口交易信息,包括企业代码、企业名称、8位数HS产品代码、进口来源地、交易年月和贸易方式等信息。我们对原始海关数据做如下处理:(1)将月度数据加总到年度,将HS 8位数数据加总到HS 6位数,并将HS 6位数编码统一转换为HS 1996版本;(2)剔除企业代码或企业名称缺失、进口来源地缺失或进口来源地为中国、进口额缺失或进口数量小于0的观测值。工业企业数据库记录了规模以上(年产值500万元以上)工业企业的信息,包括企业名称、企业雇佣人数、中间投入、产出总额和其他资产负债表相关指标。对于工业企业数据的整理,我们完全按照Brandt等的方法,先采用企业代码、企业名称、法定负责人、地区代码、产业代码、成立年份、地址、主营产品名称等信息匹配连续两年的样本,然后匹配连续3年的样本,最后生成7年的面板数据[21]。对于海关数据和工业企业数据的合并,我们参考Fan等的方法,先按企业名称匹配,再按电话号码和邮编匹配,最后按电话号码和法定负责人匹配[9]。
参照Koenig等,我们将企业是否开始进口mfpct定义为[17]:
其中,importfpct是企业f在t年从c国进口p产品的总额。如果企业f在t-1年没有从c国进口p产品,但在t年从c国进口p产品,则将其定义为开始进口;如果企业f在t-1年和t年都没有从c国进口p产品,则将其定义为未开始进口。在本文的数据库中,存在1个企业于样本期内多次开始进口的情形,我们将其全部保留①。举例而言,如果企业在2000~2006年期间的进口情况是0111001(其中1代表有进口,0代表无进口),那么mfpct依次为.1...01(点代表缺失)。要注意的是,如果某企业在样本期内从未从c国进口过p产品,即mfpct依次为.00000,那么它将不被包含在回归分析所使用的样本中,因为回归模型加入了企业—产品—国家固定效应②。也就是说,在构建样本的过程中,我们无需全面考虑一个企业在某一年份可能做出的全部选择,而只需关注企业在样本期内至少进口过的产品—国家对。工业企业和海关数据合并后的样本一共包括63460个企业、4910种产品、195个国家。如果全面地考虑企业是否进口,那么最多可能有608亿个观测值,这显然超出计算机的处理能力,但按我们的定义,最后进入回归的观测值只有5566867个。

表1列出了关键变量的描述性统计结果,邻居数量全部取滞后一期,因此2000年的数据不在样本之内。如表1所示,企业开始进口的无条件概率是26%。与企业处于同一城市并从同一国家进口同一产品的平均邻居数量为12个,明显比其他方法定义的邻居数量少。与企业处于同一城市而不论是否从同一国家进口同一产品的邻居数平均为1549个,是前者的129倍。如果忽略了企业进口产品和国家的差异,而使用宽泛的邻居定义,可能导致研究结果有偏。另外,即使是同一城市的企业,从不同国家进口不同产品的邻居数量差异也很大,这一方面为我们的估计提供了足够变化,另一方面再次说明城市层面宽泛的邻居数不能代表从事相同活动的邻居数。

表1 关键变量的描述性统计分析
数据来源:作者根据2000~2006年海关数据库和工业企业数据整理,邻居数量全部滞后一期。
为了初步考察邻居数量与企业进口概率之间的关系,我们暂不考虑邻居数量的多少,先将企业分为有邻居和无邻居(在企业—产品—国家层面)两种类型。统计显示,无邻居未开始进口的企业占27.56%,无邻居开始进口的企业占5.64%,有邻居未开始进口的企业占46.47%,有邻居开始进口的企业占20.33%。在无邻居的企业中,开始进口企业数与未开始进口企业数之比是0.20;在有邻居的企业中,开始进口企业数与未开始进口企业数之比是0.44。这说明,有邻居的企业明显进口概率更高。
