
一种混合CPU和GPU的图像金字塔数据重采样评估模型∗
2018-03-20 07:05郝瑞华
计算机与数字工程 2018年2期
郝瑞华 鲁 强
(中国石油大学(北京)计算机科学与技术系 北京 102249)
1 引言
在大规模图像可视化应用中,往往涉及到数百MB到数百GB的地形数据[1]。对要显示的数据进行绘制时,则会产生庞大的运算量。构建图像多分辨率金字塔索引是解决这一问题最有效的方法之一。如王文珊深入研究传统的分层可伸缩编码架构,提出了一种新的金字塔数据模型生成与压缩的方法[2]。张云舟等提出一种沿图像纹理方向滤波的降采样方法 TDFA(texture direction filtering ap⁃proach),可生成高质量的空间影像金字塔[3]。曾志等利用集群对遥感影像并行处理算法进行了优化[4],但是图像金字塔存在一个明显的缺点,即图像金字塔只能存储固定分辨率的地理图像,不能读取任意分辨率的图像数据。当显示图像分辨率与图像金字塔中所存图像分辨率不一致时,就需要对图像金字塔中最接近要显示分辨率的图像数据进行重采样。而传统的重采样方法是利用CPU进行串行重采样,对于较大的图像块,其重采样速度较慢。虽然GPU能够利用并行处理来加快图像重采样速度,如吕向阳分析了图像的双线性插值算法和立方卷积插值算法,给出了这两种算法的GPU实现[5],但是在其重采样过程中,图像数据需要经过主机内存与GPU存储之间的传输,影响重采样效率。因而可以针对CPU和GPU自身的优势,对CPU-GPU异构计算模型进行研究,Zhao J等设计了一个利用CPU-GPU平台进行遥感图像融合的并行计算模型[6]。Ravishankar M等提出了一种跨GPU和多核CPU架构进行图像处理的领域特定语言,允许编译器处理冗长和易出错的任务,同时为多个目标体系结构生成高效代码[7]。Teodoro G等针对大数据集的高分辨率病理组织图像设计了GPU-CPU计算平台[8]。本文通过建立RECG模型根据图像数据规模来评估在CPU和GPU中重采样的效率,以决定合适的重采样场所(CPU或GPU),便于CPU和GPU共存协作,各自发挥在图像重采样中的优势,并在此基础上分别设计了基于CPU和GPU的图像数据缓存策略,有效地加快了图像重采样速度。
2 RECG模型
通过分析和对比基于CPU和GPU重采样的方式,来建立选择CPU或GPU进行重采样的评估模型,并给出评估算法。
2.1 CPU重采样和GPU重采样的算法对比
2.1.1 算法流程对比
1)基于CPU进行重采样的算法流程如下:
根据指定的地理范围,将接近所要求分辨率的图像金字塔数据从外部存储设备读入主机内存。利用指定的重采样算法,对读入主机内存的图像金字塔数据进行重采样。将重采样后的图像数据进行显示。具体过程如图1所示。

图1 CPU重采样流程
2)基于GPU进行重采样的算法流程如下:
根据指定的地理范围,将接近所要求分辨率的图像金字塔数据从外部存储设备读入主机内存。将读入主机内存中的数据传输至GPU存储存储。在GPU中利用指定的重采样算法,对读入的数据进行重采样。将重采样的结果传递至主机内存。具体过程如图2所示。

