
基于多算法融合的化工突发事件信息抽取研究∗
2018-03-20 07:10陈卓郑帅
计算机与数字工程 2018年2期
陈卓郑帅
(青岛科技大学信息科学技术学院 青岛 266061)
1 引言
根据公安部消防局公布的今年上半年的消防出警情况来看,消防队伍已参与处置化危品事故7904起。平均每天44起化工突发事件造成危害已严重影响到人们的生活,因此对化工事件进行有效的管理已经刻不容缓,为了提高中文信息处理的效率,提高信息处理的准确率帮助人们全面地掌握自己所需要的信息,因此国内外研究人员对事件抽取的方法进行了深入研究并提出了一系列的方法,但大致上可以分为基于模式匹配和基于统计机器学习两种方法[1]。
模式匹配通常又称为规则匹配。对于化工突发事件的抽取来说,化工突发事件的模式获取是模式匹配方法中最关键的一步,这些模式规则可以通过手工方式,半手工方式,自动方式等方式来进行设定。基于化工突发事件模式匹配的方法对所研究的语言,领域以及文本格式有着严重的依赖性,且可移植性弱,通常需要借助相关领域专家的帮助才能完成。此外,化工突发事件抽取的模式并不可能覆盖所有事件,当改变语料吋,需要重新编写相关的匹配模式,性价比不是很高。但是相对于机器学习的方法,模式匹配方法的准确率相对要好。
统计机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。因为学习算法中涉及了大量的统计学理论,机器学习与统计推断学联系尤为密切,也被称为统计学习理论[2]。当前机器学习比较常用的学习算法有线性回归,逻辑回归,神经网络,SVM聚类等。统计机器学习的方法主要研究的是词语的分布情况,词语的词频,以及是否是关键词等等特征而不考虑其语义关系,统计机器学习的方法不拘泥于语料的形式与内容,但是特征选取、语料规模的大小等因素都影响了机器学习的结果,它们只是将事件抽取看作一种分类题,而没有结合语义知识,所以说提取的结果不一定符合事件的特征。
基于上述所述,本文对其优缺点进行了整合提出了基于多算法融合的方法即规则模式及机器学习相结合的方法来进行化工突发事件的信息抽取。
2 化工突发事件信息抽取方法的研究
对于化工突发事件管理来说,常常需要对事件发生时间,发生地点,发生原因,事件结果,事故善后,所涉及的化学品,事故类型信息进行分析总结。所以对于化工突发事件的信息提取应当包含对上述7个方面类型信息的提取,图1为算法的流程图,本文将根据图1算法流程图按照文本预处理,模式获取及匹配以及机器学习3方面展开论述。