三、实证模型
本文的因变量是一个二值变量,对于这类数据,通常用logit或probit模型来估计,但Bastos 和Silva都指出,当模型中的固定效应很多时,logit或probit估计可能存在不一致问题,线性概率模型估计可能更加准确[14]。因此,本文采用如下线性概率模型来估计邻居对企业开始进口的影响:

Moulton认为,个体变量对总体变量进行回归时,可能会低估标准误,因此我们使用按城市聚类的稳健标准误[23]。另外,在估计线性概率模型时,我们采用了Stata中的REGHDFE命令。Correia指出,高维数据中存在很多单一组(同一个固定效应下只有1个观测值的组,例如本模型中同一企业—产品—国家维度下只有1个观测值的组),保留这些单一组可能导致错误的估计和推断[24]。与常用的XTREG命令相比,REGHDFE不仅能直接删除样本中的单一组,且计算速度更快。
四、估计结果
(一)基本估计结果
表2列出了基本估计结果。前4列采用线性概率模型,后4列采用固定效应logit模型。从左至右,模型的控制变量逐渐增加。第(1)列仅加入企业所在地区从相同国家进口相同产品的邻居数量。与预期一致,邻居数量在1%水平上显著为正,说明企业所在城市邻居数量越多,企业开始进口的概率越高。第(2)列加入企业层面的两个变量,分别是用雇佣总人数表示的企业规模和用LP方法估算的企业全要素生产率。企业规模和生产率是决定企业进口的重要因素,也可能和邻居数量正相关,因为规模越大、生产率越高的企业越可能聚集在一起。企业规模和生产率的估计系数都显著为正,说明规模越大、生产率越高的企业开始进口的概率越高。控制这两个变量后,邻居数量的估计系数基本没有变化。第(3)列进一步考虑了进出口之间的相关关系,控制了企业出口相同产品到相同国家的数量。估计结果显示,企业出口相同产品到相同国家的数量越多,企业开始从那个国家进口相同产品的概率越高。第(4)列考虑了进口来源国的供给。如果进口来源国经济环境恶化,企业生产能力下降,那么出口可能减少,从而影响企业进口。为了控制这一变化,我们在模型中加入进口来源国产品层面对中国以外国家的出口数量总和,数据来源于BACI。由于部分国家的出口数据缺失,样本规模相比前几列略有减少。结果显示,进口来源国出口总额的估计系数在5%水平上显著,说明进口来源国的总出口越多,中国企业的进口越多。控制这一因素后,邻居数量的估计系数仍显著,且大小无明显变化。
表2的后4列采用固定效应logit模型来完成估计(使用Stata中的CLOGIT命令),该模型与LPM模型的主要区别是其假设进口概率与解释变量之间服从累积logistic分布。若被解释变量在同一企业—产品—国家维度下没有变化,logit估计会将其从样本中剔除,因此后4列的样本规模相比前4列有所下降。估计结果所示,邻居数量的估计系数在后4列中仍显著为正,其他变量的显著性也与前4列一致。至于估计系数大小,通常无法直接比较固定效应logit模型和线性概率模型的估计结果,因为不能算出前者的边际效应。以第(8)列为准,我们只能在固定效应为0的假设前提下,算出邻居数量的平均边际效应为1.008,即邻居数量增加1%将导致企业开始进口的概率提高1.008%。对于线性概率模型,以第(4)列为准,邻居数量增加1%将导致企业开始进口的概率提高0.206%。也就是说,条件logit模型的估计结果高于线性概率模型,但这是在假设固定效应为0的前提下得到的。