图2 GPU重采样流程
2.1.2 对比分析
虽然GPU图像重采样速度快,但是GPU图像重采样比CPU图像重采样增加了主机内存与GPU存储之间数据传输的过程。当GPU进行图像重采样时,图像数据在主机内存与GPU存储之间的传输时间和GPU图像重采样所用的总时间如果小于CPU图像重采样时间,则利用GPU进行重采样,反之则利用CPU进行图像重采样。因此,在对图像进行重采样时,需要建立一个模型来评估不同数据规模和分辨率图像利用CPU或GPU进行图像重采样的效率。在此基础上,为加快重采样速度,根据图像可视化特点设计缓存策略,将一部分图像金字塔中的数据缓存在缓存中。当进行图像重采样时,可减少图像块数据在不同类型存储之间的读取次数,从而提高效率。
2.2 RECG模型
根据以上分析,设CPU重采样时间为t(CPU),CPU对单个像素点进行重采样用的时间为t(sp),CPU对图像金字塔数据进行重采样的总时间为T(CPU)。主机内存与GPU存储之间的数据传输时间为t(hd),GPU进行重采样时间为t(GPU),GPU存储和主机内存之间的数据传输时间为t(dh),GPU对图像金字塔数据进行重采样的总时间为T(GPU),重采样结果图像的长宽为aw像素和ah像素,单个像素的通道数为n,重采样之前的图像长宽为bw像素和bh像素,重采样的缩放倍率为s,GPU重采样相对于CPU重采样的加速比为λ,主机内存与GPU存储之间的数据传输速度为vi,GPU存储与主机内存间的传输速度为vo,则有:
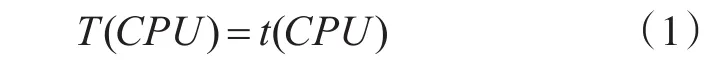
GPU的重采样总时间为数据在主机内存和GPU存储之间的传输时间和对图像进行重采样的时间之和,如式(2)所示:

CPU对图像进行串行重采样,则CPU重采样的时间与结果图像的大小成正比。则有:

根据式(1)和(3),则得到CPU重采样的总时间为
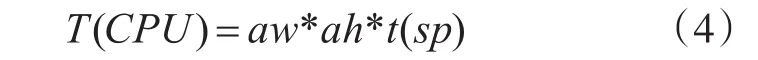
由数据量与传输速度的关系,则数据在主机内存和GPU存储之间的传输时间为

数据在GPU存储和主机内储之间的传输时间为

根据缩放倍数的关系则有:bw=aw/s,bh=ah/s,在式(5),用aw,ah,s替换bw,bh有:

根据加速比的关系,有t(GPU)=λ*t(CPU),根据式(3),将

分别用式(6~8)中的推导结果代替式(2)中的相关变量,则有:
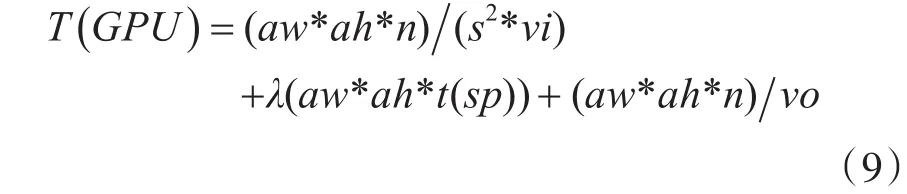
设m为CPU和GPU重采样总时间的比值,则m=(4)/(9),得到经验公式:
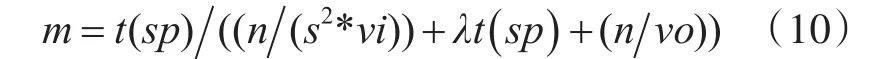
在式(10)中,vi,vo,t(sp)是常量,与具体计算设备型号相关,通过提前测试实验获得。n表示通道数,是一个常量,由图像属性决定。λ也是常量,也与具体具体设备型号有关,通过拟合在同一图像块大小相同缩放倍率条件下的t(CPU)和t(GPU)数据可以得到。因此在式(10)中,只有缩放倍数s是个变量。因为m表示CPU与GPU重采样时间的比值,所以可以通过m的值来判断是利用CPU还是GPU进行重采样。当m>1时,用GPU进行重采样,当m≤1时用CPU进行重采样。因此,利用式(10)来判断是使用GPU还是CPU进行图像重采样。
3 金字塔层图像数据的重采样调度算法
在已经建立的RECG模型基础之上,建立图像金字塔图像块的调度算法,以达到对金字塔图像进行重采样的目的。
3.1 对金字塔图像块的编码
3.1.1 图像金字塔模型
图像金字塔模型是一种四叉树结构,如图3所示。

图3 四叉树格式
如图3所示,图像金字塔每一层都代表不同分辨率的图像数据,由图像块组成,可以按照四叉树模型结构对图像块进行递归分解。
3.1.2 图像金字塔图像块编码
对于图像金字塔的每一层,可以按照从左到右,从上到下的顺序对图像块进行编码,则每一个图像块在图像金字塔中的唯一索引为(l,tx,ty),其中l为图像块所在的金字塔层数,tx为图像块横坐标,ty为图像块纵坐标。如图4对图3中图像金字塔第0层进行编码,灰色图像块的坐标为(0,3,1)。