图1 化工突发事件信息抽取算法流程图
2.1 文本预处理
从外界提取的文字信息首先要整理为文本文件格式类型,本文统一以文本类型格式进行抽取,然后进行文本分句处理,文本以任意的标点符号进行断句分句,以句子作为进行文本处理的基本单位,这样就可以把一篇化工突发事件报道分为一系列的句子,降低了分析处理的粒度。本文利用Ansj分词器(ansj是一个开源的Java中文分词工具,基于中科院的ictclas中文分词算法,比其他常用的开源分词工具的分词准确率更高。)进行句子的切分和词性标注。接下来利用化工语料库识别化工突发报道中所涉及的化学品。利用词性可以识别出地点ns,时间t等命名实体词。字典的构建基于《危险货物品名表》(GB 12268—90)[3]中所出现的2110种化学品,构建化学品字典时可以为每一个化学品建立两条记录,一条记录用于存放化学品的名称,另一条用于存放化学品相关的特性,可用于事故类型抽取,利用字典可以识别出报道中所涉及的化学品信息。
2.2 模式获取及匹配
2.2.1 模式获取
本文利用规则模式及机器学习相结合的方法来抽取化工突发事件中的相关信息。建立模式规则库根据上述的化工突发事件所提取信息来构建出模式规则库——时间模式规则库,地点模式规则库,原因模式规则库,结果模式规则库,善后模式规则库。根据化工突发事件文本信息的特点来构建相应的规则[4]。
根据发生时间,发生地点的特性分别构建出时间规则库:^[0-9]+[年|月|日|点|时]+([u4e00-u9fa5]|[0-9]|:)*$,地点规则库:^([[0-9]|A-z|u4E00-u9FFF|()|()]+(镇|区|县|庄|省|市))([[0-9]|A-z|u4E00-u9FFF])*(,|.|。)$
在化工突发事件中,化工突发事件在事件的成因上无非可以概况成5大因素1)人工操作不当,操作失误,或者违反规定进行操作;2)由于机器设备故障,或者技术存在问题;3)企业管理不当,违反电气的安全,在吸烟,静电等问题没有很好地管制;4)交通运输事故引发的化工突发事件;5)人为的损坏,破坏,如:恐怖分子袭击;
通过这5大因素的特点即可总结出一些关键字词如擅自,私自,机器设备故障,违章操作,引发等,从而可以归纳出一系列的匹配规则构建出原因模式规则库来,作者根据语料构建的部分原因规则库信息如下:
1)^([[0-9]|A-z|\u4E00-\u9FFF])*(擅自|私自|自行|执意)([[0-9]|A-z|\u4E00-\u9FFF])*(,|.|。|;|,)$;