表2 邻居对企业开始进口的影响:基本估计
注:*p表示<0.1,**表示p< 0.05,***表示p<0.01。括号中是按城市聚类的稳健标准误。如无特别说明,下表同。
(二)稳健性检验
1.更多的控制变量和固定效应
为了识别邻居与企业进口的因果关系,我们在基本估计中尽量控制了那些可能影响进口并与邻居数量相关的因素,包括企业生产率、企业规模、企业出口、进口来源国的总出口,但仍可能有潜在的遗漏变量。表3的第(1)列进一步加入企业进口相同产品的国家数以及从相同国家进口的产品数,前者反映企业联系国外供应商的经验和能力,企业已进口国家数越多,经验越丰富,从新国家进口的成本越低;后者用来反映产品层面的范围经济,从一个国家同时进口几种产品的平均成本可能低于单独进口一种产品的平均成本。这两个变量都与企业能力正相关,而能力高的企业更倾向聚集在一起。估计结果表明,当企业进口相同产品的国家数越多时,企业从一个新的国家进口这种产品的概率越高;企业从相同国家进口的产品种类越多时,企业从相同国家开始进口一种新产品的概率越高。控制企业的进口经验后,进口溢出的作用仍然为正且显著。第(2)列则以企业进口的产品—国家数取代产品数和国家数,结果基本相同。
考虑到本文数据的高维特征,为了更好地控制潜在的遗漏变量,我们在模型中加入更严格的固定效应。但要注意的是,加入的固定效应越多,企业进口和邻居数量剩下的独立变异程度越小,估计的精确程度越低。表3第(3)~(6)列逐步加入更多的固定效应。第(3)列以国家—年份固定效应取代了年份固定效应,以控制国家层面随年份变化的变量,例如人民币汇率波动、区域贸易协定、两国贸易关系变化等因素。第(4)列以产品—国家—年份固定效应取代了国家—年份固定效应,以控制同时随产品、国家和年份变化的因素,例如进口关税税率、进口来源国的供给、进口来源国在产品层面上的出口政策变化。第(5)列在第(4)列的基础上进一步加入企业—国家—年份固定效应,以控制企业层面随国家和年份变化的因素。这一固定效应将企业生产率、雇佣人数、企业从相同国家进口的产品种类数完全吸收,因为这三个变量只随企业—年份或国家—年份变动。此外,企业—国家—年份固定效应还能控制企业层面的其他因素,例如企业所有制性质、企业进口经验等。第(6)列进一步加入企业—产品—年份固定效应,以控制那些随企业—产品—年份变动的因素。这一固定效应将企业进口相同产品的国家数完全吸收。对于企业—产品—国家—年份的四维数据,第(6)列是条件允许下所能采用的最严格的模型。需要注意的是,尽可能多加入固定效应可以减少遗漏变量偏误,但也使溢出程度的独立变动大幅减少。因此,从第(4)列到第(6)列,随着固定效应增强,样本规模减少,邻居的估计系数也逐渐下降,但在所有模型中都显著为正,说明原始模型可能存在与邻居数量相关的变量被遗漏。
2.关键变量的测量方法调整