图4 图像块编码
3.1.3 像素点坐标和图像块坐标关系
如果已知金字塔图像l层的一个像素点的坐标为(px,py),图像块的宽和高为w,h,则此像素点在本层所在的图像块坐标为

已知第m层的一个像素坐标为(px,py),则此像素在第n层所对应的像素坐标为
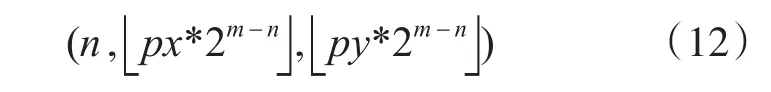
已知第m层的图像宽度和高度为mpw,mph,则在第n层时图像的宽度npw和高度nph变为
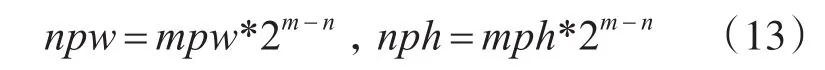
3.1.4 每层图像块之间的拓扑关系
图像块拓扑关系包含同一层内部邻接关系和上下层之间的双亲与孩子关系两个方面[9]。已知一个图像块的坐标为(l,tx,ty),则:
1)按照从左到右,从上到下的顺序,下层孩子节点的坐标分别为[10]
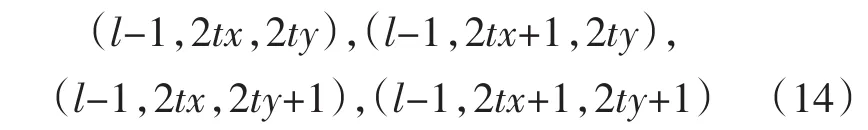
2)此图像块的双亲图像块坐标为
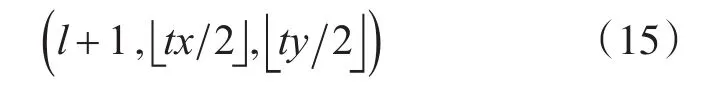
3.2 基于LRU的CPU-GPU缓存调度策略
LRU(Least Recently Used),即近期最少使用算法。由于在图像显示过程中,多次被调用过的图像块,近期被访问的概率仍然很大,所以本文的调度算法借鉴了LRU的思想,在GPU存储和主机内存分别都添加了一个LRU队列,GPU存储中的LRU队列用于存储近期在GPU中重采样过的图像金字塔图像块的数据,内存中的LRU队列则是存储了近期参与CPU重采样的图像块数据,以及这些图像块的双亲和孩子节点。为了节省GPU存储的存储空间,GPU中存储的图像块的孩子节点和父节点的图像数据也存储在主机内存中。通过对图像块数据进行缓存,可以减少图像块数据在不同类型存储之间的读取次数,以提高重采样的速度。
3.3 重采样调度算法
预设GPU存储中的LRU队列为dlrulist,在主机存储中的LRU队列hlrulist。算法的核心流程如图5所示。
输入:要显示的图像的起始像素点在原始图像中起始坐标(sx,sy),要显示的图像的宽度为bw像素,高度bh像素,图像缩放以后的宽度和高度aw像素和ah像素。
输出:重采样以后的结果图像数据。
过程:
1)计算scaleNum=aw/bw。则根据scaleNum的值,选择最接近这个缩放倍数的金字塔的层数l。
2)根据金字塔层数l,计算本层的缩放倍率为lScaleNum,分别计算本层的图像块还需要缩放的倍数为:realScaleNum=scaleNum/lScaleNum。
3)根据式(12),可以求出要显示的原始图像的起始像素坐标在l层上对应的像素坐标,记为(lsx,lsy)。根据式(13),求bw,bh在l层出对应的宽度和高度lbw,lbh。
4)根据式(11)和lsx,lsy,lbw,lbh可以求出要显示的图像在图像金字塔第l层所对应的起止图片块的坐标,记为(l,stx,sty),(l,etx,ety)。
5)根据4)求出的图片块的起止坐标,得出显示图像所需要的本层所有图像块的坐标,通过图像块的坐标生成图像标识。
6)根据RECG模型,以及2)中求出的缩放倍数,判断是否是GPU重采样,是则转7)否则转8)。
7)遍历5)的结果,根据图像标识在dlrulist中查找是否包含相应的图像块,如果不包含,则根据图像标识在hlrulist中寻找相应的图像块,如果在hlrulist存在,则直接从主机内存中加载相应的图像块到GPU存储,并将图像信息存储在dlrulist中,如果在hlrulist不存在,则从外部存储加载相应图像块到GPU存储,并将图像存储在dlrulist中,判断是否此图像块存在双亲节点或者孩子节点,如果存在,则启动预加载线程,并行地将此图像块的双亲节点和子节点加载到hrulist中。当所需的图像块都在GPU存储中,则利用GPU实现对图像块的重采样。
8)遍历5)的结果,根据图像标识在hlrulist中寻找相应的图像块,如果所需图像块不存在,则从外部存储加载相应图像块到内存,并将图像信息存储在hlrulist中。当所需的图像块全部在内存中,则接下来利用CPU进行重采样。判断如果此图像块存在双亲节点或者子节点,则启动预加载线程,并行地将此图像块的双亲节点和子节点加载到hrulist中。