2)^([[0-9]|A-z|\u4E00-\u9FFF])*(违章操作)([[0-9]|A-z|\u4E00-\u9FFF])*(,|.|。|;|,)$;
3)^([[0-9]|A-z|\u4E00-\u9FFF])*(大火|火灾|泄露|爆炸|故障|中毒|爆炸|爆燃|事故)+(系|由于|因为)([[0-9]|A-z|\u4E00-\u9FFF])+(所致|导致|引发|发生)+(,|.|。|;|,)$;
其中符号^指的是句子的开始,$指的是句子的结束,[0-9]的含义是0-9中任意的一个数字字符,[\u4E00-\u9FFF]是一个汉字字符,[A-z]指的是任意的一个英文字母,*的含义是重复任意的数量,可以是0次,+的含义是至少重复一次,|的含义是“或”。
事件所造成的结果同样有着自己独有的特征。从事故的结果内部组成结构来看它有着非常明显的提示性的词语[5]如:受伤,死亡,经济损失,中毒,失踪,摧毁的词语,因此构建事件结果模式规则库也变得明朗起来,以下是部分结果规则库信息:
1) ^ ( [\u4e00-\u9fa5] * [0-9] +[\u4e00-\u9fa5]*(丧生|死亡|失踪|受伤|失联|中毒|抢救|伤))+(,|.|,|。|、)$
2)^([[0-9]|A-z|\u4E00-\u9FFF]*)(损失)([[0-9]|A-z|\u4E00-\u9FFF]*)(万元)([[0-9]|A-z|\u4E00-\u9FFF])*(,|.|。|;|,)$
3)^([[0-9]|A-z|\u4E00-\u9FFF]*)(造成)([[0-9]|A-z|\u4E00-\u9FFF]*)(结果)([[0-9]|A-z|\uE00-\u9FFF])*(,|.|。|;|,)$
同理,事件的善后信息关键字通常是疏散,撤离,补偿,获赔,赔款,控制等词语由此构建事件构建出善后信息的规则库,以下是部分善后规则库信息:
1)^[\u4e00-\u9fa5]*(获赔|赔偿|补偿)+(,|,|.|。)$;
2)^([[0-9]|A-z|\u4E00-\u9FFF])*(疏散|撤离 |体 检 |控 制 |扑 灭 |恢 复 |治 疗)+([[0-9]|A-z|\u4E00-\u9FFF])*(,|,|.|。)$
2.2.2 模式匹配及信息提取
通过上一节叙述所构建的规则库来匹配事故信息,并利用相关算法即可对相关事故信息进行抽取,具体做法如下:
事件发生时间在事故新闻的描述位置上有着明显的特征,作者对所收集的400篇预料中统计出了一些使用频率非常高的词汇,如爆发,突发,引发,出现,发生等等特征词。事故的发生时间之后通常会出现上述词汇。所以我们可以利用这个特征一旦检测到这些特征词语可以向前就近找出现的时间,所提取的时间就是事件的发生时间[6]。根据以上描述,发生时间提取算法步骤如图2所示。
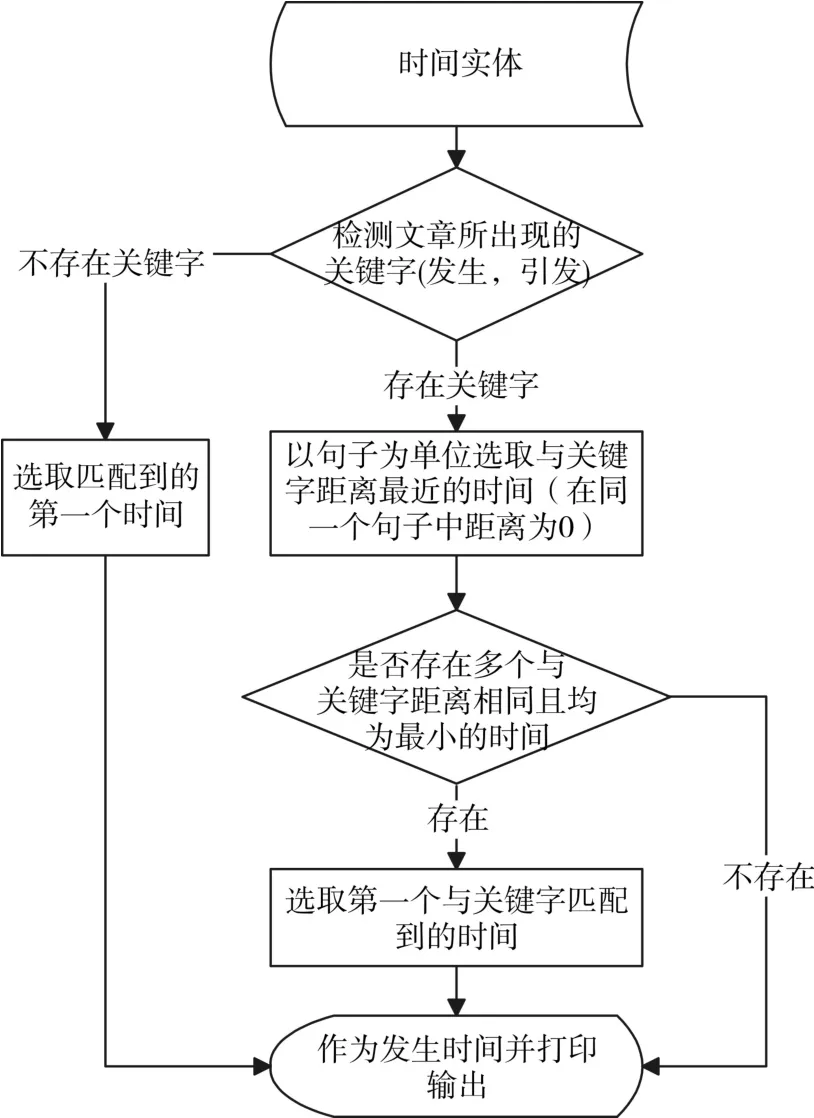
图2 时间算法流程图
利用词性标注结合时间模式规则库中的规则识别出来的时间实体经过检测关键字,选取与关键字位置最为接近的那个时间即可提取发生时间。
作者对所收集的语料进行分析和整理,通过对事故发生地点词语特点的总结,从而引申出事件发生地点的算法,事故发生地点词语的特点:1)首先同抽取发生时间一样,根据汉语的表达特点作为事故的发生地点往往与发生,引发,爆发等关键词在距离上最为接近;2)经过对语料的统计可以得出事件的发生地点往往也是描述性最长的地点词语[7]。所以事件发生地抽取算法如下:
1)通过地点词性ns与地点模式规则库匹配出来的地点集合S1;
2)对S1进行筛选,选择与事件关联词最为接近的地点,如存在且唯一则把该地点作为发生地点并输出;不存在或不唯一转3);
3)选取描述性最长的地点词语作为发生地点并输出;
事故发生原因,事故结果,事故善后的抽取在抽取方法上都有着统一性即都是依靠模式规则库中的规则来抽取。利用文本预处理之后的语料进行规则匹配[8],与原因模式规则库中的规则匹配成功,这条语句就是事故的发生原因。与结果模式规则库中的规则匹配成功后,此语句就是事故造成的结果。抽取步骤如图3所示。
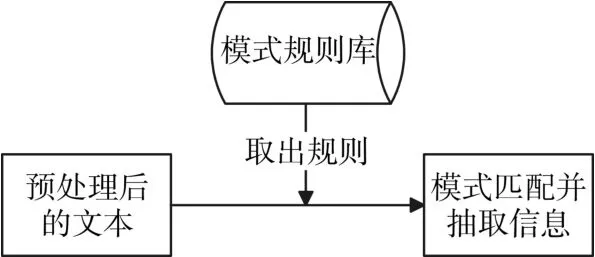
图3 规则匹配及抽取信息流程图
依照我们发布的《重大危险源辨识》(GB18218-2000)[9]把化工类事故分为爆炸事故,火灾事故,中毒事故以及泄漏事故4大项。因为我们在文本预处理时就可以通过相关语料库识别出所涉及的化学品。而化学物品是事故的发生源因此可以根据危险物品的特性来反推出所可能发生的事故类型[10]。例如:氢气具有可燃的特性,根据其特性在文章没有提及所发生事故类型的前提下可大致推断事故的类型有可能是火灾,所以事故类型抽取算法如下:
1)遍历文章的所有分句,检测是否含有爆炸,火灾,中毒等相关关键字,如果存在则直接提取关键字作为事件类型信息,如果不存在进行2);
2)根据所提取的化学物品,提取化学品字典中所具有的特性来作为事件的类型。
2.3 机器学习