接下来讨论关键变量的测量。首先是因变量的度量问题,在前面的估计中,我们将开始进口定义为t-1年不进口而t年开始进口,将未开始进口定义为t-1年和t年都不进口。在这一定义下,可能存在重复进入问题,即部分企业从某一个国家开始进口某一种产品后,中途停止进口,之后重新开始进口。造成重复进入的原因可能是统计误差,即停止进口的年份实际上存在进口;也可能是企业的正常行为。如果是统计误差,那应该剔除这些重复进口的观测值;如果是正常行为,那仍然有理由怀疑企业第一次开始进口和第二次开始进口受溢出作用的影响不同。为了确保重复进入不会影响估计结果,表4的第(1)列将重复进入的观测值(大概占全部观测值的10%)全部剔除,第(2)列则仅保留第1次开始进口的观测值。我们采用表3第(6)列的模型设定,也就是加入企业—产品—国家、企业—产品—年份、企业—国家—年份、产品—国家—年份固定效应。在这两种处理方式下,样本规模继续缩小,但邻居数量的估计系数仍然显著。第(3)列和第(4)列则考虑了企业开始进口这一行为存在的偶然性,采用更严格的方法来定义开始进口,即企业不仅开始进口,而且能够持续进口。根据我们的统计,样本中新开始的进口中,约有70%能够在第2年继续进口。第(3)列将开始进口定义为t-1年不进口,t年和t+1年都进口;将未开始进口定义为t-1年和t年都不进口或者t-1年不进口,t年开始进口且t+1年不进口,也就是企业开始进口后至少继续再进口1年。由于样本截断问题,无法观察2006年开始进口的企业是否能在下一年继续进口,我们将2006年数据从样本中剔除。第(4)列将开始进口定义为t-1年不进口,t年、t+1年、t+2年都进口,也就是企业开始进口后至少再连续进口2年。在这两种定义下,样本规模大幅下降,但邻居数量的估计系数仍然显著。与表3第(6)列相比,估计系数明显更小,说明邻居溢出对企业暂时进入进口市场的影响大于对企业持续进口的影响。
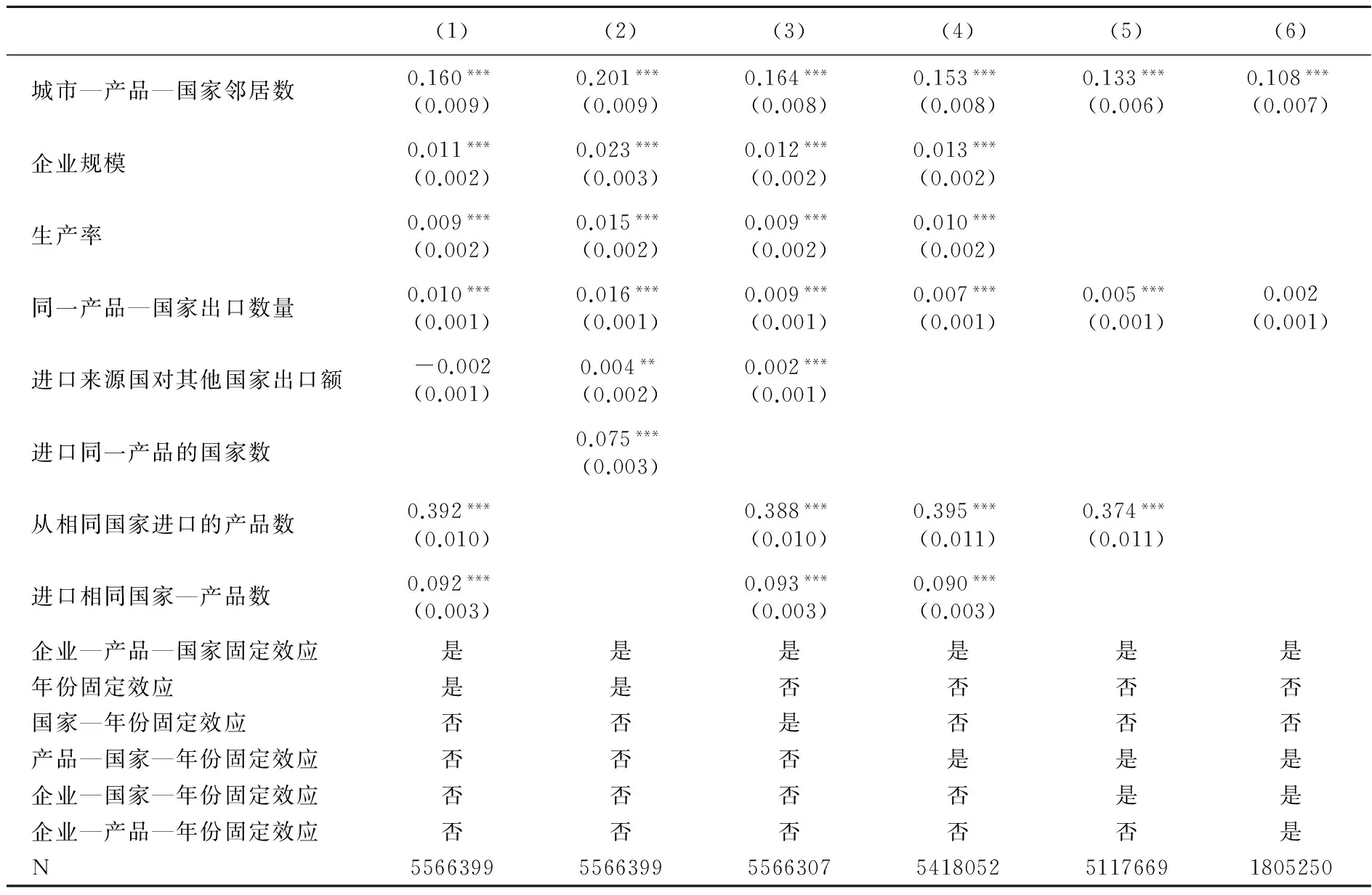
表3 邻居对企业开始进口的影响:更多的控制变量和固定效应
注:所有模型都采用线性概率模型估计,下表(除表8外)同。
其次是邻居的度量问题。前面的估计都用企业数量来度量溢出,这实际上假设所有邻居对企业有相同的溢出作用,但溢出程度可能与企业规模有关,企业从大规模邻居得到的溢出可能更大。第(5)列用企业所在城市从相同国家进口相同产品的其他企业进口总量来度量溢出。如表4所示,邻居进口数量的估计系数显著为正。
3.其他问题
上文的所有估计都采用按城市聚类的标准误,如果将标准误聚类在城市—产品—年份、城市—产品—国家层面、城市—产品、城市—国家—年份,得到的标准误更小,估计结果仍显著,如表5第(1)列所示(仅列出按城市—产品—年份聚类的标准误,其他结果类似)。截至目前,我们使用的都是工业企业数据库和海关数据库匹配的样本。由于工业数据库仅包含全部国有企业和规模以上(年产值在500万元以上)的非国有企业,而海关数据库包含全部企业的交易,这会导致部分企业被排除在匹配的样本之外。为了确保这不会影响估计结果,我们使用未匹配的海关数据重新估计模型。如表5的第(2)列所示,使用未匹配的数据导致样本规模大幅增加,但进口溢出的估计系数仍显著为正。第(3)列剔除了广东、江苏、浙江、山东和上海5个外贸集中的地区,邻居数量在剩下的地区中,仍然对企业开始进口有显著的正向影响。第(4)列仅保留那些在企业—产品—国家层面有两个以上企业的城市。第(5)列将邻居数量多于50个(90%分位数)的观测值剔除。如估计结果所示,这些调整对邻居数量的估计系数没有显著影响。

表4 邻居对企业开始进口的影响:关键变量的测量方法调整
注:所有模型都加入企业—产品—国家、企业—产品—年份、企业—国家—年份、产品—国家—年份固定效应。

表5 邻居对企业开始进口的影响:其他稳健性检验
注:第(1)列括号中是按城市—产品—年份聚类的稳健标准误,第(2)~(5)列括号中是按城市聚类的稳健标准误。所有模型都加入企业—产品—国家、企业—产品—年份、企业—国家—年份、产品—国家—年份固定效应。