图5 运行时图像块调度流程图
4 实验及分析
实验设备为单台计算机,显卡为NVIDIA Ge⁃Force GT520M显卡,支持CUDA架构,显存大小为1024M,支持的2D纹理的最大高度为65535,最大宽度为65536。CPU为Intel Core2 i5-2410M,4核,2.3GHz。图像的通道数为4,插值算法为双线性插值。实验首先在不同图片块大小的图像金字塔条件下,分别测试CPU和GPU的重采样时间来验证RECG模型的正确性。接着进行了RECG算法与开源栅格空间数据转换库GDAL(Geosp-atial Data Abstraction Library)中的图像重采样算法重采样效率对比。
4.1 RECG模型验证实验
实验结果如表1~表4所示(表格中各变量的含义见2.2节):

表1 8192*8192图片大小下GPU和CPU重采样耗时(ms)
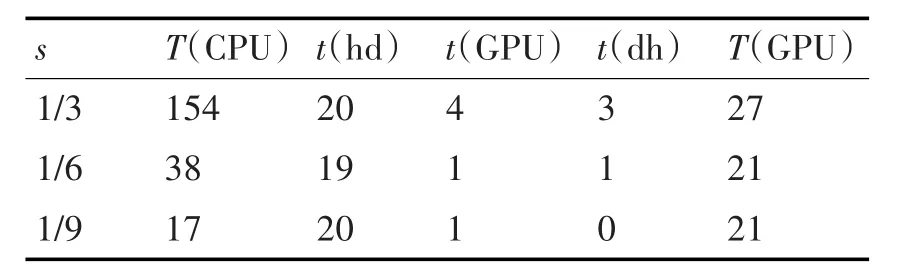
表2 4096*4096图片大小下GPU和CPU重采样耗时(ms)

表3 2048*2048图片大小下GPU和CPU重采样耗时(ms)

表4 1024*1024图片大小下GPU和CPU重采样耗时(ms)
通过以上结果可以得出:
1)由于数据在内存和GPU存储之间的传递需要消耗时间,利用GPU进行重采样的速率并不一定优于利用CPU进行重采样的速率。
2)通过试验结果数据中CPU重采样所用时间,以及图像块的像素数量,可以计算出对CPU单个像素点进行重采样用的平均时间为=0.083us。
3)利用实验结果数据,对在同一图像块大小相同缩放倍率下测得的t(CPU)(即表中T(CPU))和t(GPU)数据进行拟合,可以得到CPU重采样时间和GPU重采样时间之间的关系,如图6所示。
由拟合结果可知,在本实验环境下,进行重采样时,t(CPU)与t(GPU)的关系,符合线性关系,根据这个趋势线可以近似得出,GPU重采样相对于CPU重采样的加速比为λ=0.0243。
4)通过GPU带宽测试程序10次测量得到表5中的数据。
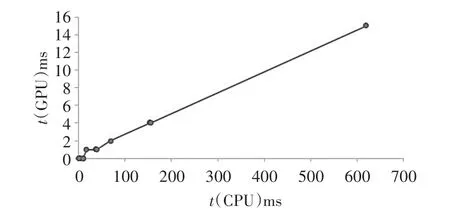
图6t(CPU)和t(GPU)关系图