规则模式库中规则的建立是抽取化工突发事件信息的最为重要的一个环节,在2.1节所述规则模式库的建立都是通过人工的方式手动建立规则,本节所要叙述的是依靠人为的反馈,自动地建立规则。
关键词是建立规则的基础,本文首先依靠最大熵依存句法分析算法模型[11]来计算得到句子中各个成分之间的依存关系,通过人为的反馈计算得出一个句子的核心关心(关键词语),最大熵模型有如下公式:
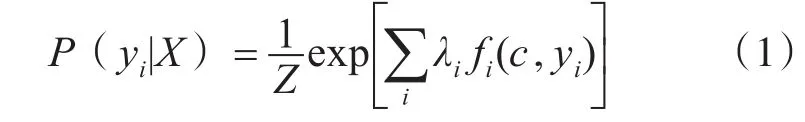
其中λi是最大熵模型的参数,每个λi对应于一个特征函数。Z是归一化因子,确保整个模型是一个合法的概率分布。在依存句法分析中依存关系权重用λ3,…,λn表示;特征向量用 f1(c , y1),f2(c , y2),…,fn(c , yi)这些特征来表示,如果特征出现为1,否则为0。
最大熵依存句法分析算法如下:
1)通过对一个句子进行分词标注;
2)然后根据式(1)利用最大熵模型估计任意两个单词之间最可能的依存关系以及概率,将概率的值取对数取相反数作为边的花费;
3)接下来使用最小生成树算法[12]计算出一棵全局最小的生成树即可。
本文通过计算选取一个句子的核心关系来自动构建规则的模式。但是并不是每一个句子都能有核心关系,所以最大熵依存句法分析算法不能完全解决问题的需要,因此本文通过使用关键字生成算法TextRank[13]所生成的关键字来辅助构建正则表达式的生成,公式表达如下:
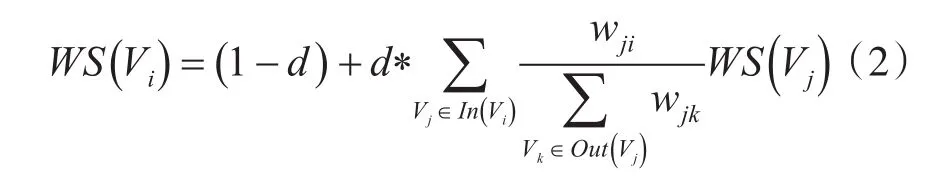
S(Vi)是结点Vi的重要性(分值)。d是阻尼系数,一般设置为0.85。In(Vi)表示指向结点Vi的结点集合。Out(Vj)表示结点Vj所指向的节点集合。Wij表示由结点Vi指向Vj的边的权重。
关键词抽取的任务就是从一段给定的文本中自动抽取出若干有意义的词语或词组。TextRank算法是利用局部词汇之间关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。其主要步骤如下:
1)把给定的文本T按照完整句子进行分割,即 T=[S1,S2,…,Sm];
2)对于每个句子Si∈T,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,即 Si∈[ti,1,ti,2,…,ti,n],其中是ti,j∈Si保留后的候选关键词。