(三)邻居作用的经济显著性
到目前为止,我们只证明了邻居对企业进口的作用是统计显著的,尚未讨论其在经济上的重要程度。我们可从以下两个角度来说明经济重要性:首先,我们以表2第(4)列的估计结果为准,邻居数量在这一列中的估计系数是0.206。这说明,邻居数量每增加1%,企业开始进口的概率提高0.206%;或者说,当邻居数量从均值处增加1个时,企业开始进口的概率提高0.016%(0.206×(ln13-ln12))。这并不是显著的提升,但如果邻居数量翻倍,企业开始进口的概率将提高14.28%(0.206×ln(1+100%))。在样本中,企业开始进口的比例(也就是企业开始进口的无条件概率)是26%,邻居数量翻倍,相当于使开始进口的无条件概率提高了54.92%(14.28/26)。


表6 邻居作用的经济显著性
数据来源:作者根据表2第(4)列估计结果计算。
五、进一步分析
(一)邻居溢出作用的特定性
上文将邻居对企业进口的影响限定在同一产品和国家,但那些进口不同产品或从不同国家进口的邻居对企业进口也可能有影响。具体而言,我们将这些邻居分为以下四种类型:从相同国家进口相同产品、从相同国家进口不同产品、从不同国家进口相同产品、从不同国家进口不同产品。因为无法再同时加入产品—国家—年份、企业—国家—年份、企业—产品—年份固定效应,我们采用表2第(4)列的模型(但加入进口同一产品的国家数和从相同国家进口的产品数)来估计不同类型的邻居对企业进口的影响。表7列出了回归结果,第(1)列识别的是城市—产品—国家层面的溢出对进口概率的影响,与表2第(4)列相同。第(2)列识别的是城市—产品层面的溢出,用企业所在城市与之进口相同产品但从不同国家进口的企业数衡量。第(3)列识别的是城市—国家层面的溢出,用企业所在城市与之从相同国家进口但进口不同产品的企业数衡量。第(4)列识别的是城市层面的溢出,用企业所在城市与之从不同国家进口不同产品的企业数衡量。第(5)列识别的是省份—产品—国家层面的溢出,用企业所在省份但不同城市与之从相同国家进口相同产品的企业数衡量。第(6)列识别的是全国—产品—国家层面的溢出,用在中国但不同城市与之从相同国家进口相同产品的企业数衡量。

表7 邻居对企业开始进口的影响:溢出作用的特定性
注:所有模型都加入企业—产品—国家固定效应和年份固定效应。
表7第(2)~(4)列的估计结果显示,城市—产品层面的溢出作用仍然显著,但溢出程度大约只有城市—产品—国家层面溢出作用的1/2;城市—国家层面的溢出作用也显著,但溢出程度更小;城市层面的溢出作用则不显著区别于0。这说明,溢出作用在产品和国家层面上都存在着特定性,且产品的特定性更强。第(5)~(6)列的估计结果显示,省份—产品—国家层面的溢出作用和全国—产品—国家层面的溢出作用仍然显著,但溢出程度存在明显的空间衰减。与第(1)列的估计结果相比,同一省份但不同城市的邻居对企业进口概率的影响约为同一城市的邻居对企业进口概率影响的70%,全国范围内但不同城市的邻居的影响进一步降低到60%。这说明,溢出作用在地理上表现出明显的空间衰减。总体而言,表7说明,溢出作用在产品、进口国和地理上都存在着特定性,与企业位于同一城市并从相同国家进口相同产品的邻居对企业的溢出作用最大。
(二)邻居对进口规模的影响