表5 GPU带宽测试(GB/s)
根据表5中的数据,求平均值可以得出:主机内存与GPU存储之间的数据传输速度-vi=2.78 GB/s,GPU存储与主机内存之间数据传输速度-vo=2.99GB/s。
根据以上的计算结果,按照2.2节中的式(10),将t(sp),λ,vi,vo的值代入公式,便可以求得关于缩放倍率s的公式为:
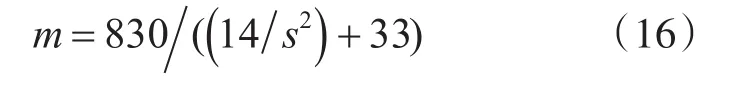
4.2 算法效率对比
在常用的由1024*1024图像块组成的图像金字塔的条件下进行本文调度算法与开源栅格空间数据转换库GDAL中的图像重采样算法重采样效率对比。结果如图7所示。
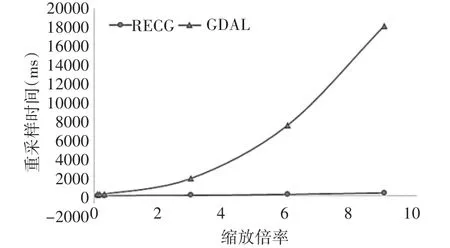
图7 调度算法与GDAL重采样时间对比
4.3 实验结果分析
4.3.1 RECG模型验证
通过4.1节实验数据进行公式的验证,首先将缩放倍率代入式(16)。当缩放倍率s=1/3时,得到m=5.22>1,当s=1/6时,m=1.55>1,表明利用GPU进行重采样的速度是CPU重采样的5.22倍和1.55倍,此时应该利用GPU进行重采样。当s=1/9时,m=0.71<1,即利用GPU进行重采样时,速度是CPU重采样速度的0.71倍,此时应该利用CPU进行重采样。由表1~表4中的实验数据可知,当s的值为1/3,1/6时,T(GPU)的值要小于T(CPU)的值,所以GPU进行重采样更合适,当s的值为1/9时,T(GPU)的值要大于T(CPU)的值,所以用CPU进行重采样更合适,与公式预测的结果吻合。又根据此公式,当进行放大操作时,m的值均大于1,说明在本实验条件下,进行放大操作时,进行重采样所占的时间是影响效率的主要因素,主机内存与GPU存储之间数据传输所消耗的时间是次要因素,应该用GPU进行重采样。这里对常用的大小为1024*1024的图像金字塔图像块进行放大操作验证,结果如表6所示。由表6的实验结果可以看出,对图像块进行放大操作时,T(GPU)的值均小于T(CPU)的值,与公式预测结果吻合。通过图像放大和缩小的实验数据表明,式(10)和(16)是合理的。

表6 1024*1024图片大小下放大操作耗时(ms)
由4.1节的实验数据知,当利用RECG模型进行判断,结果为利用GPU进行重采样时,重采样速度比相同条件下利用CPU进行重采样的速度成倍增加。当结果为利用CPU进行重采样时,比相同条件下利用GPU进行重采样时的速度也有所增加。因此,先利用RECG模型进行判断然后决定重采样的方式,比单纯地使用一种重采样的方式效率提升很多。
4.3.2 算法效率分析
从图7可以看出,本文算法的重采样效率要高于GDAL中图像重采样算法的效率。分析其中的原因,主要为算法利用RECG模型根据要进行重采样的图像的信息对重采样方法进行了动态选择,结合了GPU与CPU图像重采样的各自优势,而GDAL则是只利用了单一的CPU重采样方式对图像进行重采样。
4.4 重采样结果的精确化
4.4.1 金字塔重采样层数的选择
3.3节中的调度算法过程1)涉及到金字塔图像层数的选择问题,设目标图像的分辨率为r,图像金字塔中与目标分辨率接近的层数的分辨率为r1和r2,且r1>r>r2。为了获取更好的图像重采样效果,则应该选择分辨率为r1的金字塔图像图像进行重采样。而当需要快速地得到重采样的结果,则可以选择分辨率为r2的图像实现重采样。
4.4.2 重采样结果的定位
由于金字塔每层都是按照图像块划分的,不能具体到像素点,所以重采样时会出现图8的情况。