3)构建候选关键词图G=(V,E),其中V为节点集,由式(2)生成的候选关键词组成,然后采用共现关系构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
4)根据上面式(2),迭代传播各节点的权重,直至收敛。
5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
6)由5)得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。例如,文本中有句子“清华北大都属于名牌大学”,如果“清华”和“北大”均属于候选关键词,则组合成“清华北大”加入关键词序列。
当最大熵依存句法分析算法无法计算分析出核心关系时,基于TextRank算法即可分析出句子的关键词语来代替谓宾关系所构建的规则。经过实验得出此方法具有良好的效果。
3 实验结果
本文的实验预料选自互联网中的关于化工突发事件的新闻报道,主要来源于安全管理网,化学品事故信息网,中国化工制造网等400篇报道。本文算法可以对文章所提及的发生时间,地点,原因,善后,结果,所涉及的化学品,事故类型进行抽取。系统评价时采用的精度和召回率定义如下:精度=抽取出的正确个数/抽取出的全部个数,召回率=抽取出的正确个数/应该抽取出的正确个数。具体实验结果如表1~表4所示。从实验结果中可以看出,所抽取信息有着较高的准确度。
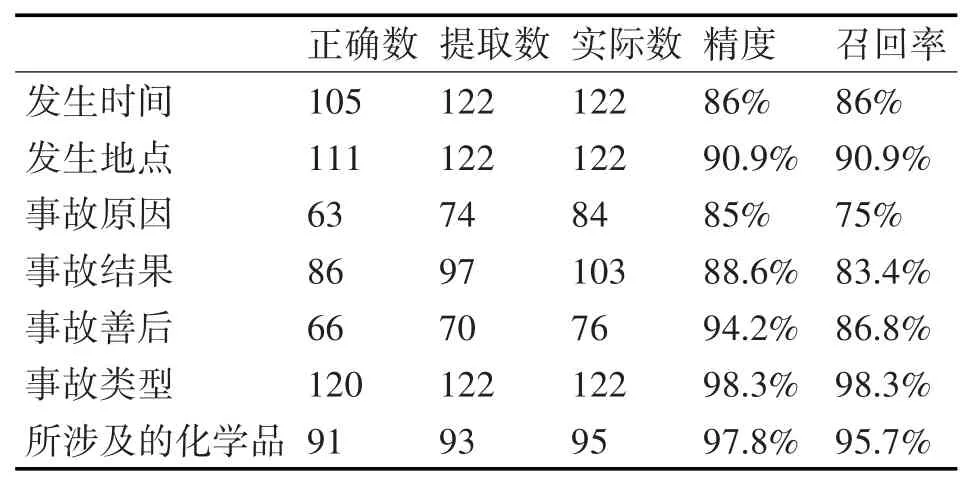
表1 爆炸类型事故测试结果
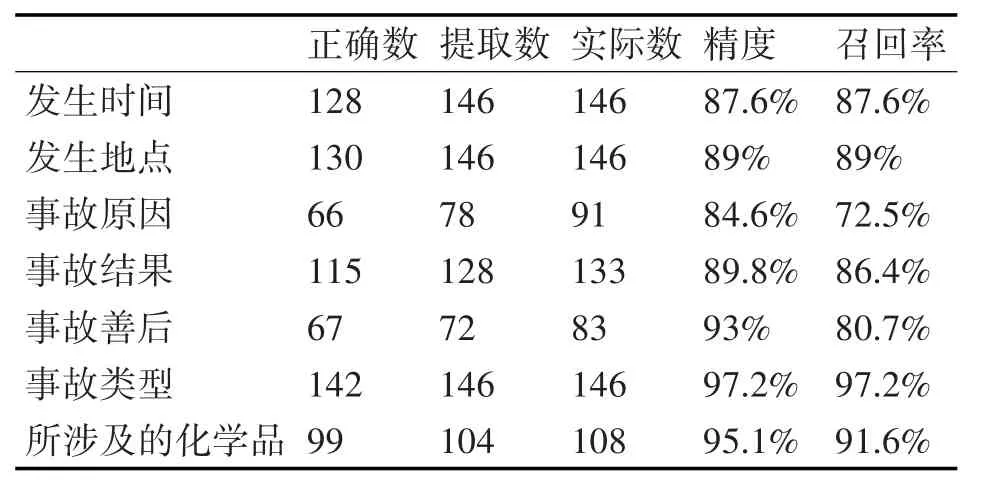
表2 火灾类型事故测试结果

表3 泄漏类型事故测试结果
图4为化工突发事件抽取系统主页面,本系统的上半部分有上传,浏览,展示的功能,通过Show按钮展示化工突发报道,下半部分通过提取内容按钮进行信息抽取从而形成结构化的数据。
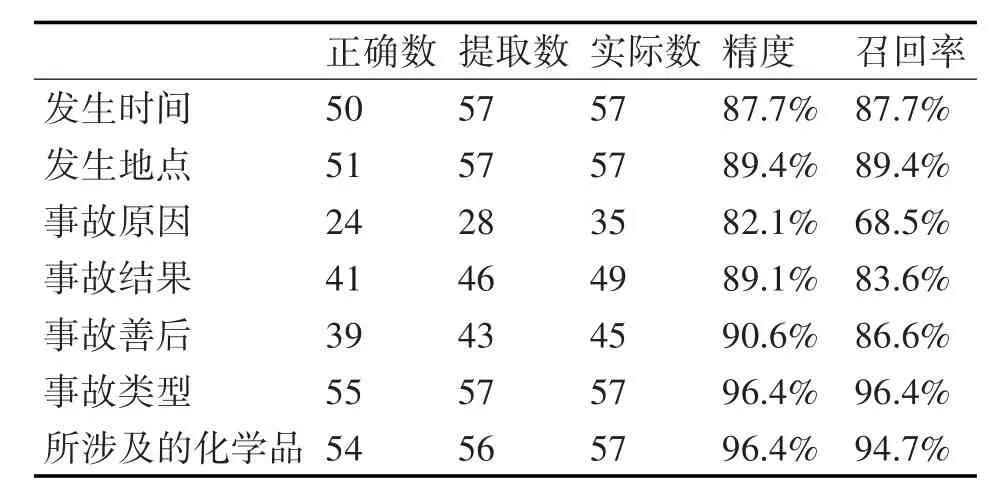
表4 中毒类型事故测试结果

图4 系统主页面
4 结语
本文针对化工突发事件提出了基于多算法融合的方法即规则模式及机器学习相结合的方法来进行信息抽取,首先对事件的不同信息实体作了较为详尽的描述抽取方法,然后利用关键字提取算法以及依存句法分析算法相融合的方法对用户所反馈的信息实现了规则模式的自动生成。实验证明本文的算法对化工突发事件的信息抽取有着较高的准确率,所抽取的结果较为可靠。
[1]杨尔弘.突发事件信息提取研究[D].北京:北京语言大学,2005:10-12.