邻居不仅能提高企业开始进口的概率,而且可能影响企业的进口规模。表8估计了邻居对企业进口规模的影响,其估计模型与表7的模型相似,区别是因变量为企业进口额(使用进口数量结果也一致)的对数。所有解释变量都滞后一期,因此我们估计的是企业在过去一年至少有进口(不论产品和国家)的条件下邻居对企业下一年进口规模的影响。
表8与表7各列一一对应。如表8第(1)列所示,邻居数量的估计系数在1%水平上显著为正。控制其他因素不变,邻居数量增加1%,企业进口额增加18.9%。另外,在加入更多固定效应后,邻居数量的估计系数仍显著。第(2)~(4)列依次用进口相同产品的邻居数、从相同国家进口的邻居数、不论产品和国家的邻居数替代产品—国家层面的邻居数。估计结果显示,其他类型邻居数的估计系数相对更小,说明邻居溢出在产品和国家层面都存在特定性。第(5)列和第(6)列依次用省份—产品—国家层面的邻居数、全国—产品—国家层面的邻居数替代城市—产品—国家层面的邻居数,这两种邻居数的估计系数都更小,说明从进口额来看,邻居的溢出也表现出空间递减。

表8 邻居对企业进口规模的影响
注:因变量是企业进口额的对数。所有模型都加入企业—产品—国家固定效应和年份固定效应。
六、结论
基于2000~2006年的中国海关数据库和工业企业数据库,本文估计了邻居对企业进口的影响。本文发现:首先,邻居对企业进口概率和进口规模都有统计上和经济上的显著影响。其次,邻居的作用存在产品和国家层面的特定性,相比与企业进口不同产品的邻居以及与企业从不同国家进口的邻居,与企业从同一国家进口同一产品的邻居对企业进口概率和进口规模的促进作用明显更大。最后,邻居的作用表现出空间递减,同一城市的邻居比同一省份和省外的邻居对企业进口的影响更大。相对于有关集聚、溢出与企业行为的研究,本文充分利用数据的高维特征,通过加入企业—产品—国家、企业—产品—年份、企业—国家—年份、产品—国家—年份等固定效应,很好地控制了可能存在的遗漏变量偏误,厘清了邻居与企业进口之间的因果关系。
从理论上来讲,本文从进口的角度证实信息壁垒阻碍国际贸易,并且,信息壁垒具有产品和国家层面的特定性,以及空间范围的衰减性。从政策角度来讲,本文的结论为政府从市场信息这一角度制定相应的扩大进口政策提供了依据。由于市场信息具有很强的正外部性,企业愿意共享的信息量必然少于社会实际需要的信息量,因此政府有必要提供这一公共产品。具体而言,政府可以建立专业的进口咨询服务平台,适当举办进口信息交流论坛,加强进口信息的搜集和宣传,增加对国外市场行情的调研和宣传,激励有经验的企业分享进口经验,并且,在实施这些政策时,要充分了解企业的地区和行业特征,提高政策的针对性。
注释:
①在稳健性分析中,我们会丢掉多次开始进口的观测值,或者仅保留第1次开始进口的观测值。
②在回归分析中,如果个体在企业—产品—国家层面无变化,那么它将不被使用。
③进口企业通常会同时报告进口地和消费地,企业编码的前4位代表进口地,也就是企业所在地。是否会存在消费地邻居而非进口地邻居影响企业进口的情况呢?我们认为无需担心这一问题,首先,由于进口地是企业的主要经营活动所在地,企业应主要从进口地了解海外供应商的信息;其次,剔除中间商之后,进口地和消费地不一致的企业仅占极少数。感谢审稿人指出这一问题。
[1] Kugler,M.,Verhoogen,E.Plants and Imported Inputs:New Facts and an Interpretation[J].American Economic Review,2009,99(2):501—507.