图8 实际重采样图像和需要重采样图像关系图
从图8可以看出,在进行重采样时,实际需要重采样的图像包含于进行重采样的图像之中,如果要获取实际需要的显示的图像,则需要求得重采样之后实际需要的图像的起始像素点坐标,设起始像素点坐标为(rsx,rsy),图像宽和高缩放倍数为scale⁃NumW,scaleNumH,则:

通过求得(rsx,rsy)以及已知的缩放以后要求的图像的长和宽,则可以从重采样结果中获取真正需要的图像部分。
5 结语
本文利用了RECG模型来判断图像的重采样方式,并且通过缓存减少图像块数据在不同类型存储之间的读取次数,有效地提升了对图像金字塔图像块进行重采样的效率。
本文中的重采样为对规则的可见区域进行重采样,下一步将研究如何对不规则可见区域进行快速重采样,以及在可见区域快速转换的过程中,如何提出更高效的预测和缓冲策略以降低图像重采样的请求响应时间。
[1]邓雪清.栅格型空间数据服务体系结构与算法研究[D].郑州:中国人民解放军信息工程大学,2003.
DENG Xueqing.Research of Service Architecture and Al⁃gorithms for Grid Spatial Data[D].Zhengzhou:The PLA Information Engineering University,2003.
[2]王文珊.遥感影像金字塔数据的生成与压缩方法研究[D].太原:太原理工大学,2015.
WANG Wenshan.TheGenerationandCompression Methord Research of Remote Sensing Image Pyramid Data[D].Taiyuan:Taiyuan University of Technology,2015.
[3]张云舟,张陌,王晋年,等.TDFA:一种生成空间影像金字塔的方法[J].中国图象图形学报,2016,21(7):959-966.
ZHANG Yunzhou,ZHANG Mo,WANG Jinnian,et al.TD⁃FA:a generation method of spatial image pyramid[J].Journal of Image and Graphics,2016,21(7):959-966
[4]曾志,李先涛,张丰,等.一种基于分块的遥感影像并行处理机制[J].浙江大学学报:理学报,2012,39(2):225-230.
ZENG Zhi,LI Xiantao,ZHANG Feng.A mechanism of re⁃mote sensing image for parallel processing base on split⁃ting blocks[J].Journal of Zhejiang University(Science Edition),2012,39(2):225-230.
[5]吕向阳.基于CPU+GPU的图像处理异构并行计算研究[D].南昌:南昌大学,2014.
LV Xiangyang.Research on Heterogeneous Parallel Com⁃puting Based on CPU+GPU in Digital Image Processing[D].Nanchang:Nanchang University,2014.
[6]Zhao J,Zhou H.Design and optimization of remote sens⁃ing image fusion parallel algorithms based on cpu-gpu het⁃erogeneous platforms[C]//Image and Signal Processing(CISP),2011 4th International Congress on.IEEE,2011,3:1623-1627.
[7]Ravishankar M,Holewinski J,Grover V.Forma:A DSL for image processing applications to target GPUs and multi-core CPUs[C]//Proceedings of the 8th Workshop on General Purpose Processing using GPUs.ACM,2015:109-120.
[8]Teodoro G,Pan T,Kurc T M,et al.High-throughput analysis of large microscopy image datasets on CPU-GPU cluster platforms[C]//Parallel&Distributed Processing(IPDPS),2013 IEEE 27th International Symposium on.IEEE,2013:103-114.
[9]Scott N Steketee,Norman I Badler,Parametric keyframe interpolation incorating kinetic adj-ustment and phrasing control[J].ACM SIGGRAPH Computer Graphics,1985,19(3):255-262.
[10]戴晨光,张永生,邓雪清.一种用于实时可视化的海量地形数据组织与管理方法[J].系统仿真学报,2005,17(2):406-409,413.
DAI Chengguang,ZHANG Yongsheng,DENG Xueqing.An Organization and Management Approach of Data for Real-Time Visualization of Massive Terrain Dataset[J].Journal of System Simulaton,2005,17(2):406-409,413.
猜你喜欢
环球时报(2022-09-19)2022-09-19
网络安全与数据管理(2022年1期)2022-08-29
考试与评价·七年级版(2020年4期)2020-10-23
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
家庭影院技术(2018年9期)2018-11-02
小学教学研究·新小读者(2017年9期)2017-10-25
电脑爱好者(2015年21期)2015-09-10
微型计算机(2009年4期)2009-12-23
数码摄影(2009年12期)2009-12-07