YANG Erhong.Study on the extraction of emergency infor⁃mation[D].Beijing:Beijing Language and Culture Uni⁃versity,2005:10-12.
[2]何清,李宁,罗文娟,等.大数据下的机器学习算法综述[J].模式识别与人工智能,2014,27(4):327-336.
HE Qing,LI Ning,LUO Wenjuan,et al.A survey of ma⁃chine learning algorithms for large data[J].pattern rec⁃ognition and artificial intelligence,2014,27(4):327-336.
[3]GB12268-90,危险货物品名表[S].GB12268-90,List of dangerous goods[S].
[4]张亮,陈家骏.基于大规模语料库的句法模式匹配研究[J].中文信息学报,2007,21(5):31-35.
ZHANG Liang,CHEN Jiajun.Research on syntactic pat⁃tern matching based on large scale corpus[J].Journal of Chinese Information Processing,2007,21(5):31-35.
[5]蒋德良.基于规则匹配的突发事件结果信息抽取研究[J].计算机工程与设计,2010,31(14):3294-3297.
JIANG Deliang.Research on rule matching based informa⁃tion extraction for unexpected events[J].Computer engi⁃neering and design,2010,31(14):3294-3297.
[6]王昀,苑春法.基于转换的时间—事件关系映射[J].中文信息学报,2004,18(4):23-30.
WANG Yun,YUAN Chunfa.Time event relationship map⁃ping based on transformation[J].Journal of Chinese Infor⁃mation Processing,2004,18(4):23-30.
[7]李文捷,周明.基于语料库的中文最长名词短语的自动提取[J].计算语言学进展与应用,1995:119-124.
LI Wenjie,ZHOU Ming.Corpus based automatic extrac⁃tion of Chinese longest noun phrases[J].Advances and ap⁃plications in Computational Linguistics,1995:119-124.
[8]Kiyoshi Sudo 2004.Unsupervised Diseovery of Extraction Patterns for Information Extraetion[D].Department of Computer Science.New York University,September,2004.
[9]GB18218-2000,重大危险源辨识[S]GB18218-2000,Identification of major hazard installa⁃tions[S].
[10]孙宏林,俞士坟.浅层句法分析方法概述[J].当代语育学,2000,2(2):74-83.
SUN Honglin,YU Shiwen.Overview of shallow parsing methods[J].Contemporary language education,2000,2(2):74-83.
[11]辛宵,范士喜,王轩,等.基于最大熵的依存句法分析[J].中文信息学报,2009,23(2):18-22.
XIN Xiao,FAN Shixi,WANG Xuan,et al.Dependency parsing based on maximum entropy[J].Journal of Chi⁃nese Information Processing,2009,23(2):18-22.
[12]李洪波,陈军.Prim最小生成树算法的动态优化[J].计算机工程与应用,2007,43(12):69-73.
LI Hongbo,CHEN Jun.Dynamic optimization of Prim minimum spanning tree algorithm[J].Computer engi⁃neering and Applications,2007,43(12):69-73.
[13]夏天.词语位置加权TextRank的关键词抽取研究[J].现代图书情报技术,2013(9):30-34.
XIA Tian.Keyword extraction of word position weighted TextRank[J].New Technology of Library and Informa⁃tion Service,2013(9):30-34.
猜你喜欢
化工管理(2022年27期)2022-11-15
化工管理(2022年30期)2022-11-15
化工管理(2022年15期)2022-11-15
化工管理(2022年24期)2022-11-09
国际医药卫生导报(2022年18期)2022-09-29
小天使·一年级语数英综合(2020年4期)2020-12-16
领导科学论坛(2016年10期)2016-06-05
文史春秋(2016年8期)2016-02-28
传奇故事(破茧成蝶)(2015年7期)2015-02-28
小说月刊(2014年10期)2014-04-23