[2] Goldberg,P.K.,Khandelwal,A.K.,Pavcnik,N.,Topalova,P.Imported Intermediate Inputs and Domestic Product Growth:Evidence from India[J].The Quarterly Journal of Economics,2010,125(4):1727—1767.
[3] 钱学锋,王胜,黄云湖,王菊蓉.进口种类与中国制造业全要素生产率[J].世界经济,2011,(5):3—25.
[4] 张杰,郑文平,陈志远,王雨剑.进口是否引致了出口:中国出口奇迹的微观解读[J].世界经济,2014,(6):3—26.
[5] Feng,L.,Li,Z.Y.,Swenson,D.L.The Connection between Imported Intermediate Inputs and Exports:Evidence from Chinese Firms[J].Journal of International Economics,2016,101(6):86—101.
[6] Amiti,M.,Khandelwal,A.K.Import Competition and Quality Upgrading[J].Review of Economics and Statistics,2013,95(2):476—490.
[7] Fan,H.,Li,Y.A.,Yeaple,S.R.Trade Liberalization,Quality,and Export Prices[Z].Working Paper,2014.
[8] Chen,Z.,Zhang,J.,Zheng,W.Import and Innovation:Evidence from Chinese Firms[J].European Economic Review ,2017,94(4):205—220.
[9] 钱学锋,陆丽娟,黄云湖,陈勇兵.中国的贸易条件真的持续恶化了吗?——基于种类变化的再估计[J].管理世界,2010,(7):18—29.
[10] Broda,C.,Weinstein,D.E.Globalization and the Gains from Variety[J].The Quarterly Journal of Economics,2006,121(2):541—585.
[11] 陈勇兵,李伟,钱学锋.中国进口种类增长的福利效应估算[J].世界经济,2011,(12):76—95.
[12] Rauch,J.E.,Watson,J.Starting Small in an Unfamiliar Environment[J].International Journal of Industrial Organization,2003,21(7):1021—1042.
[13] Rauch,J.E.,Trindade,V.Ethnic Chinese Networks in International Trade[J].Review of Economics and Statistics,2002,84(1):116—130.
[14] Bastos,P.,Silva,J.Networks,Firms,and Trade[J].Journal of International Economics,2012,87(2):352—364.
[15] Freund,C.L.,Weinhold,D.The Effect of the Internet on International Trade[J].Journal of International Economics,2004,62(1):171—189.
[16] Chaney,T.The Network Structure of International Trade[J].American Economic Review,2014,104(11):3600—3634.
[17] Koenig,P.,Mayneris,F.,Poncet,S.Local Export Spillovers in France[J].European Economic Review,2010,54(4):622—641.
[18] Fernandes,A.P.,Tang,H.W.Learning to Export from Neighbors[J].Journal of International Economics,2014,94(1):67—84.
[19] Hu,C.,Tan,Y.Export Spillovers and Export Performance in China[J].China Economic Review,2016,41(5):75—89.
[20] Bisztray,M.,Koren,M.,Szeidl,A.Learning to Import from Your Peers[Z].Working Paper,2017.
[21] Brandt,L.,Van Biesebroeck,J.,Zhang,Y.F.Creative Accounting or Creative Destruction? Firm-level Productivity Growth in Chinese Manufacturing[Z].NBER Working Paper Series,2012.
[22] Levinsohn,J.,Petrin,A.Estimating Production Functions Using Inputs to Control for Unobservables[J].Review of Economic Studies,2003,70(2):317—341.
[23] Moulton,B.R.An Illustration of a Pitfall in Estimating the Effects of Aggregate Variables on Micro Units[J].Review of Economics and Statistics,1990,72(2):334—338.
[24] Correia,S.Linear Models with High-dimensional Fixed Effects:An Efficient and Feasible Estimator[Z].Working Paper,2017.
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
小猕猴智力画刊(2021年11期)2021-11-28
中学生数理化·中考版(2021年6期)2021-11-22
心理学报(2021年9期)2021-09-09
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
儿童故事画报·自然探秘(2016年4期)2016-06-24
科学启蒙(2016年5期)2016-05-10
上海预防医学(2014年2期)2014-06-03
为了孩子(孕0~3岁)(2014年5期)2014-05-21
